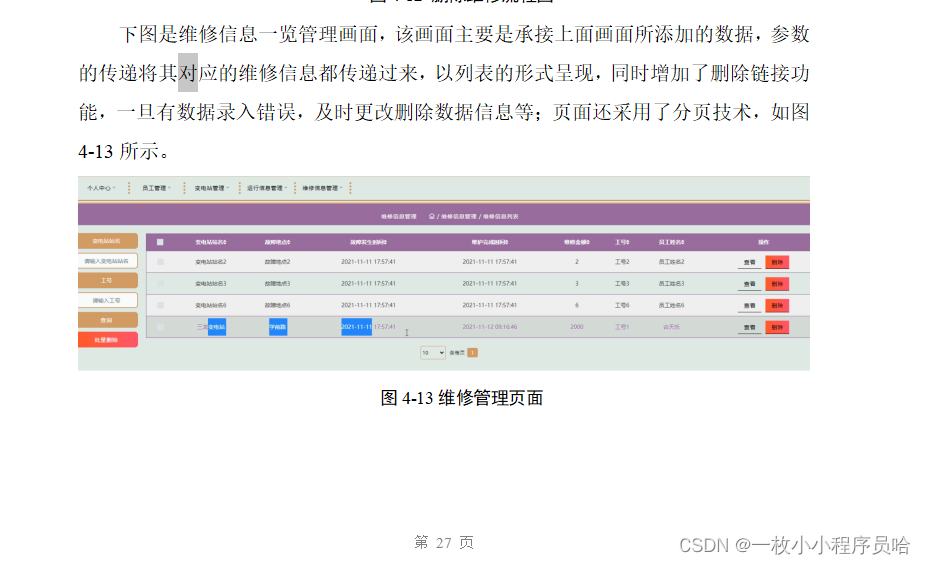
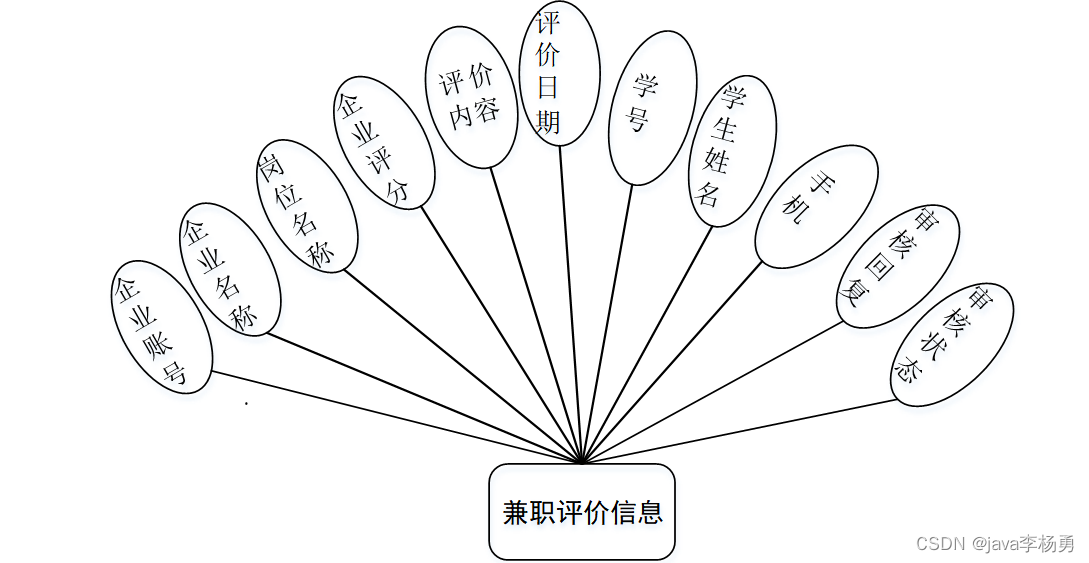
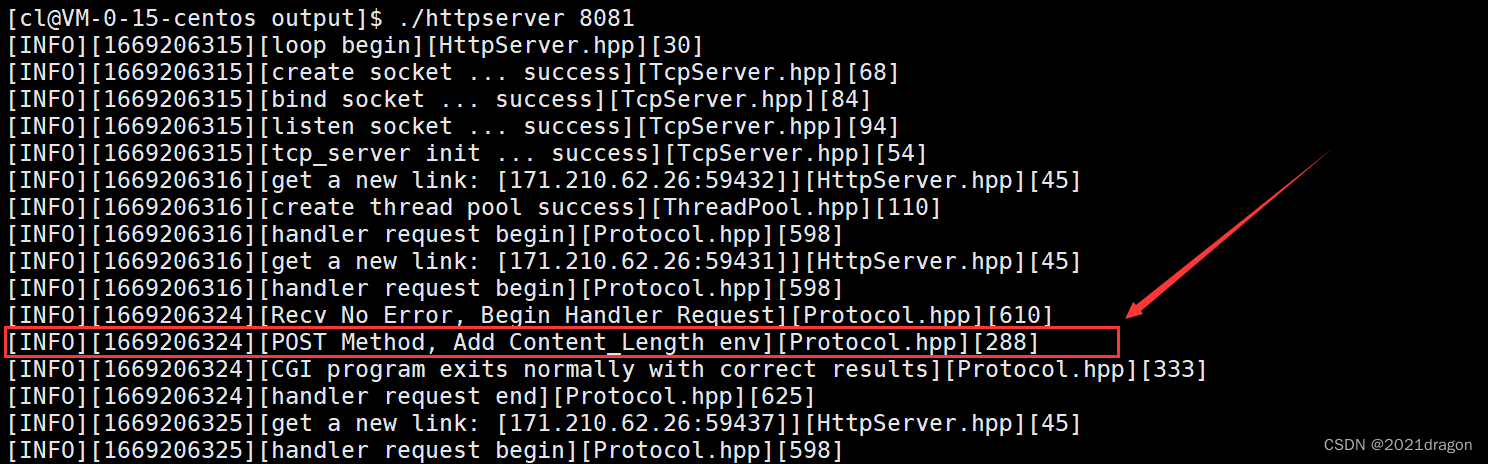
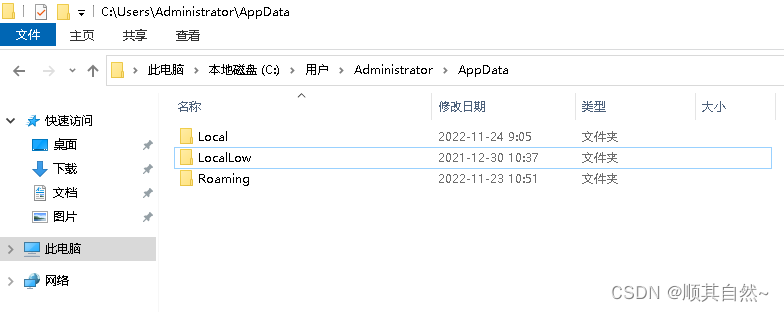
一、HashMap的简单使用
HashMap集合的创建:
Map<String,String> map = new HashMap<String,String>();使用put存储数据:
map.put("张三","喜欢打游戏");
map.put("李四","喜欢睡觉");
map.put("王五","喜欢看电视");
map.put("赵六","喜欢洗澡");使用get获取数据:
System.out.println(map.get("张三"));
System.out.println(map.get("李四"));通过Map.keySet使用iterator遍历HashMap:
// 通过Map.keySet使用iterator遍历key,然后通过key得到对应的value值
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next();
String value = map.get(key);
System.out.println("key = " + key + ", value = " + value);
}通过Map.entrySet使用iterator遍历HashMap:
// 通过Map.entrySet使用iterator遍历key和value;注意 Set entrySet():返回所有key-value对构成的Set集合
