循环依赖是之前很爱问的一个面试题,最近不咋问了,但是梳理Spring解决循环依赖的源码,会让我们对Spring创建bean的流程有一个清晰的认识,有必要搞一搞。开始搞之前,先参考了这个老哥写的文章,对Spring处理循环依赖有了一个基本的认识之后,然后开始进行源码debug,感谢这位老哥的分享:https://developer.aliyun.com/article/766880
我们搞一个简单的例子,先看看什么是循环依赖,我们只讲最简单的这种,set方法循环依赖,除此之外还有构造器循环依赖,我们讲最简单的这种,其实道理是一样的。
搞一个demo
@Data
@Component
public class TestA {
@Autowired
private TestB testB;
public void getA(){
System.out.println("我是getA方法");
}
}
@Data
@Component
public class TestB {
@Autowired
private TestA testA;
}
A依赖B,B依赖A。这样就形成了一个简单的循环依赖。众所周知,Spring解决循环依赖的经典方法是三级缓存,当然还有其他的方法也可以处理,比如懒加载。今天我们只聊三级缓存,其他方式,感兴趣的话,可以自己查一些资料。
如果之前看过Spring的代码,我们就知道,Spring在创建bean之前都会先获取bean,如果获取不到,才会创建bean。所以我们从获取bean开始看起。
获取bean的入口在AbstractBeanFactory的doGetBean方法中。第一行代码,我们先看到从缓存获取bean的流程
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);
这个方法里,我们想看的三级缓存就全了
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//先从一级缓存取
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//一级缓存没有,从二级缓存取
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//二级缓存没有,从三级缓存取
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//三级缓存取出来之后放入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//从三级缓存移除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
刚开始,这三个缓存里,肯定都没有,父容器中也不会有。所以此时,需要创建A。
创建A的流程也在doGetBean方法里,我们向下看,有这样一段逻辑
// Create bean instance.
