文章目录
- 一、为什么要有 DMA 技术?
- 二、传统的文件传输有多糟糕?
- 三、如何优化文件传输的性能?
- 四、 如何实现零拷贝?
- mmap + write
- sendfile
- 使用零拷贝技术的项目
- 五、PageCache 有什么作用?
- 六、大文件传输用什么方式实现?
一、为什么要有 DMA 技术?
在没有 DMA 技术前,I/O 的过程是这样的:
- CPU 发出对应的指令给磁盘控制器,然后返回;
- 磁盘控制器收到指令后,于是就开始准备数据,会把数据放入到磁盘控制器的内部缓冲区中,然后产生⼀个中断;
- CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据一次⼀个字节地读进自己的寄存器,然后再把寄存器里的数据写入到内存,而在数据传输的期间 CPU 是无法执行其他任务的。
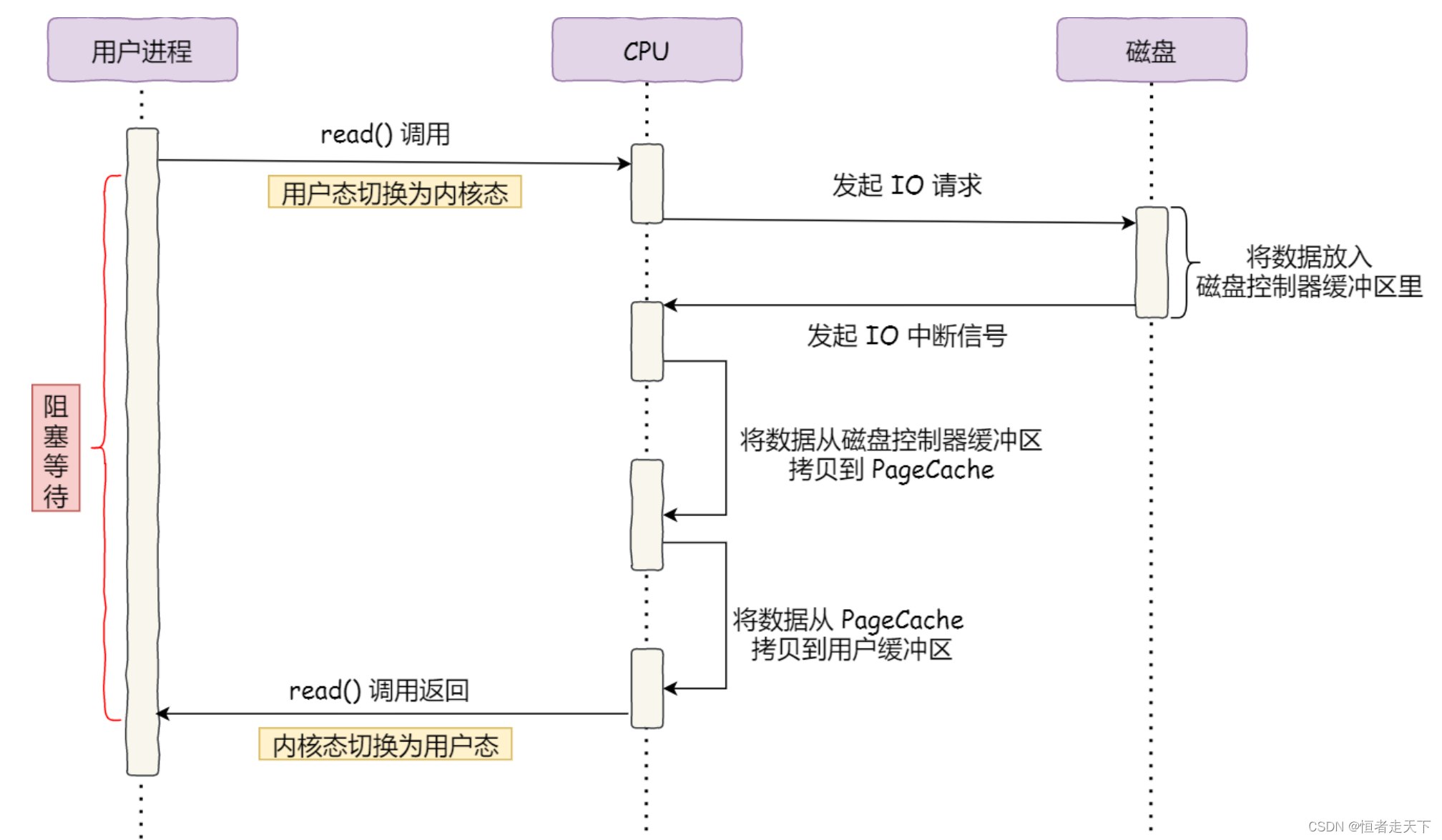
可以看到,整个数据的传输过程,都要需要 CPU 亲自参与搬运数据的过程,而且这个过程,CPU 是不能
做其他事情的。
简单的搬运几个字符数据那没问题,但是如果我们用千兆网卡或者硬盘传输大量数据的时候,都用CPU 来
搬运的话,肯定忙不过来。
计算机科学家们发现了事情的严重性后,于是就发明了 DMA 技术,也就是直接内存访问(Direct
Memory Access) 技术。
什么是 DMA 技术?简单理解就是,在进行I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给
DMA 控制器,而CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。
