[论文地址] [代码] [BMVC 18]
Abstract
我们提出了一种使用对抗性网络进行半监督性语义分割的方法。虽然大多数现有的判别器都是在图像层面上对输入图像进行真假分类的训练,但我们以完全卷积的方式设计了一个判别器,以区分预测的概率图和考虑到空间分辨率的地面真实分割分布。我们表明,通过将对抗性损失与拟议模型的标准交叉熵损失相结合,所提出的判别器可用于提高语义分割的准确性。此外,全卷积判别器通过发现未标记图像的预测结果中值得信赖的区域,从而提供额外的监督信号,实现半监督学习。与现有的利用弱标记图像的方法相比,我们的方法利用未标记的图像来增强分割模型。在PASCAL VOC 2012和Cityscapes数据集上的实验结果证明了所提算法的有效性。
Method
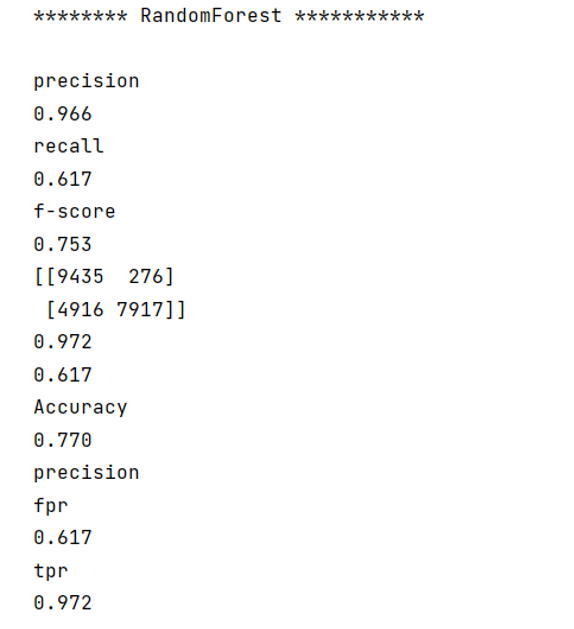
本文采用对抗学习进行了半监督分割任务,最大的特点在于判别器的设计。一般来讲,判别器做的都是一个二分类问题,属于分类网络——输入一张图片,给出一个二值的结果(真/假);而本文的判别器做的是分割问题,属于一种FCN,输出为Confidence Map;整体流程如下所示:

额外值得注意一点的是,本文的半监督不需要对原有的语义分割网络进行任何修改,只是引入了额外的判别器框架,因此理论上可迁移性会比较好(甚至可以移到别的任务上)。
具体来说,判别器接受的输入为两种分割结果——真实的Ground Truth Mask(图中的Label Map)以及网络的预测结果pred,输出为Confidence Map。对于置信度图的每个像素的值,为1表示网络认为该位置的预测结果是对的(真),为0则表示是错的(假)。因此,对于判别器的训练,输入ground truth mask,判别器给出的输出应该是一张全为1的map;输入网络的预测,判别器给出的输出应该是一张全0的map。
单纯从全监督的角度理解,加入这么个mask,其实也可以起到训练分割网络的作用;即,网络的预测结果只要和GT Mask一模一样,那么判别器自然无法区分;不过,单凭判别器并不能约束这个mask和原来的图像就是一一对应的,因此正经的交叉熵分割loss也不能少。
那么为什么加入了判别器就能起到半监督的作用呢?为了弄明白这一点,我们得了解下网络的训练流程。在全监督训练阶段,利用已标注的图像,分割网络得到了基本的训练,而判别器也被训练用于如何区分GT Mask和pred;在半监督训练阶段,判别器参数固定。对于没有标注的样本,判别器相当于起到了一个"虚拟GT的作用"。通过鼓励分割网络对未标注的图像(未标注训练集/测试集)产生判别器无法区分的样本,从而进一步提升网络的分割性能。
图中所涉及到的半监督分割损失如下: L semi = − ∑ h , w ∑ c ∈ C I ( D ( S ( X n ) ) ( h , w ) > T semi ) ⋅ Y ^ n ( h , w , c ) log ( S ( X n ) ( h , w , c ) ) \mathcal{L}_{\text {semi }}=-\sum_{h, w} \sum_{c \in C} I\left(D\left(S\left(\mathbf{X}_n\right)\right)^{(h, w)}>T_{\text {semi }}\right) \cdot \hat{\mathbf{Y}}_n^{(h, w, c)} \log \left(S\left(\mathbf{X}_n\right)^{(h, w, c)}\right) Lsemi =−h,w∑c∈C∑I(D(S(Xn))(h,w)>Tsemi )⋅Y^n(h,w,c)log(S(Xn)(h,w,c)) 这里的超参 T s e m i T_{semi} Tsemi的建议值为0.1到0.3,也就是对confidence map的置信度要求没那么高(否则一般是0.5)。