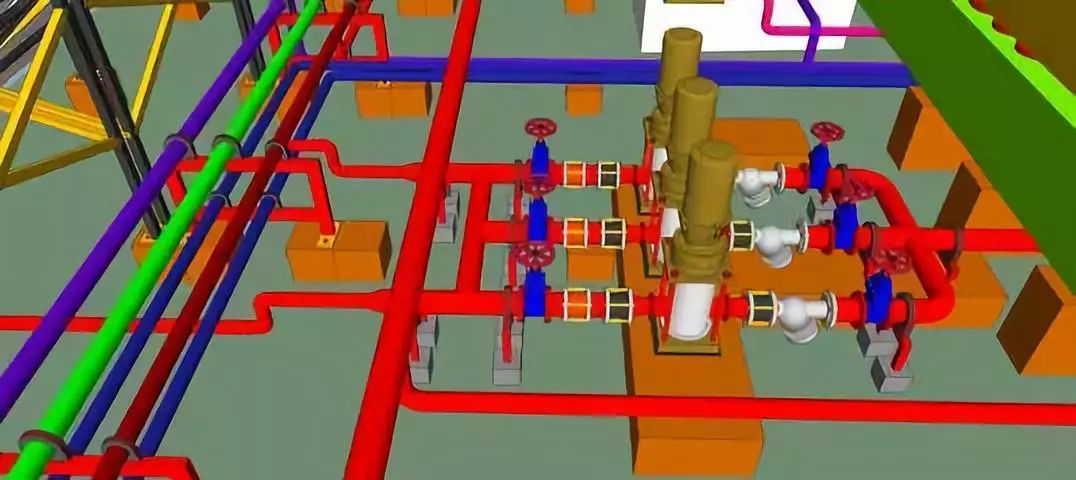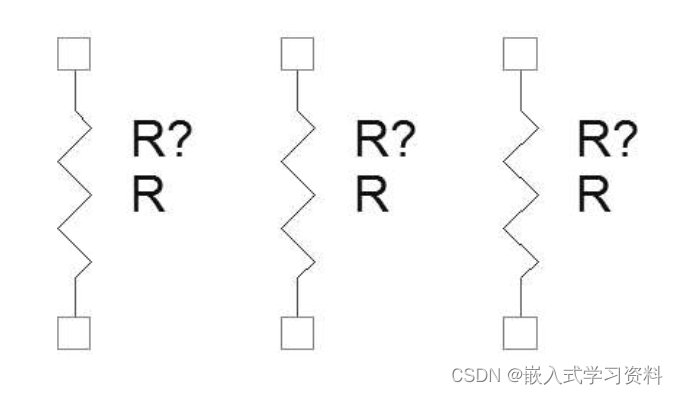

Bert没有办法一次性读入特别长的文本的问题。自注意力机制非常消耗时间和空间。

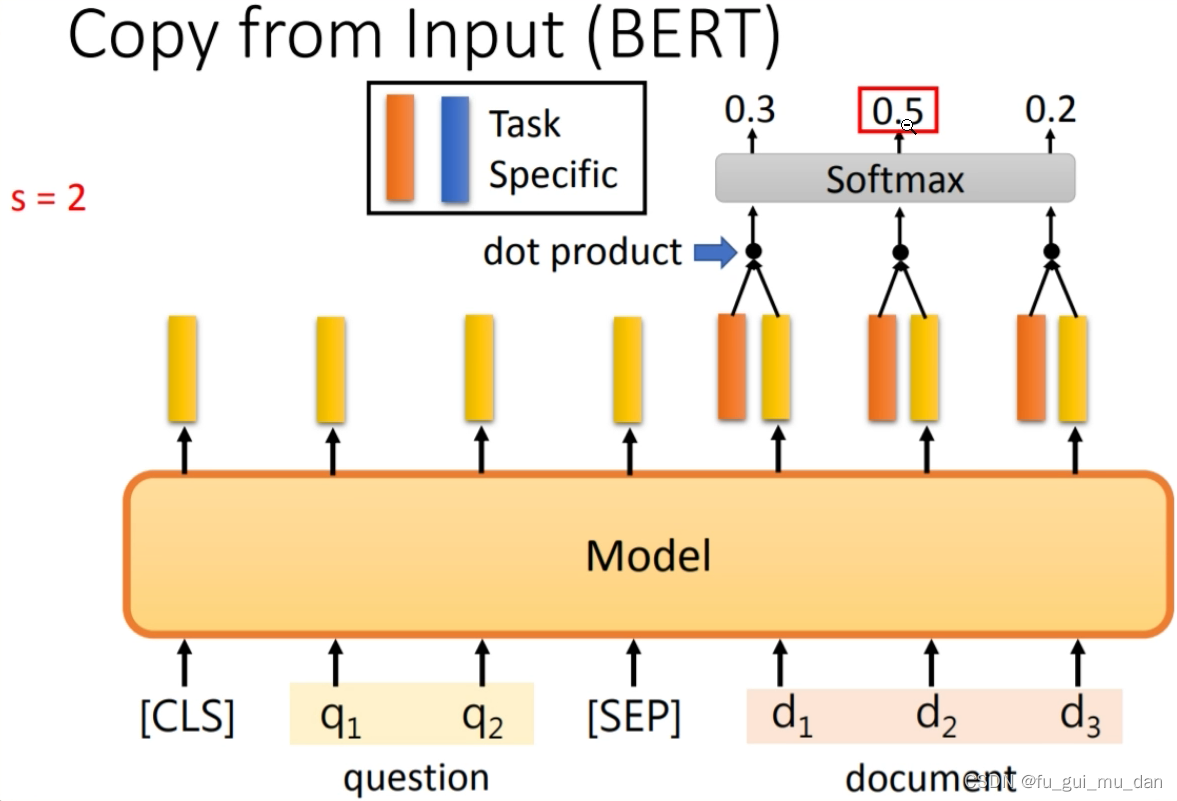
概率值最大取argmax,对应的下标