那使用DMA 控制器进行数据传输的过程究竟是什么样的呢?下面我们来具体看看。
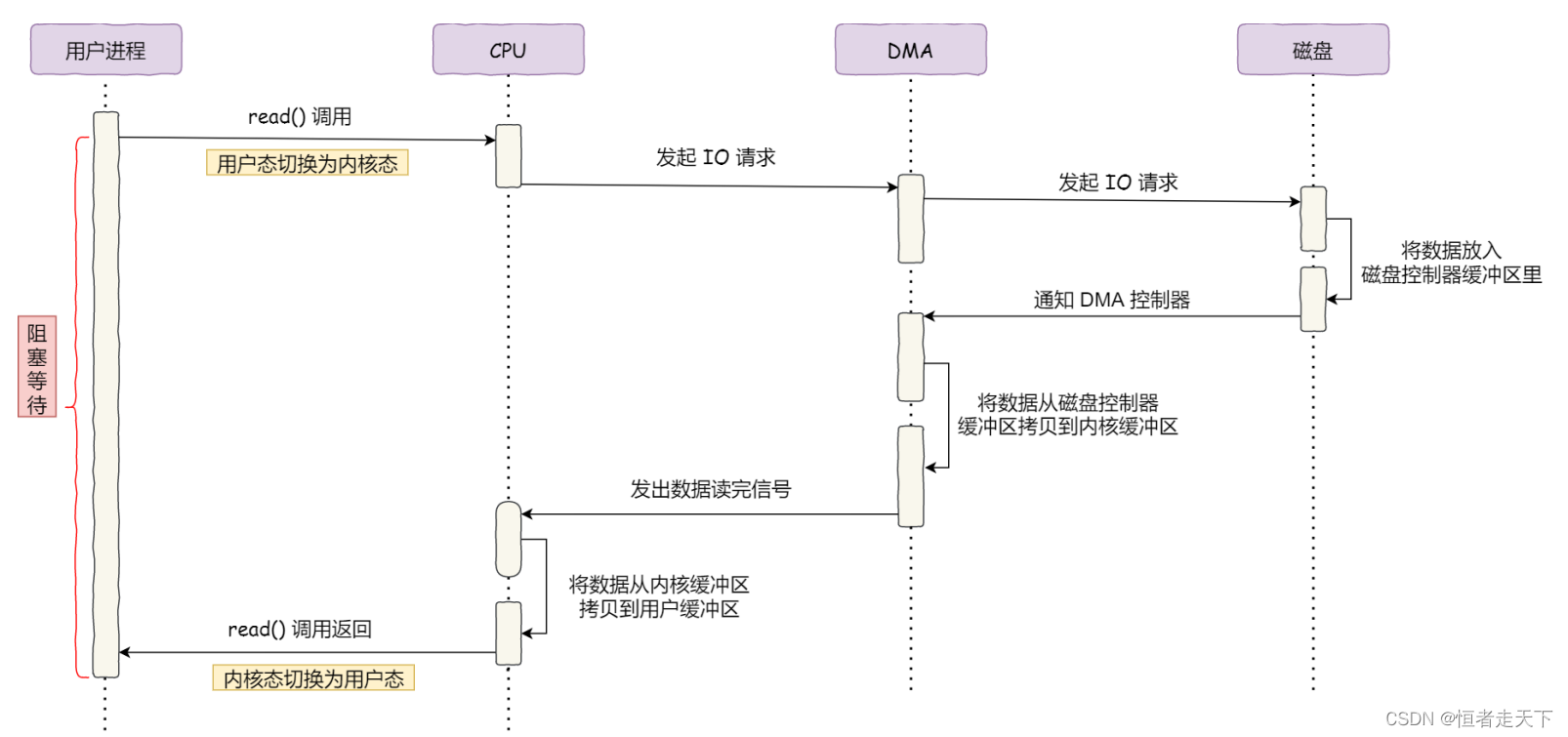
具体过程:
- 用户进程调用read方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
- 操作系统收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 执行其他任务;
- DMA 进一步将 I/O 请求发送给磁盘;
- 磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
- DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用CPU,CPU可以执行其他任务;
- 当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
- CPU 收到 DMA 的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回;
可以看到, 整个数据传输的过程,CPU 不再参与数据搬运的工作,而是全程由 DMA 完成,但是 CPU 在
这个过程中也是必不可少的,因为传输什么数据,从哪里传输到哪里,都需要 CPU 来告诉 DMA 控制器。
早期 DMA 只存在在主板上,如今由于 I/O 设备越来越多,数据传输的需求也不尽相同,所以每个 I/O 设备
里面都有自己的 DMA 控制器。
二、传统的文件传输有多糟糕?
如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操
作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,⼀般会需要两个系统调用:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
代码很简单,虽然就两行代码,但是这里面发生了不少的事情。
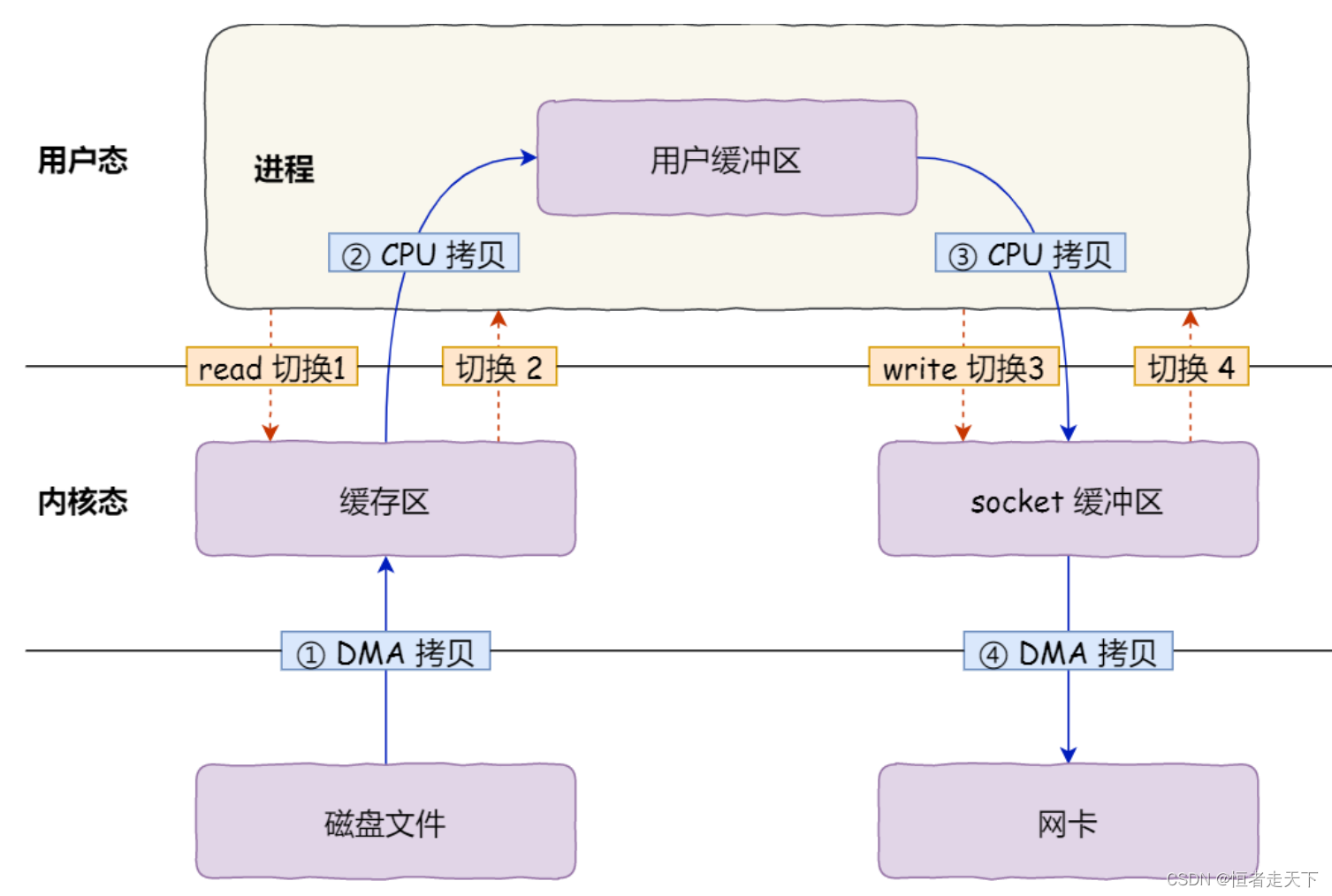
首先,期间共发生了 4 次用户态与内核态的上下文切换,因为发生了两次系统调用,一次是 read() ,一
次是 write() ,每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户
态。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的
场景下,这类时间容易被累积和放大,从而影响系统的性能。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说⼀下这
个过程:
- 第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
- 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据
了,这个拷贝到过程是由 CPU 完成的。 - 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程
依然还是由 CPU 搬运的。 - 第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运
的。
我们回过头看这个文件传输的过程,我们只是搬运⼀份数据,结果却搬运了 4 次,过多的数据拷贝无疑会
消耗 CPU 资源,大大降低了系统性能。
这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了
很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少用户态与内核态的上下文切换和内存拷贝的次数。
三、如何优化文件传输的性能?
先来看看,如何减少用户态与内核态的上下文切换的次数呢?
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权
限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以⼀般要通过内核去完成某些任务的时
候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换
回用户态交由进程代码执行。
所以,要想减少上下文切换到次数,就要减少系统调用的次数。
再来看看,如何减少数据拷贝的次数?
在前面我们知道了,传统的文件传输方式会历经 4 次数据拷贝,而且这里面,从内核的读缓冲区拷贝到
用户的缓冲区里,再从用户的缓冲区里拷贝到 socket 的缓冲区里,这个过程是没有必要的。
因为文件传输的应用场景中,在用户空间我们并不会对数据再加工,所以数据实际上可以不用搬运到用户空间,因此用户的缓冲区是没有必要存在的。
四、 如何实现零拷贝?
零拷贝技术实现的方式通常有 2 种:
- mmap + write
- sendfile
下面就谈一谈,它们是如何减少上下文切换和数据拷贝的次数。
mmap + write
在前面我们知道, read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少
这⼀步开销,我们可以用mmap() 替换 read() 系统调用函数。
buf = mmap(file, len);
write(sockfd, buf, len);
mmap() 系统调用函数会直接把内核缓冲区里的数据映射到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
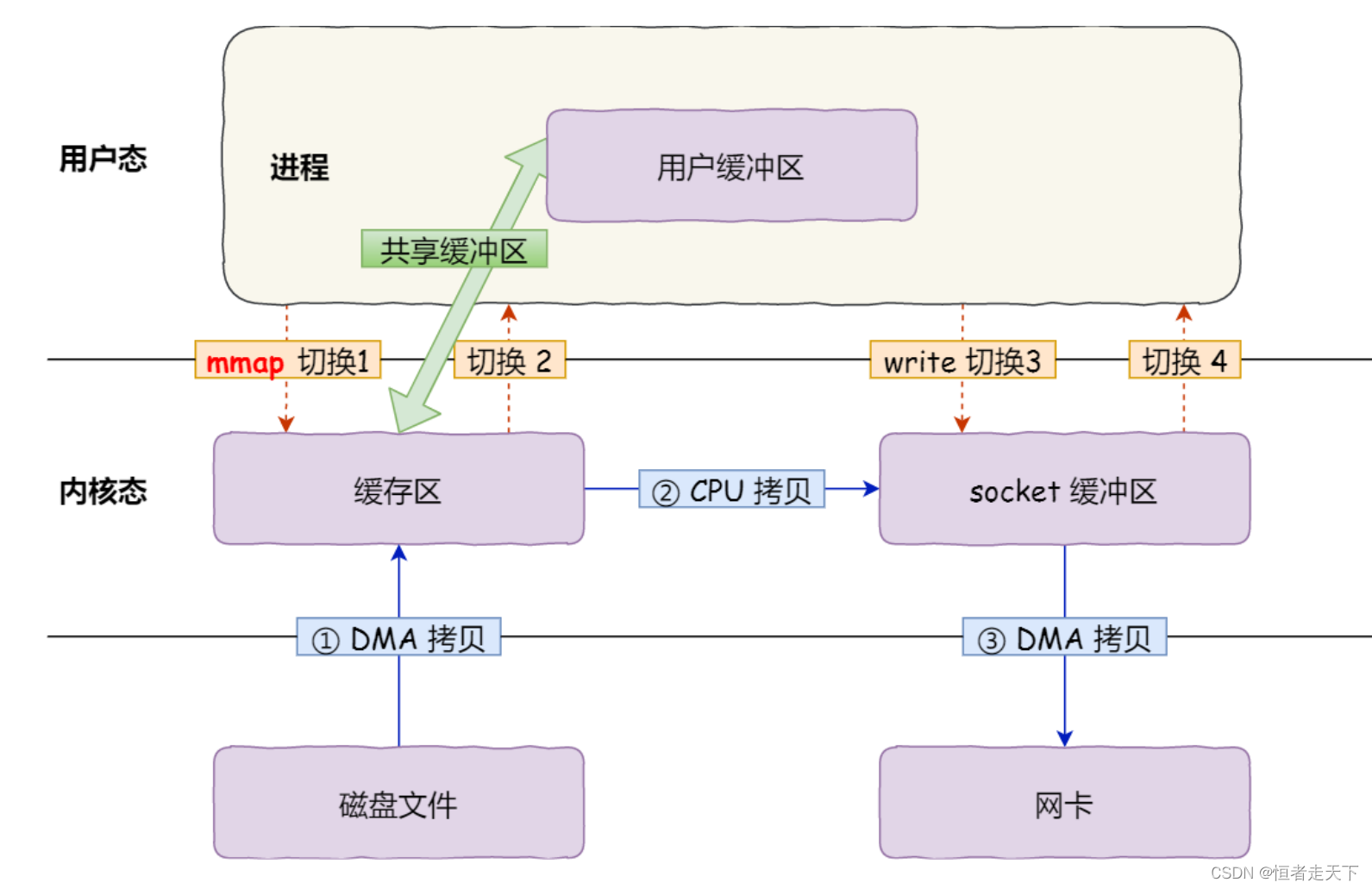
