文章目录
- 前言
- 一.表中插入数据
- 1.1 全列增加
- 1.2 指定列增加
- 1.3 一次性插入多行数据
- 1.4. 插入查询结果
- 二.表的更新和替换
- 2.1. 表的插入更新
- 2.2. 替换
- 三.表的查询
- 3.1. 全列查询
- 3.2. 指定列查询
- 3.3. 查询字段为表达式并取别名
- 3.4. 结果去重
- 3.4. where条件
- 3.5. 结果排序
- 3.6. 分页查询
- 四.表的更新(改)
- 五.删除表中的数据
- **六.插入查询结果**
- **七.聚合函数**
- 八.group by子句的使用
- **关于having:**
前言
之前的对数据表的操作主要是进行列的增删查改,增删查改:CRUD, 即增加-Create 查询-Retrieve 更新-Update 删除-Delete四个单词的首字母缩写
面试题:SQL查询中各个关键字的执行先后顺序
from > on> join > where > group by > with > having > select > distinct > order by > limit
下面我们学到的具体语句的执行顺序为:from子句>where 子句>group by 子句>having 子句>select 子句>order by 子句
- 对于我们自己对列起的别名:后面子句的别名不能在前面的子句使用.
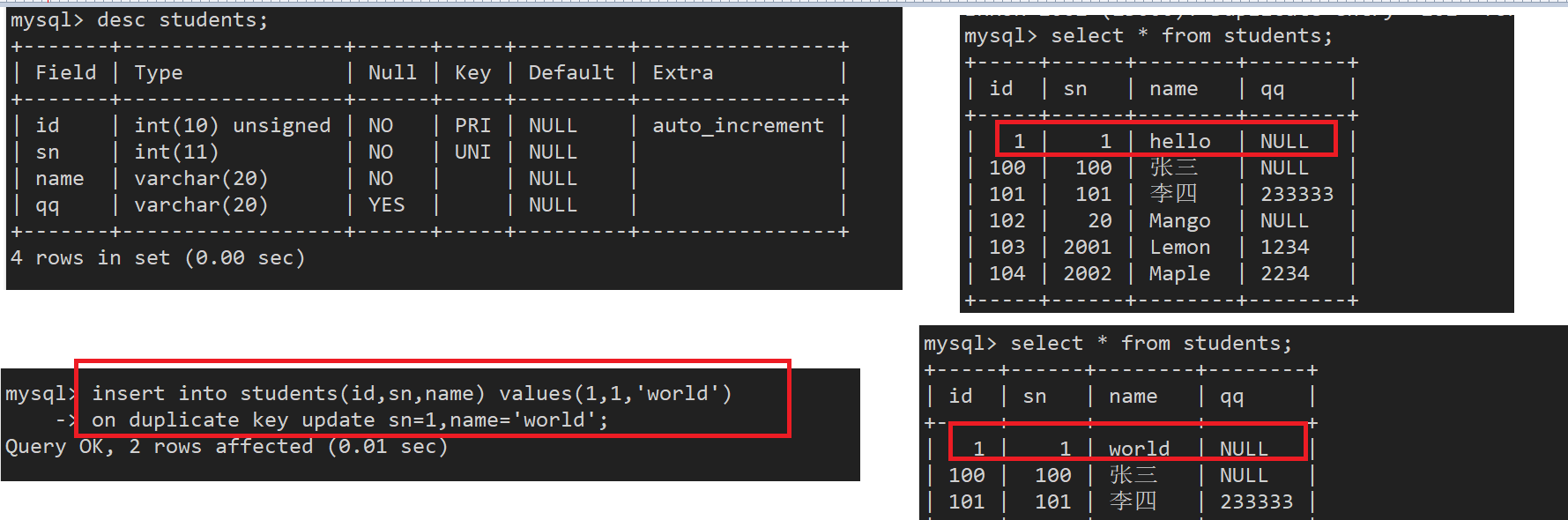
案例:创建一张学生表:
mysql> create table students(
-> id int unsigned primary key auto_increment,
-> sn int not null unique comment '学号',
-> name varchar(20) not null,
-> qq varchar(20)
-> );
一.表中插入数据
1.1 全列增加
insert into [表名称] values(表字段对应的值);
例子:插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
注意,这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认的值进行自增
insert into students (id,sn,name,qq) values(100,100,'张三',null);
insert into students values(101,101,'李四',233333); #全列插入可以不指定列
1.2 指定列增加
insert into[表名称] (表中列的名称,...) values(指定表字段对应的值...);
例子:
insert into students (sn,name) values(20,'Mango');
1.3 一次性插入多行数据
insert into[表名称] (表中列的名称,...) values(指定表字段对应的值...),(指定表字段对应的值...);
#可以简写为:
insert into [表名称] values(表字段对应的值),(表字段对应的值); #但是必须是全列增加
例子:
mysql> insert into students (sn,name,qq) values
-> (2001,'Lemon',1234),
-> (2002,'Maple',2234);
1.4. 插入查询结果
select * from 表名;
当然也可以将一个表的查询结果插入到另一个表中.
二.表的更新和替换
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败,此时可以使用更新或者替换来进行解决
例子:

