一、Unsupervised Pre-training
得益于 Hinton and Salakhutdinov 在 2006 年的开创性工作— 无监督预训(unsupervised pre-training);在《Reducing the dimensionality of data with neural networks.》这篇论文中,他们在 RBMs 中引入无监督预训练,下面我们将在Autoencoders中讲解这一方法(建议了解Restricted 玻尔兹曼机):
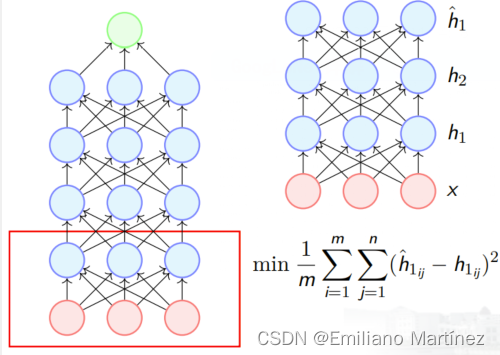
经过这一步后,第一层的权重被训练,使得 h1 捕获输入 x 的重要信息。然后,将第一层的权重固定,在第二层上重复这一过程。经过这一步后,第二层的权重被训练,使得 h2 捕获 h1 的重要信息,继续这一过程,直到最后一个隐含层。【最后一个隐含层是输出层的前一层】
预训练结束后,使用训练出的权重来初始化隐含层的权重。所得到的网络能够学习到输入数据类别独立的特征表示 (class independent 因为没有使用到数据的标签 y)。 预训练结束后,再在网络上增加输出层,使用特定的目标(或损失函数)来训练整个网络。整个过程可以理解为:先使用无监督的预训练(无监督的目标)来初始化网络权重,再使用特定有监督的目标来 fine tune 整个网络。
二、激活函数
详见: