这篇文章来讲动态规划(Dynamic Programming),这是一个在面试中很经常出现的题型
1、本质
之前说过,解决算法问题的主流思路就是穷举搜索,即遍历整个搜索空间,找到给定问题的解
只是在某些场景下,由于问题具有一些特殊的性质,我们才可以针对这些性质对算法进行优化
动态规划也符合这个逻辑,其本质还是在穷举搜索的基础上,针对一类问题特征进行优化
那么动态规划所解决的问题都具有什么特征呢?那就是问题存在重叠子问题和最优子结构
换句话说,问题存在重叠子问题和最优子结构,是应用动态规划的必要条件
什么是重叠子问题和最优子结构?
-
重叠子问题:原问题可以拆解成若干个子问题,且子问题之间存在重复
-
最优子结构:子问题相互独立,并且子问题的最优解能推导出原问题的最优解
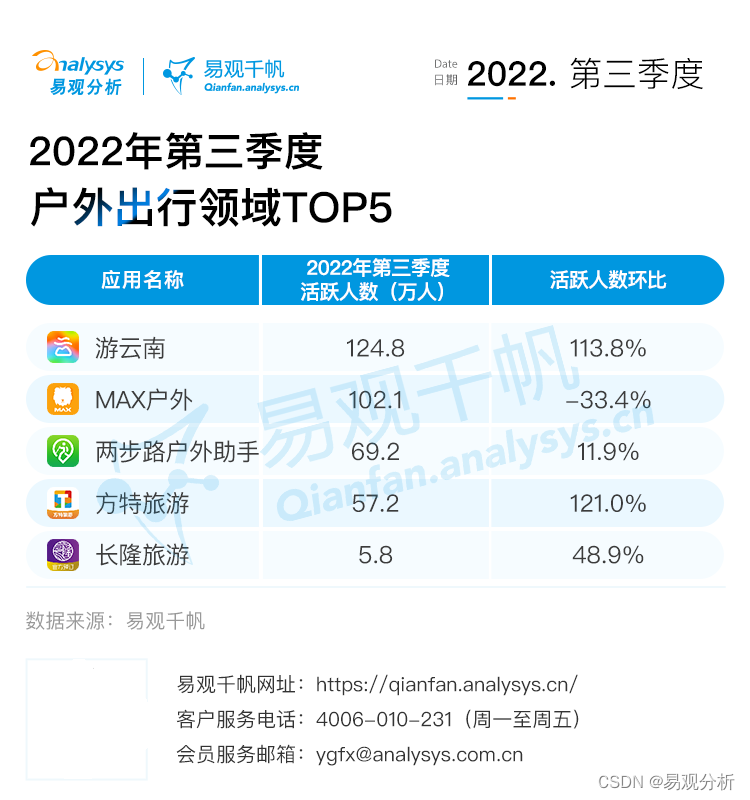
凑零钱问题 | leetcode322
给定一个整数数组
coins表示不同面额的硬币,以及一个整数amount表示总金额
假设每种硬币的数量是无限的,问凑成总金额所需的最少的硬币个数,若无法凑成,则返回
-1
下面以凑零钱问题为例,具体介绍下重叠子问题和最优子结构
举个例子,现在假设 coins = [1, 2, 5], amount = 7,画出递归树如下:

通过递归树可以清楚地看到,要求解的原问题是:凑出总金额为 7 最少需要多少硬币
可以将其分解为几个子问题,分别就是:凑出总金额为 6、5、2 最少需要多少硬币
假设我们能知道凑出总金额为 6、5、2 分别最少需要 2、1、1 个硬币
那么我们就知道凑出总金额为 7 最少需要 2 个硬币
只需选择凑出 5 的方式再加 1 个面额为 2 的硬币,或者选择凑出 2 的方式再加 1 个面额为 5 的硬币
这就是最优子结构:子问题相互独立,求解凑出总金额为 6、5、2 最少需要多少硬币没有依赖关系;且子问题的最优解能推导出原问题的最优解,如果知道凑出总金额为 6、5、2 最少需要多少硬币,就能知道凑出总金额为 7 最少需要多少硬币
重叠子问题体现在哪呢?注意到分解子问题是一个递归的过程,凑出总金额为 6 最少需要多少硬币既作为凑出总金额为 7 的子问题,又作为凑出总金额为 5 的原问题,在所有这些子问题中有存在相同的子问题,上图递归树中颜色相同的节点就表示重复的子问题
最后还想提醒大家一点,动态规划算法一般用于求最值问题
以后碰到求最值问题的,不妨往动态规划的思路想一想
2、核心
好,问题已经讲清楚了,那么动态规划是怎么解决这些问题的呢
动态规划通常有两种解题思路:一是自上而下,具体就是递归加备忘录;二是自下而上,具体就是迭代
(1)自上而下
这是一种以递归为主导思想的解题思路,并在此基础上加入备忘录算法
自上而下是说:假如现在要求解原问题,那么我们就将其分解成子问题,直至到达基本情况
如果不考虑备忘录,其实就是递归算法,我们拿凑零钱问题作为例子给出代码
class Solution {
public:
int dp(vector<int>& coins, int amount) {
// 基本情况
// 如果需要凑出的总金额小于零
// 那么此问题无解
if (amount < 0) {
return -1;
}
// 基本情况
// 如果需要凑出的总金额等于零
// 那么只需要零枚硬币就能凑满
if (amount == 0) {
return 0;
}
int sub_res = INT_MIN; // 子问题答案
int ori_res = INT_MAX; // 原问题答案
for (int coin: coins) {
// 尝试不同的方案,递归求解
// 看递归时不要深入函数,只需要知道这个函数返回的是什么即可,重点在于理解思路
sub_res = dp(coins, amount - coin);
// 如果子问题有解,且是当前最优解,更新原问题答案
ori_res = sub_res != -1 && sub_res + 1 < ori_res ? sub_res + 1 : ori_res;
}
// 如果原问题有解,则返回答案
// 如果原问题无解,则返回负一
return ori_res != INT_MAX ? ori_res : -1;
}
int coinChange(vector<int>& coins, int amount) {
return dp (coins, amount);
}
};
这就是最基础的动态规划思路,其依据是问题具有最优子结构,但这份代码还有很大的优化空间
