🌈欢迎来到笔试强训专栏
- (꒪ꇴ꒪(꒪ꇴ꒪ )🐣,我是Scort
- 目前状态:大三非科班啃C++中
- 🌍博客主页:张小姐的猫~江湖背景
- 快上车🚘,握好方向盘跟我有一起打天下嘞!
- 送给自己的一句鸡汤🤔:
- 🔥真正的大师永远怀着一颗学徒的心
- 作者水平很有限,如果发现错误,可在评论区指正,感谢🙏
- 🎉🎉欢迎持续关注!


笔试强训解析
- 🌈欢迎来到笔试强训专栏
- 🌈选择题
- 🌈编程题
- 1️⃣逆置字符串
- 2️⃣排序子序列
- 📢写在最后

🌈选择题
1.使用printf函数打印一个double类型的数据,要求:输出为10进制,输出左对齐30个字符,4位精度。以下哪个选项是正确的?
A %-30.4e
B %4.30e
C %-30.4f
D %-4.30f
题目解析: %m.nf
- 要求是打印
double类型数据,输出10进制,左对齐,30个字符,4位精度 - 首先排除%e,
%e是按指数类型进行输出。因为默认的是右对齐,左对齐要加-负号,30字符宽度对应m;4精度对应n
所以答案是:%-30.4f ,选
C
请找出下面程序中有哪些错误()
int main(){
int i = 10;
int j = 1;
const int *p1;//(1)
int const *p2 = &i; //(2)
p2 = &j;//(3)
int *const p3 = &i;//(4)
*p3 = 20;//(5)
*p2 = 30;//(6)
p3 = &j;//(7)
return 0;
}
A 1,2,3,4,5,6,7
B 1,3,5,6
C 6,7
D 3,5
复习: const右边修饰的又不能改
-
常量指针:
const int *a
指针指向空间的值不能发生改变,不能通过指针解引用修改指针所指空间的值,但是指针的方向可以发生改变 -
指针常量:
int * const a
指针本身是一个常量,指针的指向不能发生改变,但是指针所指向空间的值是可以发生改变的,可以通过指针解引用改变指针所指空间的值 -
区分方法:
const * 的相对位置: const在*的左边为常量指针;const在*的右边就表示一个指针常量
由题目可以知道:p1、p2是常量指针,p3是指针常量,而6改变了*p2, 7改变了p3,都违背了
所以答案选
C
- 下面叙述错误的是()
char acX[]="abc";
char acY[]={'a','b','c'};
char *szX="abc";
char *szY="abc";
A: acX与acY的内容可以修改
B :szX与szY指向同一个地址
C :acX占用的内存空间比acY占用的大
D :szX的内容修改后,szY的内容也会被更改
题目解析:
zcX和zcY都是在栈上开辟的空间,可以修改;
szX和szY都是指针,指向同一个字符串,是浅拷贝,所以使用同一块空间 ;
zcX是字符串初始化,本质上是:abc\0,而acY只有abc,所以acX占用的空间比acY大
D选项: szX是一个指针,内容改变也就是,szX的指向改变 ,并不会改变abc
所以答案选
D
在头文件及上下文均正常的情况下,下列代码的运行结果是()
int a[] = {1, 2, 3, 4};
int *b = a;
*b += 2;
*(b + 2) = 2;
b++;
printf("%d,%d\n", *b, *(b + 2));
A 1,3
B 1,2
C 2,4
D 3,2
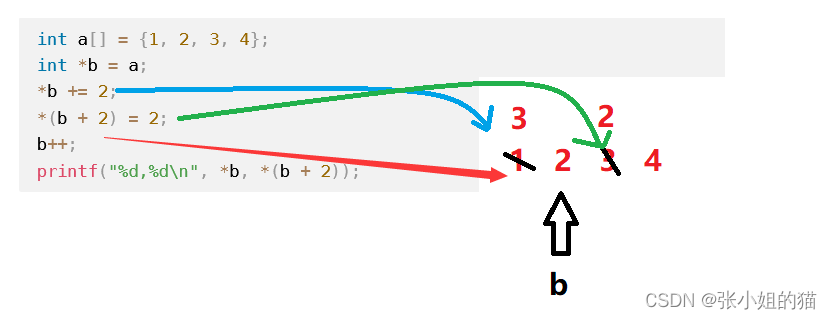
最后指针b指向的是2,*(b+2)指向的是4 ,答案选
C
下列关于C/C++的宏定义,不正确的是()
A 宏定义不检查参数正确性,会有安全隐患
B 宏定义的常量更容易理解,如果可以使用宏定义常量的话,要避免使用const常量
C 宏的嵌套定义过多会影响程序的可读性,而且很容易出错
D 相对于函数调用,宏定义可以提高程序的运行效率
题目解析:
宏定义没有安全类型检测,所以会有安全隐患,在预处理阶段进行了替换,所以应该是尽量使用const常量;宏的嵌套定义会可能会导致运算符优先级的问题,容易出错;宏定义相比于函数调用,没有在开辟栈桢,减少了开销,所以提高了运行效率。
答案选
B
有以下定义:
int a[10];
char b[80];
函数声明为:
void sss(char[],int[]); //参数都是数组
则正确的函数调用形式是()
A sss(a,b);
B sss(char b[],int a[]);
C sss(b[],a[]);
D sss(b,a);
函数调用的时候,参数是数组类型的话,传入数组名即可,也就是地址
答案选
D
用变量a给出下面的定义:一个有10个指针的数组,该指针指向一个函数,该函数有一个整形参数并返回一个整型数()
A int *a[10];
B int (*a)[10];
C int (*a)(int);
D int (*a[10])(int);
我们逐个分析:
int *a[10]:[]的运算符优先级高于*,a先和[]结合,表明是一个数组,数组里存放int类型的指针 是指针数组,不满足题意int (*a)[10]:a先和*结合,表明是一个指针,指向的是一个大小为10的int 数组int (*a)(int):a先和*结合,表明是一个指针,指向(int)函数,表示是一个函数指针,有一个int参数,返回值为intint (*a[10])(int):a先和[]结合,表示是一个数组,再和*a结合,为指针数组,指针指向的是函数,函数有int类型,并返回int。所以最后是 函数指针数组
答案是
D
以下 C++ 函数的功能是统计给定输入中每个大写字母的出现次数(不需要检查输入合法性,所有字母都为大写),则应在横线处填入的代码为()
void AlphabetCounting(char a[], int n) {
int count[26] = {}, i, kind = 10;
for (i = 0; i < n; ++i)
_________________;
for (i = 0; i < 26; ++i)
{ printf("%c=%d", _____, _____);
}
}
A ++count[a[i]-‘Z’] ‘Z’-i count[‘Z’-i]
B ++count[‘A’-a[i]] ‘A’+i count[i]
C ++count[i] i count[i]
D ++count[‘Z’-a[i]] ‘Z’- i count[i]
题目解析:
"Z - a[i]" : 对应的是出现的大写字母在数组对应的位置 ;'Z'- i : 对应大写字母;count[i]:记录的是出现的次数
i是取决于n的,可能大于26,就会出现越界访问