具体过程如下:
- 应用进程调用了 mmap() 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作
系统内核共享这个缓冲区; - 应用进程再调用write() ,操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据;
- 最后,把内核的 socket 缓冲区⾥的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
我们可以得知,通过使用mmap() 来代替 read() , 可以减少⼀次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且
仍然需要 4 次上下文切换,因为系统调用还是 2 次。
sendfile
在 Linux 内核版本 2.1 中,提供了⼀个专门发送文件的系统调用函数 sendfile() ,函数形式如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返
回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少
了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就
只有 2 次上下文切换,和 3 次数据拷贝。如下图:
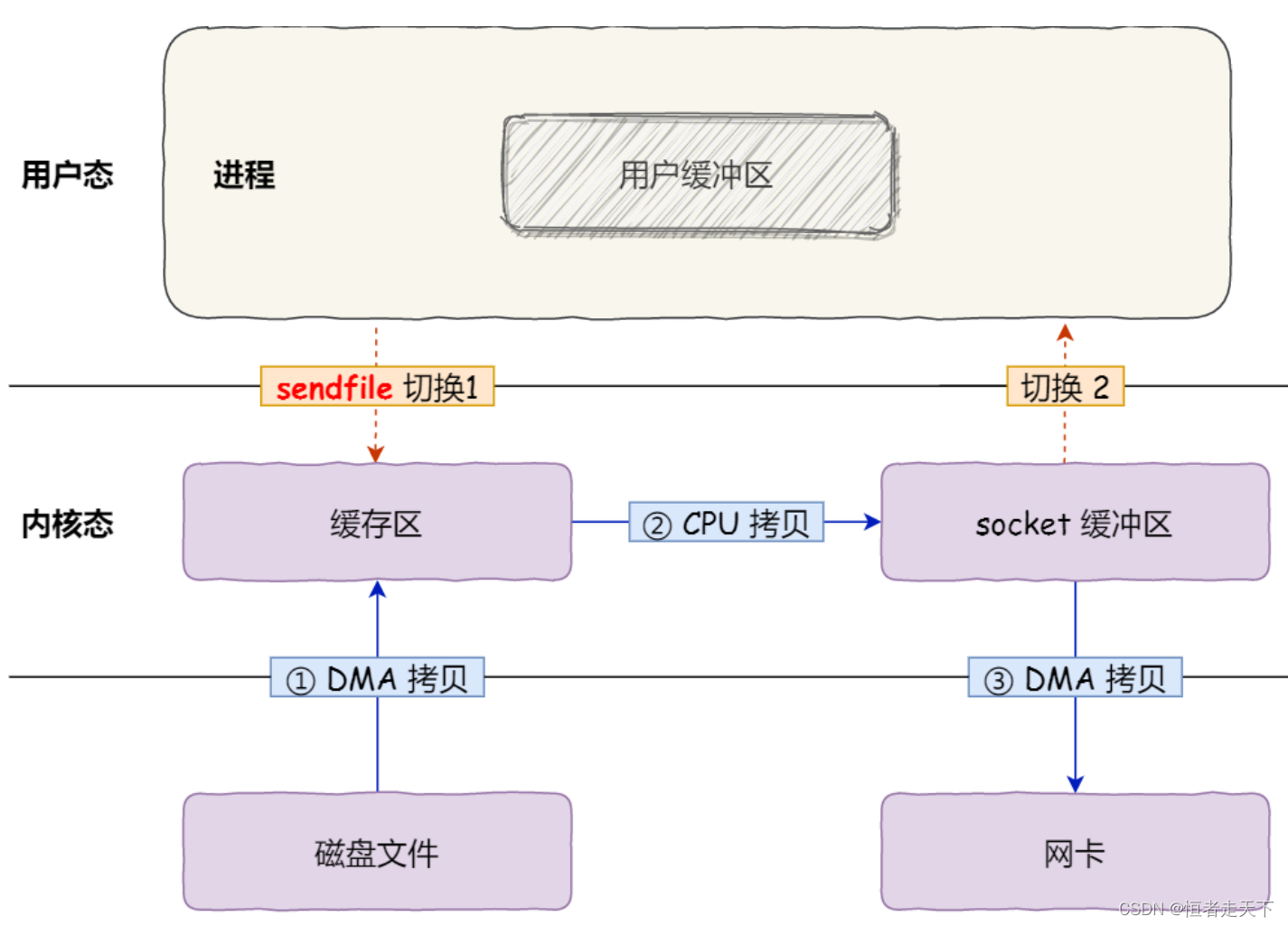
但是这还不是真正的零拷贝技术,如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),我们可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket缓冲区的过程。
