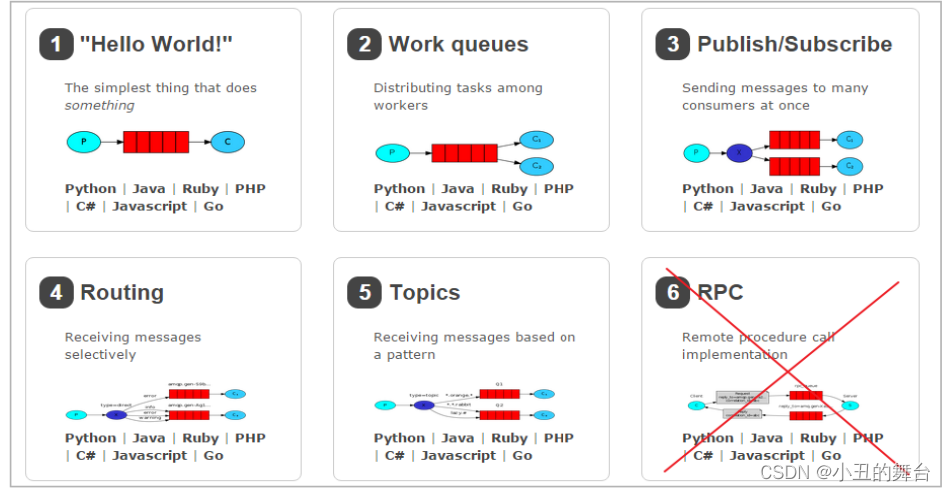
Deep Coupled Feedback Network for Joint Exposure Fusion and Image Super-Resolution
(用于联合曝光融合和图像超分辨的深度耦合反馈网络)
如今,人们已经习惯了拍照来记录自己的日常生活,然而,照片实际上与真实的自然场景并不一致。两个主要区别是,由于相机固有的成像限制,照片倾向于具有低动态范围 (LDR) 和低分辨率 (LR)。多曝光图像融合 (MEF) 和图像超分辨率 (SR) 是解决这两个问题的两种广泛使用的技术。然而,它们通常被视为独立研究。在本文中,我们提出了一种深度耦合反馈网络 (CF-Net) 来同时实现MEF和SR。给定一对低分辨率的曝光过度和曝光不足的LDR图像,我们的CF-Net能够生成具有高动态范围 (HDR) 和高分辨率的图像。具体来说,CF-Net由两个耦合的递归子网络组成,分别以LR过曝光和曝光不足的图像作为输入。每个子网络由一个特征提取块 (FEB),一个超分辨率块 (SRB) 和几个耦合反馈块 (CFB) 组成。FEB和SRB将从输入的LDR图像中提取高级特征,这对于增强分辨率是有帮助的。CFB排列在SRB之后,其作用是从两个子网络的SRB中吸收学习到的特征,从而可以产生高分辨率的HDR图像。我们有一系列CFB,以逐步完善融合的高分辨率HDR图像。
介绍
多曝光图像融合旨在融合具有不同曝光水平的多个LDR图像,以生成具有高动态范围 (HDR) 的图像。根据所需的LDR图像数量,MEF方法可以大致分为两类: 非极端曝光融合和极端曝光融合。在非极端情况下,融合性能与可获得的LDR图像的数量高度相关。大量的LDR图像通常会导致更好的融合结果。然而,大量的LDR图像不可避免地增加了存储和计算复杂性。为了克服这个缺点,最近出现了一些极端融合作品,它们只需要一对极端曝光图像。由于极端曝光图像中的信息通常是隐式的,因此它们利用深度卷积神经网络 (CNNs) 来充分探索和融合这些信息。我们的工作也属于极端融合的范畴。单图像超分辨率 (SR) 旨在从单个低分辨率 (LR) 图像中恢复高分辨率 (HR) 图像。传统方法主要基于字典学习,其中分别针对LR和HR图像学习两个字典。LR和HR图像补丁需要在学习的字典上共享相同的稀疏表示,以实现SR。最近,通过CNNs强大的表示能力的壮举,已经开发了许多方法,使用深度学习来学习从LR到HR图像的复杂非线性映射,并且它们实现了最先进的性能。然而,尽管对MEF和SR进行了大量研究,但它们通常被视为两个独立的研究问题。
我们提出了一种称为耦合反馈网络 (CF-Net) 的深度神经网络,该网络旨在充分利用图像融合和超分辨率之间的交互和协作,仅从一对LR极度曝光的图像中生成HR融合的HDR图像。据我们所知,这是第一次提出端到端CNN框架,以同时实现最先进的MEF和SR性能。
贡献
1)我们提出了一种称为耦合反馈网络 (CF-Net) 的两分支递归网络,以同时实现极端曝光融合和超分辨率。我们的CF-Net旨在实现它们之间的协作和交互,而不是简单地级联这两个任务,从而大大提高了SR和融合性能。
2)我们设计了一种新的耦合反馈块 (CFB),它是CF-Net的基本组件。CFB具有特殊的放大-缩小架构,可以接受来自曝光过度和曝光不足的LR图像的高级功能; 因此,可以保证SR和融合性能。
相关工作
Multi-Exposure Image Fusion