2.1. 表的插入更新
主键或者唯一键具有唯一性,可能会导致我们后续插入数据失败的问题.“插入否则更新”意思是如果插入成功就插入,如果失败就是更新.
如果表中数据的主键/唯一键不存在冲突则插入,存在冲突则修改原内容
insert into 表名 (列名称) values(指定表字段对应的值) on duplicate key updata 更新的列=字段内容
行受影响
- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
- 1 row affected: 表中没有冲突数据,数据被插入
- 2 row affected: 表中有冲突数据,并且数据已经被更新
通过 MySQL 函数获取受到影响的数据行数: select row_count()
例子:
ON DUPLICATE KEY 当发生重复key的时候
2.2. 替换
replace into 和 insert into的用法是类似的
replace into `表名 (列名称) values(指定表字段对应的值);
- insert每次插入一条新的数据
- 主键 或者 唯一键 没有冲突,则直接插入;
- 主键 或者 唯一键 如果冲突,则删除后再插入;
需要注意的是:replace根据表中的主键或唯一键来判断,如果表中没有主键或唯一索引,那么replace into 就相当于 insert into,会直接插入一条数据.
行受影响
- 1 row affected: 表中没有冲突数据,数据被插入
- 2 row affected: 表中有冲突数据,删除后重新插入
例子:
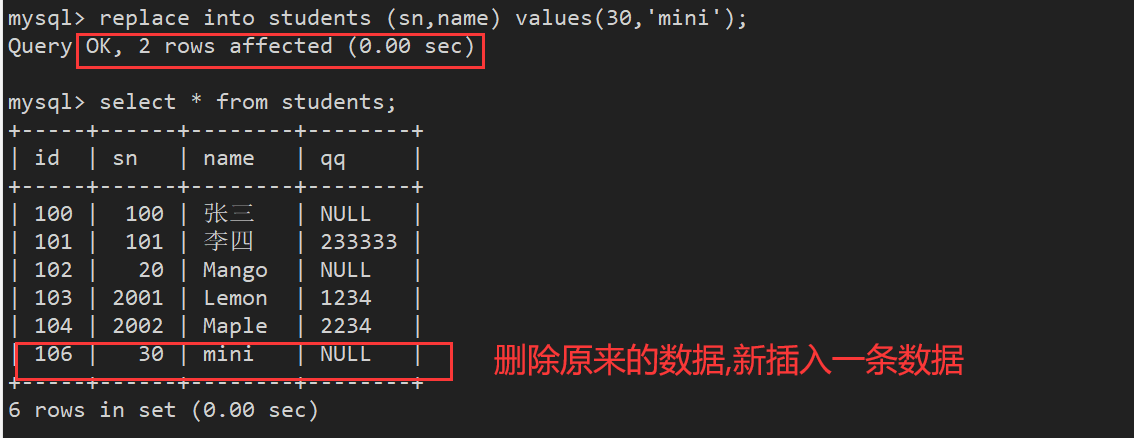
三.表的查询
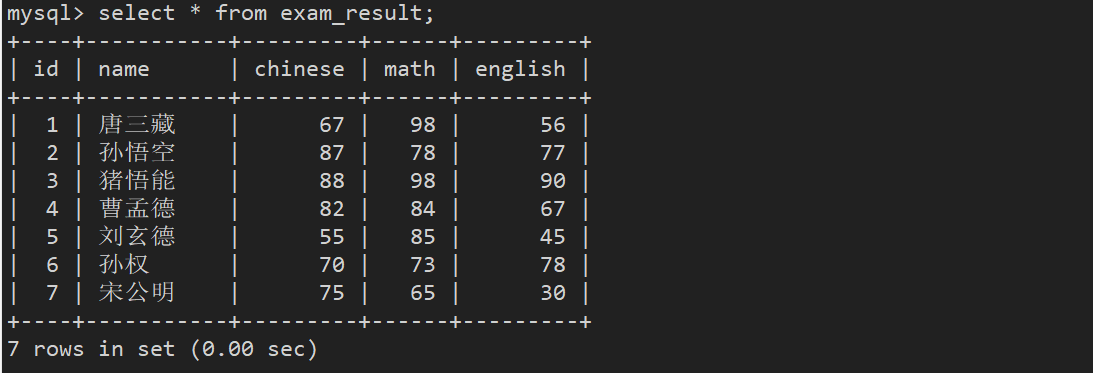
案例:
#创建表结构
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '同学姓名',
chinese float DEFAULT 0.0 COMMENT '语文成绩',
math float DEFAULT 0.0 COMMENT '数学成绩',
english float DEFAULT 0.0 COMMENT '英语成绩'
);
-- 插入测试数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);
3.1. 全列查询
select * from 表名;
* 表示当前表的所有列,对于字段比较少,并且插入数据比较少的表,可以使用全列查询,查询的效率不会收到太大影响 如果一个表中字段比较多,或者数据量比较大,则全列查询会导致查询效率降.可能会影响到索引的使用
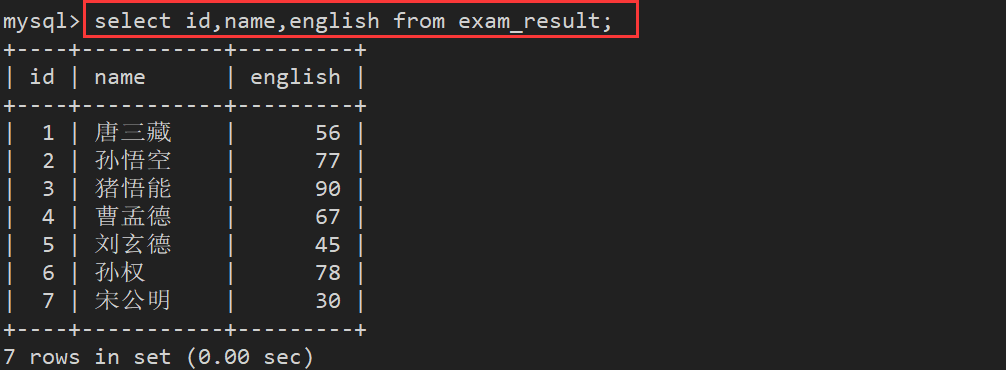
3.2. 指定列查询
- 指定列的顺序不需要按定义表的顺序来
select 字段名称,... from 表名;
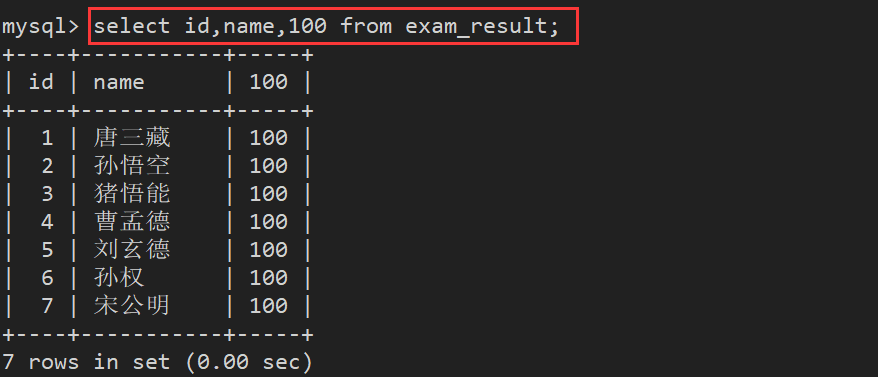
3.3. 查询字段为表达式并取别名
注意:这里的操作只是将查询结果进行操作,并不会改变表中的数据
select 字段名称, ... ,字段名称 表达式 as 别名 from 表名;
表达式中不包含字段
表达式包含一个字段
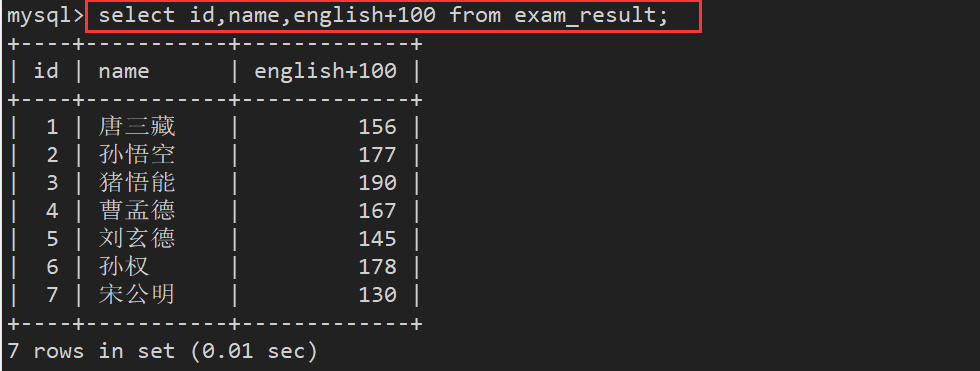
表达式包含多个字段:
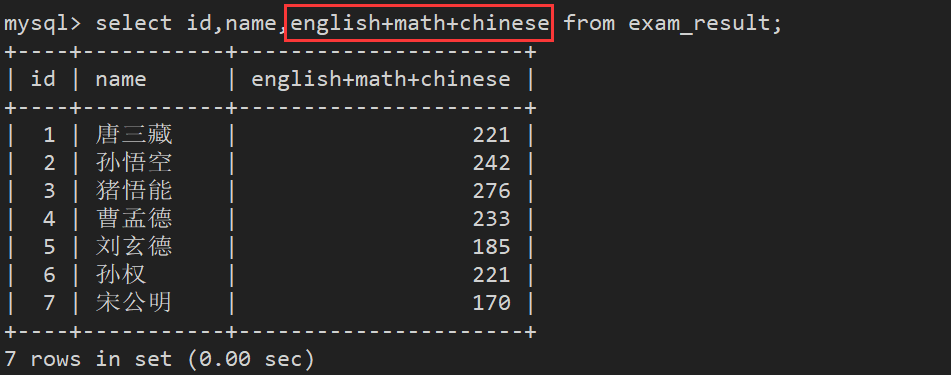
可以为查询结果指定一个别名 (as可以省略)
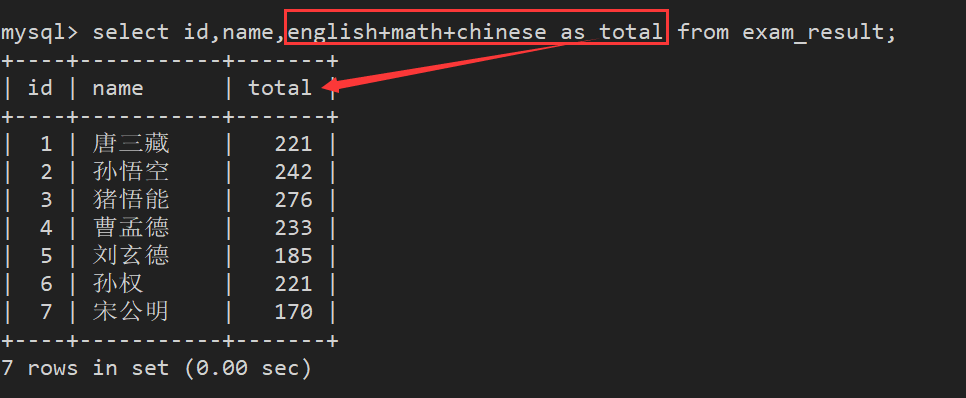
3.4. 结果去重
加上关键字**distinct**进行查询.
select distinct 字段名称 ,... from `tb_name`;
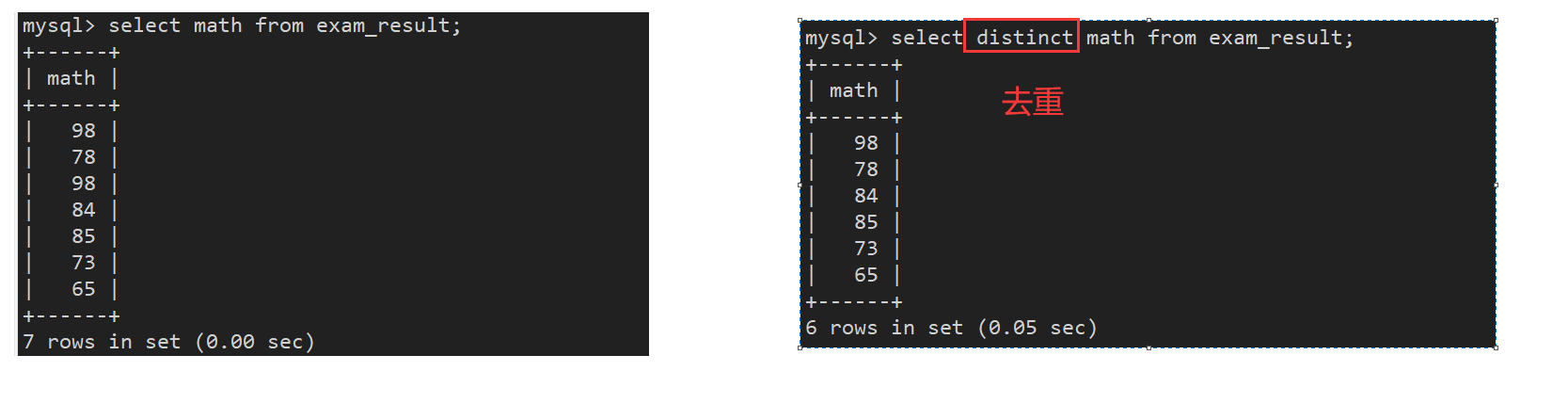
是否重复只能对显示出来的整条记录而言,当所有字段都重复才算重复
3.4. where条件
比较运算符:
| 运算符 | 说明 |
|---|---|
| <, <= ,>,>=, | 小于,小于等于,大于,大于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE 模糊匹配 | % 表示任意多个(包括 0 个)任意字符 _ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
- 如果要以是否为NULL作为判断条件的话,更推荐使用
is null和is not null - 为了更贴合C/C++编程习惯,判断等于就用 =,不等于就用 !=
注意:在select中取的别名不能出现在where条件中.因为查找的时候,是先根据条件(where后面的条件)找的,即查找的时候是先看到条件,根据条件找到内容后,再根据select后面的语句进行显示某一列.所以在查找的时候并不知道别名
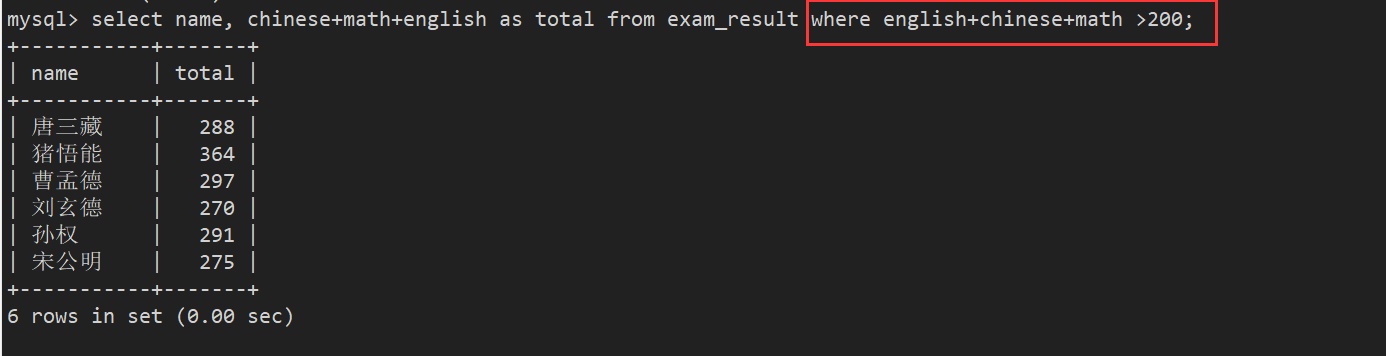
例子:选出总分<200的人

报错的原因是:我们起的别名不认识,where子句是在select子句表达式之前执行,所以起别名是在使用了这个别名之后才有的,所以在 用where查询的时候,根本没有这个别名,起别名是在筛选之后才进行的, 先有筛选条件,把数据拿出来, 然后才有计算
- 先按照条件筛选数据 然后按照要求对数据处理
筛选数据的时候,from先执行,因为要知道从哪里拿数据, 然后where再起作用,根据条件在这个表里筛选数据, 然后再是select,决定我们要取哪些数据
问:为什么order by可以取别名呢?
你要排序,前提是已经根据条件将数据全部筛选完了,所以进行order by的时候,select已经执行完了,所以认识select起的别名
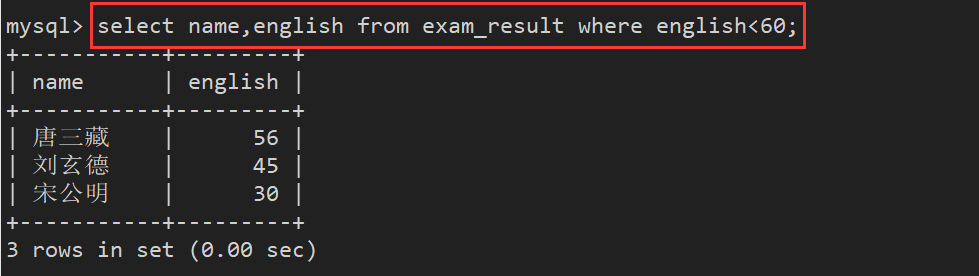
案例1: 查找英语不及格的同学 -> 即查找英语成绩<60的同学
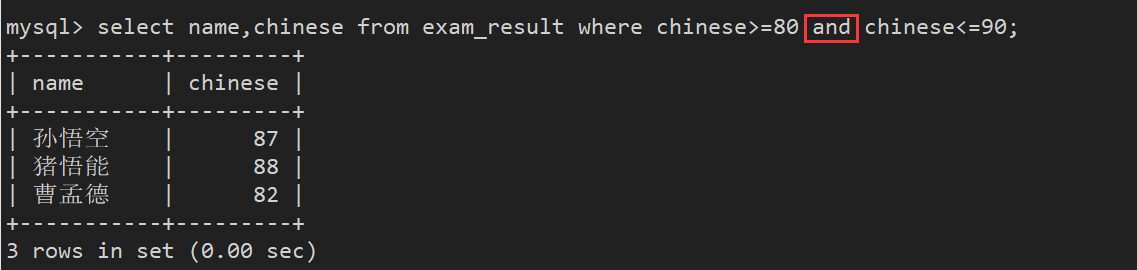
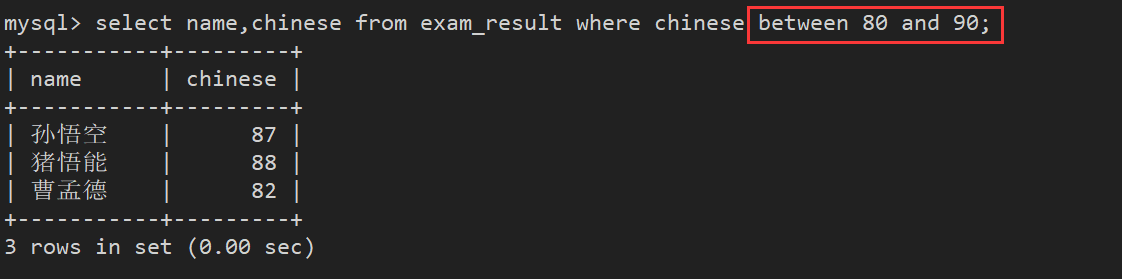
案例2:查找语文成绩在 [80, 90] 分的同学
方法1:使用 and进行条件连接
方法2:使用 between ... and ... 进行条件连接
案例3:查找数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
方法1:使用or进行条件连接

