文章目录
- 哈希表
- 概念
- 插入元素
- 搜索元素
- 结构
- 冲突
- 概念
- 冲突-避免
- 哈希函数设计
- 常见哈希函数
- 调节负载因子
- 负载因子定义
- 负载因子和冲突率的关系
- 冲突解决
- 冲突-解决-闭散列
- 线性探测
- 过程
- 缺点
- 二次探测
- 概念
- 缺点
- 冲突-解决-开散列/哈希桶
- 概念
- 结构
- 代码实现哈希桶
- hashcode 和 equals
- 问题
- 面试题:HashMap和concurrentHashMap的区别
哈希表
概念
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
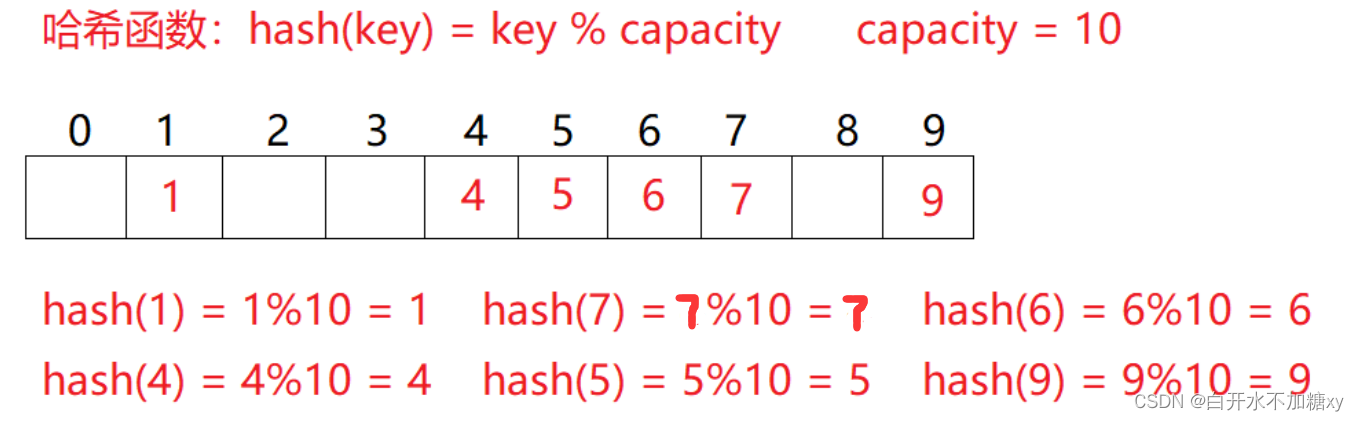
以上方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(HashTable)(或者称散列表)
结构
冲突
概念
哈希冲突:两个不同关键字key通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
冲突-避免
哈希函数设计
常见哈希函数
- 直接定制法(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀 缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
调节负载因子
负载因子定义

负载因子和冲突率的关系
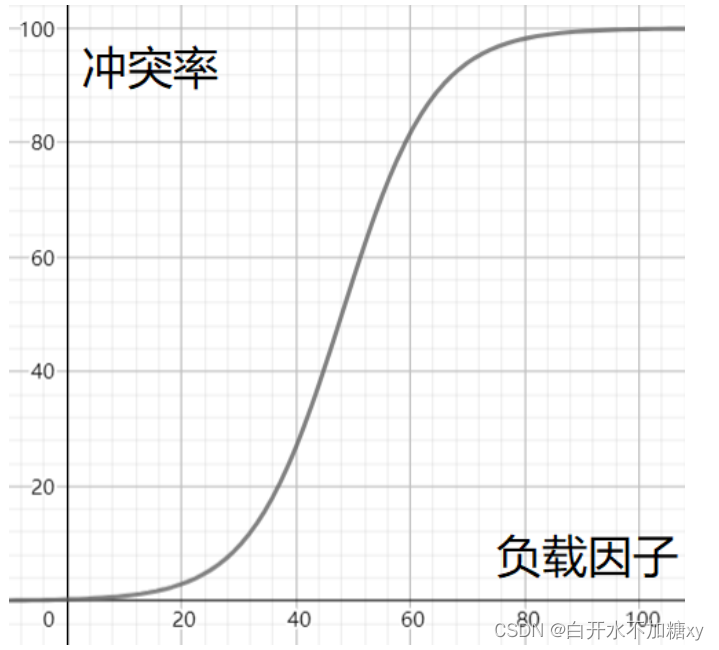
由图不难发现,只有降低负载因子,才能降低冲突率。那么想要降低冲突率,只能增加散列表长度。
冲突解决
冲突-解决-闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个”空位置中去。
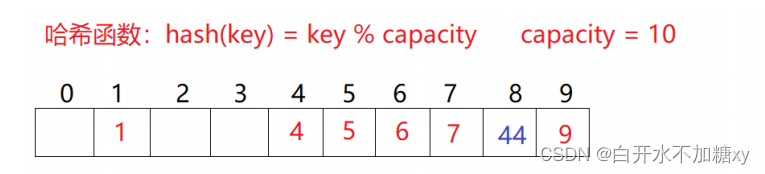
线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
过程
- 通过哈希函数获取待插入元素在哈希表中的位置
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素。
如下,44与4发生哈希冲突,则向后找到哈希表中下一个空位置为下标8处。
缺点
通过以上概念及过程可知,线性探测法存在以下不足:
- 不好删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若**直接删除元素会影响其他元素的搜索**。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。 - 冲突元素分布紧密。由于每次冲突发生都是向后 找空位置(遇到后就存进去),此举会使得 尽量冲突的元素都放在了一起。
二次探测
概念
为了避免 线性探测冲突数据堆积的问题,二次探测提出找下一个空位置的方法:

其中:H0 是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
- 当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。
- 在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
缺点
空间利用率低
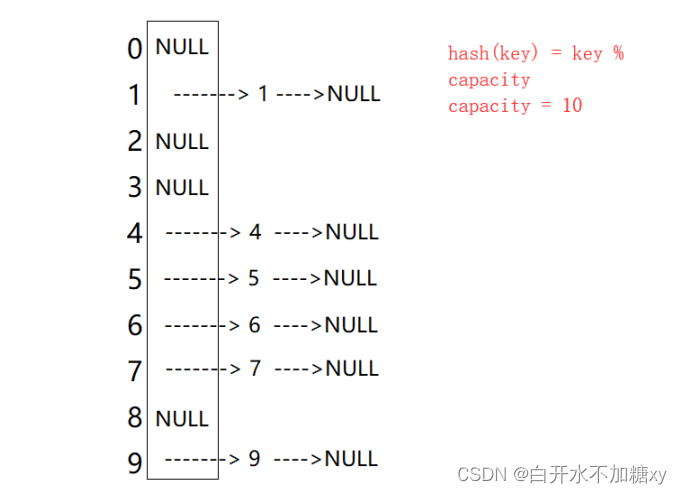
冲突-解决-开散列/哈希桶
数组+链表+红黑树
概念
开散列又叫做链地址法,首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来(冲突的元素),各链表的头结点存储在哈希表中。
结构
代码实现哈希桶
public class HashBuck {