你可以在你的 Linux 系统通过下⾯这个命令,查看⽹卡是否⽀持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket缓冲区中,这样就减少了⼀次数据拷贝;
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:
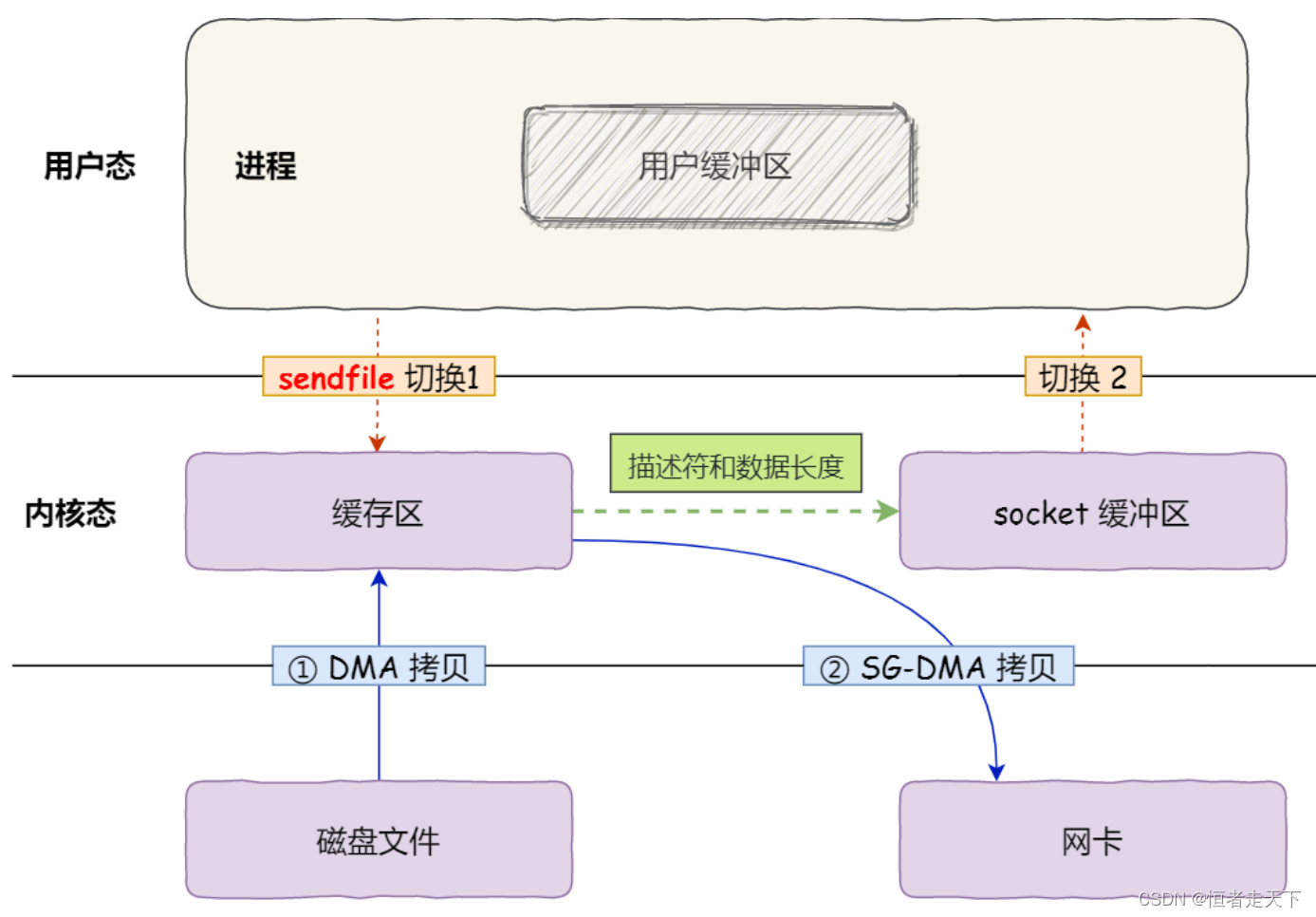
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过
CPU 来搬运数据, 所有的数据都是通过 DMA 来进行传输的。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2
次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,
2 次都是由 DMA 来搬运。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少⼀倍以上。
使用零拷贝技术的项目
事实上,Kafka 这个开源项目,就利用了零拷贝技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka
在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws
IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
Nginx 也支持零拷贝技术,⼀般默认是开启零拷贝技术,这样有利于提高文件传输的效率,是否开
启零拷贝技术的配置如下:
http {
...
sendfile on
...