方法2:使用in条件
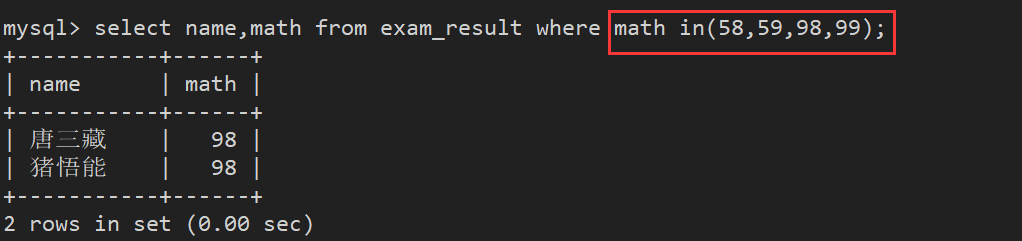
案例4:查询姓孙的同学
此时需要使用模糊匹配, %匹配任意多个(包括0个)任意字符
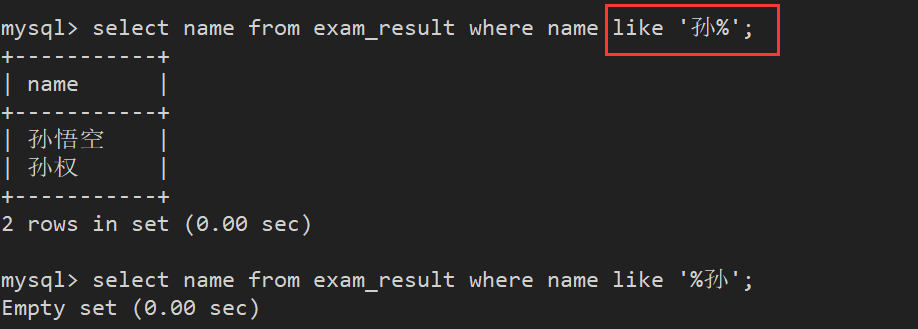
注意:%放前面和放后面是不同的
案例5: 查询孙某同学
此时需要使用模糊匹配, _匹配严格的一个任意字符
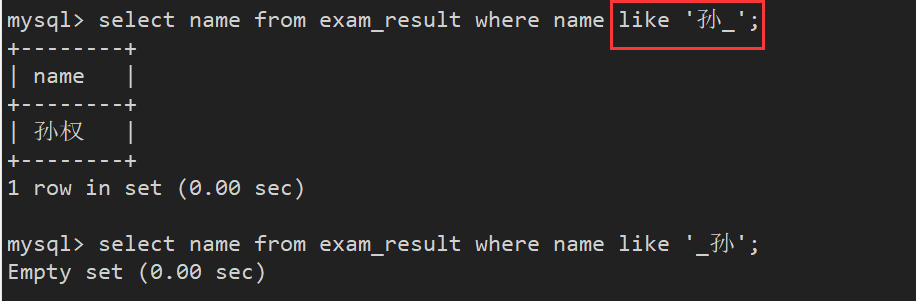
注意: _放前面和放后面是不同的
案例6:语文成绩好于英语成绩的同学
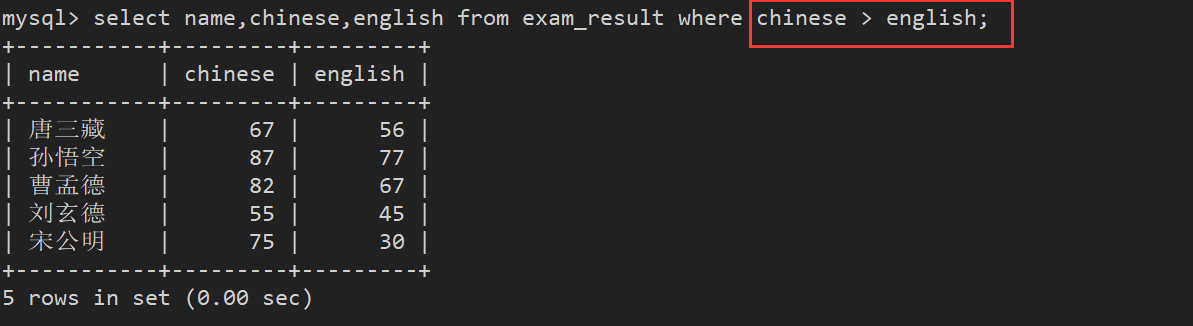
- 注意:此时where条件中,比较运算符的两侧都是字段
案例7:总分在 200 分以下的同学
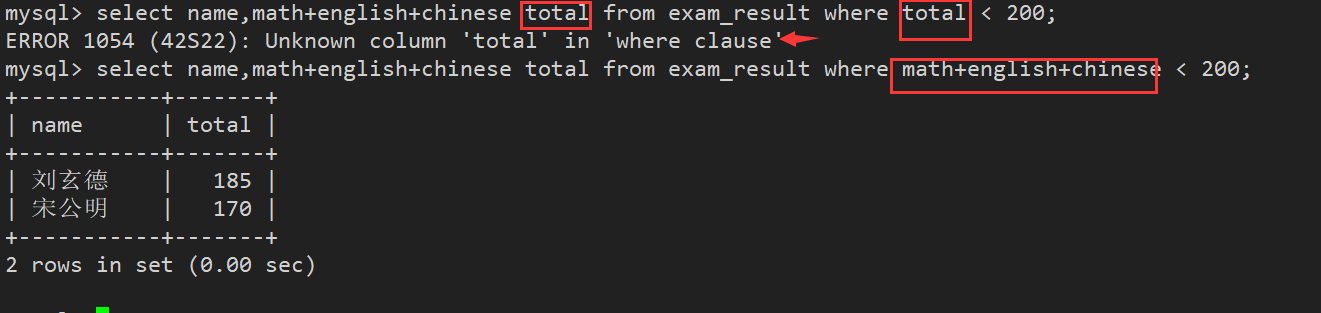
- WHERE 条件中使用表达式 , 别名不能用在 WHERE 条件中
- where后续的字句本身就是在我们select期间要进行作为条件筛选的
- 别名是最终为了展示结果起的别名,已经把数据全筛出来了; where 先于select,此时还不认识这个别名total
案例8: 语文成绩 > 80 并且不姓孙的同学