因为我们没利用上问题具有重叠子问题这个特性,导致在递归求解过程中,会重复计算很多相同的子问题
下面我们来消除下重叠子问题,这时就要用到备忘录算法,或者称为记忆化搜索
具体的做法就是用一个数据结构来记录已经计算过的结果,以后再次遇到时直接返回结果就行
class Solution {
public:
unordered_map<int, int> memo; // key: amount, value: count
int dp(vector<int>& coins, int amount) {
// 基本情况
if (amount < 0) {
return -1;
}
// 基本情况
if (amount == 0) {
return 0;
}
// 查备忘录,若已有结果,则直接返回
unordered_map<int, int>::iterator iter = memo.find(amount);
if (iter != memo.end()) {
return iter -> second;
}
// 求解
int sub_res = INT_MIN;
int ori_res = INT_MAX;
for (int coin: coins) {
sub_res = dp(coins, amount - coin);
ori_res = sub_res != -1 && sub_res + 1 < ori_res ? sub_res + 1 : ori_res;
}
// 写备忘录,将当前结果写进去备忘录
memo[amount] = ori_res != INT_MAX ? ori_res : -1;
return memo[amount];
}
int coinChange(vector<int>& coins, int amount) {
return dp (coins, amount);
}
};
上面是使用字典来记录结果,简单一点用数组也是可以的,而且效率可能还会更高
class Solution {
public:
int* memo; // idx: amount, value: count
int dp(vector<int>& coins, int amount) {
// 基本情况
if (amount < 0) {
return -1;
}
// 基本情况
if (amount == 0) {
return 0;
}
// 查备忘录
if (memo[amount] != -7) {
return memo[amount];
}
// 求解
int sub_res = INT_MIN;
int ori_res = INT_MAX;
for (int coin: coins) {
sub_res = dp(coins, amount - coin);
ori_res = sub_res != -1 && sub_res + 1 < ori_res ? sub_res + 1 : ori_res;
}
// 写备忘录
memo[amount] = ori_res != INT_MAX ? ori_res : -1;
return memo[amount];
}
int coinChange(vector<int>& coins, int amount) {
memo = new int[amount + 1];
for (int i = 0; i < amount + 1; i++) {
memo[i] = -7; // 初始化一个不能取的值,表示未处理
}
return dp(coins, amount);
}
};
(2)自下而上
这是一种以迭代为主导思想的解题思路
自下而上是说:既然我们要求所有的子问题,那么我们不妨直接从子问题开始推导,直至到达原问题
在这种思路中,一个核心的问题就是:怎么根据较小规模的问题,推导出较大规模的问题
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
// 定义数组 ,dp[i] 表示凑出总金额为 i 最少需要多少硬币
vector<int> dp(amount + 1, amount + 1);
// 填充数组(基本情况)
dp[0] = 0;
// 填充数组(其余情况)
for (int i = 1; i <= amount; i++) {
// 对于凑出总金额 i
// 尝试不同的方案
for (int coin: coins) {
if (i - coin < 0) {