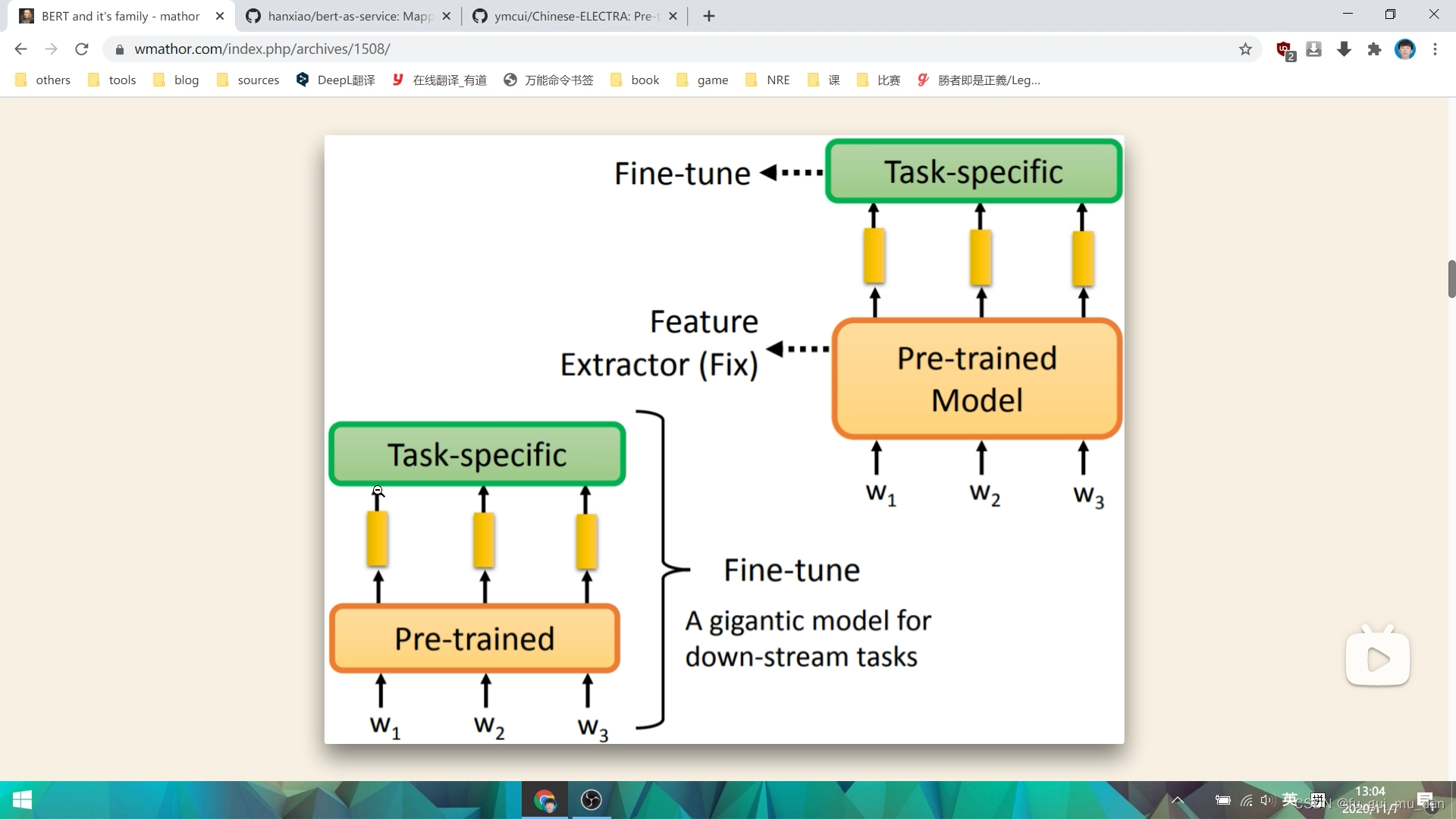
整体全部更新,所有参数都更新,比固定住pre-trained要好很多。
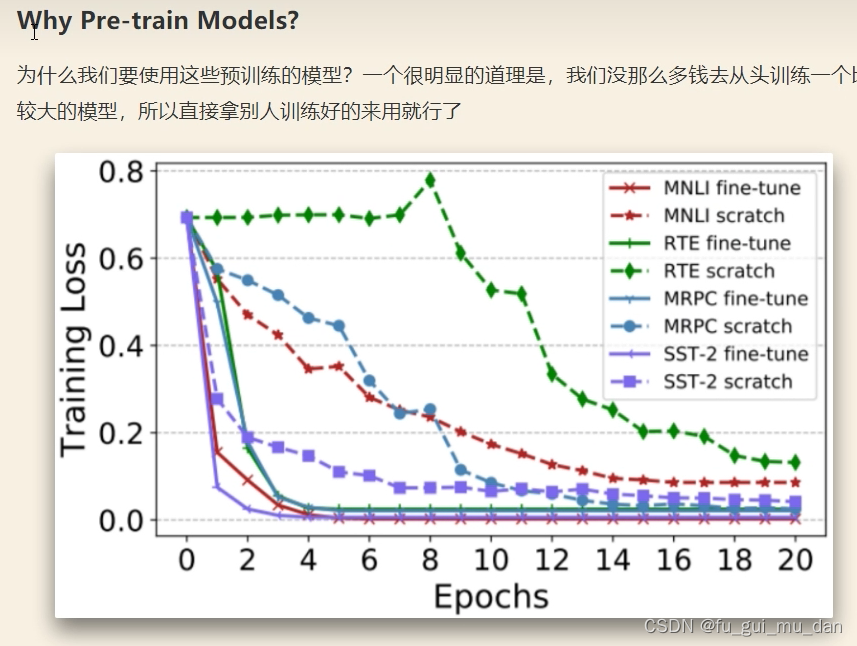
不做预训练,loss下降比较慢,收敛比较慢,而且有些时候还会有些问题
做了预训练就会平滑很多
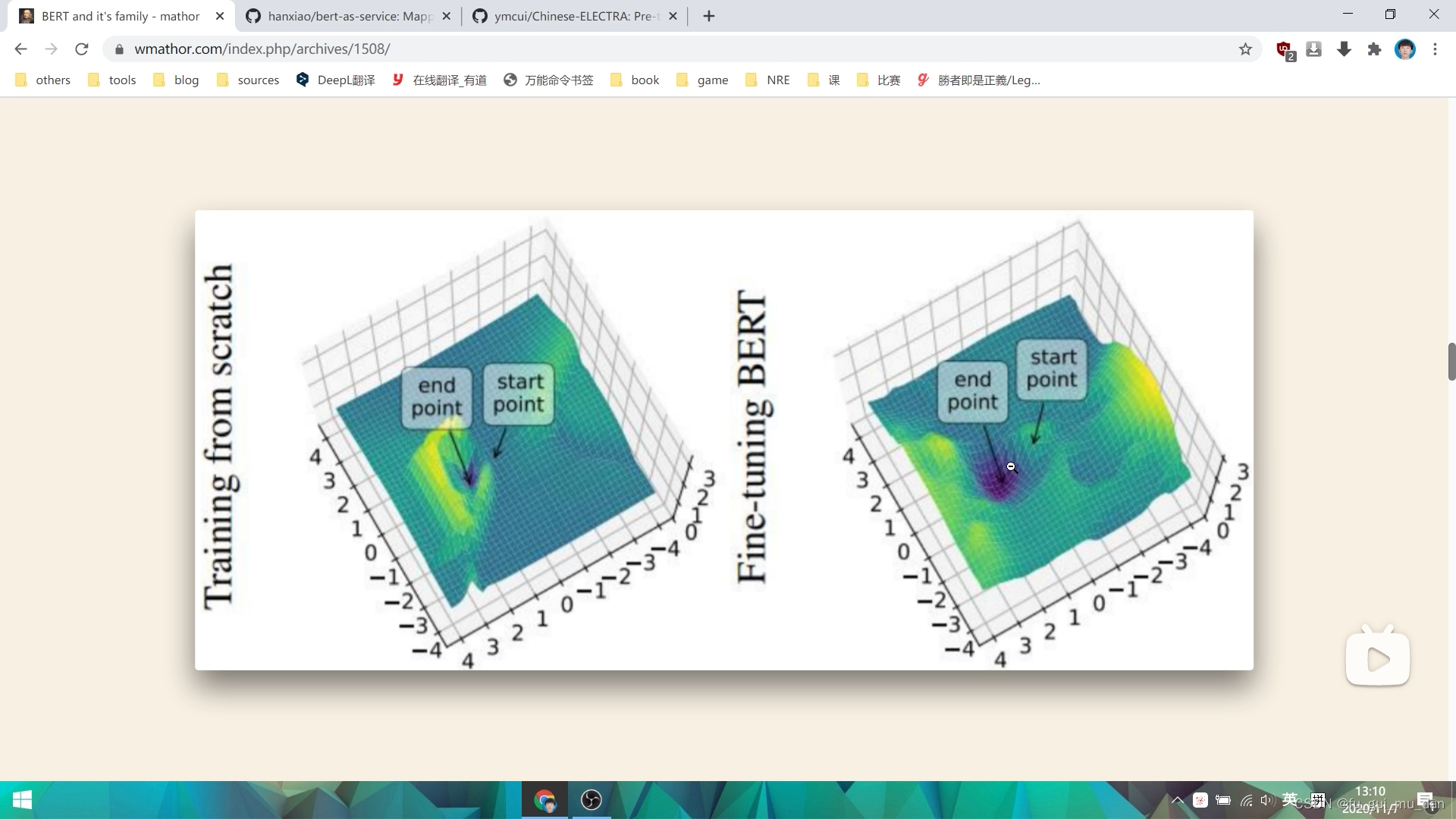