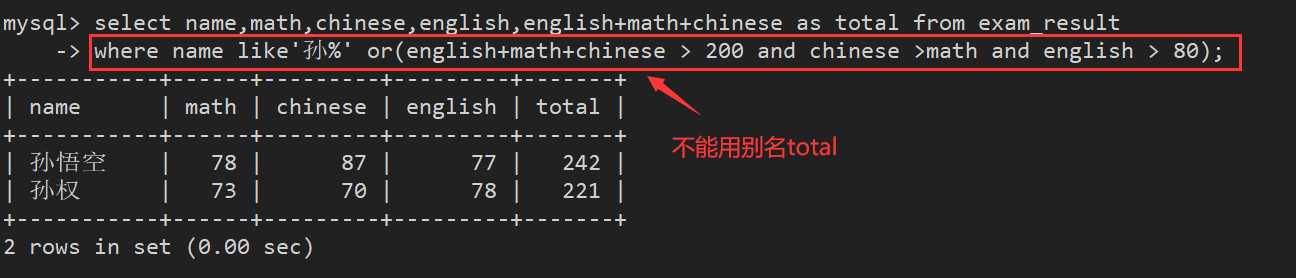
案例9:查找孙某同学,如果不是孙某则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
案例10:关于NULL
1.查询qq号已知的同学姓名
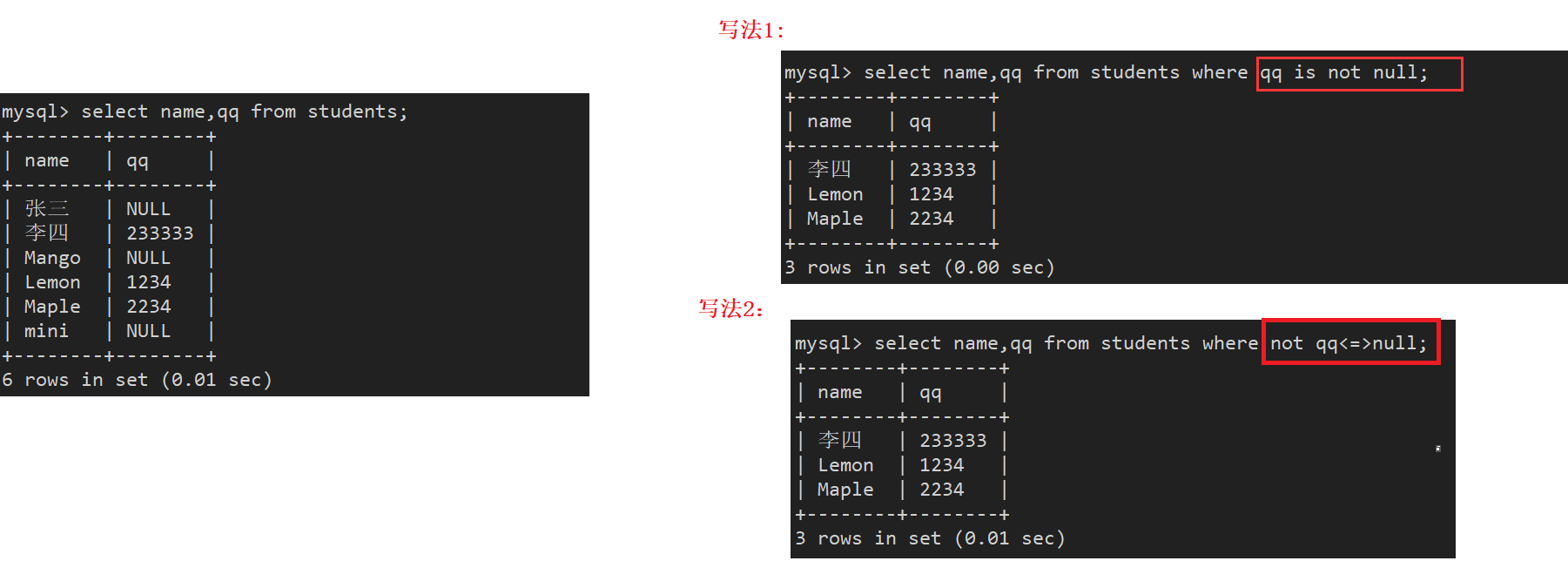
2.NULL和NULL的比较, =和<=>的比较
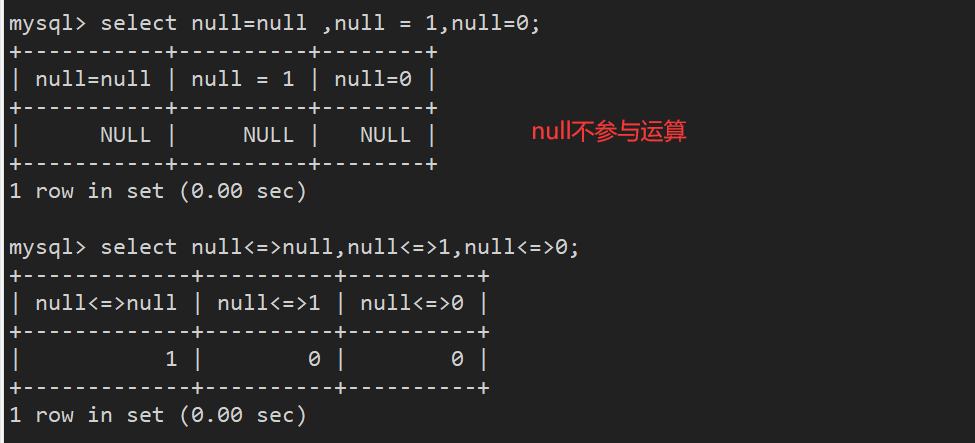
NULL不进行任何的计算,和数值进行运算也是NULL ,除了和数值比较是否相等,才是0和1
3.5. 结果排序
-- ASC 为升序(从小到大) DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...];
# 升序
select `field1`, `field2` [, ...] from `tb_name` order by `field` [asc];
# 降序
select `field1`, `field2` [, ...] from `tb_name` order by `field` desc;
- order by子句中可以使用列别名,注意:没有order by子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
- 默认排升序:ASC 如果想排降序 :DESC
- NULL 视为比任何值都小,降序出现在最下面,升序出现在最上面
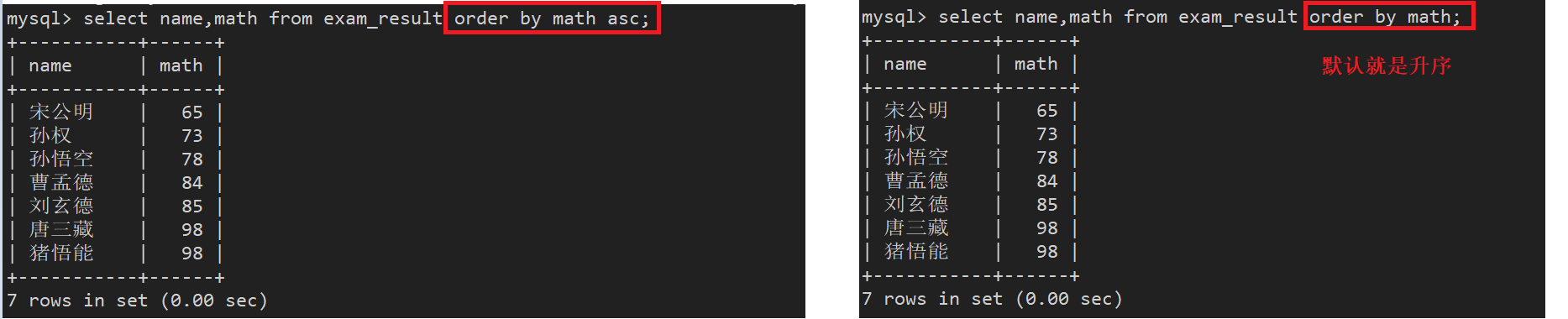
案例1: 显示同学及数学成绩,按数学成绩升序显示
案例2:显示同学及 qq 号,按 qq 号排序显示
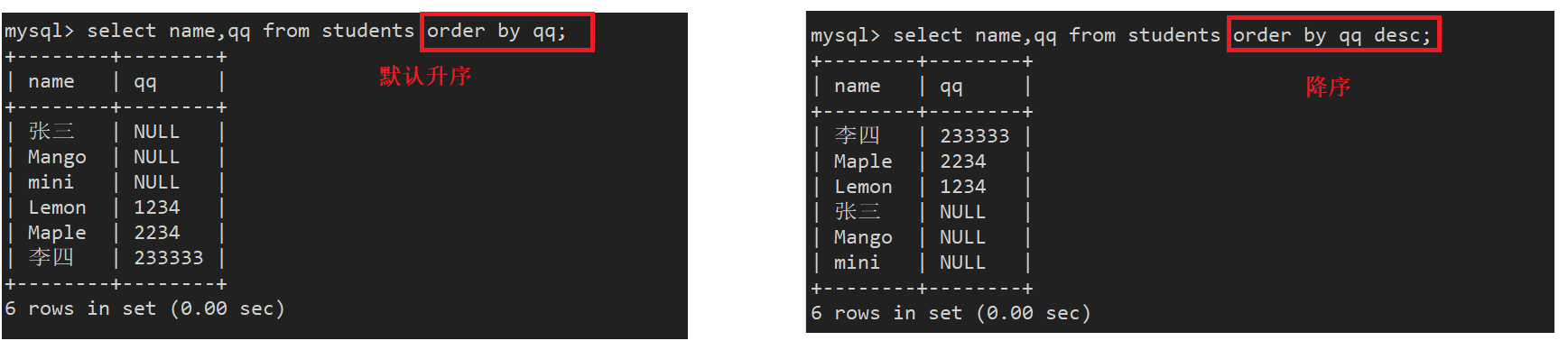
NULL 视为比任何值都小,升序出现在最上面,降序出现在最下面
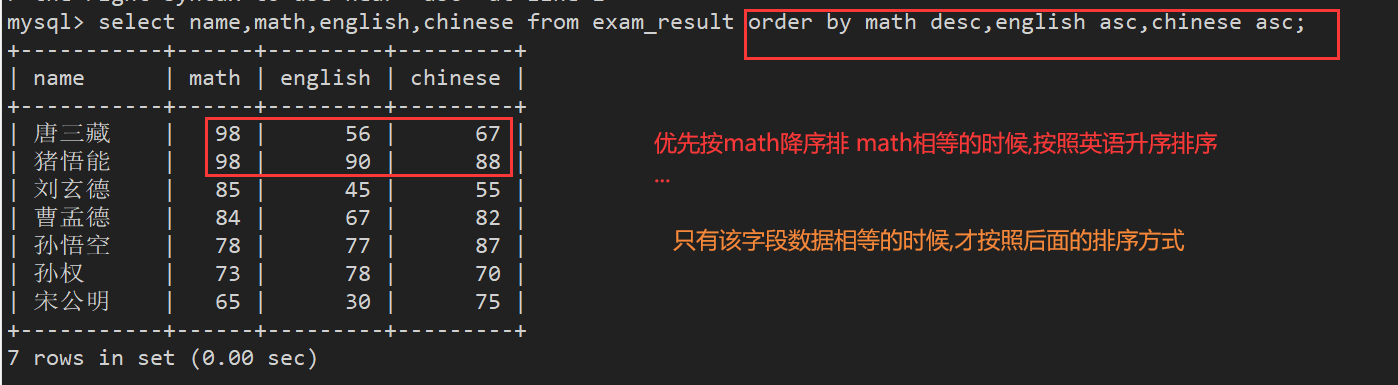
案例3:查询同学各门成绩,依次按数学降序,英语升序,语文升序的方式显示
- 多字段排序,排序优先级随书写顺序
- 只有该字段数据相等才按照后面的排序方式,本质是先根据数学排序,如果值相等,再按后面的排序
案例4:查询同学及总分,由高到低
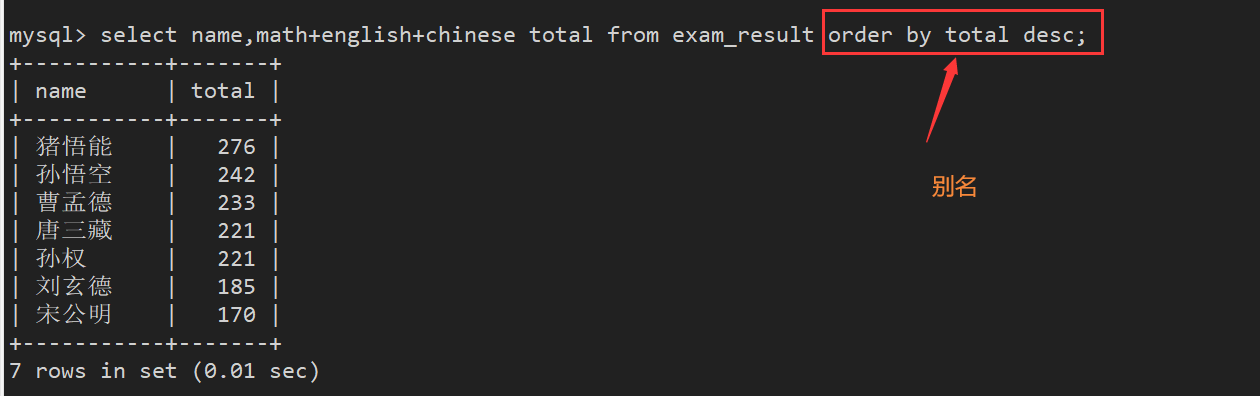
执行顺序: from > where > select > order by , 所以order by子句中可以使用列的别名
- 我们筛选数据,先选择哪个表,然后要用where条件选择出所有的数据,然后才能按照select的要求,进行数据进一步筛选或者计算,上面这些足以支撑拿到所有的数据,然后进行后序的操作,比如:排序
- 要排序,本质是需要先把要排序的数据准备好! 然后才使用order by排序
案例5:查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
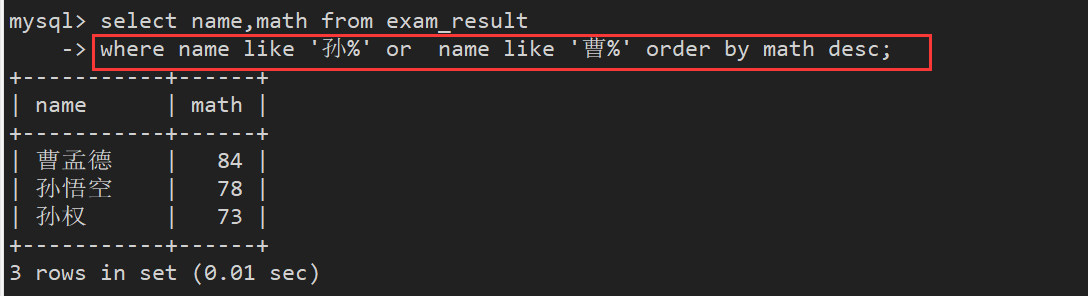
3.6. 分页查询
对未知表进行查询时,最好加一条 limit 1,避免因为表中数据过大,查询全表数据导致数据库卡死
-- 起始下标为 0