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
}
});
}
createBean就是创建一个bean,但是这个createBean的过程是getSingleton方法的一个参数,是一个工厂方法,也就是说先执行getSingleton方法,某一个时机下,再触发工厂方法,我们看一下getSingleton的逻辑,我去掉了无关代码。先从一级缓存中获取,如果没有获取到,会触发createBean工厂方法的执行
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
//从一级缓存中获取
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//一级缓存不存在,执行工厂方法创建bean
singletonObject = singletonFactory.getObject();
newSingleton = true;
//bean创建成功,放入一级缓存
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
//将创建完成的对象放入一级缓存中,也就是单例池中
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
从上面的逻辑,我们可以得到一个结论,一级缓存的bean已经是创建完成的bean,可以对外提供服务。
接下来,我们继续看工厂方法createBean的流程,创建bean的流程在AbstractAutowireCapableBeanFactory的doCreateBean方法中,我去掉了无关逻辑。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
//初始化bean,相当于new对象操作
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
//Spring解决循环依赖的核心逻辑
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//放入三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
Object exposedObject = bean;
//对当前bean进行依赖注入
populateBean(beanName, mbd, instanceWrapper);
//初始化bean,执行bean的一些初始化方法,比如各种aware、实现各种接口啥的。这个流程也有一个经典的面试题,bean的生命周期
exposedObject = initializeBean(beanName, exposedObject, mbd);
return exposedObject;
}
上面就是创建A的具体逻辑,我们画个图梳理一下
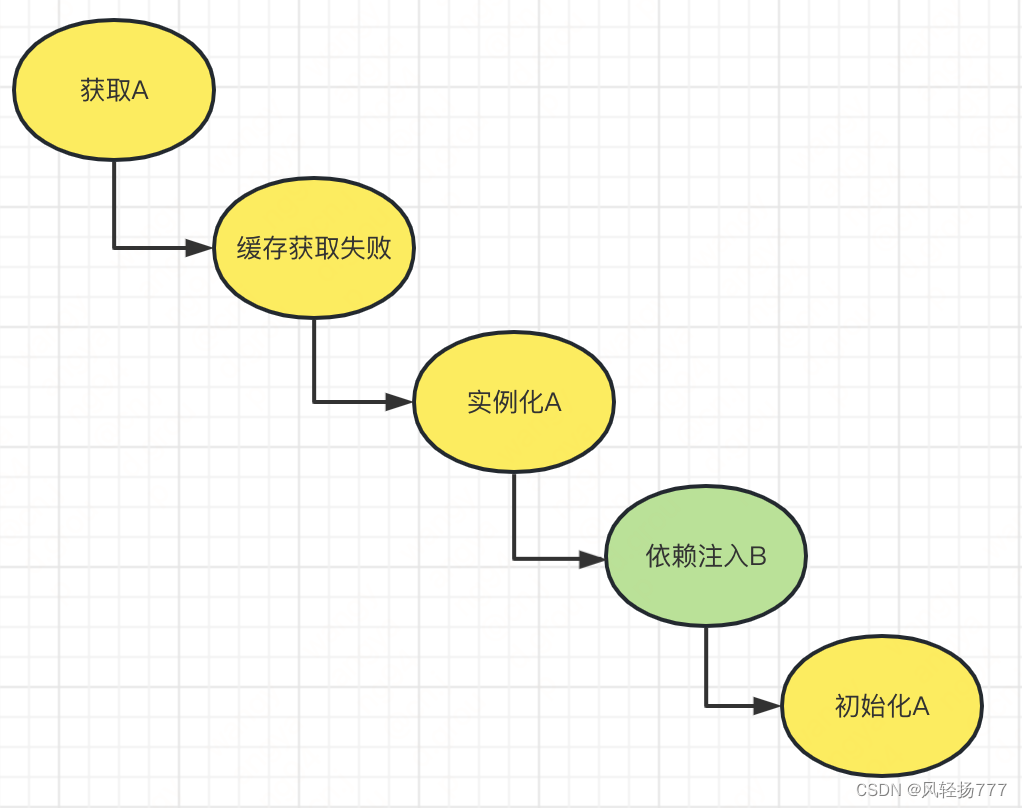