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
public Node[] array;
public int usedSize;//存放的数据的个数
public static final double DEFAULT_LOAD_FACTOR = 0.75;//默认的负载因子
public HashBuck () {
array = new Node[8];
}
/**
*
* @param key
* @param val
* @return 代表你插入的元素的val
*/
public boolean put(int key,int val) {
Node node = new Node(key,val);
//1、位置
int index = key % array.length;
//2、遍历这个下标的链表
Node cur = array[index];//就是一个链表的头节点
while (cur != null) {
if(cur.key == key) {
cur.val = val;//更新val值
return false;
}
cur = cur.next;
}
//3、遍历完成了当前下标的链表,开始进行插入
node.next = array[index];
array[index] = node;
this.usedSize++;
//4、存放元素之后,判断当前哈希桶当中的负载因子 是否超过了默认的负载因子
if(loadFactor() >= DEFAULT_LOAD_FACTOR) {
//5、扩容
resize();
}
return true;
}
/**
* 扩容的同时 要进行重新哈希
*/
private void resize() {
//1、重新申请2倍的数组
Node[] tmp = new Node[array.length*2];
//2、遍历原来的数组,把每个下标的链表的节点,都重新进行哈希
for (int i = 0; i < array.length; i++) {
Node cur = array[i];
while (cur != null) {
int newIndex = cur.key % tmp.length;//新的数组的下标
Node curNext = cur.next;//先要记录下来下一个
cur.next = tmp[newIndex];
tmp[newIndex] = cur;
cur = curNext;//这里注意
}
}
array = tmp;
}
public int get(int key) {
//1、确定位置
int index = key % array.length;
Node cur = array[index];
while (cur != null) {
if(cur.key == key) {
return cur.val;
}
cur = cur.next;
}
return -1;
}
/**
* 计算当前哈希桶当中的负载因子
* @return
*/
private double loadFactor() {
return this.usedSize*1.0 / this.array.length;
}
}
public class TestDemo {
public static void main2(String[] args) {
HashBuck hashBuck = new HashBuck();
hashBuck.put(1,1);
hashBuck.put(2,2);
hashBuck.put(3,3);
hashBuck.put(6,6);
hashBuck.put(14,14);// 14
hashBuck.put(24,44);// 8
System.out.println("hello");
}
}
注意
哈希表扩容需注意:需要进行重新哈希!!!