左边非常陡峭,右边比较平缓
输入稍微改变一下,非常陡峭,loss跑的非常大,效果不好,泛化能力就不好
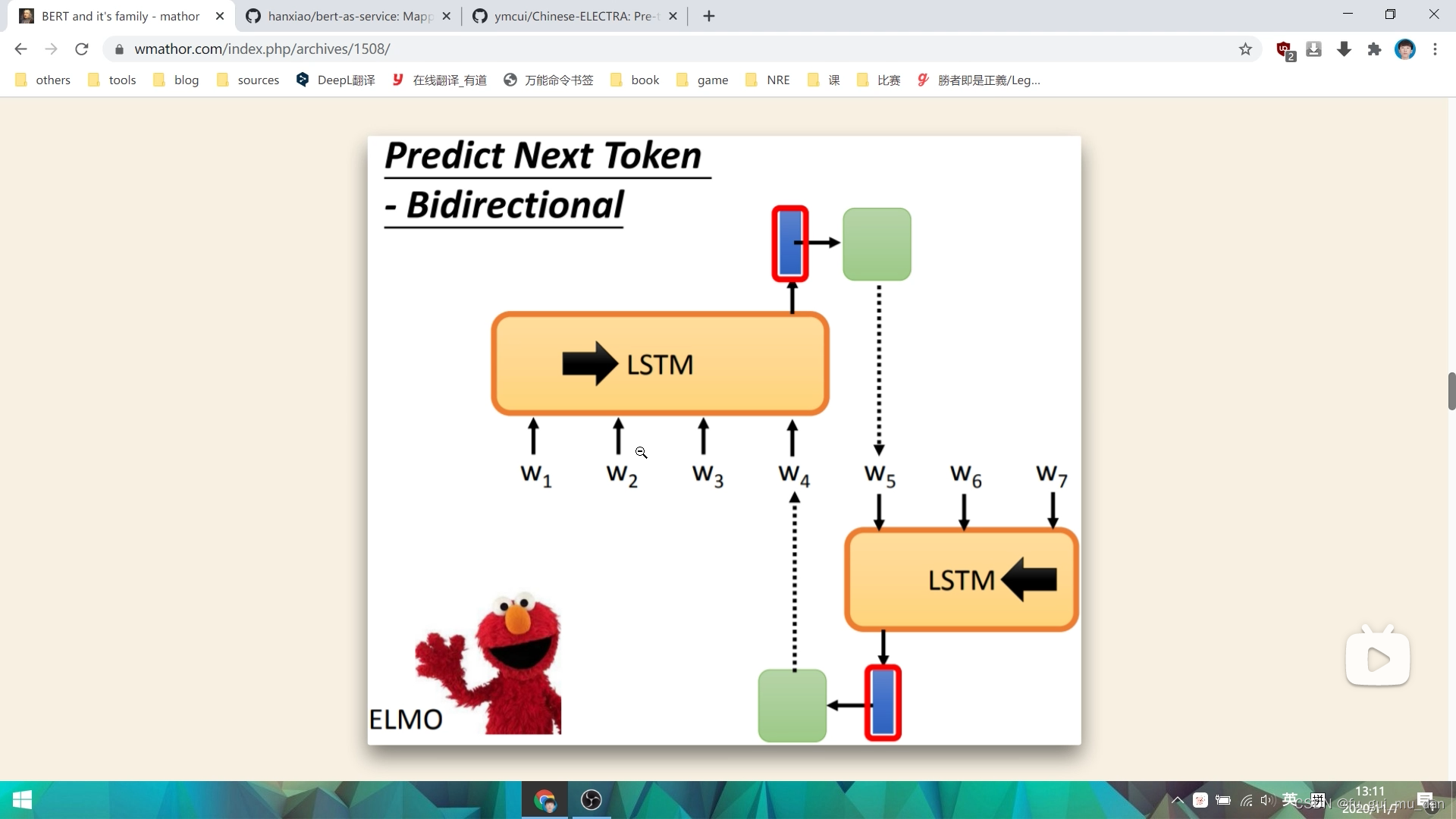
ELMo,双向LSTM
首先把句子正向读入一遍,得到一个embedding,反向读入一遍,得到一个embedding,然后将两个embedding concat,再去做我的下游任务。