continue;
} else {
dp[i] = min(dp[i], dp[i - coin] + 1);
}
}
}
// 返回结果
return dp[amount] != amount + 1 ? dp[amount] : -1;
}
};
一般来说,自上而下和自下而上两种方案的时间复杂度是相当的,都只需要求解一遍子问题即可
具体选择哪种方法,可以根据自己的需要来决定,但在动态规划的场景下,第二种方案好像用得比较多
3、框架
对于动态规划问题,相信大家或多或少都听过状态转移方程这个词
这是一个很重要的概念,如果能正确写出状态转移方程,那么问题就解决一半了
状态转移方程的核心就是根据较小规模的问题推导出较大规模的问题,要点如下:
- 状态:问题中的变量
- 转移:在当前状态下,会有什么选择,能够到达哪些状态
- 方程:输入哪些状态,怎么进行转移,输出哪些新的状态
还是以凑零钱问题为例,状态就是需要凑出的总金额,转移就是选择不同硬币会减少目标总金额,递推方程如下:
- 当
n < 0时,dp(n) = INT_MAX - 当
n = 0时,dp(n) = 0 - 当
n > 0时,dp(n) = min{dp(n - coin) for coin in coins} + 1
该方程含义是:凑出总金额为 n 最少需要 dp(n) 硬币
当 n < 0 和 n = 0 时,表示的是基本情况,当 n > 0 时,表示的是状态转移,是递推方程的核心
状态转移方程是串联整个动态规划问题和解决的关键
状态转移方程不仅能对应到上述两种解题思路,而且能将这两种思路统一到一个逻辑
-
自上而下:状态转移方程对应
dp函数,状态体现在函数参数,转移体现在函数逻辑该方案通过递归调用
dp函数得出答案,给定待求信息后递归直到已知信息 -
自下而上:状态转移方程对应
dp数组,状态体现在数组维度,转移体现在推导过程该方案通过迭代推导
dp数组得出答案,从已知信息开始推导直到待求信息
上面是理论框架,我们尝试解释了状态转移方程是怎么串联起整个动态规划问题的
根据此理论框架,我们可以得到解决动态规划问题的通用代码框架
-
定义:确定问题状态有哪些
对于
dp函数,在函数参数对应问题状态,需要明确函数定义和函数参数
对于dp数组,在数组维度对应问题状态,需要明确数组定义和数组维度 -
初始:明确已知信息是什么
对于
dp函数,需要确定递归边界
对于dp数组,需要确定数组哪些位置已知 -
推导:确定状态转移有哪些
对于
dp函数,在函数内部处理状态转移,需要明确在当前状态经过哪些选择能到达什么状态
对于dp数组,在推导过程处理状态转移,需要明确在当前状态经过哪些选择能到达什么状态 -
结果:明确待求信息是什么
对于
dp函数,需要确定初始调用
对于dp数组,需要确定数组哪些位置待求
对照上面的代码框架,我们重新看回凑零钱的例子
我已经用注释在代码中把框架部分标注出来,看看大家能否对动态规划有不一样的理解
// 自上而下
// 其核心是 dp 函数
// 无备忘录版本,只要能理解这个版本,加上备忘录也很简单
// 无非是在处理子问题时先去查备忘录,有则直接返回,无则求出结果后记录到备忘录再返回
class Solution {
public:
// 【定义】
// 函数有两个参数,但只有一个表示状态,也就是需要凑出的总金额,另一个是辅助参数,用于确定选择
// 函数 dp(i) 表示凑出总金额为 i 最少需要多少硬币
int dp(vector<int>& coins, int amount) {
// 【初始】
// 已知信息是凑出总金额为 0 需要零个硬币,凑出总金额为负是无解的
// 因此递归边界可以确定为 0 以及负数
if (amount < 0) {
return -1;
}
if (amount == 0) {
return 0;
}
// 【推导】
// 给定待求信息后递归直到已知信息
int sub_res = INT_MIN;
int ori_res = INT_MAX;
for (int coin: coins) {
sub_res = dp(coins, amount - coin); // 看递归函数不要深入,要根据定义理解逻辑
ori_res = sub_res != -1 && sub_res + 1 < ori_res ? sub_res + 1 : ori_res;
}
return ori_res != INT_MAX ? ori_res : -1;
}