}
sendfile 配置的具体意思:
- 设置为 on 表示,使用零拷贝技术来传输文件:sendfile ,这样只需要 2 次上下文切换,和 2 次数据
拷贝。 - 设置为 off 表示,使用传统的文件传输技术:read + write,这时就需要 4 次上下文切换,和 4 次数据
拷贝。
当然,要使用sendfile,Linux 内核版本必须要 2.1 以上的版本。
五、PageCache 有什么作用?
回顾前面说道文件传输过程,其中第一步都是先需要先把磁盘文件数据拷贝内核缓冲区里,这个内核缓冲区实际上是磁盘高速缓存(PageCache)。
由于零拷贝使用了 PageCache 技术,可以使得零拷贝进⼀步提升了性能,我们接下来看看 PageCache
是如何做到这一点的。
读写磁盘相比读写内存的速度慢太多了,所以我们应该想办法把读写磁盘替换成读写内存。于是,我们会通过 DMA 把磁盘里的数据搬运到内存里,这样就可以用读内存替换读磁盘。
但是,内存空间远比磁盘要小,内存注定只能拷贝磁盘里的一小部分数据。
那问题来了,选择哪些磁盘数据拷贝到内存呢?
我们都知道程序运行的时候,具有局部性,所以通常,刚被访问的数据在短时间内再次被访问的概率很高,于是我们可以用PageCache 来缓存最近被访问的数据,当空间不足时淘汰最久未被访问的缓存。
所以,读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘
中读取,然后缓存 PageCache 中。
还有一点,读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转
到数据所在的扇区,再开始顺序读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的
影响,PageCache 使用了预读功能。
比如,假设 read方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会
把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64
KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
所以,PageCache 的优点主要是两个:
- 缓存最近被访问的数据;
- 预读功能;
这两个做法,将大大提高读写磁盘的性能。
但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的⼀
次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能
这是因为如果你有很多 GB 级别⽂件需要传输,每当⽤户访问这些⼤⽂件的时候,内核就会把它们载⼊
PageCache 中,于是 PageCache 空间很快被这些⼤⽂件占满
另外,由于⽂件太⼤,可能某些部分的⽂件数据被再次访问的概率⽐较低,这样就会带来 2 个问题:
- PageCache 由于长时间被大文件占据,其他热点的⼩⽂件可能就⽆法充分使⽤到 PageCache,