实际在下层并不是双向的,我们可以这么想,假设LSTM有非常多层,在第一次的时候,单词从左往右,要预测w4,就是输入w4的时候,得到这个embedding,那这个embedding看到了后面的单词吗,没有,这个LSTM在第一层,从左往右是单向的。反向的LSTM也看不到左边的信息。所以在下层的时候并不是真正的双向,只是说,随着层数越来越高,越来越往上层走,最上面蓝色向量对双向信息越来越敏感
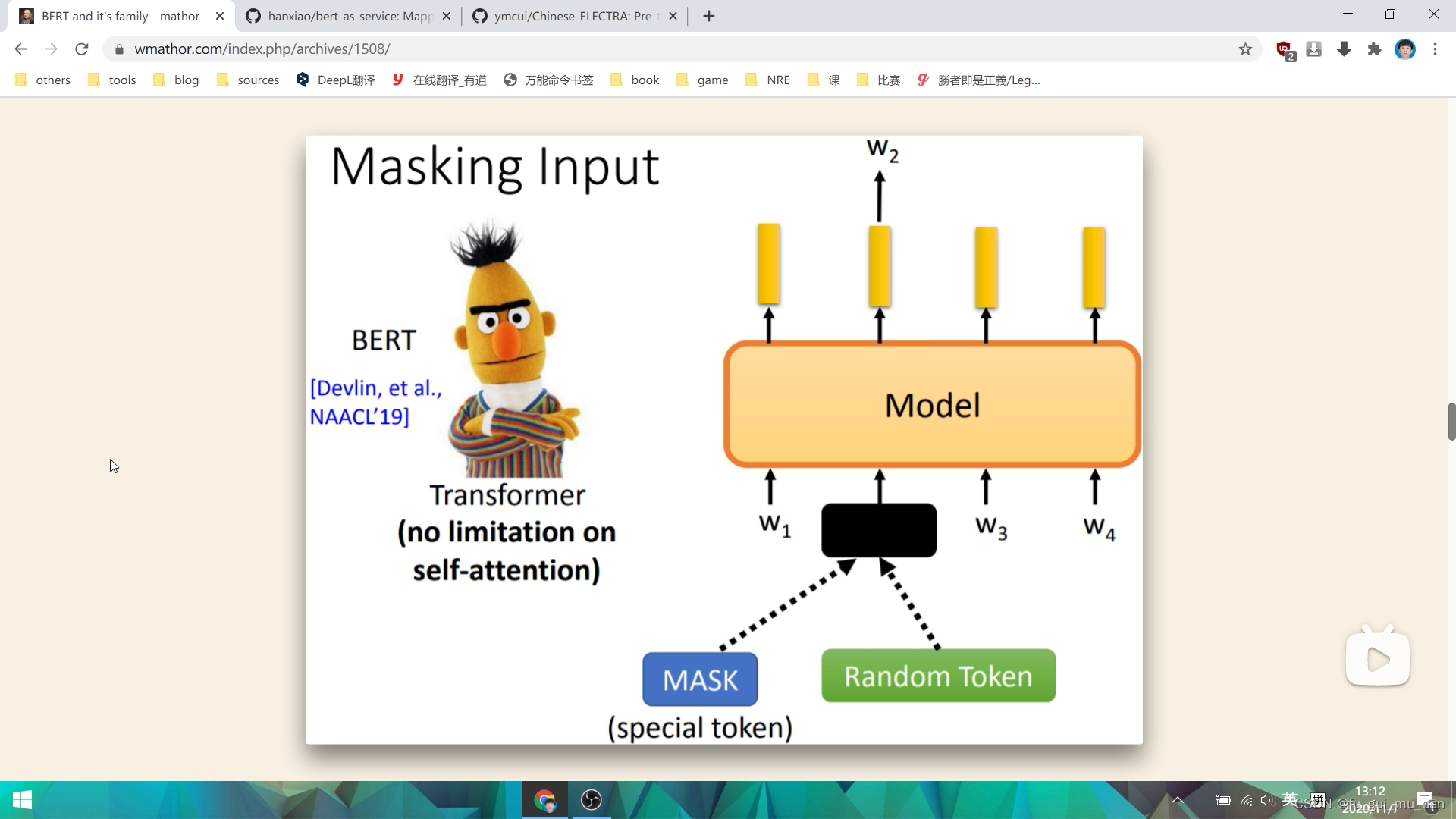
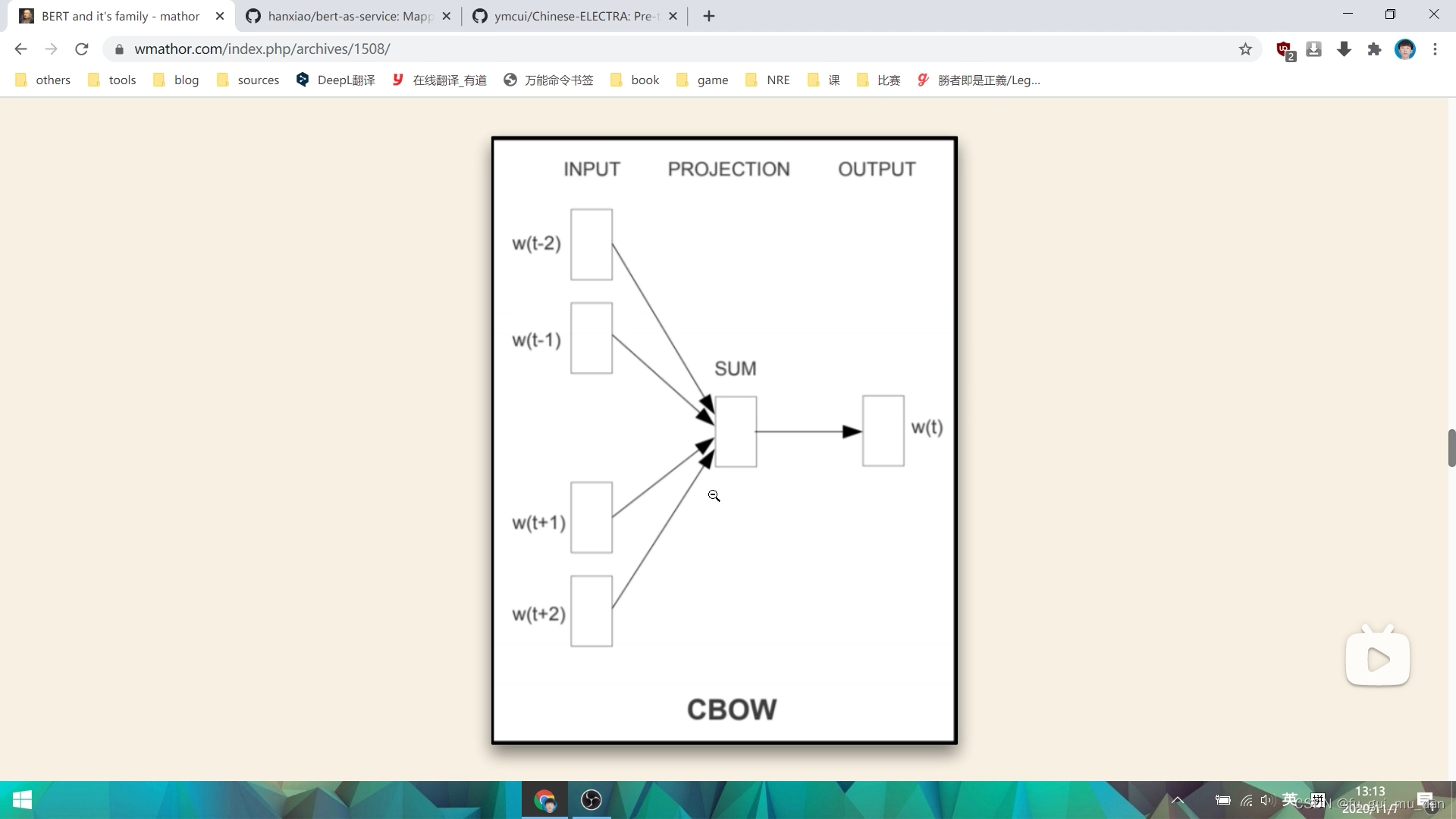
七八年前的word2vec非常像,唯一的不同点在,word2vec我们会设定一个窗口大小,只能看到左边两个、右边两个, 通过这些词的信息,来预测wt,Bert的窗口是无限的
