Ubuntu 16.4 配置Hadoop集群
- 总体步骤
- 环境说明
- 虚拟机配置
- java安装
- hadoop安装与配置
- 克隆虚拟机
- ssh安装使用,免密登录
- 更改hadoop配置
- 结束语
总体步骤
1、虚拟机配置
2、java安装
3、hadoop下载配置
4、复制虚拟机
5、ip更换,使用固定ip,并且每台机器访问外网
6、免密登录,ssh
7、更改hadoop配置
8、启动
环境说明
1、VMware
2、虚拟机:Ubuntu16.4
3、hadoop 3.3.0
4、jdk-1.8.0
虚拟机配置
1、VMware和Ubuntu16.4的下载和安装省略
我将我的虚拟机配置贴在下方,可以根据自己的电脑配置做调整

2、虚拟机创建完成以后,这有个重点,虚拟机创建以后是一个hadoop用户,不是root用户,这里需要知道root用户的密码。新创建的虚拟机root用户时没有密码的,我们需要设置一个密码。

这个root密码后面是需要的,否则会造成一定的麻烦。
3、查看虚拟机的ip,设置成固定的ip。由于在自己虚拟机里要搭建集群,需要三台电脑,ip不能一样。


这里有个重点,虚拟机和自己真实的主机必须是NAT的连接方式,通过虚拟网络编辑器可以看到子网的ip是多少。我们可以去自己本地主机的电脑上修改成使用指定的ip,这样虚拟机里的ip不会再变化。


我们设置的ip前三位要和虚拟网络编辑器一致,我这就从192.168.220.100开始,设置好后,我们就需要进入到虚拟机里,查看一下我们的hadoop101主机的ip,将主机hadoop101的ip设置为固定ip。

这里的ens33 指的是ens33网卡,这里的ip 已经时我修改以后的了,修改完成以后记得重启下网络。
vim /etc/network/interfaces (修改静态ip)
注:Ubuntu16.4的网络配置是在这个文件下的,其他版本的虚拟机可能不在该文件下)

设置ens33网卡为静态ip
地址为192.168.220.101
子网掩码
默认网关
设置完后,你会发现你可能连不上外网,可以尝试ping www.baidu.com。至此我们还需要设置DNS
vim /etc/resolv.conf ,添加DNS服务器ip,

这里有个重点,避坑,设置好DNS后,当重启虚拟机,又不能访问外网了,因为当重启虚拟机这些配置都会消失,所以建议永久修改DNS服务器 。
vim /etc/resolvconf/resolv.conf.d/base ,在里面添加 nameserver 114.114.114.114
执行:resolvconf -u
重启网络: /etc/init.d/networking restart
完成上述不步骤再去观察/etc/resolv.conf文件,会发现会自动生成nameserver。这样每当重启虚拟机,都不用再配置一遍了。实质是对/etc/resolv.conf文件做修改,则能保证DNS的配置
4、修改主机名称。
vim /etc/hostname
这样方便我们统一管理,我这修改为hadoop101
5、最后重启虚拟机,完成以后
检查: 查看ip是否已经为自己固定的静态ip。
查看是否能上外网。
查看主机名是否正确。
查看root用户密码是否正确。
到这按理说我们应该克隆虚拟机,生成三台自己需要的虚拟机,但是每台电脑都要安装java、ssh等,我们可以先把一台电脑处理好,然后克隆后,每台电脑都有了,则不用再重复三遍。
java安装
我直接使用的Linux里面自带的jdk安装,没有自己去下载
sudo apt-cache search jdk (搜索jdk版本)
sudo apt-get install openjdk-8-jdk (安装自己需要的jdk版本)
自动安装完成以后,可以使用以下命令查看安装路径,这也是重点,后面配置环境变量都需要用到该路径
whereis java 找到/usr/bin/java
ls -lrt /usr/bin/java
ls -lrt /etc/alternatives/java

修改环境变量 :vim /etc/profile(这里就需要上述说的安装路径)
重置环境变量:source /etc/profile

验证,输入 java -version 命令,出现下图则成功。

hadoop安装与配置
上hadoop下载链接:https://archive.apache.org/dist/hadoop/common/
我下载的是hadoop-3.3.0.tar.gz,路径:/home/hadoop100/software,解压。