int coinChange(vector<int>& coins, int amount) {
// 【结果】
// 待求信息是凑出总金额为 amount 需要多少硬币
// 因此初始调用的参数就是 amount
return dp(coins, amount);
}
};
// 自下而上
// 其核心是 dp 数组
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
// 【定义】
// 数组只有一个维度,也就只有一个状态,来表示需要凑出的总金额
// 数组 dp[i] 表示凑出总金额为 i 最少需要多少硬币
vector<int> dp(amount + 1, amount + 1);
// 【初始】
// 已知信息是凑出总金额为 0 需要零个硬币
// 因此数组中索引为 0 的位置是已知的
dp[0] = 0;
// 【推导】
// 从基本信息开始推导直到待求信息
for (int i = 1; i <= amount; i++) {
for (int coin: coins) {
if (i - coin < 0) {
continue;
} else {
dp[i] = min(dp[i], dp[i - coin] + 1);
}
}
}
// 【结果】
// 待求信息是凑出总金额为 amount 需要多少硬币
// 因此数组中索引为 amount 的位置是待求的
return dp[amount] != amount + 1 ? dp[amount] : -1;
}
};
4、例题
对于动态规划题目来说,使用自上而下的思想解题相对来说是比较简单的
但是为了帮助大家更好地掌握动态规划的题目,以下例题都会使用更难的自下而上的思路进行分析
(1)最长递增子序列 | leetcode300
给定一个整数数组,找出其中最长严格递增子序列的长度(子序列是不要求连续的)
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
// 特判
int n = nums.size();
if (n == 0) {
return 0;
}
// 定义数组,dp[i] 表示以 nums[i] 结尾的子问题的结果,即最长严格递增子序列的长度,0 <= i <= n - 1
int dp[n];
// 填充数组
// 边界情况,dp[0] 表示以 nums[0] 结尾的子问题的结果,为一,因为有且只有一个元素
dp[0] = 1;
// 填充数组
// 其余情况,从上往下、从左往右填充
for (int i = 1; i < n; i++) {
dp[i] = 1;
// 遍历选择
for (int j = 0; j < i; j++) {
if (nums[j] < nums[i] ) {
dp[i] = max(dp[i] , dp[j] + 1);
}
}
}
// 返回结果
return *std::max_element(dp, dp + n);
}
};
(2)最长公共子序列 | leetcode1143
给定两个字符串,找出它们最长公共子序列的长度(子序列是不要求连续的)
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
// 特判
int m = text1.size();
int n = text2.size();
if (m == 0) {
return 0;
}
if (n == 0) {
return 0;
}
// 定义数组,dp[i][j] 表示当 text1 长度为 i 且 text2 长度为 j 时子问题的结果,即最长公共子序列的长度,0 <= i <= m,0 <= j <= n
int dp[m + 1][n + 1];
// 填充数组
// 边界情况,dp[i][0] 表示当 text1 长度为 i 且 text2 长度为 0 时子问题的结果,为零,因为 text2 字符串长度为零
// dp[0][j] 表示当 text1 长度为 0 且 text2 长度为 j 时子问题的结果,为零,因为 text1 字符串长度为零
for (int i = 0; i <= m; i++) {
dp[i][0] = 0;
}
for (int j = 0; j <= n; j++) {
dp[0][j] = 0;
}
// 填充数组
// 其余情况,从上往下、从左往右填充
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 分类讨论