如果哈希桶中存放引用类型
重写hashCode()和equals()方法
class Person {
public String id;
public Person(String id) {
this.id = id;
}
@Override
public String toString() {
return "Person{" +
"id='" + id + '\'' +
'}';
}
/**
* 在下标底下 找哪个节点的key和我是一样的
* @param o
* @return
*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(id, person.id);
}
/**
* 找节点的小标的
* @return
*/
@Override
public int hashCode() {
return Objects.hash(id);
}
}
public class TestDemo {
public static void main(String[] args) {
HashBuck2<Person,String> map = new HashBuck2<>();
Person person1 = new Person("123456");
Person person2 = new Person("123456");
map.put(person1,"xyy");
System.out.println(map.get(person2));//xyy
}
public static void main3(String[] args) {
HashMap<Person,String> map = new HashMap<>();
Person person1 = new Person("123456");
Person person2 = new Person("123456");
System.out.println(person1.hashCode());//找位置
System.out.println(person2.hashCode());
map.put(person1,"xyy");
System.out.println(map.get(person2));
}
}
HashMap 第一次put元素时,分配内存。
hashcode 和 equals
1、hashcode一样equals一定一样吗?不一定
2、equals一样hashcode一定一样吗?一定
HashCode简介 ——参考HashCode()和equals()的区别
hashCode()方法的作用是获取哈希码,返回的是一个int整数
Object类中的hashCode()方法定义如下
public native int hashCode();
哈希码的作用是确定对象在哈希表的索引下标。比如HashSet和HashMap就是使用了hashCode方法确定索引下标。如果两个对象返回的hashCode相同,就被称为“哈希冲突”。
equals简介
equals()方法的作用很简单,就是判断两个对象是否相等,equals()方法是定义在Object类中,而所有的类的父类都是Object,所以如果不重写equals方法则会调用Object类的equals方法。
Object类中的equals()方法定义如下
public boolean equals(Object obj) {
return (this == obj);
}
在equals()方法中的==,那么在Java中有什么含义呢,
我们都知道在Java中分为基本数据类型和引用数据类型。那么==在这两个类型中作用是不一样的。
基本数据类型:比较的是 两边值是否相等 -》==
引用数据类型: 比较的是 两边内存地址是否相等-》equals()
问题
1.如果new HashMap(19),bucket数组多大? 32,数组长度一定要是接近2的n次幂
2.HashMap什么时候开辟bucket数组占用内存? 默认的构造方法,不带参数的第一次put的时候,大小为16
3.hashMap何时扩容? 超过了负载因子
4.当两个对象的hashcode相同会发生什么? 碰撞(哈希冲突)
5.如果两个键的hashcode相同,你如何获取值对象? 遍历与hashCode值相等时相连的链表,直到相等(通过equals()判断)或者null
6.你了解重新调整HashMap大小存在什么问题吗? 必须重新哈希
面试题:HashMap和concurrentHashMap的区别
看到其他博主一篇较好的总结:HashMap和concurrentHashMap的区别
之后自己进一步学习后,会将此部分整理更新。






![[论文阅读] Adversarial Learning for Semi-Supervised Semantic Segmentation](https://img-blog.csdnimg.cn/0e32abb15ce04976bfdaa186b52f5d8a.jpeg#pic_center)