-- 从0开始,筛选 n 条结果 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从s开始,筛选 n 条结果 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从s开始,筛选 n 条结果,比第二种用法更明确,建议使用 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
# 从0开始筛选n条记录
select `field` [, ...] from `tb_name` limit `n`;
# 从s行开始筛选n条记录
select `field` [, ...] from `tb_name` limit `s`, `n`;
# 从s行开始筛选n条记录
select `field` [, ...] from `tb_name` limit `n` offset `s`;
limit +数字(表示显示多少行) offset +数字(表示偏移量);`
limit+数字(表示偏移量),数字(表示显示多少行);
当只有一个数字的时候,比如limit 5,上述的显示的都是一样的,即显示前5行
建议:对未知表进行查询时,最好加一条 limit 1,避免因为表中数据过大,查询全表数据导致数据库卡死
limit本质就是数据已经全部有了,然后显示前几行,所以是在所有操作都做完之后才进行limit操作
案例1: 按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
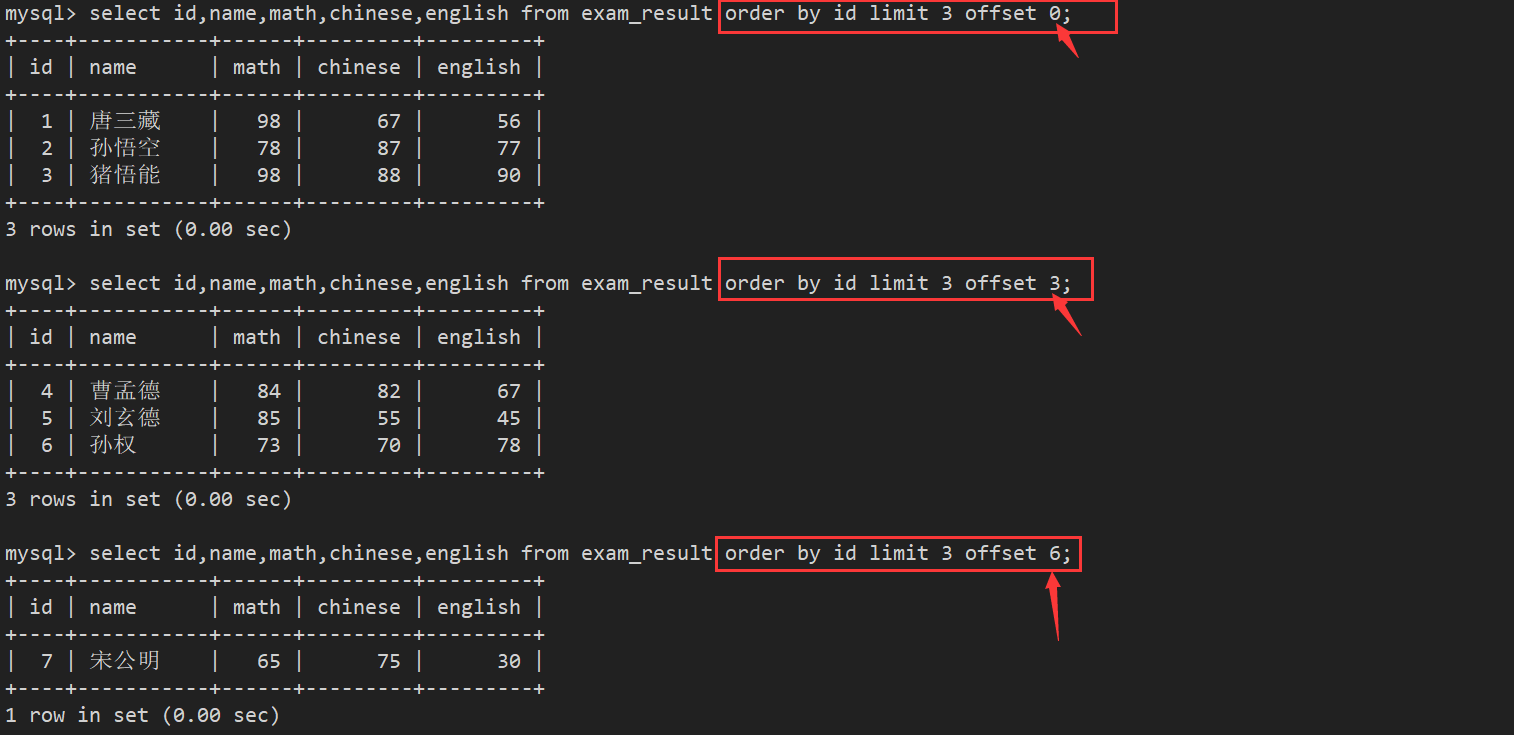
- 注意:这里第3页结果不足3个,不会有影响
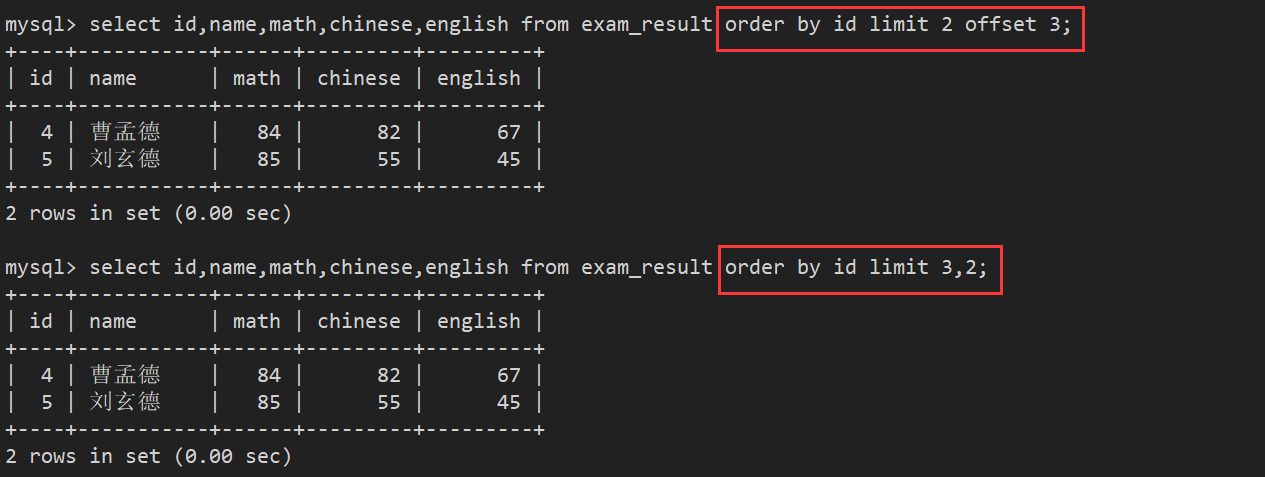
limit n offset m 表示从m下标开始,截取n条数据 其中起始下标是0
注意: limit 3,2 == limit 2 offset 3 (从第几行数据开始显示后面几行)
四.表的更新(改)
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
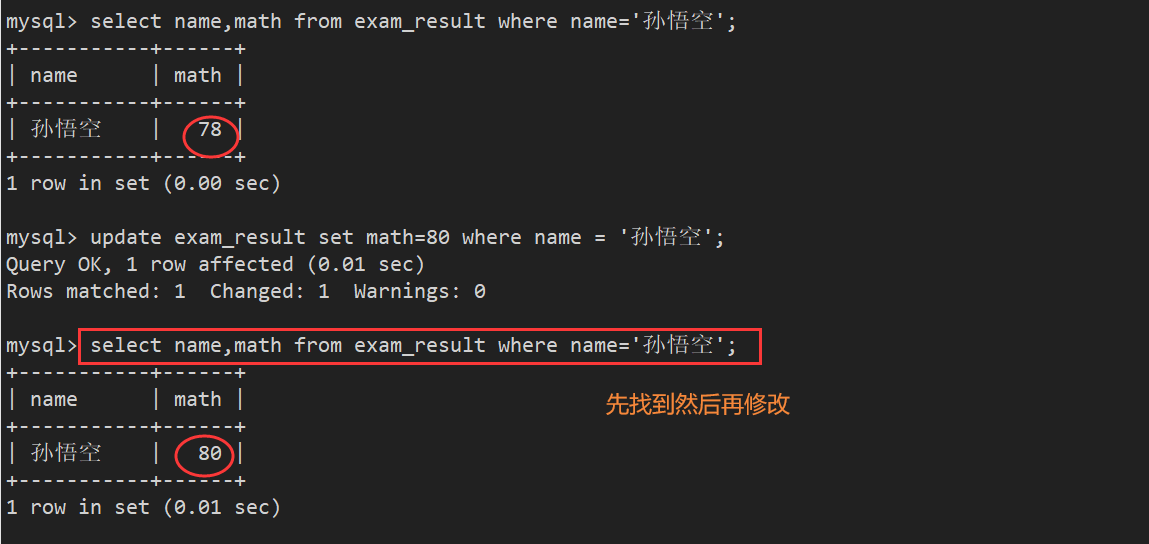
- 注意:要修改数据,必须要先查找才能修改
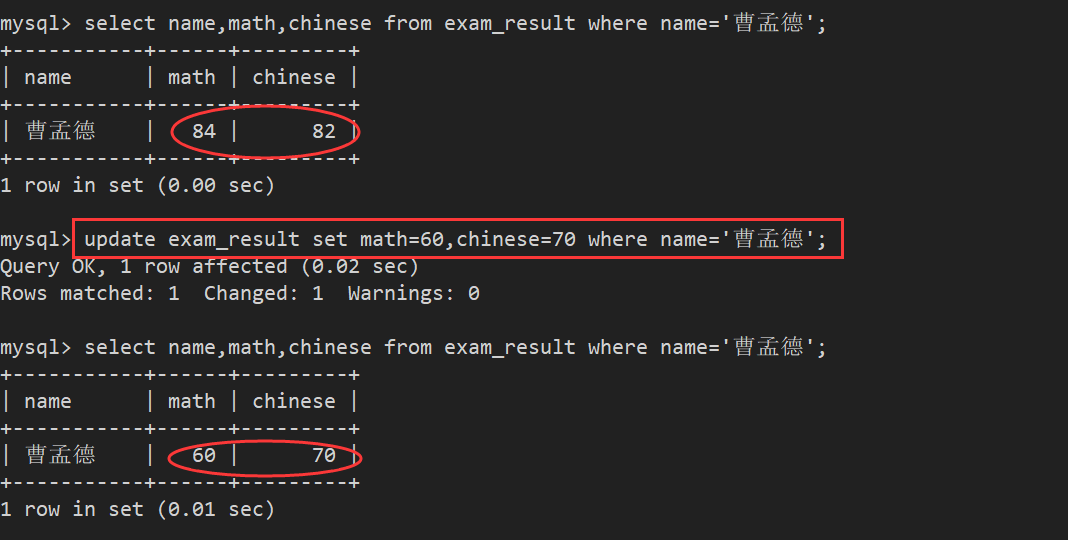
案例1:将孙悟空的数学成绩变为80分
案例2:将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
案例3:将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
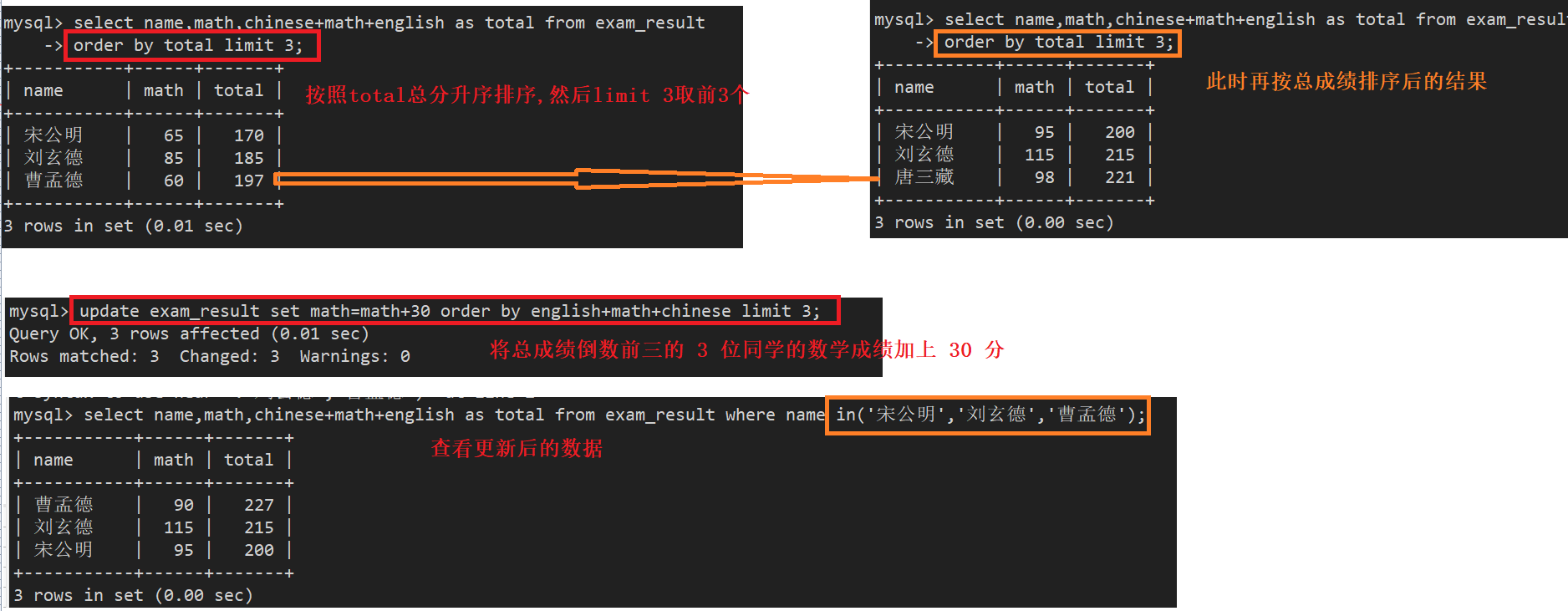
- 注意:更新数据不支持+=,-= 只能 X = X + m / X = X -m
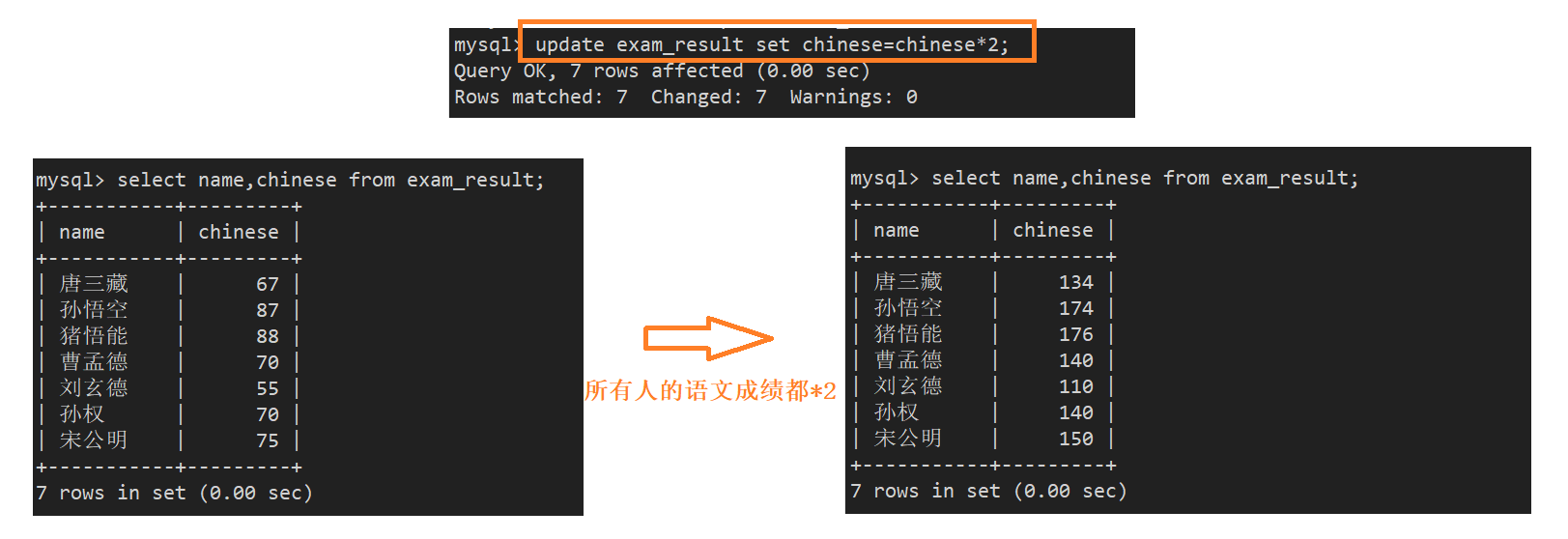
案例4:将所有同学的语文成绩更新为原来的 2 倍
- 更新全表的语句慎用,如果没有where子句选择特定的人,则更新全表
五.删除表中的数据
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
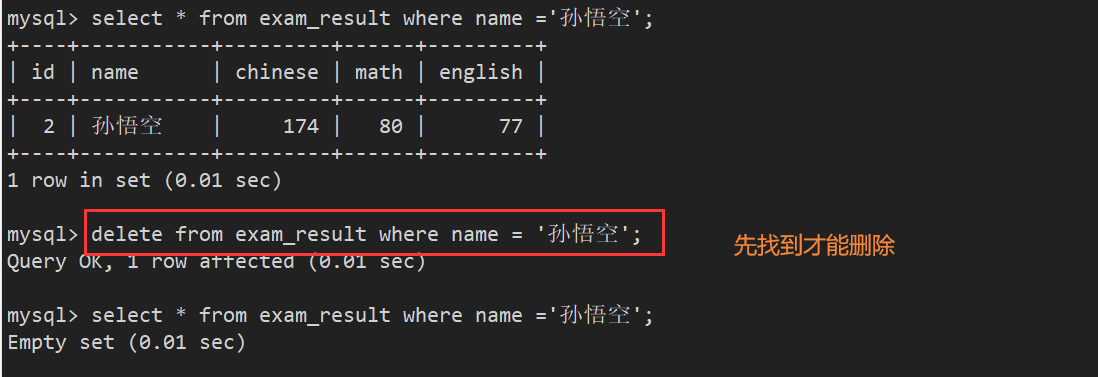
- 删除数据,必须先找到才能删除
案例1:删除孙悟空同学的考试成绩
案例2:删除整张表数据
- 删除整表操作要慎用!
所以这里用的是测试表:
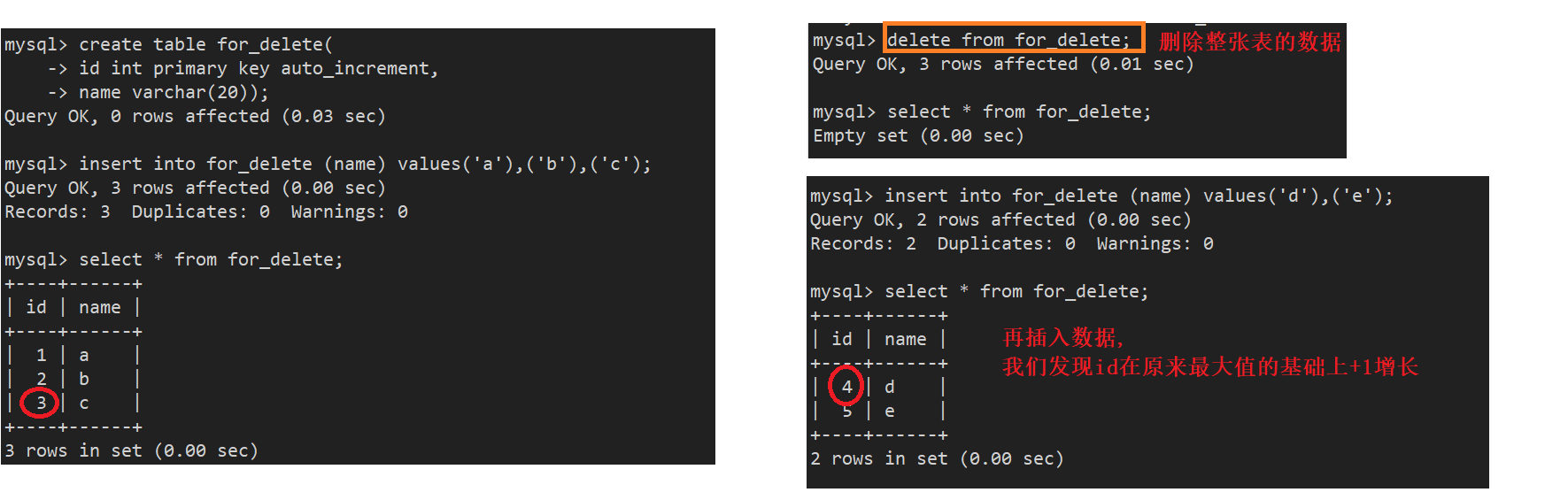
我们查看表结构: 可以发现其中有一个auto_increment=n的选项