Iterator<Map.Entry<String, String>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<String, String> entry = entries.next();
System.out.println(entry);
}通过Map.keySet遍历HashMap:
// 通过Map.keySet遍历key,然后通过key得到对应的value值
for (String key : map.keySet()) {
System.out.println("key = " + key + ", value = " + map.get(key));
}通过For-Each迭代entries,使用Map.entrySet遍历HashMap:
// 使用For-Each迭代entries,通过Map.entrySet遍历key和value
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}使用lambda表达式ForEach遍历HashMap:
// 使用lambda表达式forEach遍历
map.forEach((k, v) -> System.out.println("key = " + k + ", value = " + v));二、HashMap的底层原理
HashMap本身就是一个程序/工具类,主要用来存储数据
程序=数据结构+算法
数据结构:数组、链表、红黑树
算法:哈希算法
HashMap的数据结构在1.8之前是“数组+链表”
数组:
采用一段连续的存储单元来存储数据
/**
* 数组
*/
public class MyArray {
public static void main(String[] args) {
Integer integer[] = new Integer[10];
integer[0] = 0;
integer[1] = 1;
integer[9] = 2;
integer[9] = 100;
System.out.println(integer[9]);
}
}特点:查询o(1),删除o(N)
总结:查询快,插入慢
ArrayList的数据结构就是数组:
链表:
链表是一种物理存储单元上非连续、非顺序的存储结构
/**
* 链表
*/
public class Node {
public Node next;
private Object data;
public Node(Object data){this.data= data;}
public static void main(String[] args) {
Node head = new Node("睡觉");
head.next = new Node("吃饭");
head.next.next = new Node("打游戏");
System.out.println(head.data);
System.out.println(head.next.data);
System.out.println(head.next.next.data);
}
}特点:插入、删除时间复杂度o(1),查找遍历时间复杂度o(N)
总结:插入快,查找慢
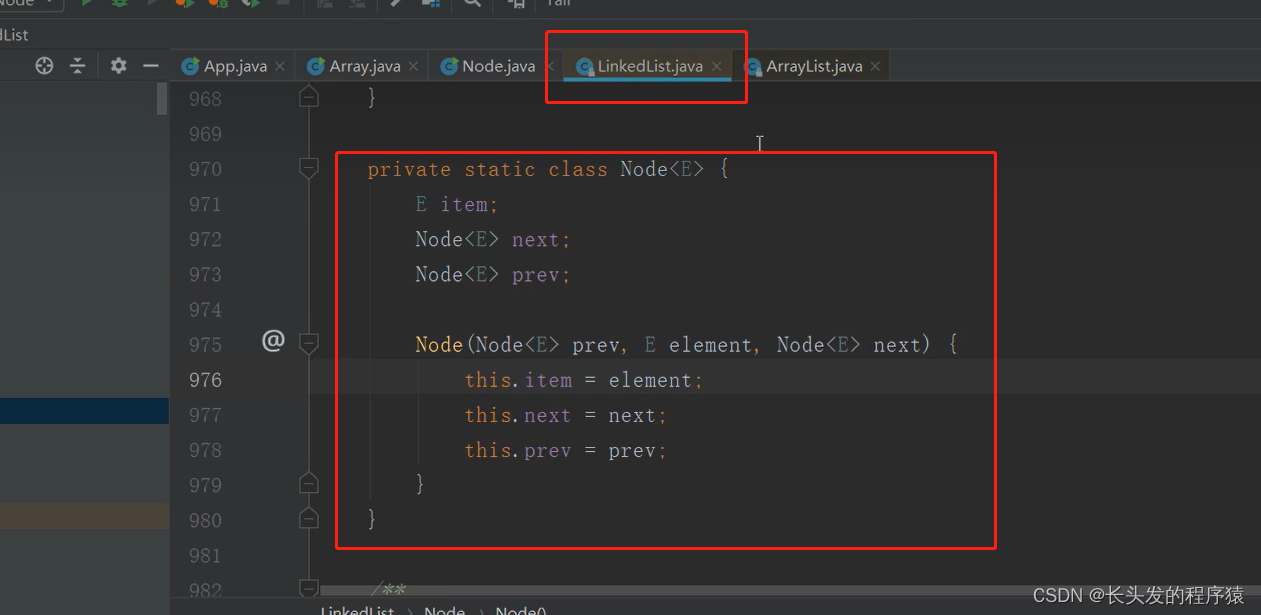
LinkedList的数据结构就是链表:
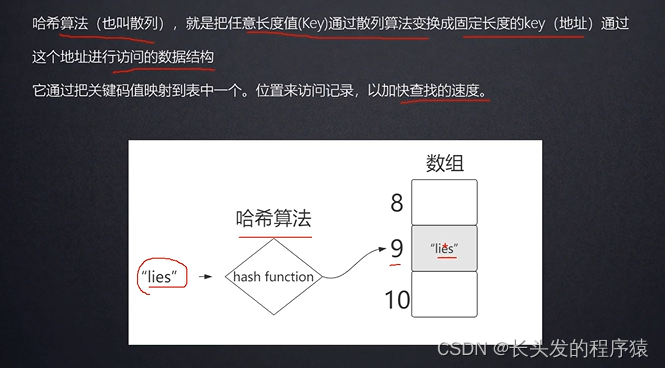
哈希算法:
/**
* ascii码
*/
public class AsciiCode {
public static void main(String[] args) {
char c[] = "lies".toCharArray();
for (int i = 0; i < c.length; i++) {
System.out.println((c[i])+":"+(int)c[i]);
}
}
}
“取模”的目的是为了节省空间.