在非极端情况下,大多数方法共享类似的两步融合过程。他们首先计算每个LDR图像的权重,然后返回LDR图像序列的加权和作为融合结果。具体来说,Mertens等人提出通过测量每个像素的感知质量来计算它们的权重,然后通过组装具有最高质量的像素来融合所有LDR图像。Raman等人提出使用双边滤波器来检测强或弱边缘,然后对强边缘分配更大的权重,以获得每个LDR图像的权重图。后来,Li等人提出了根据局部对比度、亮度和颜色不相似性来估计每个LDR图像的权重,并使用递归滤波来细化原始的权重图,以去除嘈杂的伪影。与上述以像素级计算权重图的方法不同,Ma等人提出了一种结构补丁分解方法,该方法在补丁级操作图像融合。该方法无需进一步的后处理即可获得无噪声的权重图,并且可以克服重影伪影。Li等人深入研究了SPD-MEF,使其在不降低性能的情况下加快了30倍以上的速度。此外,他们开发了SPD-MEF的多尺度扩展,称为快速多尺度SPD-MEF,可以有效减少强边缘周围的晕圈效应。缺点: 通常需要许多LDR图像来覆盖所有范围以获得良好的融合,这可能导致高存储负担和计算复杂度。
极端曝光融合的方法,可以生成仅具有两个LDR图像作为输入的融合HDR图像,即一个过度曝光和一个曝光不足的图像。具体来说,Prabhakar等人引入了用于极端暴露融合的无监督深度学习框架。卷积神经网络用于处理输入图像对的亮度通道,而其他两个通道则通过加权融合进行融合。后来Ma等人提出了MEF-NET,其中输入图像的下采样版本被馈送到网络中以生成权重图,从而可以大大降低计算成本。最近,Deng等人提出了一种稀疏编码启发网络,该网络可以区分输入图像对之间的共同和独特特征,以实现最先进的融合性能。Jung等人提出了一种用于图像融合的DIF-Net,其中使用多通道图像对比度的结构张量表示构造了无监督损失函数。最近,Xu等人提出了一种用于多曝光图像融合的生成对抗网络,以提高融合图像的感知质量。Xu等人又提出了一种端到端无监督图像融合网络,该网络可以使用一个统一网络处理不同的多模态图像融合任务,而无需任何地面真实图像。
Single Image Super-Resolution
单图像超分辨率是一个不适定的逆问题,因为一个LR图像可能对应于许多不同的HR图像。已经提出了许多方法来减少这种歧义(目的),以找到真实的HR图像。我们首先回顾了基于字典学习的传统方法,然后介绍了基于深度学习的最新方法。许多传统的SR方法都依靠字典学习和稀疏表示来恢复HR图像。代表性的算法包括SCSR 、CDL、A+和CSC。具体来说,Zeyde等人利用k-svd算法对LR和HR图像都学习过完备的字典,假设LR和HR对应物共享相同的稀疏系数。但是,稀疏系数的计算非常耗时。为了解决这个问题,A+建议将训练补丁分类为不同的集群,并为每个集群预先计算从LR到HR补丁的投影。然后,可以避免稀疏系数的计算,从而大大提高了计算速度。由于传统的稀疏编码是基于补丁的,因此没有利用相邻补丁之间的邻域信息,这可能会降低重建精度。为了解决这个问题,CSC提出使用卷积字典学习来解决SISR问题,其中稀疏表示是在图像级别中计算的。
目前也出现了许多基于SCSR的方法(略)
方法
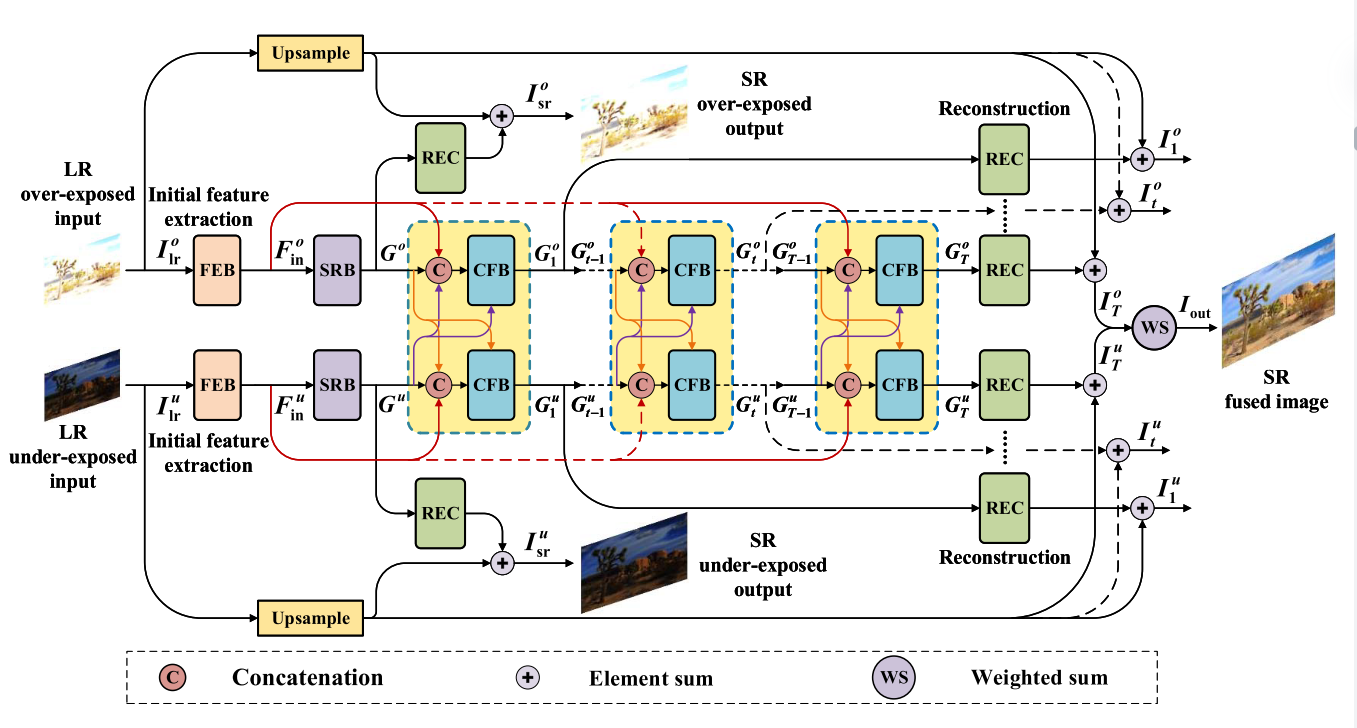
图1显示了所提出的CF-Net的整体网络架构。可以看出,我们的CF-Net由两个耦合的递归子网络组成,其中LR过度曝光或曝光不足的图像作为输入。每个子网络包含一个初始特征提取块 (FEB),一个超分辨率块 (SRB) 和几个耦合反馈块 (CFB)。具体来说,FEB旨在从LR输入中提取基本特征,以支持随后的SRB和CFB。

FEB由两个具有PReLU激活的卷积层组成: 第一层具有256个尺寸为3 × 3的滤波器,第二层具有64个尺寸为1 × 1的滤波器。第一层用于提取基本的LR特征,而第二层用于进一步集成交叉通道特征以使其更加紧凑。

在这里,我们采用 Li等人提出的反馈块架构作为我们的SRB架构。具体来说,它包含几个投影组,它们之间具有密集的跳过连接。每个投影组包括上采样和下采样操作。SRB学习的高级功能可以表示为:
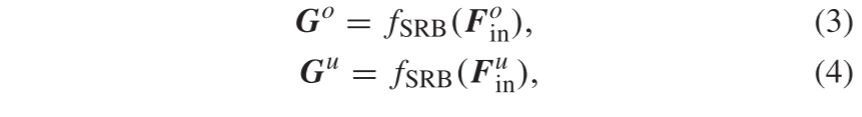
其中fSRB表示SRB的操作。在这里,G^o和 G^u分别是提取的过度曝光和曝光不足图像的高级特征。为了重建超分辨图像,我们使用重建块 (REC) 将G^o和 G^u映射到高分辨率图像。重建块由反卷积层和卷积层组成。考虑到跳过连接,通过将双线性上采样图像添加到重建的残差图像中,可以获得SRB之后的最终超分辨图像:
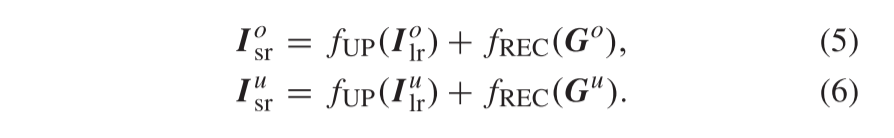
这里,fUP表示双线性放大,而fREC表示重建操作。REC块彼此不共享参数。

