✨ 原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力! \textcolor{green}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向! \textcolor{green}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! \textcolor{green}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!
项目效果图:

YOLOv5
- 一、YOLOv5介绍
- 二、模型详解
- 2.1 Input
- 2.2 Backbone
- 2.3 Neck
- 2.4 Prediction
- 三、项目意义
- 四、检测效果
- 五、数据集获取
- 六、模型训练效果
- 七、总结
一、YOLOv5介绍
YOLO(You Only Look Once) 是REDMON等提出的目标检测算法,作为单阶段(one-stage)的代表算法,目前 YOLO已经更新到了YOLOv5。相比于Two stage目标检测算法,YOLO是直接从网络中提取特征,并预测物体的类别和具体位置,一步到位。
此后,REDMON在此基础上提出了YOLO9000等检测算法,使系统的检测性能得到进一步提升。在YOLOv3的基础上继续改进升级,并最终得到 YOLOv4。YOLOv4网络结构主要由CSPDarknet53特征提取网、SPP(空间金字塔池化)模块、PANet特征融合模块、Yolo Head分类器组成。
YOLOv5算法使用CSPDarknet(跨阶段局部网络)作为特征提取网络,从输入图像中提取目标信息。如今,YOLOv5无论是在准确率还是速度上,都已经达到较好的效果。所以,本项目采用YOLOv5训练模型,结合YOLOv5算法构建火灾检测系统。
二、模型详解
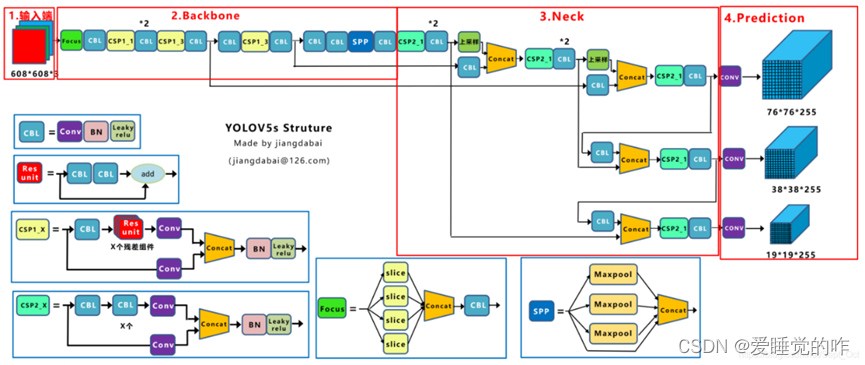 上图是yolov5s的网络结构,它是yolov5系列中深度最小、特征图宽度最小的网络。后面的m、l、x都是在此基础上不断加深、加宽的。网络主要分为输入端、Backbone、Neck、Prediction四个部分。它和yolov3主要不同的地方:
上图是yolov5s的网络结构,它是yolov5系列中深度最小、特征图宽度最小的网络。后面的m、l、x都是在此基础上不断加深、加宽的。网络主要分为输入端、Backbone、Neck、Prediction四个部分。它和yolov3主要不同的地方:
- 输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
- Backbone:Focus结构、CSP结构
- Neck:FPN+PAN结构
- Prediction:GIOU_Loss
YOLOv5 模型在输入端(Input)增加了 Mosaic 数据增强、自适应锚框计算、自适应图片缩放等数据预处理技巧来增强数据,防止过拟合;在特征提取网络部分(Backbone)引入了Focus 模块、跨阶段局部融合网络(CrossStage Partial Network, CSPNet)等方法,在减少了计算量的同时可以保证准确率,使特征能够更好的向后传递。下图为cspnet 结构图:
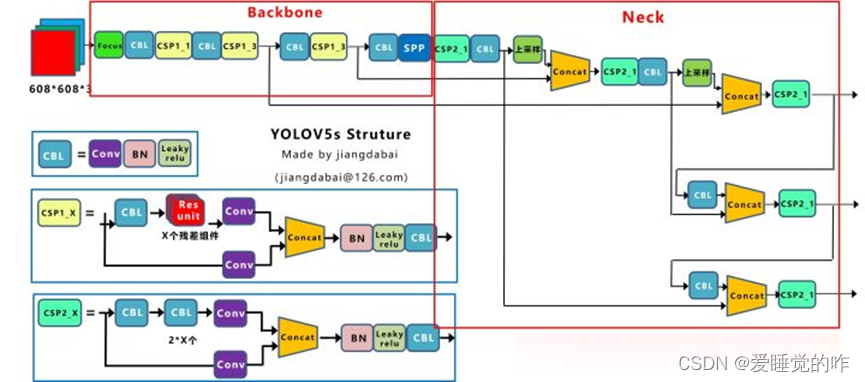
CSPNet主要目的就是缓解以前需要大量推理计算的问题,它有以下优点:
- 增强了CNN的学习能力,能够在轻量化的同时保持准确性。
- 降低计算瓶颈。
- 降低内存成本。
- CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。
CSPNet和PRN都是一个思想,将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。在特征融合部分(Neck)借鉴了空间金字塔池化(Spatial Pyramid Pooling, SPP)、特征金字塔(Feature Pyramid Networks, FPN)与路径聚合网络(PathAggregation Network, PAN)等方法,有效的增加主干特征的接收范围,融合后的特征保留了丰富的语义特征和精准的定位特征;同时在预测部分(Prediction)采用了新的定位损失函数,确保定位的精准。通过引入各种高效的网络组件,使得YOLOv5 模型在保持实时目标检测速度的基础上,也实现了精度上SOTA。
2.1 Input
Input 使用了 Mosaic 数据增强、自适应锚框计算、图片尺寸处理。Mosaic 数据增强把 4 张图片,采用随机缩放、随机裁剪、随机排布的方式进行拼接 , 极大地丰富了检测数据集,同时也能提高小目标检测的精度,除此以外,Mosaic数据增强在训练时可一次性对 4 张图片的数据进行计算,降低了 mini-batch 的大小,也减少了 GPU 的使用。YOLOv5 将自适应锚框计算嵌入代码中,通过在初始设定的锚框上输出预测框,然后和真实标签进行比对,计算损失函数,再不断更新,更新锚点框的大小,实现自适应计算并得出最佳锚框值。图片尺寸处理是对输入的各种图片的尺寸进行自适应填充处理,为了提高目标检测的速度,采用了减少灰度边缘的方法。