所以我们就可以理解它怎么知道我们自增到多少了,实际上并不是看表里面的id,而是表结构天然的帮我们维护了这个值,一旦我们做插入,这个值会自增,这个值是下一次应该赋予的起始的序号,删除表的数据之后,这个自增的数据不会清0,而是保存历史最大的值+1
截断表
TRUNCATE [TABLE] table_name #注意:这个操作慎用
- 该语句只能对整表操作,不能像 delete 一样针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 delete 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚(对数据的恢复)
- TRUNCATE会重置 AUTO_INCREMENT 项
- 目前来看,delete只会将表内容清除,truncate还会将我们表中的自增记录清零
这里我们也准备一张测试表:
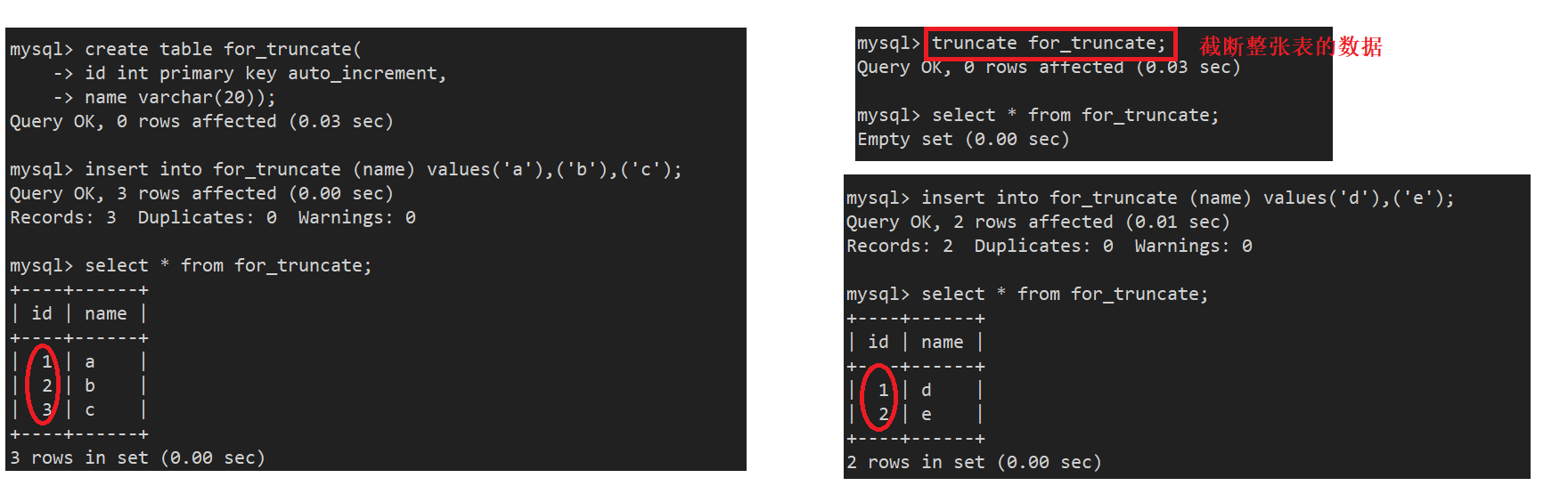
注意:这里截断整表的数据,影响的行数是0, 这也说明了实际上没有对数据真正操作,此时再插入数据,自增id从1开始重新增长,TRUNCATE会重置 AUTO_INCREMENT 项
关于日志:承担很大的功能要求,分为三种:bin log ,redo log , undo log
bin log:几乎所有的sql操作,mysqld服务器都会给我们记录下来放在bin log, 该日志用来进行多机同步,增量备份
redo log:mqsql数据持久化和crash-safe功能
undo log:在事务中承担回滚的日志,数据操作恢复功能
delete清空表,会更新日志, 而truncate清空表不更新日志
六.插入查询结果
案例:删除表中的重复记录,重复的数据只保留一份
1.先创建表结构并且插入含重复数据的样例
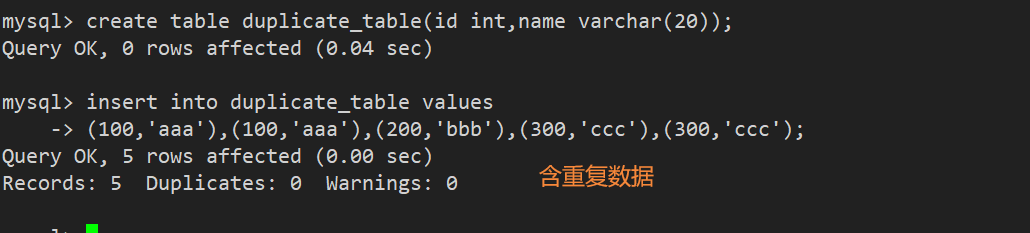
2.处理思路:
- 创建一张备份表no_duplicate_table,其结构和要去重的表:duplicate_table一样