和java一样,需要配置环境变量
配置环境变量:vim /etc/profile
重置环境变量:source /etc/profile

验证,输入hadoop查看是否正常,如下图则正确

到这我们已经成功了一半了,继续!!
克隆虚拟机
我将克隆虚拟机放在安装jdk、安装hadoop后面,这样我们就不用再去安装了。



如上图,克隆两台虚拟机,分别为hadoop102、hadoop103
修改主机名称,修改hadoop102、hadoop103的ip为静态的。(hadoop101已经修改,无需再改)
vim /etc/hostname(修改主机名称)
vim /etc/network/interfaces (修改静态ip)
(hadoop102主机为 192.168.220.102;hadoop103主机为 192.168.220.103)
重启网络服务:/etc/init.d/networking restart
重启两台克隆的虚拟机

克隆完成以后,三台主机都要修改/etc/host 文件,将ip加进去

重启完成后检查三台主机的信息,看是否正确
①三台主机名称:hadoop101、hadoop102、hadoop103
②三台主机的ip,都是静态ip,并且都能上外网
③三台主机的java、hadoop是否正常
④三台主机的环境变量是否正常。(/etc/profile文件中)
⑤三台主机的root用户的密码是否正常
ssh安装使用,免密登录
1、三台主机都要安装ssh命令。(其实这一步可以放在克隆虚拟机前面,这样只需要安装一遍就行)
这里避坑,一直远程ssh连接不上,因为A主机安装了ssh,B主机没安装ssh,导致不连接不通。
sudo apt-get install ssh
验证:可以查看进程是否有sshd进程,也可以执行ssh查看
验证是否正常


安装完ssh后,查看/root/.ssh 是否有该目录,如果没有该目录,手动创建一个.ssh文件夹
在三台主机都使用root用户生成公钥、密钥(使用root用户是因为后面会报权限不足)
ssh-keygen -t rsa
scp id_rsa.pub hadoop101:/root/.ssh/id_rsa_102.pub (将hadoop102主机上的复制到hadoop101)
scp id_rsa.pub hadoop101:/root/.ssh/id_rsa_103.pub (将hadoop103主机上的复制到hadoop101)
再将这三个id_rsa.pub整合到一个authorized_keys 文件中
cat id_rsa.pub >> authorized_keys
cat id_rsa_102.pub >> authorized_keys
cat id_rsa_103.pub >> authorized_keys
最后把authorized_keys 再传回hadoop102、hadoop103主机
有的虚拟机可能在这就能完成免密登录了,但是有的不行,我们需要再将三台主机的防火墙关闭
关闭防火墙
service ufw stop
修改ssh密码配置文件,取消密码验证
vim /etc/ssh/sshd_config
将PermitRootLogin prohibit-password禁用
添加:PermitRootLogin yes
重启sshd服务:/etc/init.d/sshd restart

