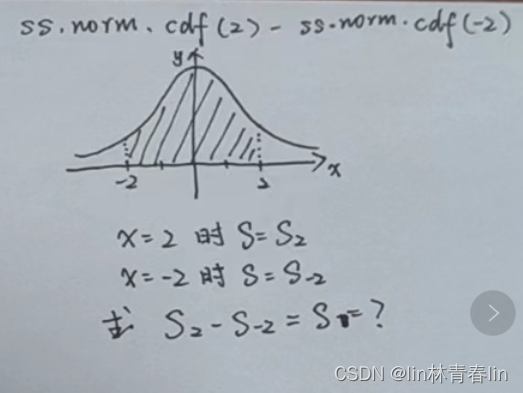
一、语句
1.加注释
单行注释:
(1)在代码上面加注释: # 后面跟一个空格
(2)在代码后面加注释:和代码相距两个空格, # 后面再跟一个空格
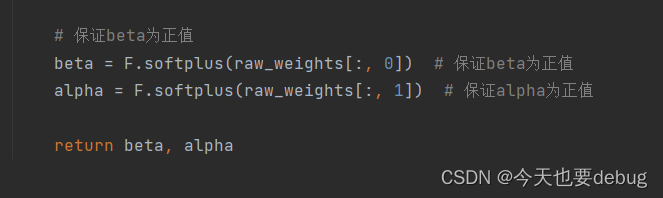
多行注释:按住shift + 点击三次"(英文状态下)
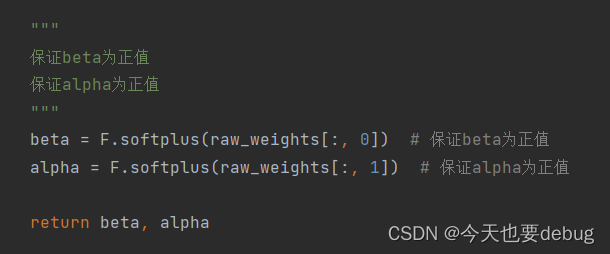
2.with...as...
with as 语句操作上下文管理器(context manager),它能够帮助我们自动分配并且释放资源。
二、导入
导入模块有两种常用方法 :import 语句和 from … import 语句
import XXX:导入模块,后调用此模块的ZZ方法时格式为XXX.ZZ()
from XXX import ZZ:ZZ为模块 XXX里的方法,后调用此模块中的ZZ方法时格式为ZZ()
(1条消息) 坑啊!为什么不建议用 from xxx import *!_菜鸟学Python的博客-CSDN博客
1.from __future__ import print_function
该语句是python2的概念,那么python3对于python2就是future了,也就是说,在python2的环境下,超前使用python3的print函数。
2.import numpy as np
利用命令“import numpy as np”将numpy库取别名为“np”
3.from tensorboardX import SummaryWriter
是神经网络中的可视化工具
Pytorch中TensorBoard及torchsummary的使用详解 | w3c笔记 (w3cschool.cn)
4.import os
import os 在python环境下对文件,文件夹执行操作的一个模块
import os.path获取文件的属性
5.import torch.nn.functional as F
包含 torch.nn 库中所有函数
同时包含大量 loss 和 activation function
6.import argparse
(1条消息) argparse.ArgumentParser()用法解析_quantLearner的博客-CSDN博客_argparse.argumentparser() 参数
用来设置命令行参数,参数和超参数的区别:
超参数(Hyperparameter) - HuZihu - 博客园 (cnblogs.com)
三、一般函数解读
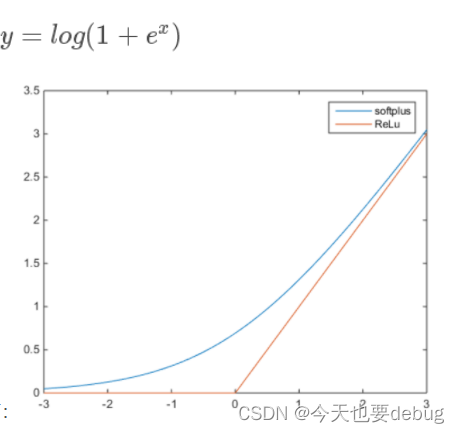
1.softplus()激活函数
softplus的数学表达式以及与Relu的函数对比,相当于Relu的平滑
2.forward()
将上一层的输出作为下一层的输入,并计算下一层的输出,一直到运算到输出层为止。
3.os.path.join
用于路径拼接,注意/的运用
(2条消息) os.path.join()函数用法详解_swan777的博客-CSDN博客
import os
path='C:/yyy/yyy_data/'
print(os.path.join(path,'/abc'))
print(os.path.join(path,'abc'))
结果
C:/abc
C:/yyy/yyy_data/abc4.shutil.rmtree()
递归地删除文件夹以及里面的文件
5.random.randint(start, stop)
返回指定范围内的整数
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
6.enumerate()
四、torch函数解读
1.torch.tensor()
用来存储和变换数据
2.torch.sum()
对输入的tensor数据的某一维度求和,有两种方法,dim=0纵向求和,dim=1横向求和
(1条消息) torch.sum()、np.sum()和sum()简要介绍_np.sum torch.sum_两分先生的博客-CSDN博客
import torch
import numpy as np
a = torch.tensor([[1, 2, 3], [4, 5, 6]])