创建A的流程中可以看到,在实例化A之后,就执行了放入三级缓存的动作。只要你没有禁止循环依赖,刚实例化的bean就会放入三级缓存。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
添加进三级缓存的是一个lambda表达式,() -> getEarlyBeanReference(beanName, mbd, bean),我们经常叫做工厂,那这个工厂方法又是什么时候触发呢?先按下不表,我们继续往下看,A进入三级缓存后,逻辑紧接着就要对A进行依赖注入,A需要依赖注入B,此时要去容器中获取B,获取B的流程和获取A的流程是一样的,获取入口也是AbstractBeanFactory的doGetBean方法,和获取A一样,也执行一遍三级缓存的获取操作,就是getSingleton方法。当然也是没有,所以需要创建B。
创建B的过程和创建A的过程一样。
实例化—>依赖注入—>初始化
我们把B的创建流程也画一下
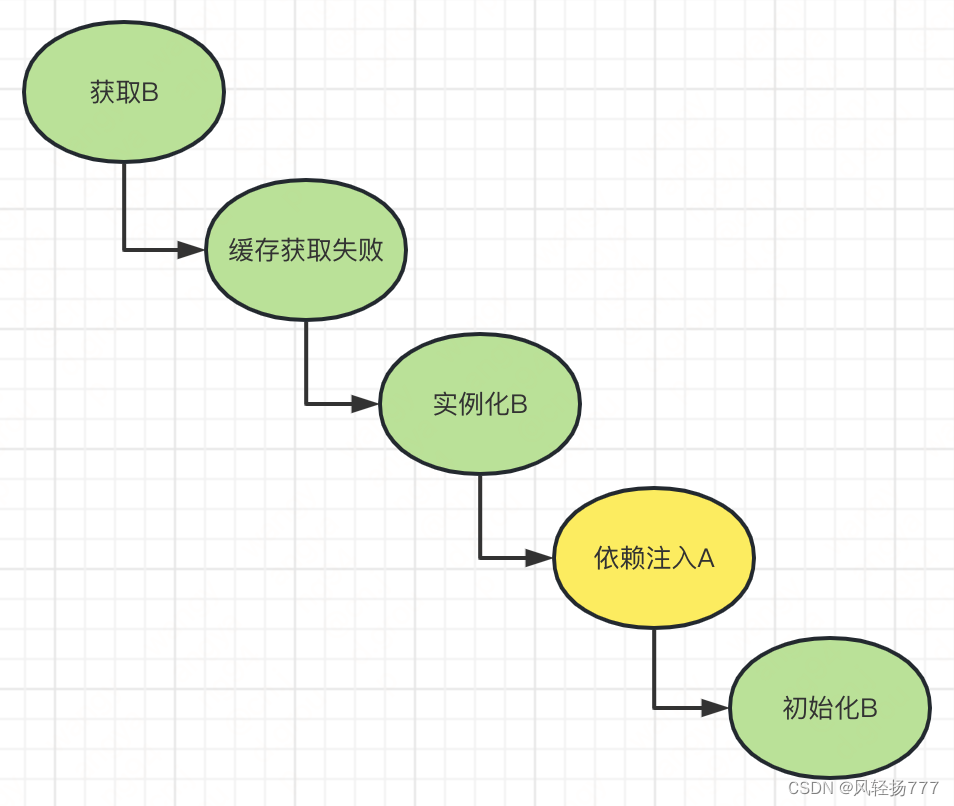
B的依赖注入,需要注入A,我们需要先获取A,此时就又会走到AbstractBeanFactory的doGetBean的逻辑中。又会执行getSingleton逻辑。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//先从一级缓存取
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//一级缓存没有,从二级缓存取
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//二级缓存没有,从三级缓存取
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//三级缓存取出来之后放入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//从三级缓存移除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
一级缓存还是没有,二级缓存也没有,但是三级,此时就有了,因为我们创建A的过程中,已经把A先放入了三级缓存。此时从三级缓存中获取出来的工厂方法 “() -> getEarlyBeanReference(beanName, mbd, bean)” 就会触发,拿到A,然后将A放入二级缓存。我们看下这个工厂方法的逻辑里都干了啥
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
以上代码等价于
Object exposedObject = bean;
exposedObject = beanPostProcessor.getEarlyBeanReference(exposedObject, beanName);
return exposedObject;