但如果两个字符串的ascii码计算结果相同,再进行取模,则会发生“哈希冲突”。.
因为HashMap的数据结构包含了“链表”,而链表就是解决哈希冲突这一问题的关键。
HashMap对产生哈希冲突的数据会以“链表”的形式来存储它们,其它数据则以“数组”的形式存储。
HashMap的数据结构在1.8之后是“数组+链表+红黑树”
由于“链表”查询速度慢的原因,所以新增了“红黑树”:
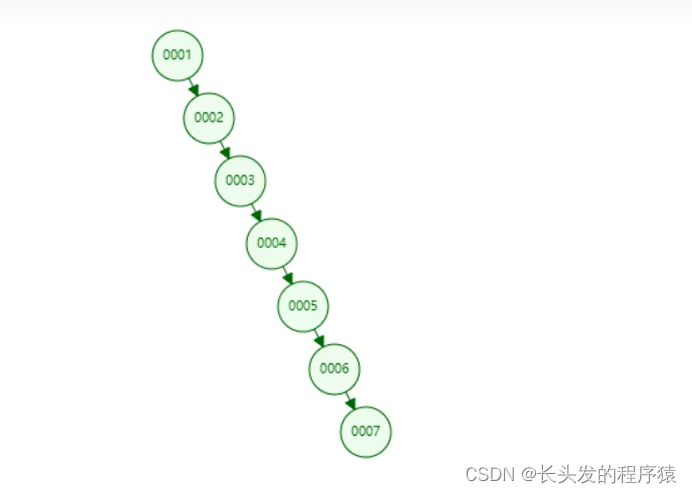
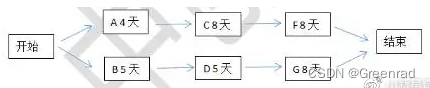
如上图,这是一个以“链表”形式存储数据的图示