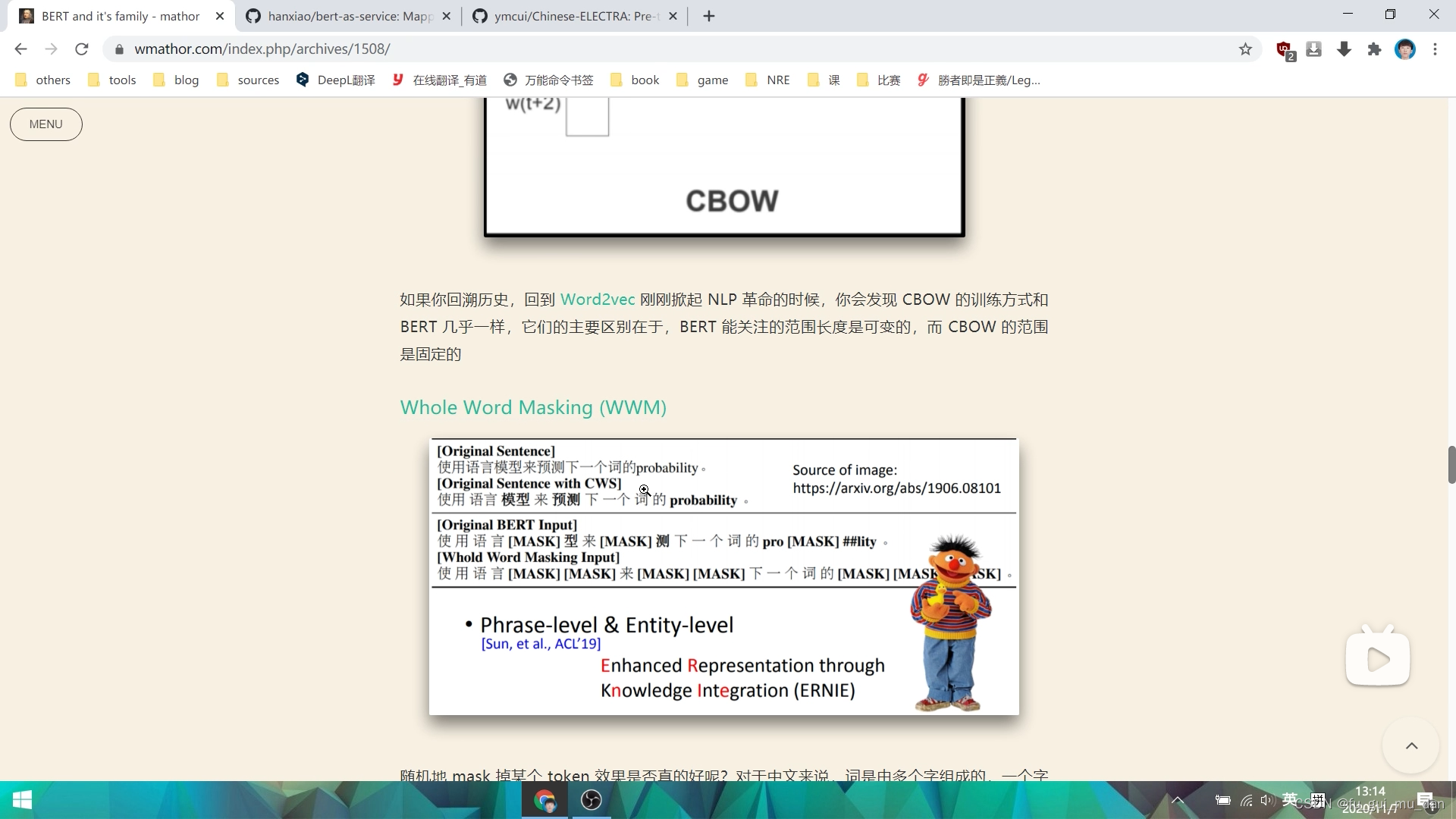
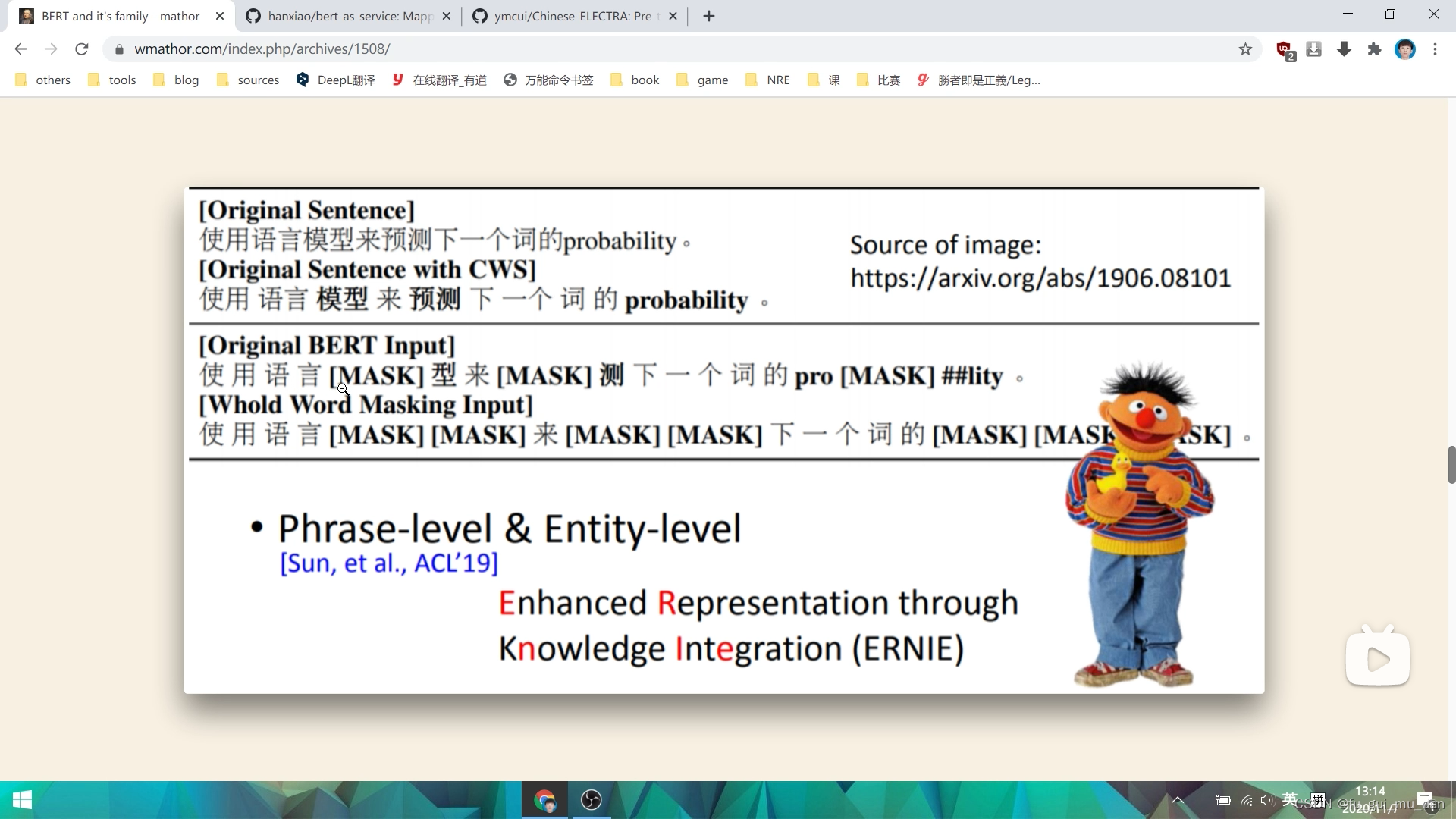
Whole Word Masking
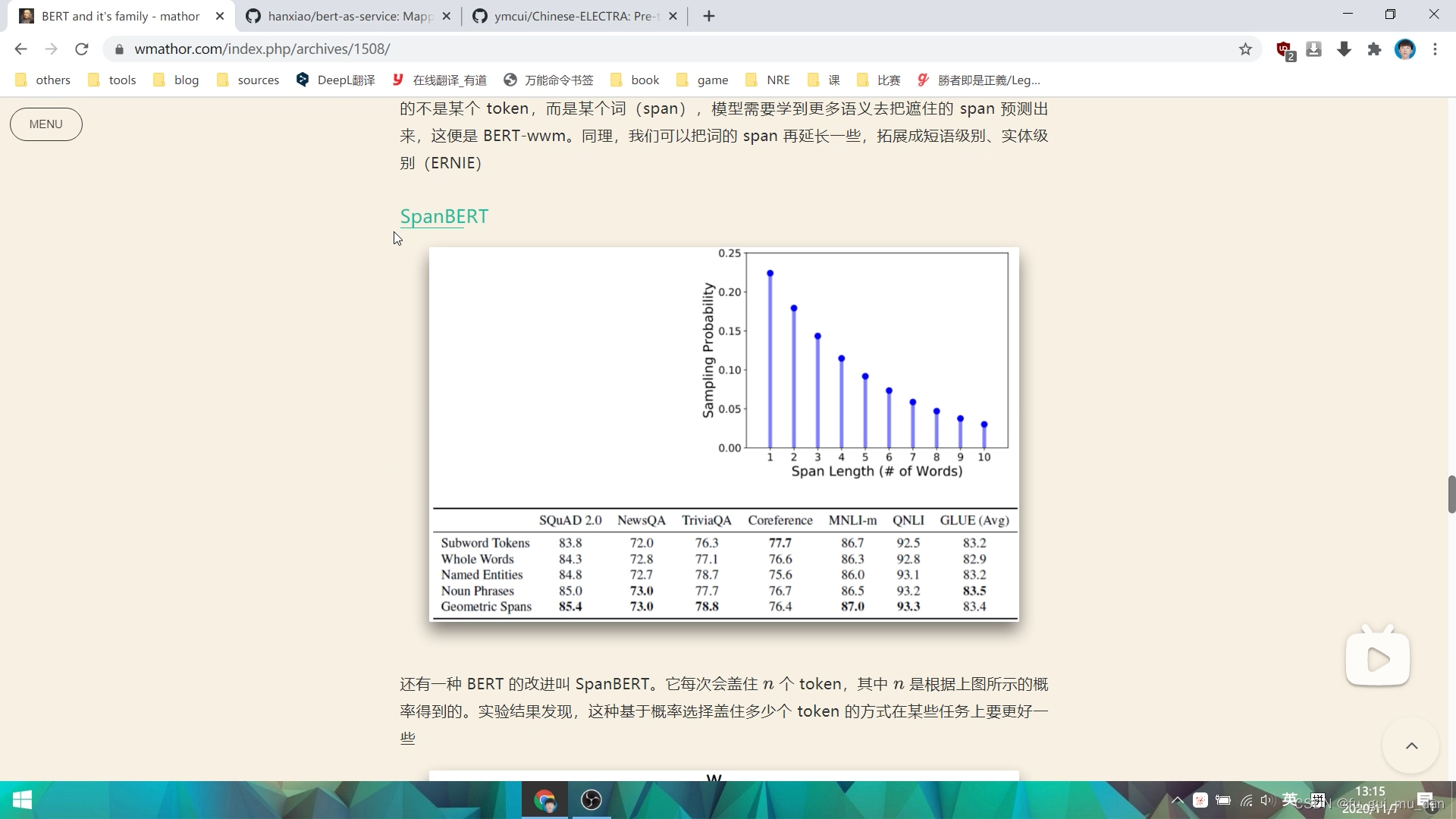
随机的选择多长的词被mask掉,是否会更好呢
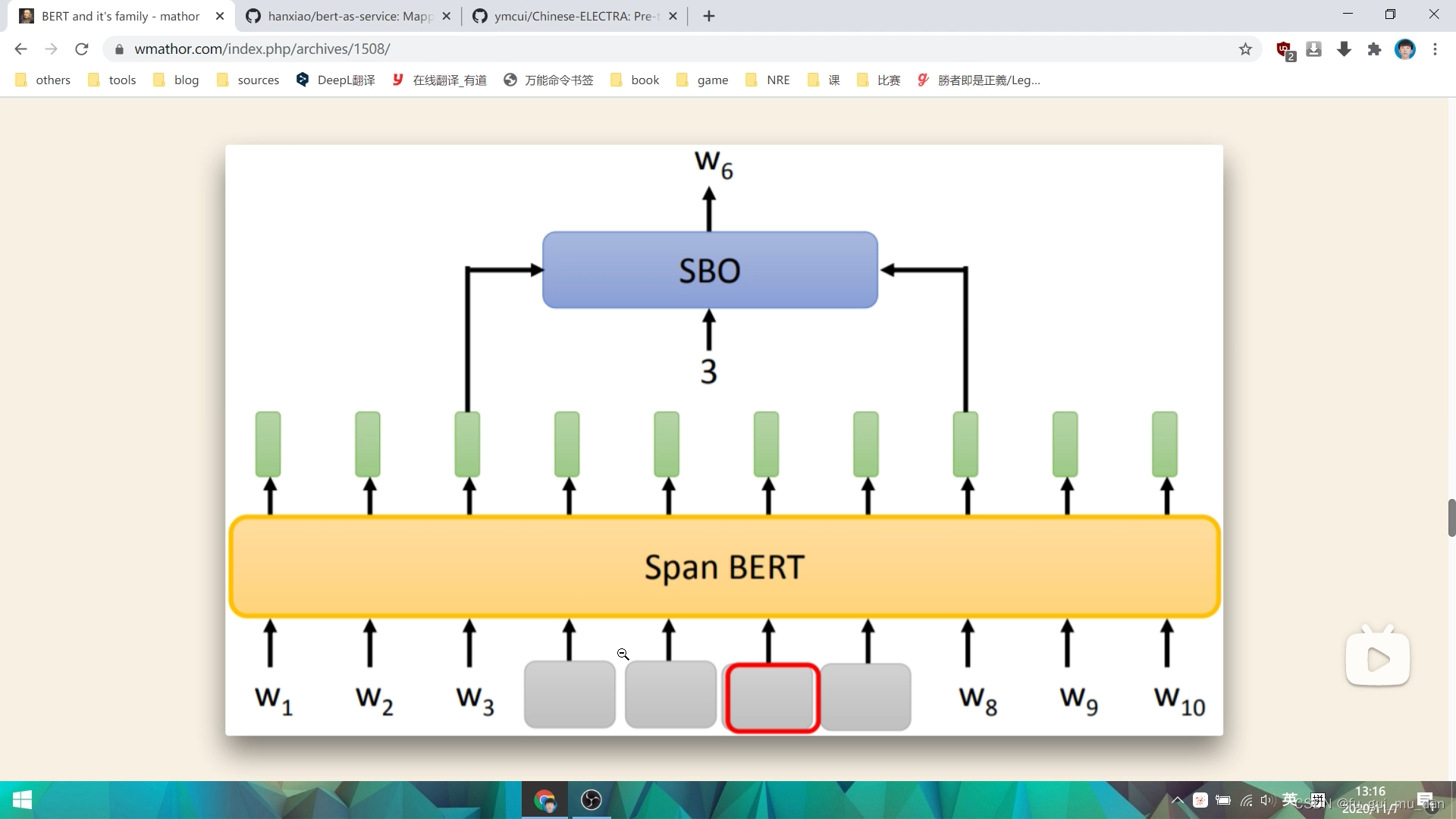