if (text1[i - 1] == text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 返回结果
return dp[m][n];
}
};
(3)最长回文子序列 | leetcode516
给定一个字符串,找出其中最长回文子序列的长度(子序列是不要求连续的)
class Solution {
public:
int longestPalindromeSubseq(string s) {
// 特判
int n = s.size();
if (n == 0) {
return 0;
}
// 定义数组,dp[i][j] 表示以 s[i] 开头且 s[j] 结尾的子问题的结果,即最长回文子序列的长度,0 <= i <= j <= n
int dp[n][n];
memset(dp, 0, sizeof(dp));
// 填充数组
// 边界情况,dp[i][i] 表示以 s[i] 开头且 s[i] 结尾的子问题的结果,为一,因为有且只有一个元素
for (int i = 0; i < n; i++) {
dp[i][i] = 1;
}
// 填充数组
// 其余情况,从下往上、从左往右填充
for (int i = n - 2; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
// 分类讨论
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
// 返回结果
return dp[0][n - 1];
}
};
(4)高楼扔鸡蛋 | leetcode887
class Solution {
public:
int superEggDrop(int k, int n) {
// 特判
if (
k <= 1 ||
n <= 1
) {
return n;
}
// 定义数组,dp[i][j] 表示当鸡蛋数为 i 且楼层数为 j 时子问题的结果,即确定在最坏情况下鸡蛋掉落不会碎的最高楼层的操作次数
int dp[k + 1][n + 1];
// 填充数组
// 边界情况,dp[i][0] 表示当鸡蛋数为 i 且楼层数为 0 时子问题的结果,只需随便返回 0,因为此情况不合法
// dp[0][j] 表示当鸡蛋数为 0 且楼层数为 j 时子问题的结果,只需随便返回 0,因为此情况不合法
// dp[i][1] 表示当鸡蛋数为 i 且楼层数为 1 时子问题的结果,因为楼层数为 1,所以只需在第一层楼层尝试即可,因此最小操作次数为 1
// dp[1][j] 表示当鸡蛋数为 1 且楼层数为 j 时子问题的结果,因为鸡蛋数为 1,所以只能从低到高楼层逐层尝试,因此最小操作次数为 j
for (int i = 0; i <= k; i++) {
dp[i][0] = 0;
dp[i][1] = 1;
}
for (int j = 0; j <= n; j++) {
dp[0][j] = 0;
dp[1][j] = j;
}
// 填充数组
// 其余情况,从上往下、从左往右填充
for (int i = 2; i<= k; i++) {
for (int j = 2; j <= n; j++) {
// 遍历选择
// 当鸡蛋数为 i 且楼层数为 j 时,因为不知道在哪一层扔鸡蛋符合条件,所以需要逐一尝试在每一层扔鸡蛋的情况
int result = INT_MAX;
for (int k = 1; k <= j; k++) {
// 如果鸡蛋碎了,说明在 k 层及以上的楼层扔鸡蛋也会碎
// 此时鸡蛋数量减一,之后继续检查 k 层以下的楼层即可,即状态转移为:dp[i - 1][k - 1]
int case1 = dp[i - 1][k - 1] + 1;
// 如果鸡蛋没碎,说明在 k 层及以下的楼层扔鸡蛋也不碎
// 此时鸡蛋数量不变,之后继续检查 k 层以上的楼层即可,即状态转移为:dp[i][j - k]
int case2 = dp[i][j - k] + 1;
// max 对应最坏情况
// min 对应最少次数
result = min(result, max(case1, case2));
}
dp[i][j] = result;
}
}
// 返回结果
return dp[k][n];
}
};
class Solution {
public:
int superEggDrop(int k, int n) {
// 特判
if (
k <= 1 ||
n <= 1
) {
return n;
}
// 定义数组,dp[i][j] 表示当鸡蛋数为 i 且楼层数为 j 时子问题的结果,即确定在最坏情况下鸡蛋掉落不会碎的最高楼层的操作次数
int dp[k + 1][n + 1];
// 填充数组
// 边界情况,dp[i][0] 表示当鸡蛋数为 i 且楼层数为 0 时子问题的结果,只需随便返回 0,因为此情况不合法
// dp[0][j] 表示当鸡蛋数为 0 且楼层数为 j 时子问题的结果,只需随便返回 0,因为此情况不合法
// dp[i][1] 表示当鸡蛋数为 i 且楼层数为 1 时子问题的结果,因为楼层数为 1,所以只需在第一层楼层尝试即可,因此最小操作次数为 1
// dp[1][j] 表示当鸡蛋数为 1 且楼层数为 j 时子问题的结果,因为鸡蛋数为 1,所以只能从低到高楼层逐层尝试,因此最小操作次数为 j
for (int i = 0; i <= k; i++) {
dp[i][0] = 0;
dp[i][1] = 1;
}
for (int j = 0; j <= n; j++) {
dp[0][j] = 0;
dp[1][j] = j;
}
// 填充数组
// 其余情况,从上往下、从左往右填充
for (int i = 2; i<= k; i++) {
for (int j = 2; j <= n; j++) {
// 修改之处
// 当鸡蛋数为 i 且楼层数为 j 时,可以用二分搜索来查找楼层,代替线性搜索
int result = INT_MAX;
int lp = 1;
int rp = j;
while (lp <= rp) {
// 找出中间楼层 m
int m = lp + (rp - lp) / 2;
// 如果鸡蛋碎了,说明在 m 层及以上的楼层扔鸡蛋也会碎
// 此时鸡蛋数量减一,之后继续检查 m 层以下的楼层即可
int case1 = dp[i - 1][m - 1] + 1;
// 如果鸡蛋没碎,说明在 m 层及以下的楼层扔鸡蛋也不碎
// 此时鸡蛋数量不变,之后继续检查 m 层以上的楼层即可
int case2 = dp[i][j - m] + 1;
// 缩小搜索区间
if (case1 > case2) {
rp = m - 1;
} else {
lp = m + 1;
}
// max 对应最坏情况
// min 对应最少次数
result = min(result, max(case1, case2));
}
dp[i][j] = result;
}
}
// 返回结果
return dp[k][n];
}
};
(5)正则表达式 | leetcode10
class Solution {
public:
bool isMatch(string s, string p) {
// 预处理
// 字符串 s 和字符串 p 前填充一个无关字符,此时 dp[i][j] 可以直接表示 s 的前 i 个字符和 p 的前 j 个字符是否匹配
int m = s.size();
int n = p.size();
s.insert(0, "_");
p.insert(0, "_");
// 定义数组,dp[i][j] 表示 s 的前 i 个字符和 p 的前 j 个字符是否匹配
bool dp[m + 1][n + 1];
// 填充数组
// 边界情况,dp[0][0] 表示 s 的前 0 个字符和 p 的前 0 个字符是否匹配,为 true ,因为两者都是空字符串
// dp[i][0] 表示 s 的前 i 个字符和 p 的前 0 个字符是否匹配,此时 p 为空字符串,只有 s 是空字符串才能匹配
// dp[0][j] 表示 s 的前 0 个字符和 p 的前 j 个字符是否匹配,此时 s 为空字符串,只有 p 是“字符+星号”组合才能匹配
dp[0][0] = true;
for (int i = 1; i <= m; i++) {
dp[i][0] = false;
}
for (int j = 1; j <= n; j++) {
dp[0][j] = j % 2 == 0 && p[j] == '*' && dp[0][j - 2];
}
// 填充数组
// 其余情况,从上往下、从左往右填充
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 分类讨论