假如我要查询“004”,“005”,“007”则会从001到007查询7次

上图是一个以“红黑树”形式存储数据的图示
红黑树结构特征:“左中右”对应“小中大”
使用“红黑树”查询“004”,“005”,“007”则只需要要查询4次即可
这里要注意,java1.8之后,HashMap默认的数据结构一开始仍然是“数组+链表”,但是当链表的阈值达到8的时候就会变成“数组+红黑树”
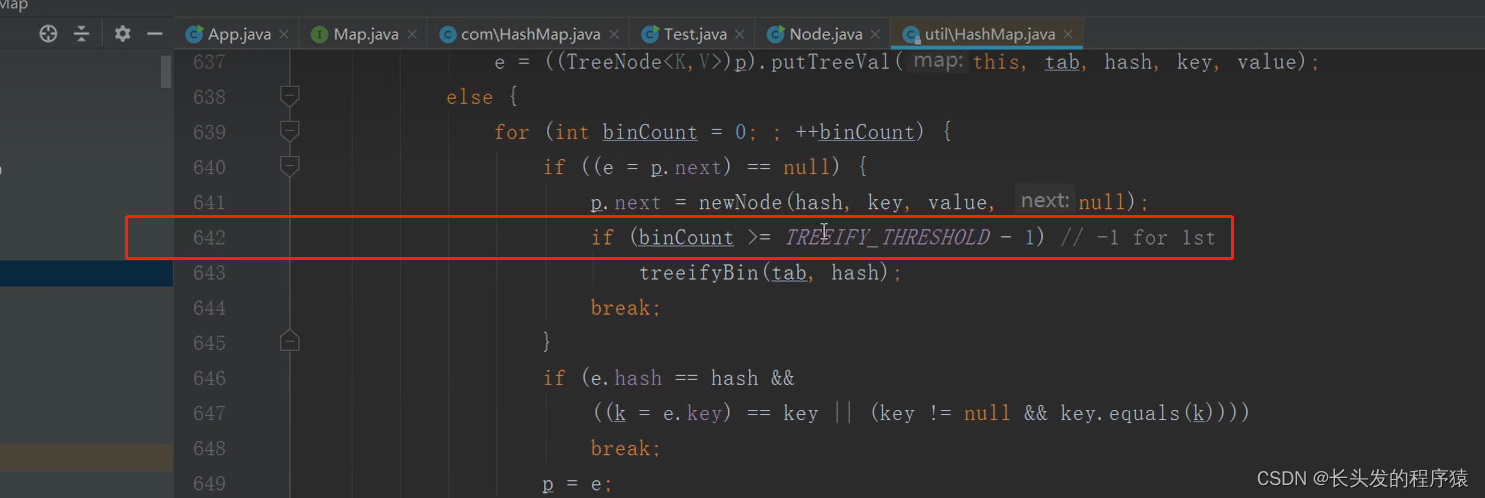
查看HashMap源码,点进putVal方法:
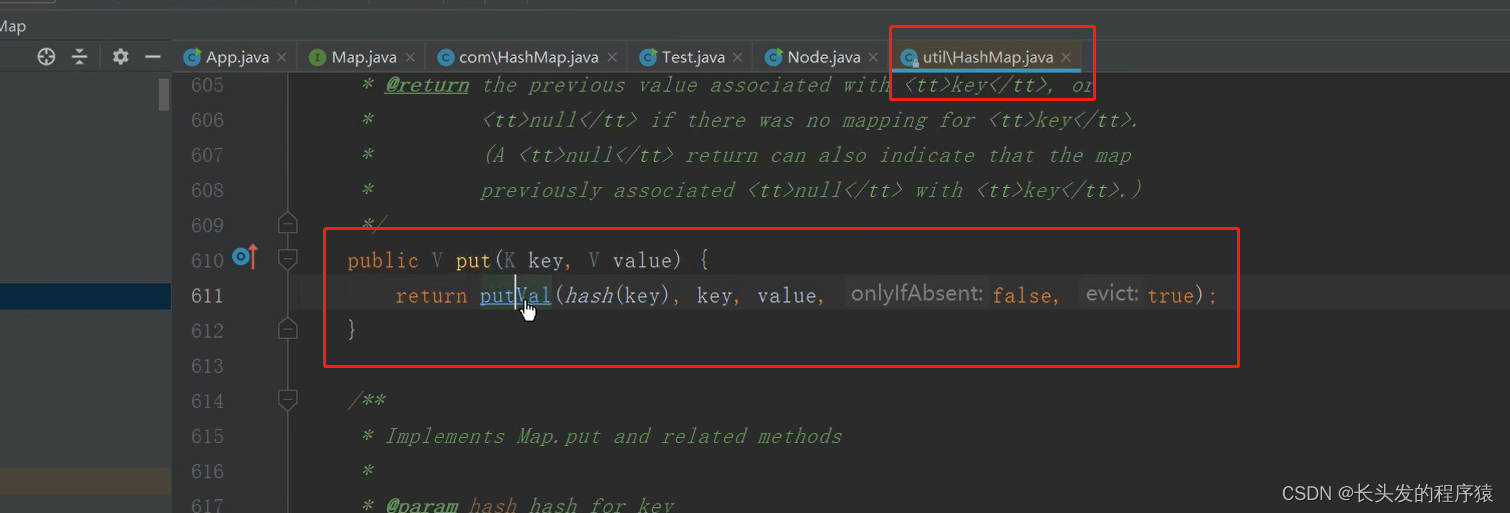
