目录
1. 地址转换
1.1 动态重定位
1.1.1 基址寄存器(虚拟地址 -> 物理地址)
1.1.2 界限寄存器(提供访问保护)
1.2 操作系统的工作
2. 分段
2.1 分段:泛化的基址/界限
2.2 引用哪个段
2.3 代码和堆的地址转换举例
2.4 栈的地址转换举例
2.5 支持共享
2.6 分段解决和未解决的问题
3. 空闲空间管理
3.1 底层机制
3.1.1 分割与合并
3.1.2 追踪已分配空间的大小
3.1.2 嵌入空闲列表
3.2 基本策略
3.2.1 最优匹配
3.2.2 首次匹配
3.2.3 下次匹配
3.3.4 分离空闲列表
3.3.5 伙伴系统
参考资料:Operating Systems: Three Easy Pieces
第15章 机制:地址转换
第16章 分段
第17章 空闲空间管理
1. 地址转换
我们先假设
用户的地址空间必须连续地放在物理内存中
地址空间不是很大,小于物理内存的大小
每个地址空间的大小完全一样
1.1 动态重定位
基址加界限机制(base and bound),有时又称为动态重定位(dynamic relocation)
每个 CPU 需要两个硬件寄存器:
基址(base)寄存器和界限(bound)寄存器 / 限制(limit)寄存器
基址寄存器将虚拟地址转换为物理地址
界限寄存器确保这个地址在进程地址空间的范围内
1.1.1 基址寄存器(虚拟地址 -> 物理地址)
采用这种方式,在编写和编译程序时假设地址空间从零开始。但是,当程序真正执行时,操作系统会决定其在物理内存中的实际加载地址,并将起始地址记录在基址寄存器中。
当进程运行时,该进程产生的所有内存引用,都会被处理器转换为物理地址:
physical address = virtual address + base
进程中使用的内存引用都是虚拟地址(virtual address),硬件接下来将虚拟地址加上基
址寄存器中的内容,得到物理地址(physical address),再发给内存系统。
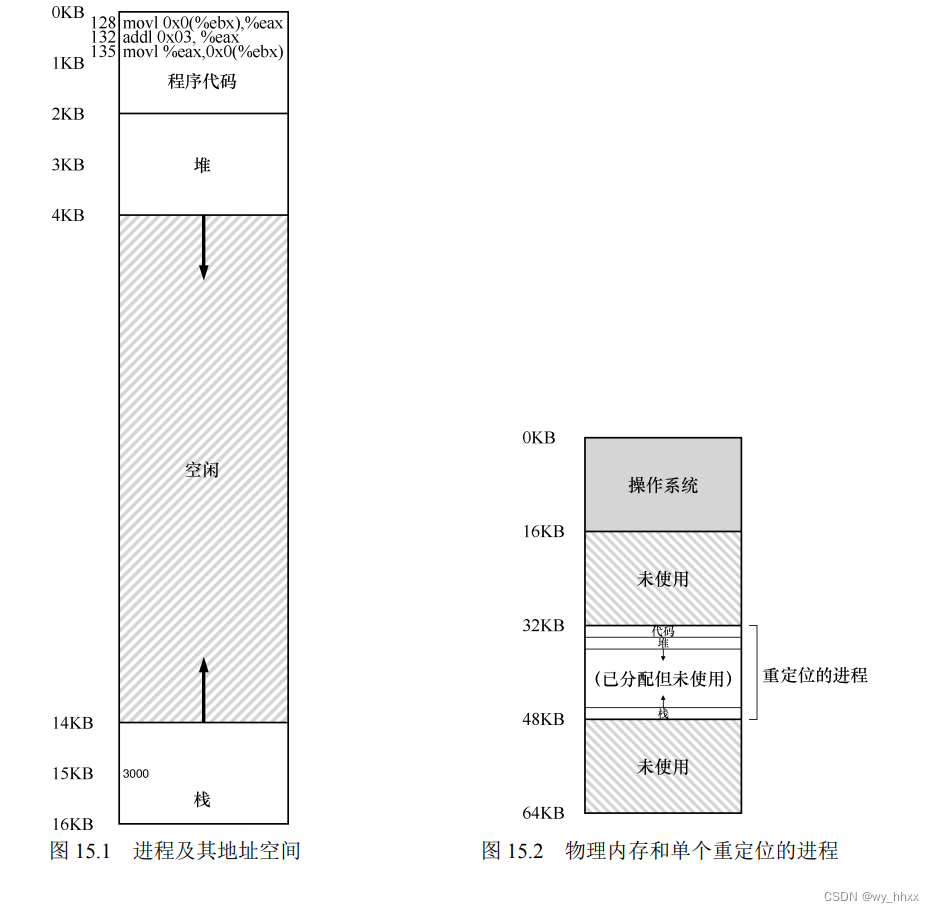
图 15.1 从程序的角度来看,它的地址空间(address space)从 0 开始到 16KB 结束。它包含的所有内存引用都应该在这个范围内。
图 15.2 展示了一个例子,操作系统将第一块物理内存留给了自己,并将上述例子中的进程地址空间重定位到从 32KB 开始的物理内存地址。剩下的两块内存空闲(16~32KB 和 48~64KB)。
将虚拟地址转换为物理地址,即地址转换(address translation)技术。
由于这种重定位是在运行时发生的,这种技术一般被称为动态重定位(dynamic relocation)。
1.1.2 界限寄存器(提供访问保护)
上例,界限寄存器被置为 16KB。如果进程需要访问超过这个界限或者为负数的虚拟地址,CPU 将触发异常,进程最终可能被终止。
这种基址寄存器配合界限寄存器的硬件结构是芯片中的(每个 CPU 一对)。有时我们将
CPU 的这个负责地址转换的部分统称为内存管理单元(Memory Management Unit,MMU)。
1.2 操作系统的工作