- 将去重结果导入备份表

- 通过重命名备份表,实现去重操作 (偷梁换柱 备份表转正)

注意:最好不要删除原来的表,而是选择把它重命名为其它名字,比如加个old,方便我们知道是旧表
- 查看去重结果

总结:
# 1. 建立备份表
create table duplicate_table_bak like duplicate_table;
# 2. 将去重结果导入备份表
insert into duplicate_table_bak select distinct * from duplicate_table;
# 3. 删除表
rename table duplicate_table to old_duplicate_table;
# 4. 备份表转正
rename table duplicate_table_bak to duplicate_table;
七.聚合函数
当我们进行某些数据统计工作时,经常会用到聚合函数,一般用来给同类别或者具有相同特征的数据聚合到一起,聚合函数的使用更多时关注数据纵向之间的关系
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
案例1:统计班级共有多少同学
- 使用
*做统计,不受NULL影响
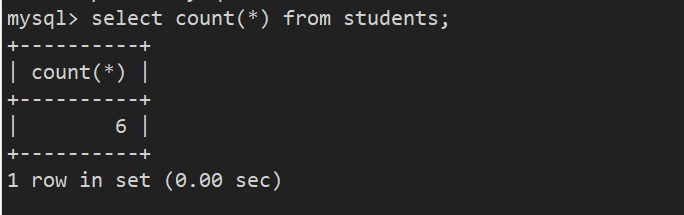
案例2:统计班级收集的 qq 号有多少
- 注意:NULL不会计入结果

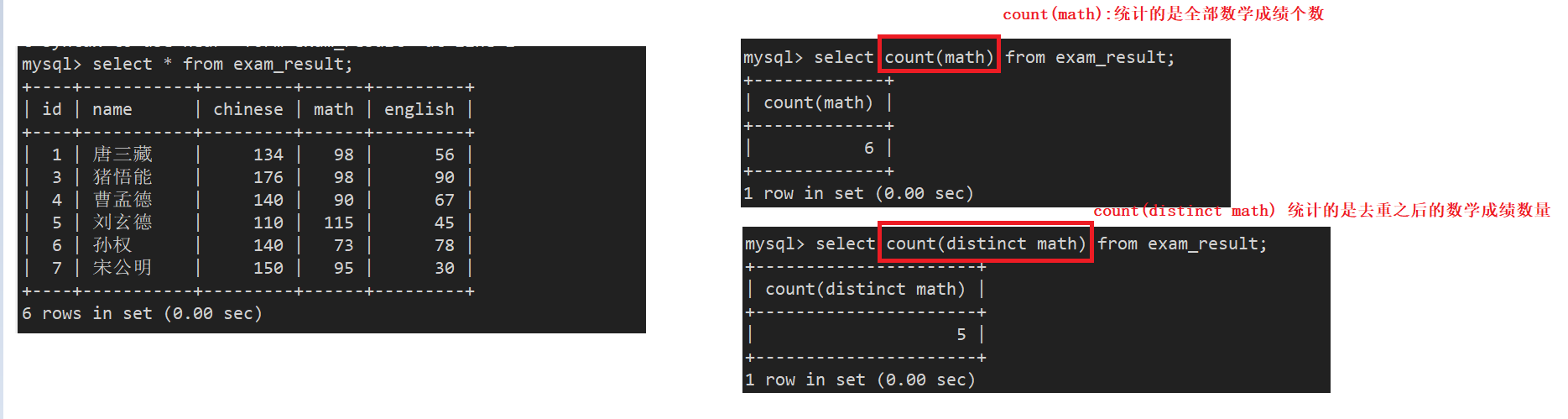
案例3:统计本次考试的数学成绩分数个数
- count(math):统计的是全部数学成绩个数
- count(distinct math) 统计的是去重之后的数学成绩数量
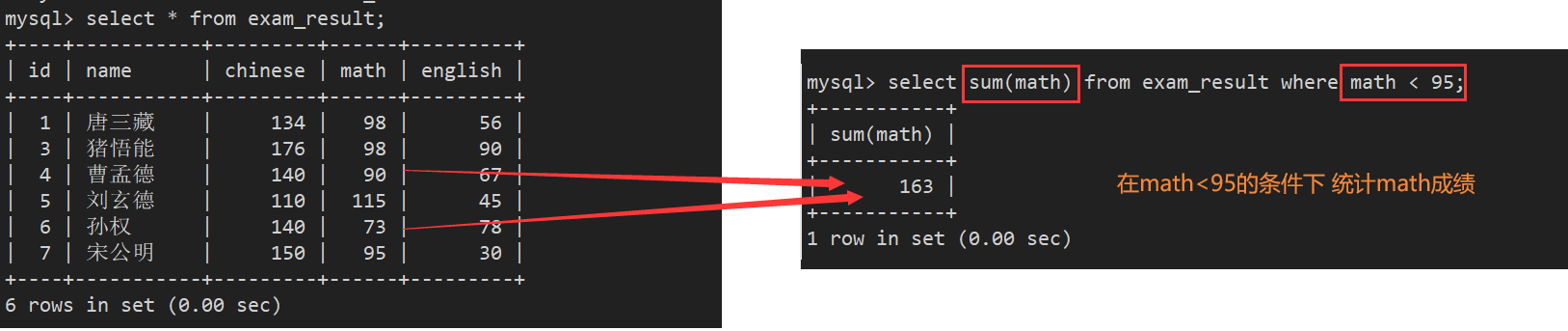
案例4:统计数学成绩总分