答案是:
D
在32位cpu上选择缺省对齐的情况下,有如下结构体定义:
struct A{
unsigned a : 19;
unsigned b : 11;
unsigned c : 4;
unsigned d : 29;
char index;
};
则sizeof(struct A)的值为()
A 9
B 12
C 16
D 20
涉及位段:
4字节(32): 19 + 11(a+b)
4字节(32): 4(c)
4字节(32):29(d)
1字节(8) :1(index)
因为要涉及到内存对齐,最终大小是最大宽度的整数倍,现在占了13个字节,要比13大,也要是4的整数倍,所以是16
所以答案选
C
下面代码会输出()
int main(){
int a[4]={1,2,3,4};
int *ptr=(int*)(&a+1);
printf("%d",*(ptr-1));
}
A 4
B 1
C 2
D 3
有坑:(&a+1):对数组名进行取地址,变成数组指针,+1会向后偏移指针类型的大小,也就是偏移了数组类型大小,*ptr是int类型指针,(ptr-1)是向前偏移一个int类型的大小,所以最后指向4,再解引用获得4

答案是:A
🌈编程题
老规矩一道算法、一道常见的
1️⃣逆置字符串
题目地址:传送

思路:先整体逆置,再局部单词进行逆置

#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
int main()
{
string s1;
getline(cin, s1);
//进行整体的逆置
reverse(s1.begin(), s1.end());
//局部单词的逆置
auto start = s1.begin();
while(start != s1.end())
{
auto end = start;
while(end != s1.end() && *end != ' '){
end++;
}
//reverse(start, end);也可以放在这,反正两种情况都要逆置
if(end != s1.end())
{
reverse(start, end);
start = end + 1;
}
else
{
reverse(start, end);
start = end;
}
}
cout<<s1<<endl;
return 0;
}
2️⃣排序子序列
题目地址:传送


看到这题我连题目都没读懂,什么叫子序列
1,2,3,4,5; 递增序列
9,8,7,6,5; 递减序列
1,2,3,3,4,5,8,8; 非递减序列 (原本是递增,但是有相等数字)
9,8,7,7,6,5,5,2,1; 非递增序列 (原本是递减,但是有相等数字)
非递减就是: a[i] <= a[i+1] ;非递增: a[i] >= a[i+1]
思路讲解:
- 遍历数组,有三种情况:
1️⃣ a[i] <= a[i+1] 即将非递减序列
2️⃣ 两个数相等 ,不予理会,还是++i
3️⃣a[i] >= a[i+1] 非递增序列 - 定义一个
count计数器,如果前面都是非递减的,突然变成非递增,count++

ps:注意越界问题 :于是我们多开辟vector多开一个空间,并置0

上代码
#include<iostream>
#include<vector>
using namespace std;
int main()
{
int count = 0;
int n = 0;
cin >> n;
vector<int> a;
a.resize(n+1);//防止越界
a[n] = 0;
for(int i=0; i<n ;i++)
{
cin>>a[i];
}
//数组中已经有数据了
int i=0;
while(i<n)
{
//进入非减序列
if(a[i] < a[i+1])
{
//可能有多个数据都小于
//注意i的值不要越界
while(i < n && a[i] <= a[i+1])
{
i++;
}
count++;//完成了一组
i++;
}
else if(a[i] == a[i+1])
{
i++;
}
else if(a[i] > a[i+1])
{
while(i < n && a[i] >= a[i+1])
{
i++;
}
count++;//又完成了一组
i++;
}
}
cout<<count<<endl;
return 0;
}
📢写在最后
正值世界杯,发现卡塔尔好有钱啊

![[附源码]java毕业设计学校缴费系统](https://img-blog.csdnimg.cn/24c5e7044deb4d0eb3e3c5d4709e254e.png)