耦合反馈块 (CFB) 是CF-NET的核心组件,旨在通过复杂的网络连接同时实现超分辨率和图像融合。与前面提到的FEB和SRB分别只涉及一个块不同,我们使用了一系列相互连接的CGB,如图1所示,(t − 1)-第 (t>1) CFB的输出用作第t个CFB的输入。除了这个输入之外,第t个CFB还有另外两个输入。

这意味着我们接受SRB的输出作为第一CFB的输入。在公式(7)中的三个输入中。前两个输入对超分辨率性能的贡献更大,而最后一个输入则用于改善融合结果。这三个输入不是简单地串接到CFB中,而是具有精心设计的连接
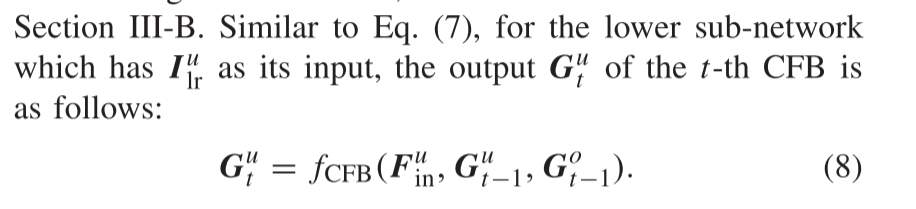
在每个CFB之后,我们可以通过以下方式重建融合的SR图像:
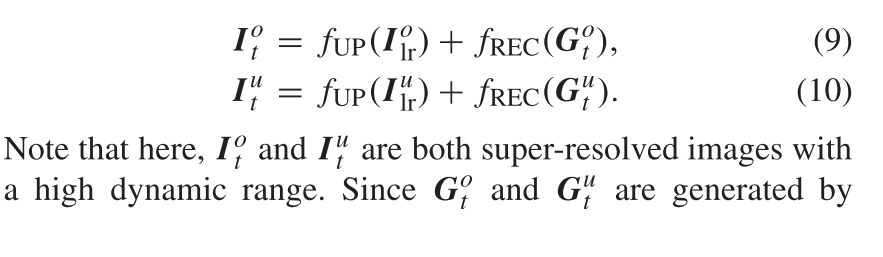

Coupled Feedback Block (CFB)
耦合反馈块 (CFB) 是我们CF-NET的基本和核心组件。正如许多研究所验证的,反馈机制有助于图像恢复。在本文中,我们提出了一种耦合反馈机制,该机制被证明可以为图像超分辨率和图像融合任务带来巨大的好处。图2显示了提议的CFB的详细架构。尽管我们在网络中有一系列CFB,但每个CFB的体系结构都是相同的。在这里,我们以上层子网络中的第t个CFB为例,介绍其内部结构及其与其他块的相互作用。
如图2所示,在上层子网络中,第t个CFB接受三个输入: 由FEB提取的一个基本特征
F
o
F^o
Fo in,两个反馈特征
G
o
G^o
Go t-1,
G
u
G^u
Gu t-1来自先前的CFBs。这两个反馈功能具有不同的作用。具体来说,
G
o
G^o
Go~t − 1~是来自同一子网络的反馈特征,因此 其主要作用是校正基本特征
F
o
F^o
Foin以提高SR性能 。相比之下,**
G
u
G^u
Gu ~t − 1~** 是来自另一个子网络的反馈,其 主要作用是带来互补信息以提高融合性能。这三个输入首先由一组1 × 1滤波器串联和融合,如下所示:

之后,我们使用一系列投影组重复执行以
L
o
L^o
Lo t (0) 为输入的放大和缩小操作,以提取更有效的高级特征。具体地,在每个投影组中,我们首先通过反卷积层进行上采样以获得HR特征图,然后通过卷积层进行下采样以生成LR特征图。我们使用密集连接来考虑所有先前的特征进行上采样和下采样。假设
L
o
L^o
Lo t(n)和
H
o
H^o
Ho t (n) 是第t个CFB中第n个投影组中提取的LR和HR特征图,我们可以得到
H
o
H^o
Hot (n) 如下:
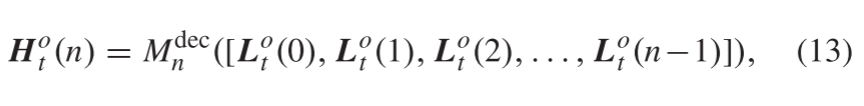
其中
M
d
e
c
M^dec
Mdec n指示第n个投影组中的反卷积操作。正如我们从Eq()13)中看到的那样。将所有先前的LR特征图级联以生成HR特征图。类似地,第n个投影组中的LR特征图
L
o
L^o
Lot (n) 可以通过考虑所有先前的HR特征图来生成:
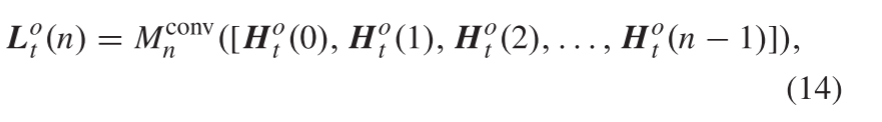
其中
M
c
o
n
v
M^conv
Mconvn表示第n个投影组中的卷积运算。在这里,可以通过改变步幅大小来调整下采样比例。
如前所述,
G
u
G^u
Gu ~t − 1~作为来自对方子网络的反馈特征,主要负责提高融合性能。然而,我们发现,随着投影组数的增加,
G
u
G^u
Gu ~t − 1~的影响逐渐下降,导致不令人满意的融合结果。可能的原因是
G
u
G^u
Gu ~t − 1~的记忆在长投影组后逐渐消失。为了加强
G
u
G^u
Gu ~t − 1~的影响,我们不仅将其作为CFB开始时的输入,还将其嵌入投影组的中间,以重新刺激记忆。对于投影组的总数N,

最后,在N个投影组之后,我们从每个投影组中收集所有LR特征图,并使用一组1 × 1滤波器将它们融合在一起,以形成第t个CFB的输出,如下所示:

在这里,Mout表示使用一组1 × 1滤波器的卷积。第t个CFB的输出 G o G^o Got具有两个流向。一方面,转t流到重建块以生成第t个CFB的融合HR图像。另一方面, G o G^o Got被馈送到下一个 (t +1)-CFB作为输入,下一个CFB开始其学习过程。
(上述介绍了上层子网中的CFB。对于下部子网络中的CFB,它们具有与上部子网络中的CFB对称的体系结构。图2显示了上下子网络中CFB的关系)
Loss Function
1) Mean Structural Similarity Index Metric:
在本文中,我们采用了平均结构二度指标 (mean dtructural dimilarity index metric (MSSIM)) 损失来以端到端的方式训练网络。MSSIM起源于SSIM,它最初是由Wang等人提出的测量失真图像补丁和参考图像补丁之间的差异。与均方误差 (MSE) 相比,它可以更好地描述图像的感知质量。给定失真的图像补丁x和参考图像补丁y,SSIM由以下公式定义:
上述公式只能计算补丁级别的SSIM值。为了在图像级别测量SSIM值,我们需要使用MSSIM,它是通过对补丁中的所有SSIM值进行平均来计算的:

2) Loss Function:
由于我们的工作旨在同时实现超分辨率和图像融合,因此我们设置了分层损耗约束以保证网络的训练效率。我们的CF-NET的总损失函数定义如下:

Eq(20) 中的损失函数可以分为两部分。前两个损失用于保证SRB的有效性,而最后一个损失用于确保每个CFB都能正常工作。换句话说,前两个损失是为了确保超分辨率性能而形成的,而最后一个损失是为了同时保证超分辨率和曝光融合性能而构造的。前两次损失也是最后一次损失的重要基础。通过最小化Eq(20)中定义的损耗,以端到端的方式训练整个网络。使用训练好的模型,在测试阶段,我们应用Eq(11) 获取最终输出图像。





![[附源码]java毕业设计医院档案管理系统](https://img-blog.csdnimg.cn/265a91fb4866483c9d6eae4287b94c36.png)