三台电脑互相验证是否可以免密登录
ssh hadoop102
ssh hadoop103

成功!!!
更改hadoop配置
注: 修改hadoop配置文件我暂时不是很清楚,我照着网上的参数配置的。待我去了解了每个参数的意思后再做补充。
重点: 三台电脑都要配置下述文件,我们可以先配置一台,然后使用scp命令将/hadoop-3.3.0/etc/hadoop/整个文件夹下的文件都拷贝到hadoop102和hadoop103。
1、需要修改多个文件的配置包括(配置文件都在hadoop解压包下的/etc/hadoop)
/hadoop-3.3.0/etc/hadoop/core-site.xml
/hadoop-3.3.0/etc/hadoop/hdfs-site.xml
/hadoop-3.3.0/etc/hadoop/yarn-site.xml
/hadoop-3.3.0/etc/hadoop/mapred-site.xml
/hadoop-3.3.0/etc/hadoop/yarn-env.sh
hadoop-3.3.0/etc/hadoop/hadoop-env.sh
hadoop-3.3.0/etc/hadoop/workers
/hadoop-3.3.0/etc/hadoop/core-site.xml 文件配置如下
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop100/software/hadoop-3.3.0/hdfs/data</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
/hadoop-3.3.0/etc/hadoop/hdfs-site.xml配置如下
<configuration>
<!-- 设置文件副本数,两个datanode,所以设置副本数为2-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop100/software/hadoop-3.3.0/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop100/software/hadoop-3.3.0/hdfs/data</value>
<final>true</final>
</property>
<!-- 指定NameNode的外部web访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 指定secondary NameNode的外部web访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>
/hadoop-3.3.0/etc/hadoop/yarn-site.xml配置如下
<configuration>
<!--指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!--环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
/hadoop-3.3.0/etc/hadoop/mapred-site.xml配置如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
/hadoop-3.3.0/etc/hadoop/yarn-env.sh 和 hadoop-3.3.0/etc/hadoop/hadoop-env.sh 都要配置jdk环境,加上下面的全局变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
hadoop-3.3.0/etc/hadoop/workers 添加你的工作用户
hadoop101
hadoop102
hadoop103
配置完成后,还需要在/hadoop-3.3.0/sbin路径下,配置下述文件
/hadoop-3.3.0/sbin/start-dfs.sh
/hadoop-3.3.0/sbin/stop-dfs.sh
/hadoop-3.3.0/sbin/start-yarn.sh
/hadoop-3.3.0/sbin/stop-yarn.sh
/hadoop-3.3.0/sbin/start-dfs.sh 和 /hadoop-3.3.0/sbin/stop-dfs.sh 配置加入如下配置
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
/hadoop-3.3.0/sbin/start-yarn.sh 和 /hadoop-3.3.0/sbin/stop-yarn.sh 加入如下配置
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
至此,所有的配置已经完成,记得将配置好的文件拷贝到另外两台虚拟机上 ,但是你会发现有一个start-all.sh 和 stop-all.sh ,start-all.sh实质上时调用了start-dfs.sh、start-yarn.sh等shell脚本。stop-all.sh同理。
在三台虚拟机都正常运行的情况下,我们可以在主机hadoop101执行/sbin/start-yarn.sh启动hadoop,在hadoop102上执行/sbin/start-yarn.sh


通过进程查看是否正常。

进入浏览器,网址浏览 hadoop101:9870、hadoop103:9868 (这两个是在前面的hdfs-site.xml文件中配置的),看是否正常。


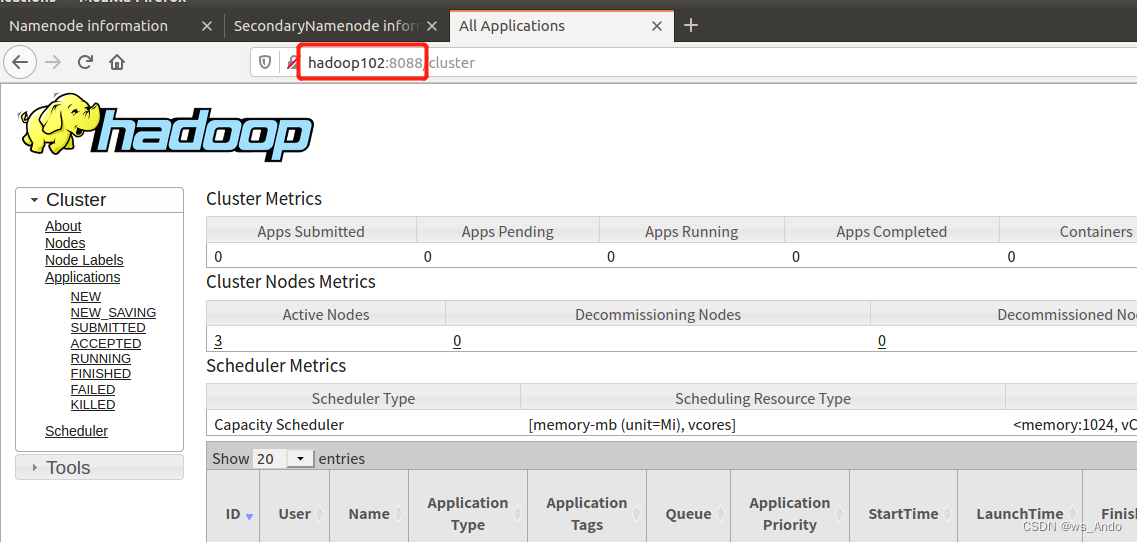
这样,hadoop搭建已经成功,并且能正常运行。
结束语
该博客是在我自己搭建成功后,作为笔记记录的,中间可能有些具体步骤忘记写了,欢迎各位看客批评指正交流。hadoop部分的配置文件,目前还不清楚为啥要这样配置,还需继续学习。