于是这样磁盘读写的性能就会下降了; - PageCache 中的⼤⽂件数据,由于没有享受到缓存带来的好处,但却耗费 DMA 多拷⻉到
PageCache ⼀次;
所以,**针对⼤⽂件的传输,不应该使⽤ PageCache,也就是说不应该使⽤零拷⻉技术,因为可能由于
PageCache 被⼤⽂件占据,⽽导致「热点」⼩⽂件⽆法利⽤到 PageCache,**这样在⾼并发的环境下,会
带来严重的性能问题。
六、大文件传输用什么方式实现?
对于阻塞的问题,可以⽤异步 I/O 来解决,它⼯作⽅式如下图:
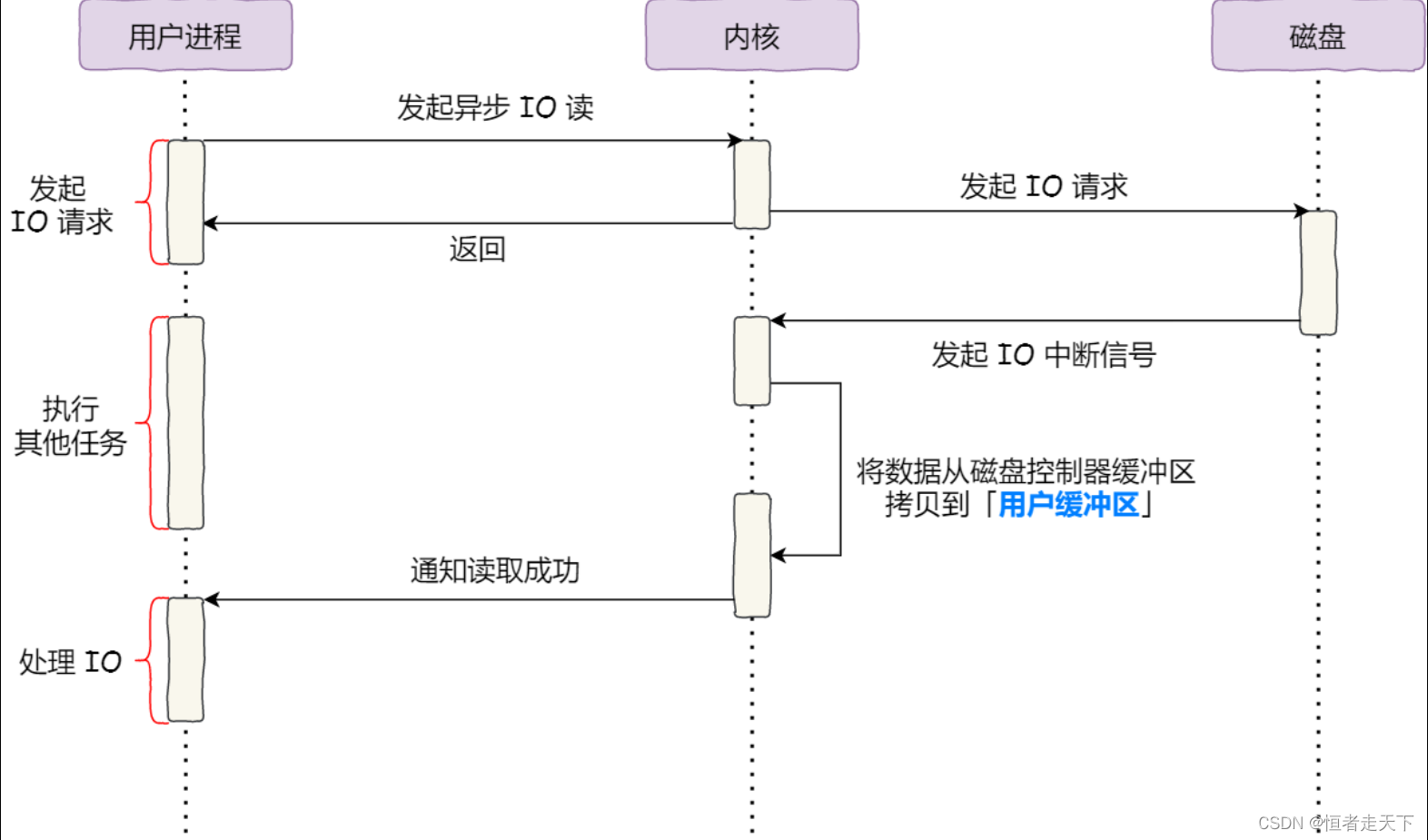
它把读操作分为两部分:
- 前半部分,内核向磁盘发起读请求,但是可以不等待数据就位就可以返回,于是进程此时可以处理其
他任务; - 后半部分,当内核将磁盘中的数据拷⻉到进程缓冲区后,进程将接收到内核的通知,再去处理数据;
而且,我们可以发现,异步 I/O 并没有涉及到 PageCache,所以使用异步 I/O 就意味着要绕开
PageCache。
绕开 PageCache 的 I/O 叫直接 I/O,使⽤ PageCache 的 I/O 则叫缓存 I/O。通常,对于磁盘,异步 I/O 只
⽀持直接 I/O。
前⾯也提到,⼤⽂件的传输不应该使⽤ PageCache,因为可能由于 PageCache 被⼤⽂件占据,⽽导致
「热点」⼩⽂件⽆法利⽤到 PageCache。
于是,在⾼并发的场景下,针对⼤⽂件的传输的⽅式,应该使⽤「异步 I/O + 直接 I/O」来替代零拷⻉技
术。
直接 I/O 应⽤场景常⻅的两种:
- 应⽤程序已经实现了磁盘数据的缓存, 那么可以不需要 PageCache 再次缓存,减少额外的性能损
耗。在 MySQL 数据库中,可以通过参数设置开启直接 I/O,默认是不开启; - 传输⼤⽂件的时候, 由于⼤⽂件难以命中 PageCache 缓存,⽽且会占满 PageCache 导致「热点」
⽂件⽆法充分利⽤缓存,从⽽增⼤了性能开销,因此,这时应该使⽤直接 I/O。
另外,由于直接 I/O 绕过了 PageCache,就⽆法享受内核的这两点的优化:
- 内核的 I/O 调度算法会缓存尽可能多的 I/O 请求在 PageCache 中,最后「合并」成⼀个更⼤的 I/O
请求再发给磁盘,这样做是为了减少磁盘的寻址操作; - 内核也会 「预读」 后续的 I/O 请求放在 PageCache 中,⼀样是为了减少对磁盘的操作;
于是,传输⼤⽂件的时候,使⽤「异步 I/O + 直接 I/O」了,就可以⽆阻塞地读取⽂件了。
所以,传输⽂件的时候,我们要根据⽂件的⼤⼩来使⽤不同的⽅式:
- 传输⼤⽂件的时候,使⽤「异步 I/O + 直接 I/O」;
- 传输⼩⽂件的时候,则使⽤「零拷⻉技术」;
在 nginx 中,我们可以⽤如下配置,来根据⽂件的⼤⼩来使⽤不同的⽅式:
location /video/ {
sendfile on;
aio on;
directio 1024m;
}
当⽂件⼤⼩⼤于 directio 值后,使⽤「异步 I/O + 直接 I/O」,否则使⽤「零拷⻉技术」。