说明:在上下文切换时,操作系统也必须执行一些额外的操作。
每个 CPU 只有一个基址寄存器和一个界限寄存器,对于每个运行的程序它们的值不同。因此,
在切换进程时,操作系统必须保存和恢复基础和界限寄存器。
2. 分段
2.1 分段:泛化的基址/界限
在 MMU 中引入不止一个基址和界限寄存器对,而是给地址空间内的每个逻辑段(segment)一对。一个段只是地址空间里的一个连续定长的区域。
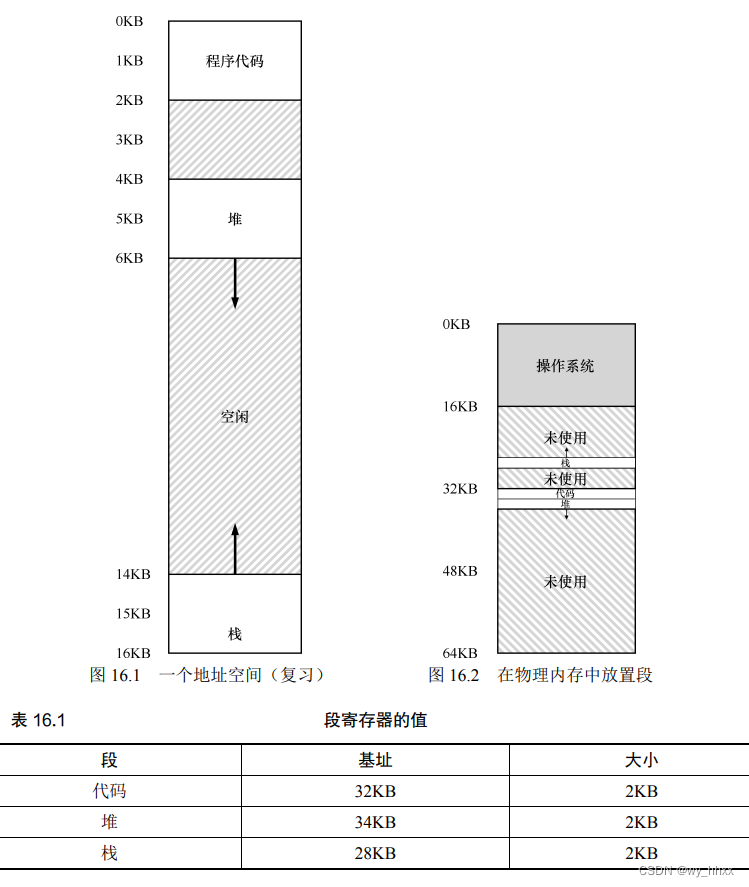
把图 16.1 中的地址空间放入物理内存。通过给每个段一对基址和界限寄存器,可以将每个段独立地放入物理内存。如图 16.2 所示,64KB 的物理内存中放置了 3 个段(为操作系统保留 16KB)。从图中可以看到,只有已用的内存才在物理内存中分配空间,因此可以容纳巨大的地址空间。
2.2 引用哪个段
硬件在地址转换时使用段寄存器。它如何知道段内的偏移量,以及地址引用了哪个段?
可以用虚拟地址的开头几位来标识不同的段,之前的例子有 3 个段,因此需要两位来标识。
如果用 14 位虚拟地址的前两位来标识,那么虚拟地址如下所示:
| 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 段 | 偏移量 | ||||||||||||
上述例子中,如果前两位是 00,硬件就知道这是属于代码段的地址,使用代码段的基址和界限;
如果前两位是 01,则是堆地址,使用堆的基址和界限。
虚拟地址 4200(在堆中)的二进制形式如下:
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
段 01 -> 堆中
段内偏移 0000011 01000 -> 104(十进制)
2.3 代码和堆的地址转换举例
(1)虚拟地址100(在代码段中)
MMU 将基址值加上偏移量(100)得到实际的物理地址:100 + 32KB = 32868
检查该地址是否在界限内(100 小于 2KB),发现是的,于是发起对物理地址 32868 的引用。
(2)虚拟地址 4200(在堆中)
计算堆的偏移量:堆从虚拟地址 4K开始,4200 的偏移量是 4200 减去 4096,即 104
用这个偏移量(104)加上基址寄存器中的物理地址(34KB),得到真正的物理地址 34920。
2.4 栈的地址转换举例
在表 16.1 中,栈被重定位到物理地址 28KB。注意,它是反向增长的。
在物理内存中,它始于 28KB,增长回到 26KB,相应虚拟地址从 16KB 到 14KB。
硬件支持:除了基址和界限外,硬件还需要知道段的增长方向(用一位区分,比如 1 代表自小而大增长,0 反之)。
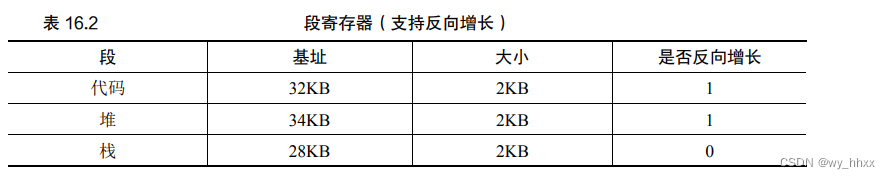
假设要访问虚拟地址 15KB,它应该映射到物理地址 27KB。
该虚拟地址的二进制形式是:11 1100 0000 0000。
从 3KB (1100 0000 0000) 中减去最大的段地址:例本中,段可以是 4KB(2^12B),因此正确的偏移量是 3KB 减去 4KB,即−1KB。
用这个反向偏移量(−1KB)加上基址(28KB),就得到了正确的物理地址 27KB。用户可以进行界限检查,确保反向偏移量的绝对值小于段的大小。
2.5 支持共享
要节省内存,有时候在地址空间之间共享(share)某些内存段是有用的,例如代码共享。
硬件支持:保护位(protection bit),标识程序是否能够读写该段,或执行其中的代码。
通过将代码段标记为只读和可执行,同样的代码可以被多个进程共享,因此物理内存中的一个段可以映射到多个虚拟地址空间。
2.6 分段解决和未解决的问题
分段解决了一些问题,
更好地支持稀疏地址空间
很快、地址转换的开销极小
代码共享
在内存中分配不同大小的段会导致一些问题,
由于段的大小不同,空闲内存被割裂成各种奇怪的大小
分段还是不足以支持更一般化的稀疏地址空间。例如,如果有一个很大但是稀疏的堆,都在一个逻辑段中,整个堆仍然必须完整地加载到内存中
3. 空闲空间管理
3.1 底层机制
3.1.1 分割与合并