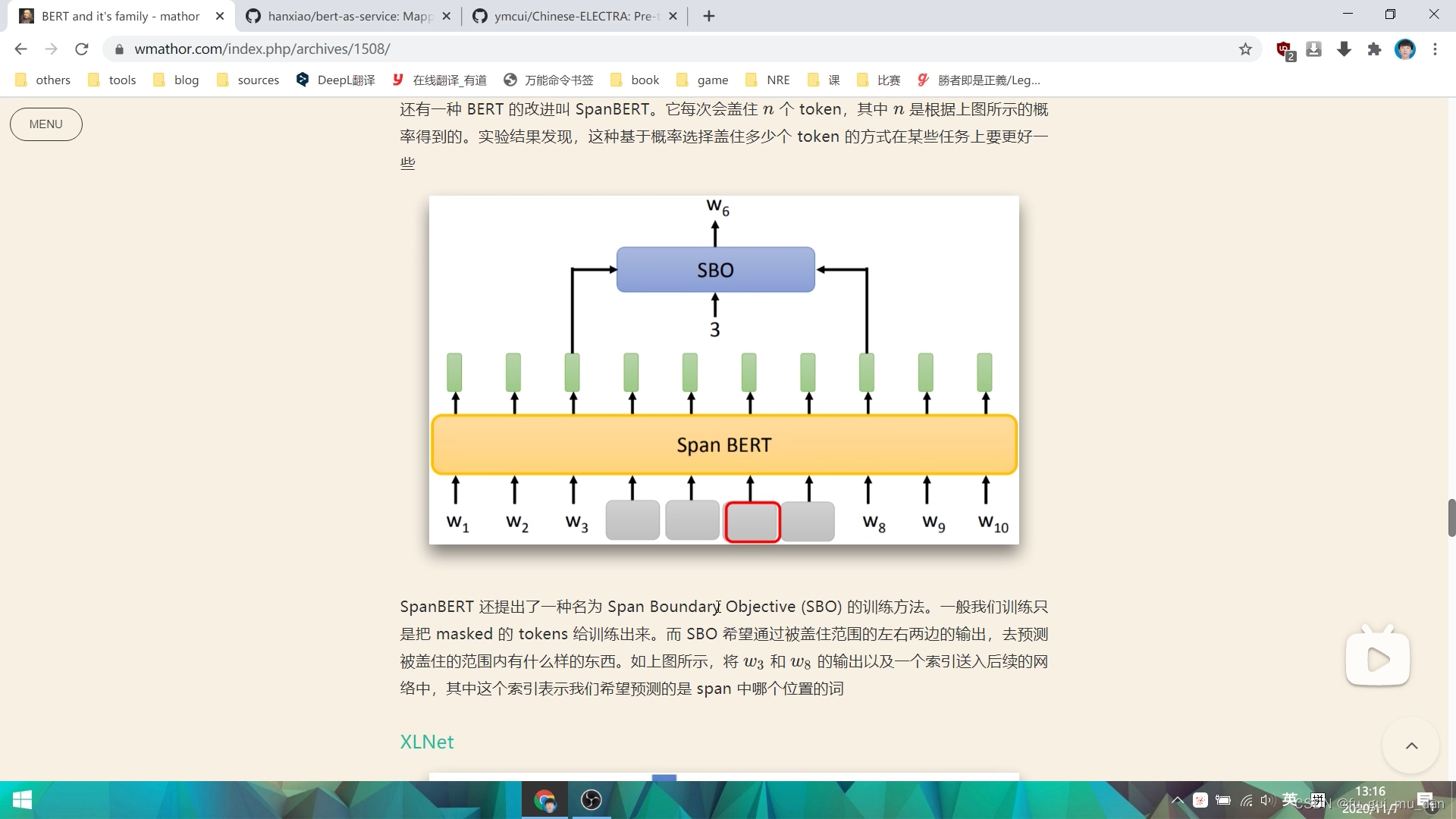
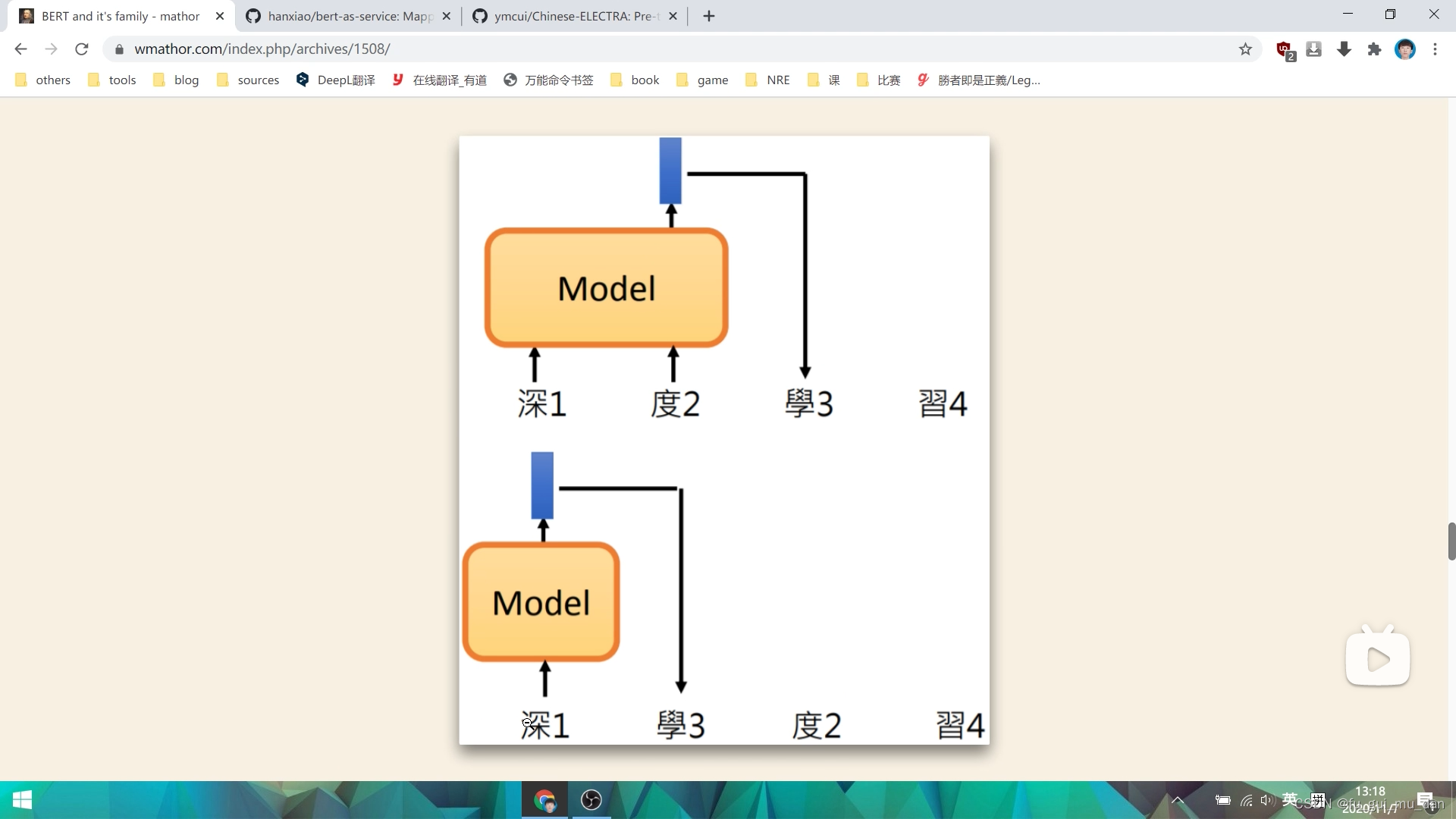
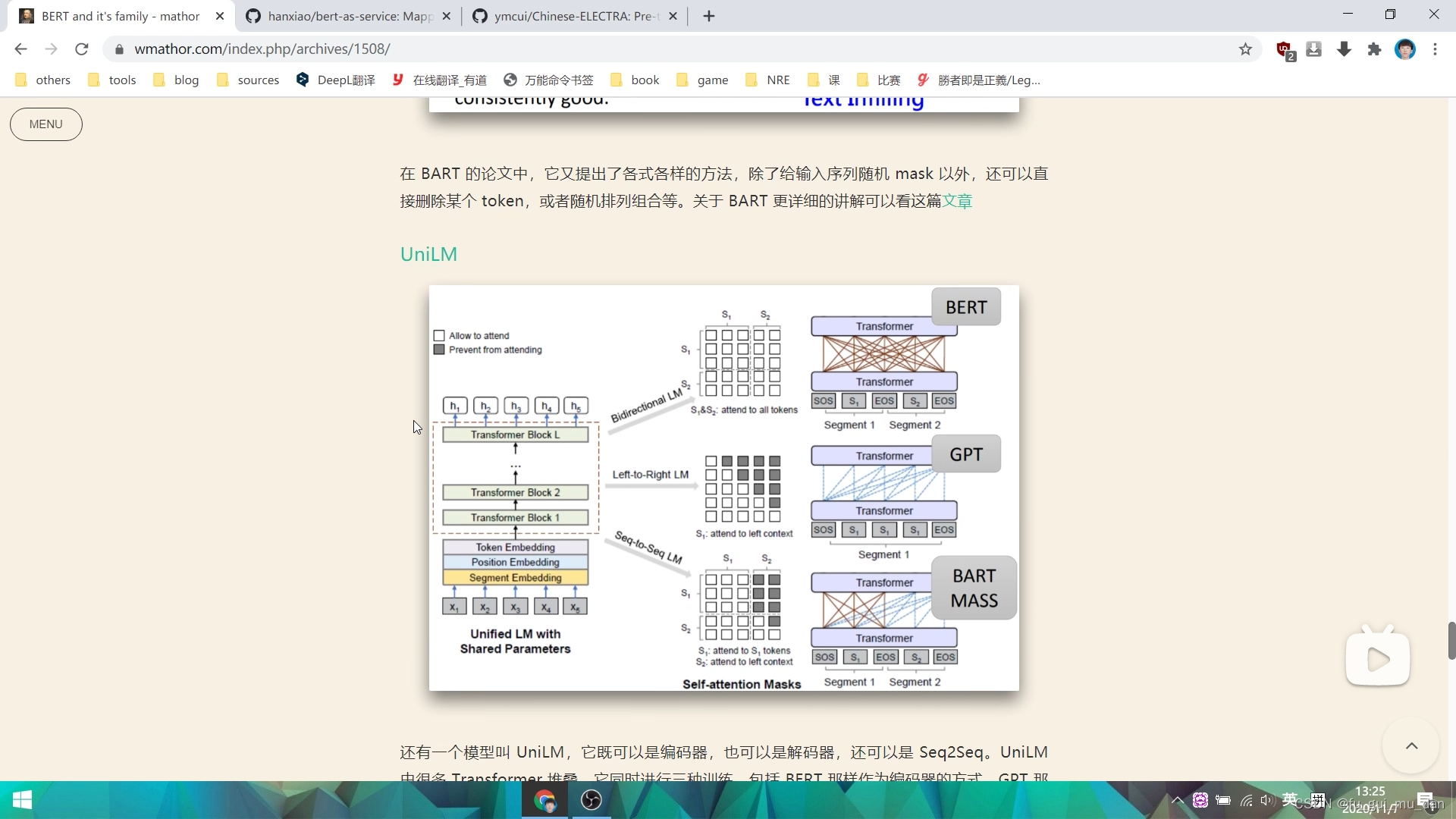
XLNet
auto regressive角度
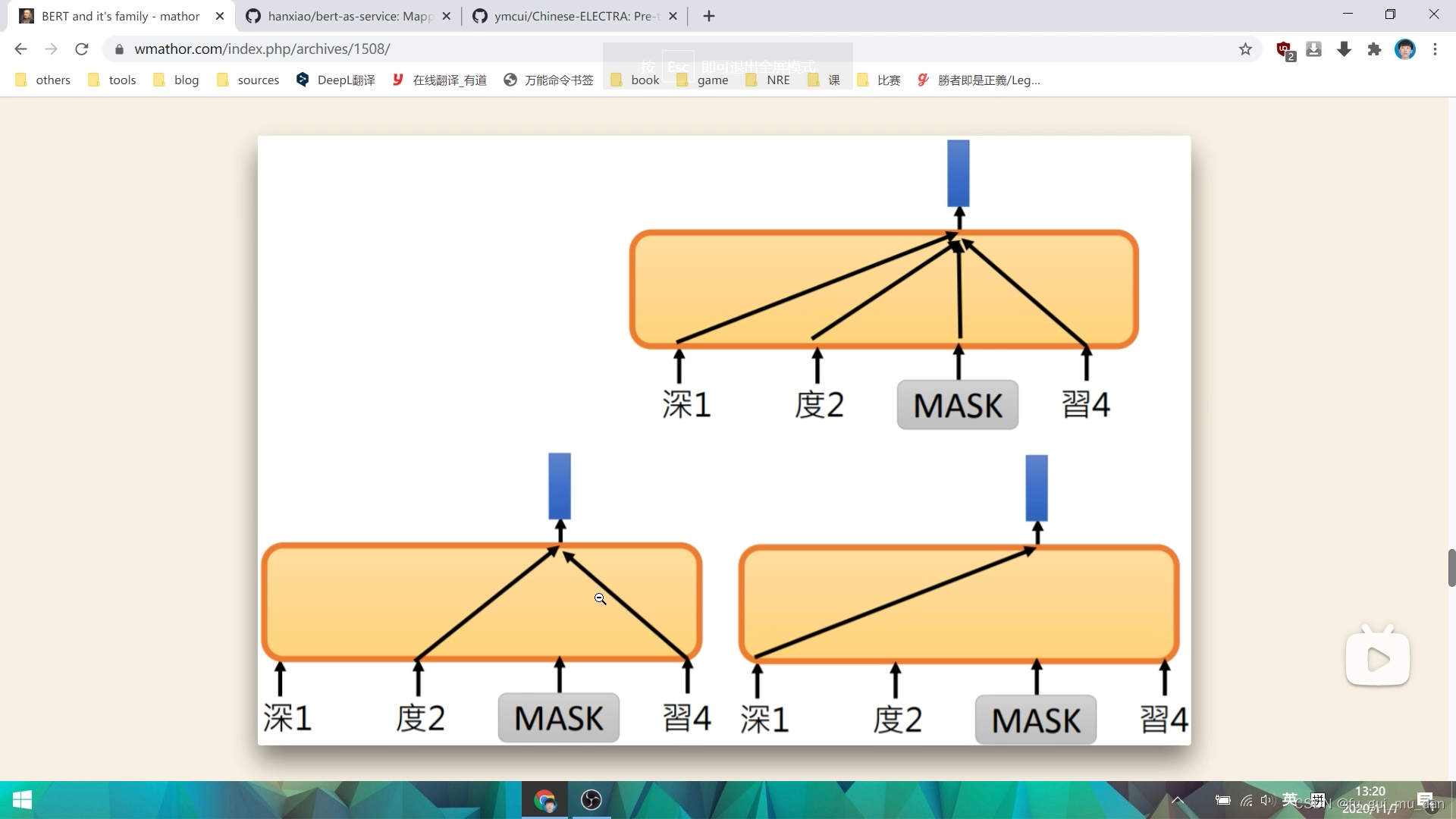 auto encoder的角度
