目录
Nginx 性能调优
零拷贝(Zero Copy)
零拷贝基础
A、 实现细节
B、 总结
零拷贝方式
A、 实现细节
B、 总结
A、 实现细节
B、 总结
A、 实现细节
B、 总结
-
Nginx 性能调优
在 Nginx 性能调优中,有两个非常重要的理论点(面试点)需要掌握。所以,下面首先讲解这两个知识点,再进行性能调优的配置。
-
-
-
零拷贝(Zero Copy)
-
-
-
零拷贝基础
零拷贝指的是,从一个存储区域到另一个存储区域的 copy 任务没有CPU 参与。零拷贝通常用于网络文件传输,以减少 CPU 消耗和内存带宽占用,减少用户空间与 CPU 内核空间的拷贝过程,减少用户上下文与 CPU 内核上下文间的切换,提高系统效率。
用户空间指的是用户可操作的内存缓存区域,CPU 内核空间是指仅 CPU 可以操作的寄存器缓存及内存缓存区域。
用户上下文指的是用户状态环境,CPU 内核上下文指的是 CPU 内核状态环境。
零拷贝需要 DMA 控制器的协助。DMA,Direct Memory Access,直接内存存取,是 CPU
的组成部分,其可以在 CPU 内核(算术逻辑运算器ALU 等)不参与运算的情况下将数据从
一个地址空间拷贝到另一个地址空间。
下面均以“将一个硬盘中的文件通过网络发送出去”的过程为例,来详细详细分析不同拷贝方式的实现细节。
A、 实现细节
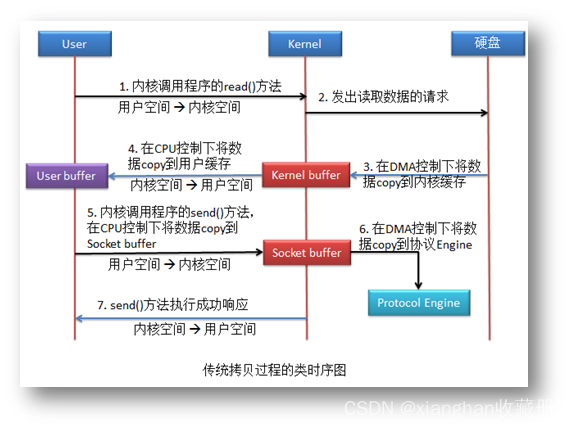
首先通过应用程序的 read()方法将文件从硬盘读取出来,然后再调用 send()方法将文件发送出去。
B、 总结
该拷贝方式共进行了 4 次用户空间与内核空间的上下文切换,以及 4 次数据拷贝,其中两次拷贝存在 CPU 参与。
我们发现一个很明显的问题:应用程序的作用仅仅就是一个数据传输的中介,最后将
kernel buffer 中的数据传递到了 socket buffer。显然这是没有必要的。所以就引入了零拷贝。
A、 实现细节
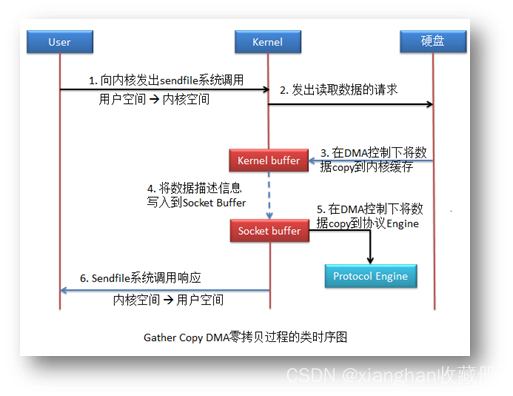
Linux 系统(CentOS6 及其以上版本)对于零拷贝是通过 sendfile 系统调用实现的。
B、 总结
该拷贝方式共进行了 2 次用户空间与内核空间的上下文切换,以及 3 次数据拷贝,但整个拷贝过程均没有 CPU 的参与,这就是零拷贝。
我们发现这里还存在一个问题:kernel buffer 到 socket buffer 的拷贝需要吗?kernel buffer 与 socket buffer 有什么区别呢?DMA 控制器所控制的拷贝过程有一个要求,数据在源头的存放地址空间必须是连续的。kernel buffer 中的数据无法保证其连续性,所以需要将数据再拷贝到 socket buffer,socket buffer 可以保证了数据的连续性。
这个拷贝过程能否避免呢?可以,只要主机的 DMA 支持Gather Copy 功能,就可以避免由 kernel buffer 到 socket buffer 的拷贝。
由于该拷贝方式是由 DMA 完成,与系统无关,所以只要保证系统支持 sendfile 系统调用功能即可。
A、 实现细节
该方式中没有数据拷贝到 socket buffer。取而代之的是只是将 kernel buffer 中的数据描述信息写到了 socket buffer 中。数据描述信息包含了两方面的信息:kernel buffer 中数据的地址及偏移量。
B、 总结
该拷贝方式共进行了 2 次用户空间与内核空间的上下文切换,以及 2 次数据拷贝,并且整个拷贝过程均没有 CPU 的参与。
该拷贝方式的系统效率是高了,但与传统相比,也存在有不足。传统拷贝中user buffer 中存有数据,因此应用程序能够对数据进行修改等操作;零拷贝中的 user buffer 中没有了数据,所以应用程序无法对数据进行操作了。Linux 的mmap 零拷贝解决了这个问题。
mmap 零拷贝是对零拷贝的改进。当然,若当前主机的 DMA 支持 Gather Copy,mmap
同样可以实现Gather Copy DMA 的零拷贝。
A、 实现细节
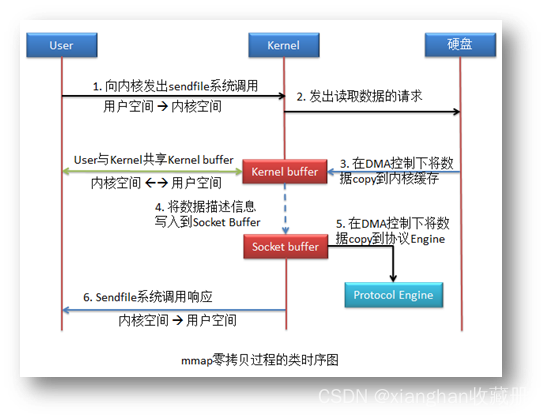
该方式与零拷贝的唯一区别是,应用程序与内核共享了 Kernel buffer。由于是共享,所以应用程序也就可以操作该 buffer 了。当然,应用程序对于 Kernel buffer 的操作,就会引发
用户空间与内核空间的相互切换。
B、 总结
该拷贝方式共进行了 4 次用户空间与内核空间的上下文切换,以及 2 次数据拷贝,并且整个拷贝过程均没有 CPU 的参与。虽然较之前面的零拷贝增加了两次上下文切换,但应用程序可以对数据进行修改了。