processor虽然是一个集合,但是真正起作用的processor只有一个,就是AnnotationAwareAspectJAutoProxyCreator,它是通过@EnableAspectJAutoProxy注解导入到bean容器中的,从名字也能看到它是处理AOP的。我们看看这个processor的处理逻辑
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
//获取AOP代理对象
return wrapIfNecessary(bean, beanName, cacheKey);
}
实际上就是AOP代理的增强过程
但是,我们的业务代码,不一定都会用到AOP吧。那如果不用AOP的话,容器中就不会有AnnotationAwareAspectJAutoProxyCreator对象,那getEarlyBeanReference方法就可以简化为:
Object exposedObject = bean;
return exposedObject;
相当于工厂方法啥也没干。所以这就是为啥Spring放入三级缓存的是一个工厂方法,而不是立即获取代理对象放入三级缓存,因为在创建A的过程中,并不一定存在循环依赖,如果没有循环依赖,Spring处理AOP增强的逻辑统一在bean创建流程的末尾,就是initializeBean方法中
//对当前bean进行依赖注入
populateBean(beanName, mbd, instanceWrapper);
//初始化bean,执行bean的一些初始化方法,比如各种aware、实现各种接口啥的。这个流程也有一个经典的面试题,bean的生命周期
exposedObject = initializeBean(beanName, exposedObject, mbd);
就是因为Spring也不确认依赖注入过程中是否会有循环依赖,它没办法,只能先暴露一个工厂方法,等到循环依赖真正产生的时候,再执行工厂方法,相当于把AOP增强过程延迟了。
至此,我们小结一下,我们完善一下创建A的流程
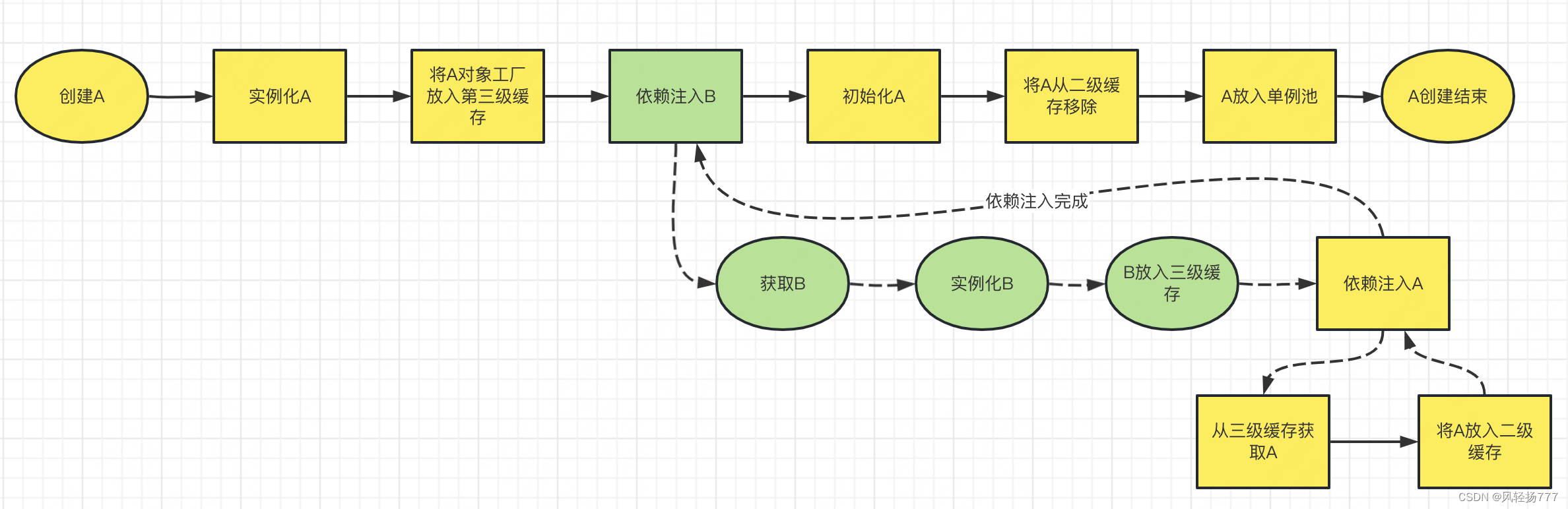
此时,我们就拿到了A,虽然不完美,但是已经可以让B的创建流程继续往下走,B创建完成后,将B放入单例池。然后,继续创建A。A完成,放入单例池,结束。Spring的循环依赖就是这样解决的。
下面,我们说2个经典的面试题
1、为什么需要三级缓存,二级缓存可以吗?
不但不可以,而且可能会破坏Spring的整体设计。我们说2种情况。
A是一个AOP对象,对A进行依赖注入前,Spring也不知道会不会存在循环依赖,只能先把A进行AOP增强,放入二级缓存,这样做明显是不合理的,如果后面不存在循环依赖,我们提前搞了一个代理对象,就做了无用功,并且也破坏了Spring的整体设计,因为Spring会在bean创建的末尾统一进行AOP增强,提前搞没有任何意义。有的同学会说,工厂方法确实有必要存在,那二级缓存有必要吗?我只保留一级和三级,不要二级可以吗?那就是下面这道面试题了。
2、只有一级和三级,没有二级可以吗?