auto encoder的角度
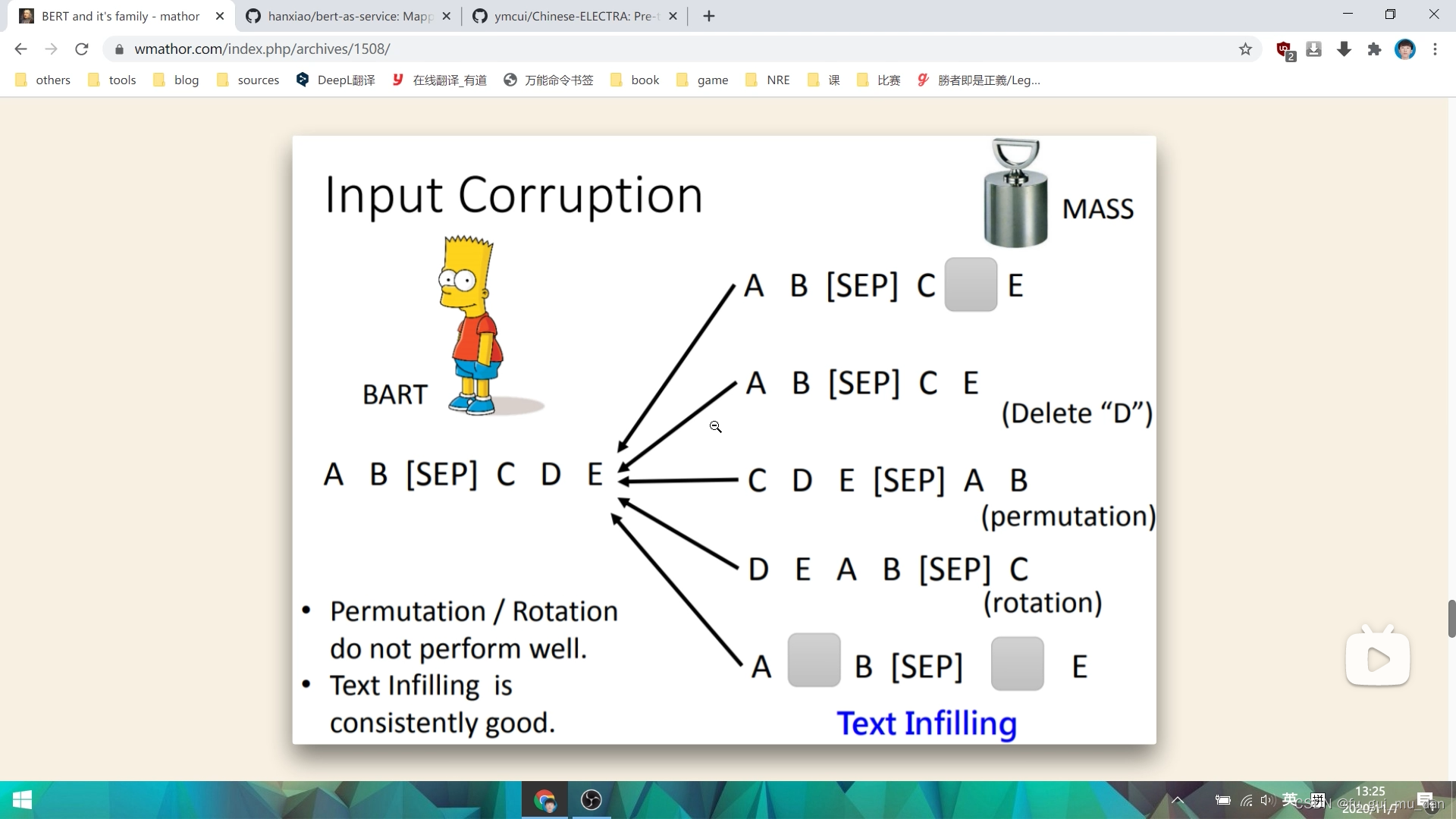
bart
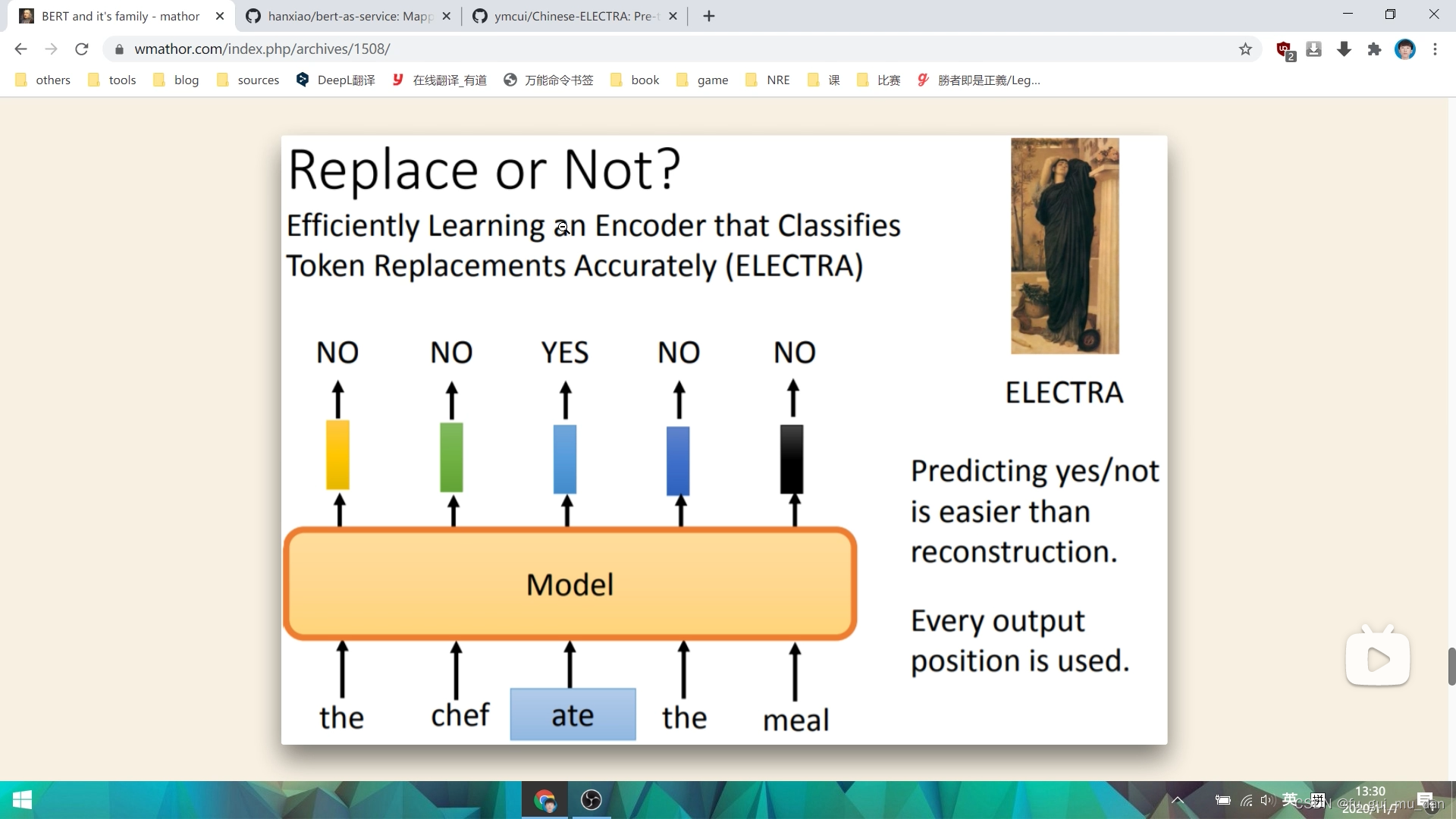 词被替换过
词被替换过
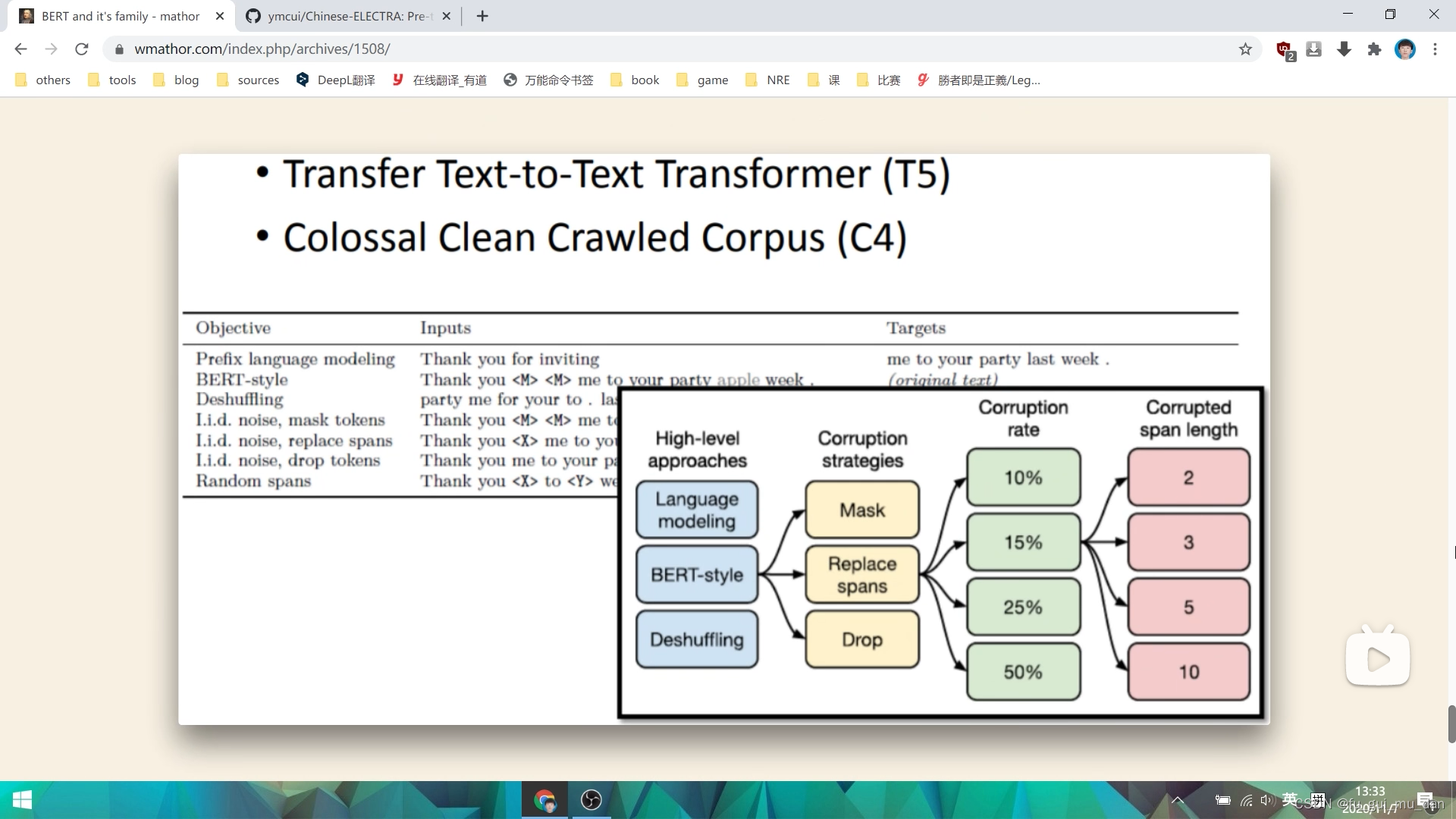
T5,非常庞大的计算任务