2.2 Backbone
Backbone 是 YOLOv5 网络的主干部分,包含 Focus 结构、CSP 结构和 SPP 结构。其 中 Focus 结 构: 主 要 进 行 切 片 操 作, 只 存 在 于YOLOv5 算法中,以 YOLOv5s 为例,将原始三通道图像输入 Focus 结构,经过切片操作后,进行拼接,图片尺寸缩小到原来的 1/4、输入通道扩充到原来的 4 倍,经过 32 个卷积核的卷积计算,最终得到含有 32 个通道的特征图。YOLOv5s、YOLOv5m、YOLOv5x 和 YOLOv5l, 使 用 的 卷积核数量依次增加,其中,YOLOv5m 使用了 48 个卷积核。卷积核个数越多 , 特征图的宽度越宽 , 网络提取特征的学习能力也越强。开发者认为,Focus 模块的设计目的是减少层数并降低计算量。
- CSP 结构:YOLOv5 中设计了 CSP1_N 和 CSP2_N 两种CSP 结构,CSP1_N 应用于 Backbone 作为主干网络,CSP2_N 应用在 Neck 中,这部分没有残差组件。CSP1_N 结构将基础层的特征映射划分为两个不同的部分,其中之一就是将 N个残差组件进行卷积操作,另一部分则是直接进行卷积操作,两次卷积操作可以使通道数减半,然后通过拼接来进行输出。
- SPP 结构:在 Backbone 中,采用 SPP(空间向量金字塔
池化)。多尺度融合是通过最大化池来实现的。
2.3 Neck
Neck 采用 FPN+PAN 的结构。FPN 结构是自上向下传递强特征,对结构起到增强的作用,然而,FPN 只能增强语义信息,而不能传递位置信息。而 PAN 结构刚好弥补了 FPN结构不能进行定位信息传递的缺陷,PAN 结构自下向上将低层的强定位特征传递上去,两者结合操作,增强网络特征融合的能力。
2.4 Prediction
本文中 Yolov5 采用 GIOU_Loss 作 Bounding box 的损失函数GIOU_Loss 能够区分重叠的预测框和目标框在 IOU 相同时两者相交情况的不同。另外,针对预测过程中会出现多个预测框的情况,需要通过非极大值抑制即 NMS 来处理,Yolov5 使用加权 NMS 来筛选最佳的预测框
三、项目意义