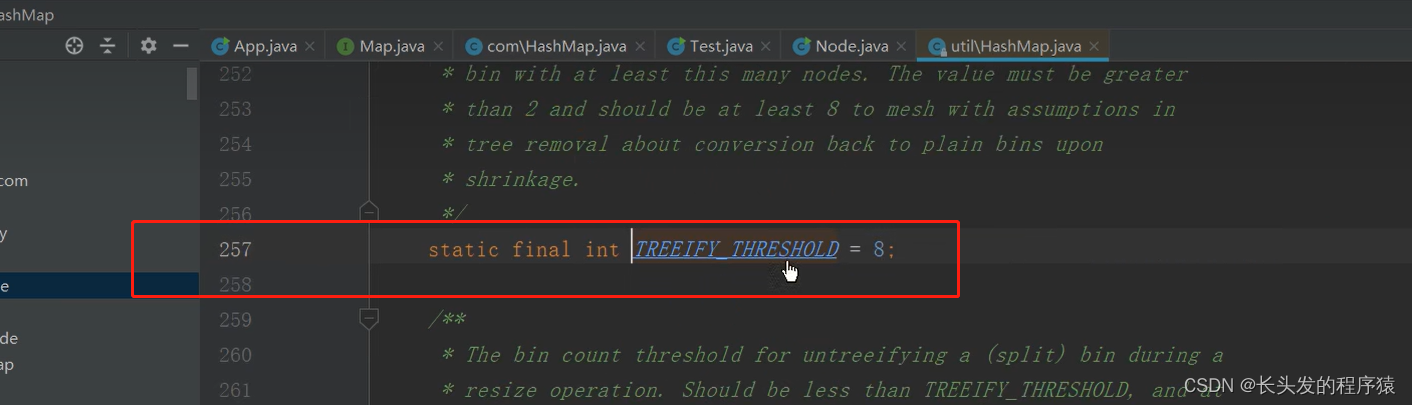
点进642行的常量,发现对应的数值就是8:
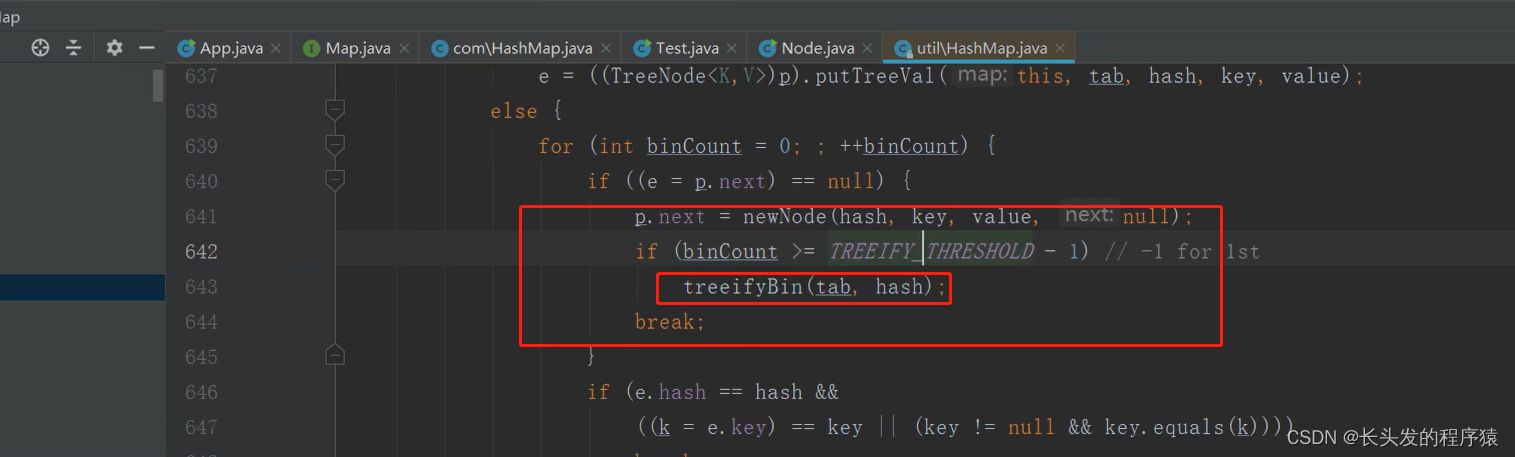
再看putVal方法中的treeifyBin方法:
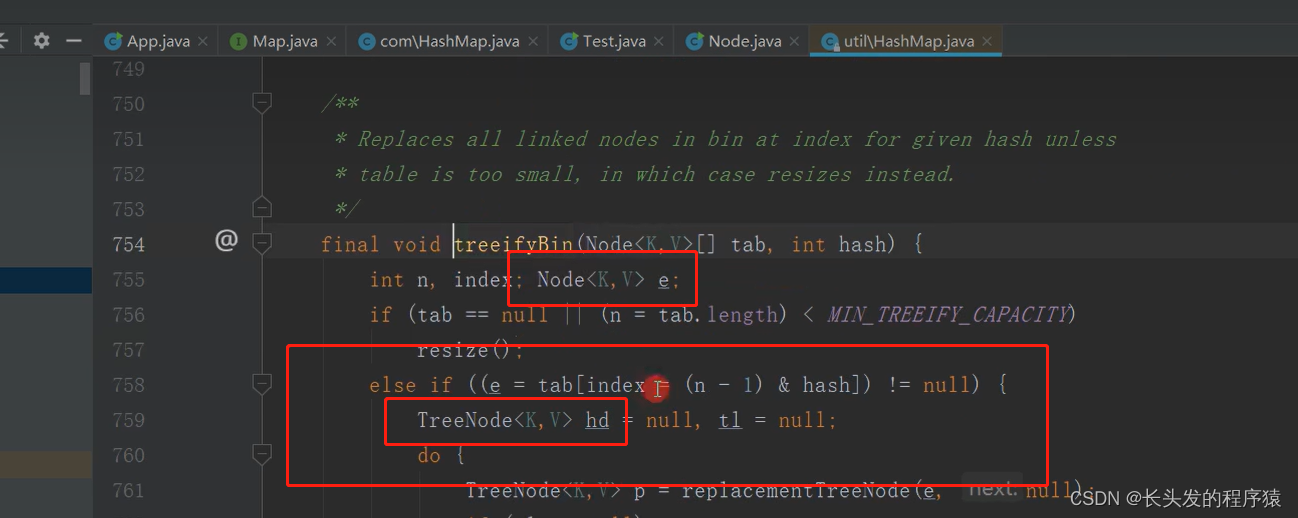
此方法一开始执行的是“链表(执行Node)”,而随着条件的改变就变成了“红黑树(执行TreeNode)”:
这里,你可能会好奇,明明知道了“链表”的查询速度慢,为什么一开始不使用“数组+红黑树”???