案例4.1 统计所有数学成绩<95分的学生的数学成绩总分
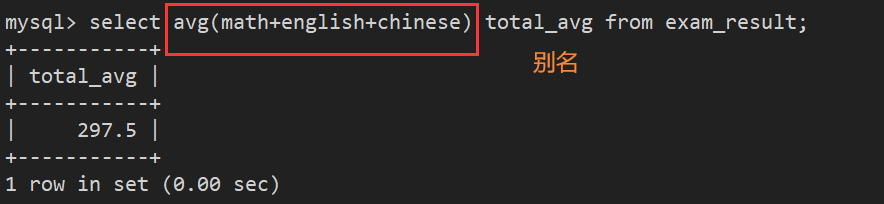
案例5:统计平均总分
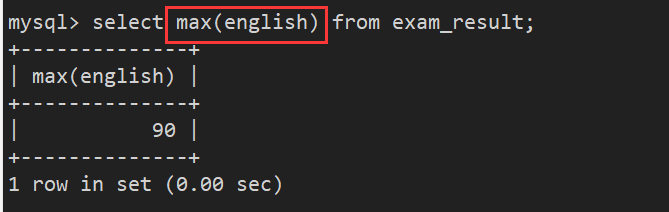
案例6:返回英语最高分
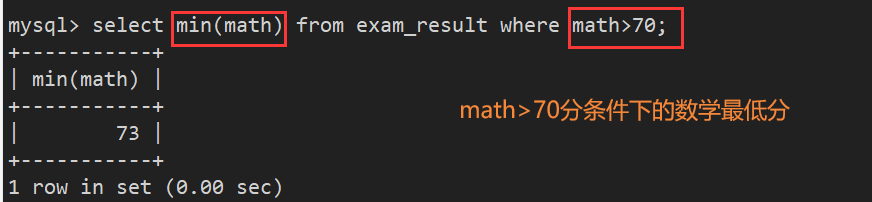
案例7:返回 > 70 分以上的数学最低分
八.group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询,分组之后对其进行某种聚合操作.
select column1, column2, .. from table group by column;
group by 首先要对全部数据进行分组,分完组后再针对每组数据执行相同的操作.
所谓的分组是在原始表当中按照筛选条件, 分组是在数据计算之前要做的,
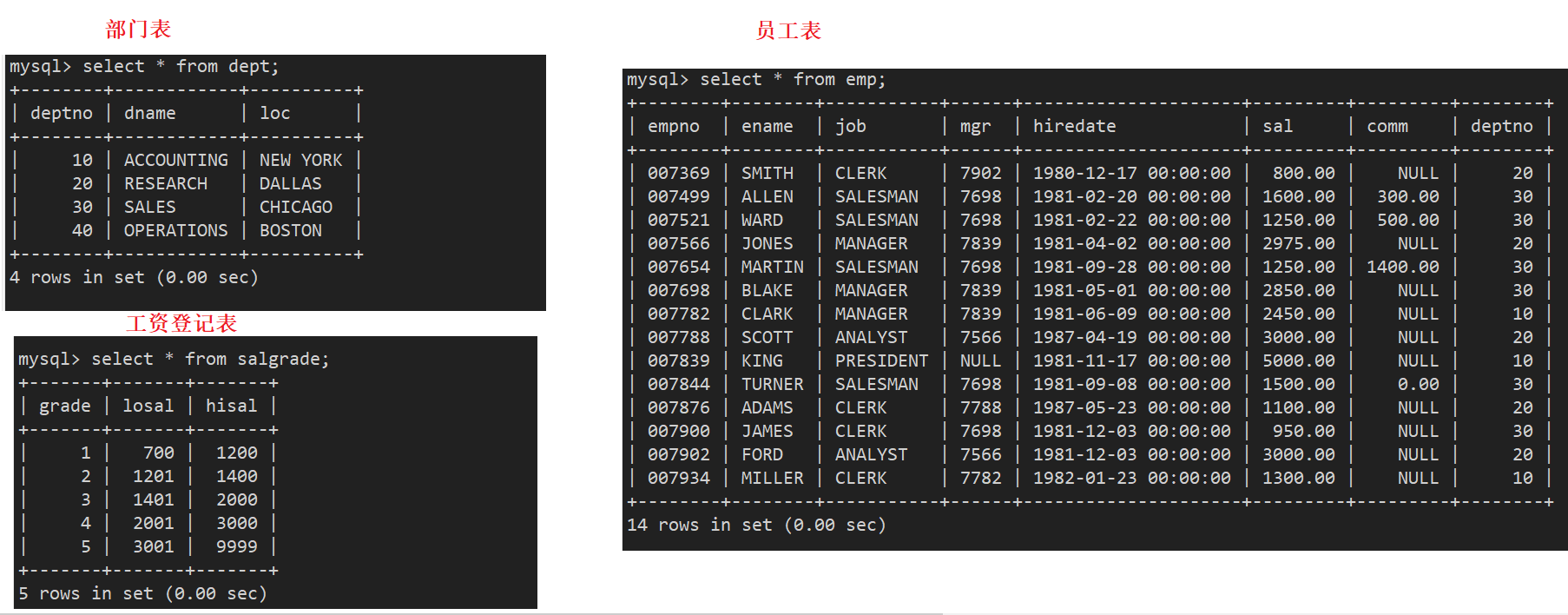
准备工作,创建一个雇员信息表:(来自oracle 9i的经典测试表)
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `scott`;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
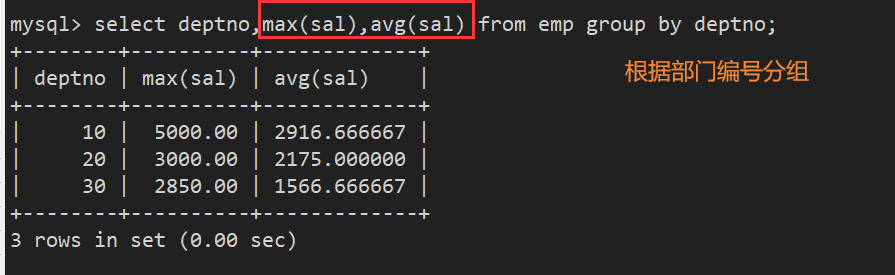
案例1:如何显示每个部门的平均工资和最高工资
先对部门编号进行分组,然后使用聚合函数即可求出平均工资和最高工资.
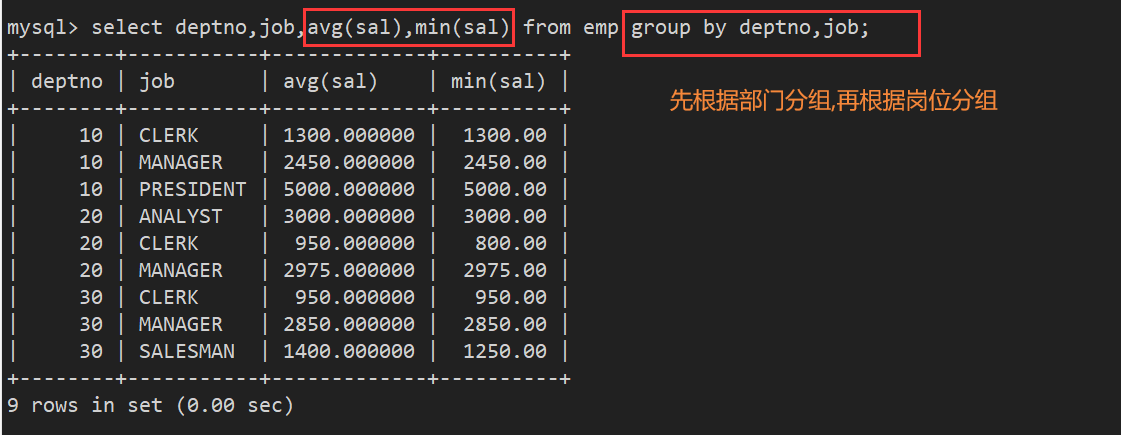
案例2:显示每个部门的每种岗位的平均工资和最低工资
首先按照部门进行分组,然后再对部门按照岗位分组 ,分完之后就能保证:同组内岗位和部门是相同的,不同组至少岗位和部门有一个不同
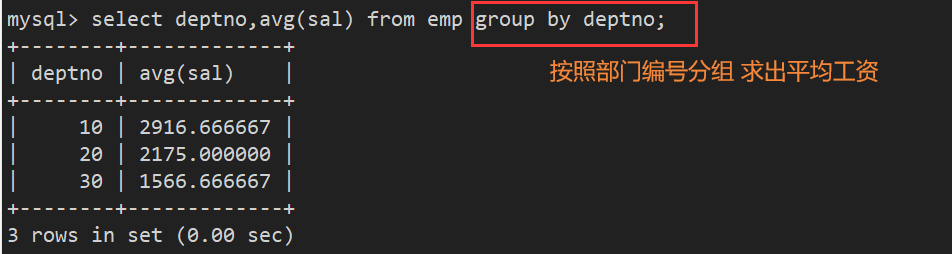
案例3:显示平均工资低于2000的部门和该部门的平均工资
首先统计各个部门的平均工资,然后在这些部门中找出小于2000工资的部门
- 第一步:统计各个部门的平均工资
- 第二步:在这些部门中找出小于2000工资的部门
错误写法1:

这主要是因为where后的条件表达式里不允许使用聚合函数,原因如下:
- where是一行一行检查的,筛选出符合条件的行,当全部行检查完才会形成一张新的表,也就是结果集,而聚合函数需要对结果集的某一列的全部值进行运算(比如求最大值、平均值). 因此两者冲突(在执行聚合函数时并没有结果集),不能同时使用
错误写法2:

where子句几乎是最早的要被作为筛选条件的一个语法来进行信息筛选,where子句的执行的顺序比groud by早!先把数据筛选出来,然后再分组,所以是不能通过where筛选ground by之后的数据
正确写法:

having则是分组(group by)后,在组内进行筛选,此时可以使用聚合函数
具体语句的执行顺序为:from子句->where 子句->group by 子句->having 子句->select 子句->order by 子句
问:上述这里为什么having可以使用别名, 不是说执行顺序: having 子句->select 子句吗?
**首先,放在select后面的不是select在执行,**select后面有一个聚合函数avg 是聚合函数先执行!
所以代码的执行顺序:先根据from找到表,(然后根据条件where筛选出数据,ps:这里没有),然后再对筛选数据进行group by分组, 然后对每一个分组组进行聚合,重命名,这样别名就有了, 然后再根据having组内进行筛选, 最后才执行的是select,把数据显示出来
关于having:
where 子句在SQL语句中几乎是最早被执行的部分,不可能去筛选 group by 分组之后的数据. 所以 where 子句不能和 group by 搭配使用, 和 group by 搭配,对其结果进行筛选过滤的是 having 子句,作用和 where 一样
- having和group by配合使用,对group by结果进行过滤,先分完组,然后having进行条件判断
- having的使用前提是组分好,即可能先把where的筛选条件使用过,所以where子句的执行顺序在having前面
where和having的区别:
二者的执行位置,次序是不同的. where的执行顺序几乎是最早的,先用where过滤表中的数据,拿到筛选出的数据才能进行分组等操作, having是过滤分组的数据的
案例5:显示公司部门编号为10的工资>1500的员工
- 第一步:先筛选出所有工资>1500的员工,并按部门分组
需要注意的是:group by是一个分组函数,你要筛查的数据列,都应该考虑一个情况,就是分组的时候,如果当前分组条件相同,接下来的分组依据是什么
所以错误写法:

正确写法:
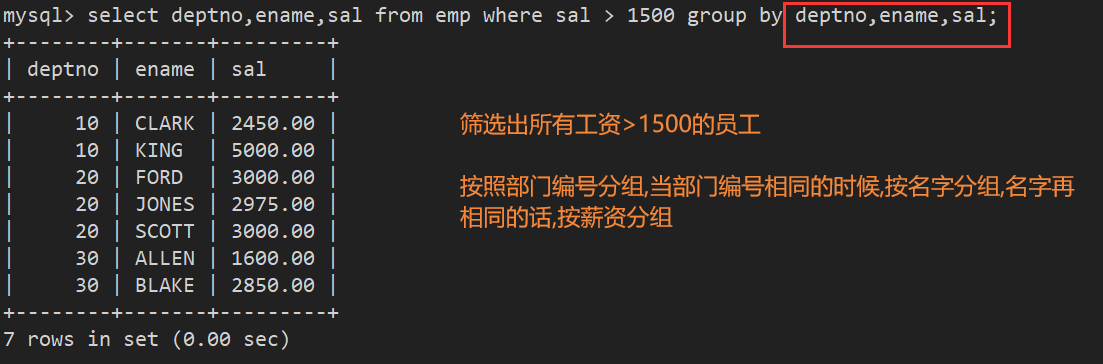
所以凡是在select中出现原表中的列名称,也必须在group_by中出现
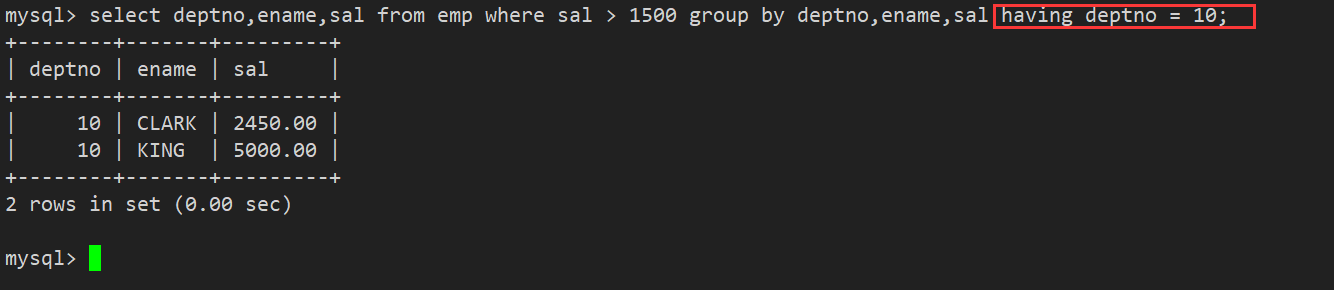
- 第二步:在所有工资>1500的员工当中,找部门编号为10的员工









![[附源码]计算机毕业设计JAVA民宿网站管理系统](https://img-blog.csdnimg.cn/c49e79c23fb14d05a42c2c17488e45d1.png)