火灾作为威胁人类生命生产安全的隐患之一,一直是人们关注的重点。传统的火灾监测装置根据温度来检测火灾,不仅灵敏度差,而且反馈时间长,常常会出现消防员收到警报消息时,火室已经无法控制。本文由树莓派、Opencv和蜂鸣器设计了一套火灾检测装置,能够对火灾进行实时灵敏检测,适用于地下停车场、居民楼道、商场等多种场景。
四、检测效果

五、数据集获取
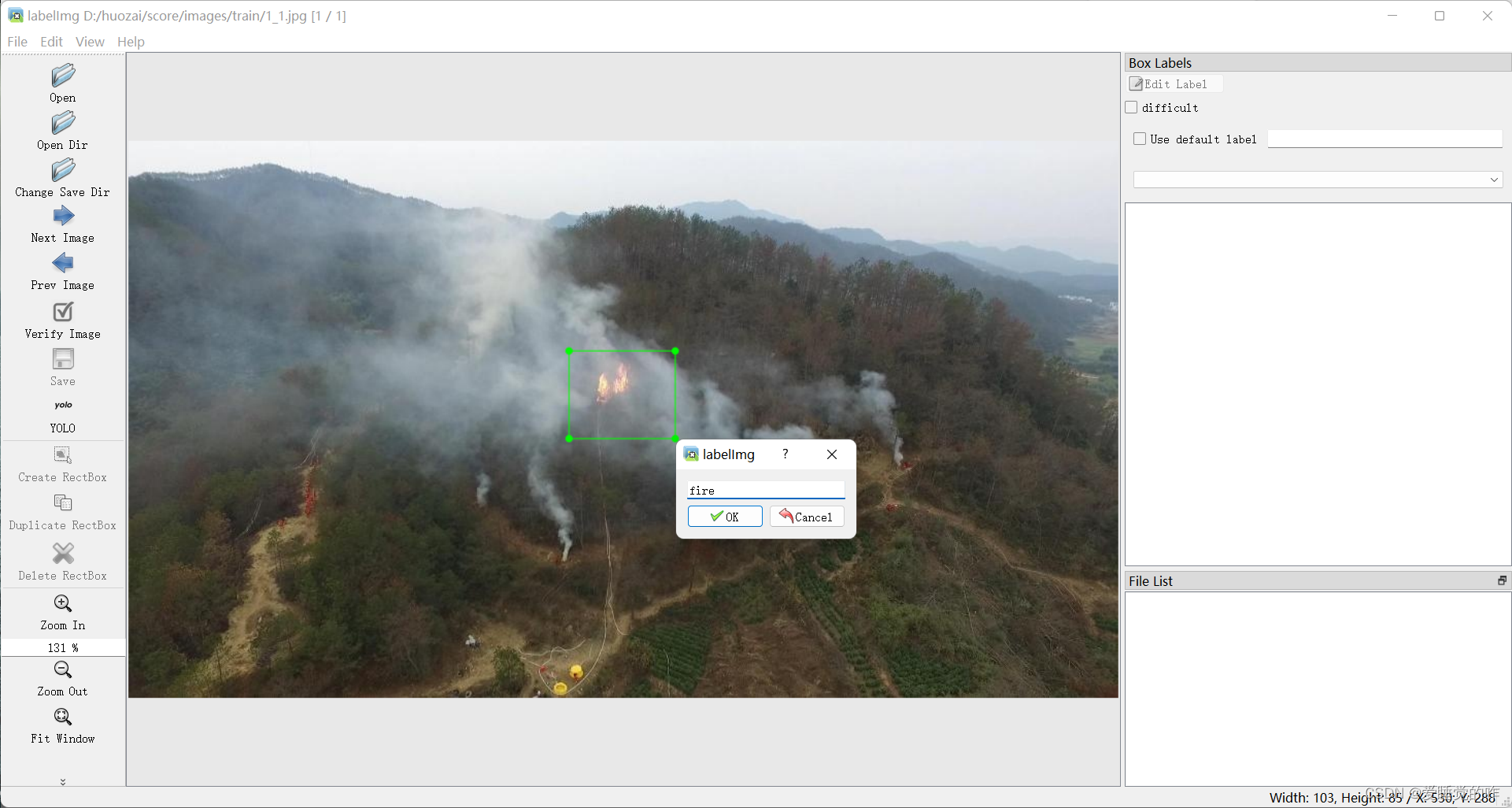
通过labelImg 标注工具对数据集图像进行标注,并保存为YOLO 系列的 txt 格式。可以在你的虚拟环境中进入labelImg,这是他的界面。左侧open Dir可以打开数据集的文件夹,Change Save Dir是你的保存路径,Next和Prev Image分别是上一张和下一张图片。重点来了:Create RectBox绘制一个矩形框将你需要框选的对象框选出来,并添加标签。这里不懂的同学可以看我之前有一篇很详细的教程链接: Yolov5:强大到你难以想象──新冠疫情下的口罩检测
通过对数据进行乱序排列,随机选出训练集 1442 张,测试集共617 张,验证集共 617 张。通过上千张火灾的图片进行机器学习的训练,对于微小火焰也有这不错的检测效果。数据集的下载地址我贴在这里了:链接:https://pan.baidu.com/s/1ry7o3oJfyHM5rw4nkXL14A?pwd=f5xp
提取码:f5xp
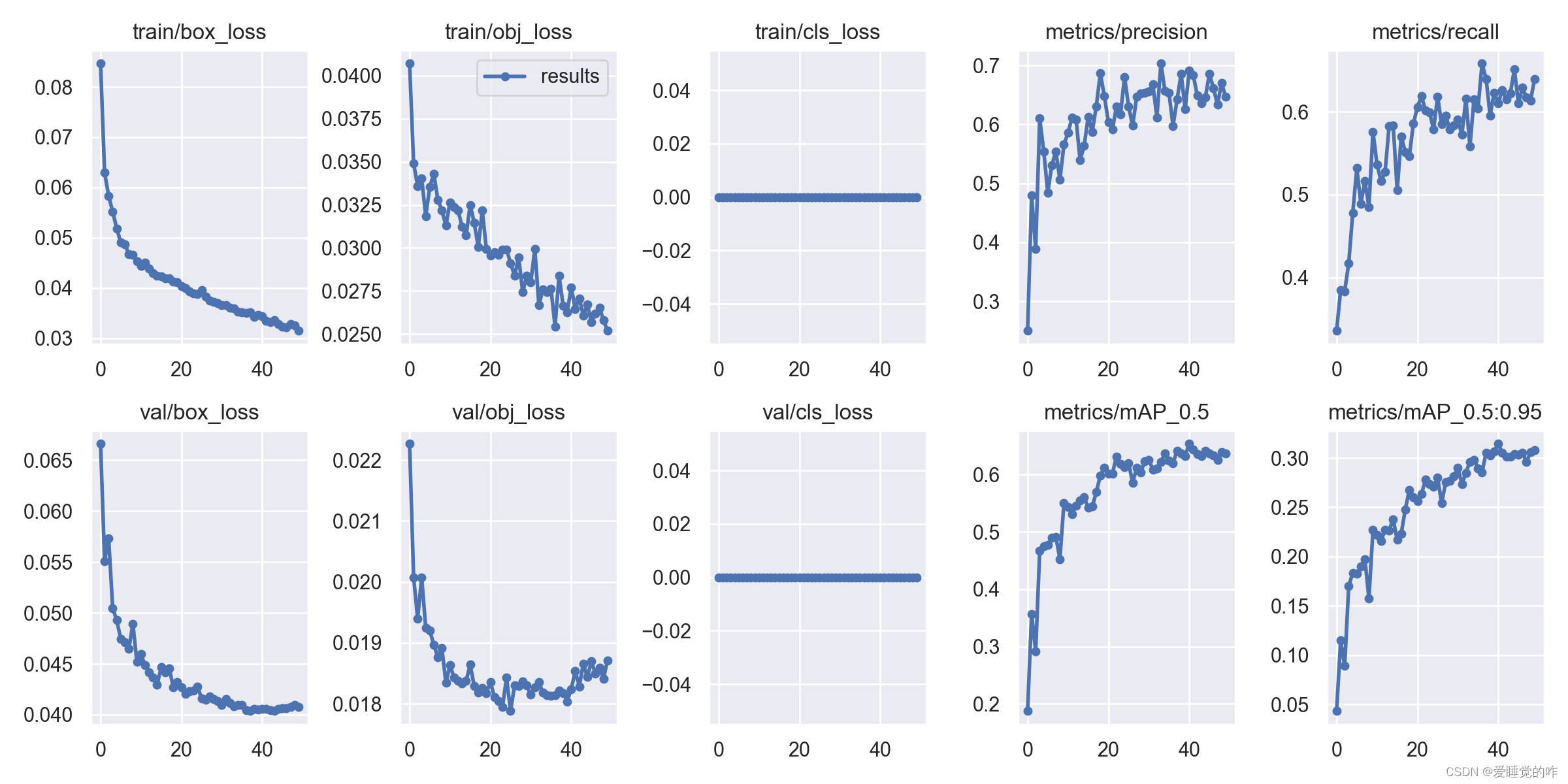
六、模型训练效果
七、总结
由于大多数设备、算法的实时性较差或检测精确度偏低,而YOLOv5 检测算法拥有轻量级的模型和优良的性能,针对于此,本项目基于 YOLOv5 算法, 着重解决的问题是如何实现准确快速地检测火灾,以减小在复杂环境中的误检率,并提高检测精确率和实时性。
✨ 原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力! \textcolor{green}{点赞,你的认可是我创作的动力!} 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向! \textcolor{green}{收藏,你的青睐是我努力的方向!} 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! \textcolor{green}{评论,你的意见是我进步的财富!} 评论,你的意见是我进步的财富!