这就好比“鱼和熊掌不可兼得”。
因为“红黑树”在插入数据的时候需要做“数据左旋(也可以理解为数据位置交换)”的动作,所以“红黑树”的插入速度慢。
而“链表”它的插入速度快,和红黑树相反,所以才有了“当链表的阈值达到8的时候就会变成“数组+红黑树””这一说法。
不知道“阈值”是什么意思的小伙伴可以去百度一下。
三、手写一个HashMap
Map<K,V>接口:
/**
* K V
* @param <K>
* @param <V>
*/
public interface Map<K,V> {
V put(K k,V v);
V get(K k);
int size();
interface Entry<K,V>{
K getKey();
V getValue();
}
}HashMap<K,V>,实现Map<K,V>接口:
/**
* 手写实现HashMap
* @param <K>
* @param <V>
*/
public class HashMap<K,V> implements Map<K,V> {
Entry<K,V> [] table =null;
int size = 0;
public HashMap() {
table = new Entry[16];
}
/**
* 1、key进行hash 取模算出index下标
* 2、数组的对应节点对象 对象是否为空
* 3、如果为空的话 赋值存储
* 4、如果不为空的话 冲突 链表存储
* 5、返回值
* @param k
* @param v
* @return
*/
@Override
public V put(K k, V v) {
//1、key进行hash 取模算出index下标
int index = hash(k);
//2、数组的对应节点对象 对象是否为空
Entry<K, V> entry = table[index];
if (null == entry){
//3、如果为空的话 赋值存储
table[index]=new Entry<>(k,v,index,null);
size++;
}else {
//4、如果不为空的话 冲突 链表存储
table[index]=new Entry<>(k,v,index,entry);
}
//5、返回值
return table[index].getValue();
}
private int hash(K k) {
int index = k.hashCode()%16;
return index>=0?index:-index;
}
/**
* key 进行hash index下标
* 是否为空 如果为空 直接返回null
* 不为空 k 当前k进行比较
* 如果相等 直接返回数据
* 如果不相等 next是否为空
* 如果为空 直接返回
* 如果不为空
* k是否key是否相等 直到相等为止
* @param k
* @return
*/
@Override
public V get(K k) {
int index = hash(k);
Entry<K,V> entry = findValue(table[index],k);
return entry==null?null:entry.getValue();
}
public Entry<K,V> findValue(Entry<K,V> entry,K k){
if (k.equals(entry.getKey())||k==entry.getKey()){
return entry;
}else {
if (entry.next!=null){
return findValue(entry.next,k);
}
}
return null;
}
@Override
public int size() {
return size;
}
class Entry<K,V> implements Map.Entry<K, V> {
K k;V v;int index;Entry<K,V> next;
public Entry(K k, V v, int index, Entry<K, V> next) {
this.k = k;
this.v = v;
this.index = index;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
}测试类:
public class Test {
public static void main(String[] args) {
HashMap<Object, Object> map = new HashMap<>();
map.put("张三","喜欢打游戏");
map.put("王五","喜欢看电视");
System.out.println(map.get("张三"));
System.out.println(map.get("王五"));
}
}测试结果:
喜欢打游戏
喜欢看电视