假设我们只申请一个字节的内存。分配程序会执行所谓的分割(splitting)动作:它找到一块可以满足请求的空闲空间,将其分割,第一块返回给用户,第二块留在空闲列表中。

如果应用程序调用 free(10),归还堆中间的空间,会发生什么?

问题出现了:尽管整个堆现在完全空闲,却被分割成了 3 个 10 字节的区域。
这时,如果用户请求 20 字节的空间,简单遍历空闲列表会找不到这样的空闲块,因此返回失败。
为了避免这个问题,分配程序会在释放一块内存时合并(coalescing)可用空间。
在归还一块空闲内存时,查看要归还的内存块的地址及其相邻的空闲空间块。如果新归还
的空间与一个或两个原有空闲块相邻,就将它们合并为一个较大的空闲块:

3.1.2 追踪已分配空间的大小
假设:函数void free(void *ptr)接受一个指针,释放对应的内存块。请注意该接口的隐含意义,在释放空间时,用户不需告知库这块空间的大小。因此,在只传入一个指针的情况下,库必须能够弄清楚这块内存的大小。
要完成这个任务,大多数分配程序都会在头块(header)中保存一点额外的信息,它在
内存中,通常就在返回的内存块之前。

在上图的例子中,用户调用了 malloc(),并将结果保存在ptr 中:ptr = malloc(20)。
该头块中包含所分配空间的大小、一些额外的指针来加速空间释放、一个幻数来提供完整性检查,以及其他信息。我们假定,一个简单的头块包含了分配空间的大小和一个幻数。
因此,如果用户请求 N 字节的内存,库不是寻找大小为 N 的空闲块,而是寻找 N 加上头块大小的空闲块。释放空间同理,实际释放的是头块大小加上分配给用户的空间的大小。
3.1.2 嵌入空闲列表
假设我们需要管理一个 4096 字节的内存块(即堆是 4KB)。head 指针指向这块区域的起始地址,假设是 16KB,列表的状态是它只有一个条目,记录大小为 4088。(图17.3)