猛地一看,二级缓存确实啥也没干,就是存取对象,真实的情况是这样吗?肯定不是的。抛开代码不说,就凭Spring的使用范围如此之广,不可能出现一段无用代码。那二级缓存的作用是什么呢?我举一个例子,你马上就明白了。下面这种场景,二级缓存必须得有。
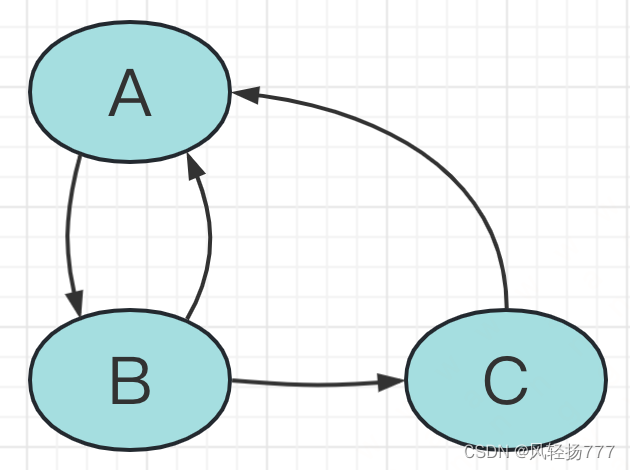
A依赖B,B依赖A(三级缓存中获取A,将A加入二级缓存),B依赖C,C依赖A(二级缓存中获取A),如果没有二级缓存,那我们需要执行两次A的三级缓存工厂方法,如果依赖关系更复杂,可能需要执行多次工厂方法,显然是不合理的,所以Spring的二级缓存很重要。
我们画一下以上循环依赖的处理过程
我标注了序号,你可以按照序号来看一下整个过程,然后自己debug一遍代码,对二级缓存存在的必要会有一个更清洗的认识
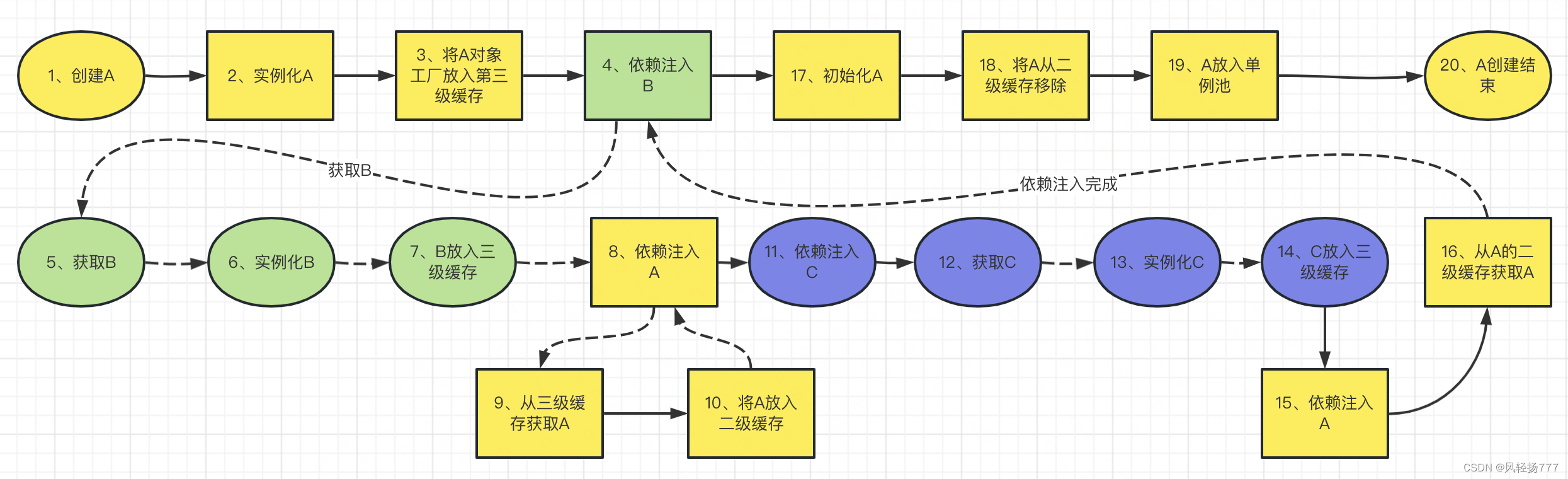
我们总结一下Spring三级缓存的作用。
第一级缓存:存放完整的bean对象,这里面的bean已经可以对外提供服务
第二级缓存:已经进行了实例化,但是未完成依赖注入和初始化的对象
第三级缓存:存放工厂方法。提前暴露的一个对象,Spring解决循环依赖的核心所在