b = np.array([[1, 2, 3], [4, 5, 6]])
c = [1, 2, 3, 4, 5, 6]
print(torch.sum(a))
print(torch.sum(a, dim=0))
print(torch.sum(a, dim=1))
print(torch.sum(a, dim=1, keepdim=True))
print(np.sum(b))
print(np.sum(b, axis=0))
print(np.sum(b, axis=1))
print(np.sum(b, axis=1, keepdims=True))
print(sum(c))
print(sum(c, 1))
print(sum(c, 2))
结果
tensor(21)
tensor([5, 7, 9])
tensor([ 6, 15])
tensor([[ 6],
[15]])
21
[5 7 9]
[ 6 15]
[[ 6]
[15]]
21
22
233.torch.mul(a, b)
矩阵a和b对应位相乘,a和b的维度必须相等,比如a的维度是(1, 2),b的维度是(1, 2),返回的仍是(1, 2)的矩阵;
(1条消息) Pytorch矩阵乘法之torch.mul() 、 torch.mm() 及torch.matmul()的区别_irober的博客-CSDN博客
a = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(a[:, :])#获取矩阵的全部值
l_x = a[:, :].mul(a[:, :])#矩阵对应位相乘
print(l_x)
结果
tensor([[1, 2, 3],
[4, 5, 6]])
tensor([[ 1, 4, 9],
[16, 25, 36]])4.torch.zeros()
返回一个由标量值0填充的张量
>>> torch.zeros(2, 3)
tensor([[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> torch.zeros(5)
tensor([ 0., 0., 0., 0., 0.])5.torch.device()
代表将torch.tensor分配到的设备的对象(简单点说,就是分配到你的CPU还是GPU上,以及哪块GPU上)
6.lambda
函数的简化,可以直接赋给变量并调用
细说Python的lambda函数用法,建议收藏 - 知乎 (zhihu.com)
import torch
c=lambda x,y,z:x*y*z
print(c(2,3,4))
结果
247.torch.utils.data.DataLoader()
将数据加载到模型
(2条消息) PyTorch学习笔记(6)——DataLoader源代码剖析_sooner高的博客-CSDN博客_woker_init_fn
8.Tensorboard:SummaryWriter类
可以看训练过程中loss的变化。之前用于Tensorflow框架,自Pytorch1.1之后,Pytorch也加了这个功能
writer1=SummaryWriter('runs/exp')#将loss值存储到此路径中Pytorch深度学习实战教程(四):必知必会的炼丹法宝 - 知乎 (zhihu.com)
9.torch.optim.SGD()
随机梯度下降算法,parameters为待优化参数的iterable(w和b的迭代),lr为学习率
optim.SGD(pnet.parameters(), lr=opt.lr, momentum=opt.momentum)(3条消息) torch.optim.SGD()_echo_gou的博客-CSDN博客_torch.optim.sgd
10.torch.optim.lr_scheduler
torch.optim.lr_scheduler模块提供了一些根据epoch训练次数来调整学习率(learning rate)的方法。一般情况下我们会设置随着epoch的增大而逐渐减小学习率从而达到更好的训练效果。
常见的调整策略:
史上最全学习率调整策略lr_scheduler - cwpeng - 博客园 (cnblogs.com)