现在,假设有一个 100 字节的内存请求。库首先要找到一个足够大小的块。因为只有一个 4088 字节的块,所以选中这个块。然后,这个块被分割(split)为两块:一块足够满足请求(以及头块,如前所述),一块是剩余的空闲块。假设记录头块为 8 个字节(一个整数记录大小,一个整数记录幻数),堆中的空间如图 17.4 所示。
至此,对于 100 字节的请求,库从原有的一个空闲块中分配了 108 字节,返回指向它的一个指针(在上图中用 ptr 表示),并在其之前连续的 8 字节中记录头块信息,供未来的free()函数使用。同时将列表中的空闲节点缩小为 3980 字节(4088−108)。
再继续分配两个同样大小的块,图 17.5,

在这个例子中,应用程序调用 free(16500),归还了中间的一块已分配空间(sptr 指向,内存块的起始地址 16384 加上前一块的 108,和这一块的头块的 8 字节,就得到了 16500)。
库释放空间,并将空闲块加回空闲列表。假设将它插入到空闲列表的头位置。现在的空闲列表包括一个小空闲块(100 字节,由列表的头指向)和一个大空闲块(3764字节),如图 17.6 所示。
3.2 基本策略
3.2.1 最优匹配
最优匹配(best fit)首先遍历整个空闲列表,找到和请求大小一样或更大的空闲块,然后返回这组候选者中最小的一块。这就是所谓的最优匹配(也可以称为最小匹配)。
避免空间浪费 <--> 较高的性能代价
3.2.2 首次匹配
首次匹配(first fit)找到第一个足够大的块,将请求的空间返回给用户。
速度优势 <--> 有时会让空闲列表开头的部分有很多小块
因此,分配程序如何管理空闲列表的顺序就变得很重要。一种方式是基于地址排序(address-based ordering)。通过保持空闲块按内存地址有序,合并操作会很容易,从而减少了内存碎片。
3.2.3 下次匹配
下次匹配(next fit)算法多维护一个指针,指向上一次查找结束的位置。其想法是将对空闲空间的查找操作扩散到整个列表中去,避免对列表开头频繁的分割。
3.3.4 分离空闲列表
分离空闲列表(segregated list),如果某个应用程序经常申请一种(或几种)大小的内存空间,那就用一个独立的列表,只管理这样大小的对象。其他大小的请求都一给更通用的内存分配程序。
减少碎片、分配和释放都很快 <--> 应该拿出多少内 存来专门为某种大小的请求服务?
厚块分配程序(slab allocator),很优雅地处理了这个问题。
具体来说,在内核启动时,它为可能频繁请求的内核对象创建一些对象缓存(object cache),如锁和文件系统 inode 等。这些的对象缓存每个分离了特定大小的空闲列表,因此能够很快地响应内存请求和释放。如果某个缓存中的空闲空间快耗尽时,它就向通用内存分配程序申请一些内存厚块(slab)(总量是页大小和对象大小的公倍数)。相反,如果给定厚块中对象的引用计数变为 0,通用的内存分配程序可以从专门的分配程序中回收这些空间,这通常发生在虚拟内存系统需要更多的空间的时候。
3.3.5 伙伴系统
因为合并对分配程序很关键,所以人们设计了一些方法,让合并变得简单,一个好例子就是二分伙伴分配程序(binary buddy allocator)。
在这种系统中,空闲空间首先从概念上被看成大小为 2N 的大空间。当有一个内存分配请求时,空闲空间被递归地一分为二,直到刚好可以满足请求的大小(再一分为二就无法满足)。这时,请求的块被返回给用户。在下面的例子中,一个 64KB 大小的空闲空间被切分,以便提供 7KB 的块:

这种分配策略只允许分配 2 的整数次幂大小的空闲块,因此会有内部碎片(internal fragment)的麻烦。
伙伴系统的漂亮之处在于块被释放时。如果将这个 8KB 的块归还给空闲列表,分配程序会检查“伙伴”8KB 是否空闲。如果是,就合二为一,变成 16KB 的块。然后会检查这个 16KB 块的伙伴是否空闲,如果是,就合并这两块。这个递归合并过程继续上溯,直到合并整个内存区域,或者某一个块的伙伴还没有被释放。
确定某个块的伙伴很容易 --> 每对互为伙伴的块只有一位不同,正是这一位决定了它们在整个伙伴树中的层次。
![[附源码]java毕业设计医院预约挂号管理系统](https://img-blog.csdnimg.cn/ae1f0f6f7ce044298bcc42d31dbd7afd.png)