// 如果 p[j] 为字符且 s[i] != p[j],那么 dp[i][j] 结果就等于 false
// 如果 p[j] 为字符且 s[i] == p[j],那么 dp[i][j] 结果取决于 dp[i - 1][j - 1]
if (
p[j] != '.' &&
p[j] != '*'
) {
dp[i][j] = s[i] == p[j] && dp[i - 1][j - 1];
}
// 如果 p[j] 为点号,那么 p 中点号必然匹配 s 中一个字符,那么 dp[i][j] 结果取决于 dp[i - 1][j - 1]
else if (p[j] == '.') {
dp[i][j] = dp[i - 1][j - 1];
}
// 如果 p[j] 为星号且 p 中“字符+星号”匹配 s 中零个字符,那么 dp[i][j] 结果取决于 dp[i][j - 2]
// 如果 p[j] 为星号且 p 中“字符+星号”匹配 s 中一个字符,那么 dp[i][j] 结果取决于 dp[i - 1][j]
else if (p[j] == '*') {
dp[i][j] = dp[i][j - 2] || ((p[j - 1] == s[i] || p[j - 1] == '.') && dp[i - 1][j]);
}
}
}
// 返回结果
return dp[m][n];
}
};
(6)编辑距离 | leetcode72
class Solution {
public:
int myMin(int a, int b, int c) {
return min(min(a, b), c);
}
int minDistance(string word1, string word2) {
// 特判
int m = word1.size();
int n = word2.size();
if (m == 0) {
return n;
}
if (n == 0) {
return m;
}
// 定义数组,dp[i][j] 表示当 A 长度为 i 且 B 长度为 j 时子问题的结果,即编辑距离
int dp[m + 1][n + 1];
// 填充数组
// 边界情况,dp[i][0] 表示当 A 长度为 i 且 B 长度为 0 时子问题的结果,为 i,只需对 A 做 i 次删除或对 B 做 i 次插入即可
// dp[0][j] 表示当 A 长度为 0 且 B 长度为 j 时子问题的结果,为 j,只需对 A 做 j 次插入或对 B 做 j 次删除即可
for (int i = 0; i < m + 1; i++) {
dp[i][0] = i;
}
for (int j = 0; j < n + 1; j++) {
dp[0][j] = j;
}
// 填充数组
// 其余情况,从上往下、从左往右填充
for (int i = 1; i < m + 1; i++) {
for (int j = 1; j < n + 1; j++) {
// 分类讨论
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = myMin(dp[i - 1][j] + 1, dp[i][j - 1] + 1, dp[i - 1][j - 1] + 1);
}
}
}
// 返回结果
return dp[m][n];
}
};
5、技巧
经过上面题目的练习,相信大家对解决动态规划问题都有一定的感悟
下面是从题目中总结的一些关键技巧,有些是规律性的总结,有些是对过程的优化
建议大家看完下面的总结后重新回顾下例题
(1)怎么定义 dp 函数或 dp 数组
常用的定义方法如下:
- 以
nums[i]开头的子问题的结果 - 以
nums[i]结尾的子问题的结果 nums[0...i]中的子问题的结果(从前往后数长度为i的数组中 子问题的结果)nums[i...n]中的子问题的结果(从后往前数长度为i的数组中 子问题的结果)
(2)怎么推导 dp 函数或 dp 数组
推导过程的核心是数学归纳法:在已知 dp[1...k] 的情况下,求 dp[k + 1]
常用的推导思路如下:
- 在当前状态下,面临哪些选择,尝试所有选择并取最值
- 在当前状态下,满足哪些条件才能进行选择,对不同的条件分类讨论
对于自下而上的思路来说,推导的过程就是填充数组的过程
而填充数组就有两个方向:从上往下、从左往右;从下往上,从右往左
我们可以借助已知信息和待求信息,分析它们的相对位置,得出填充方向,具体来说:
- 思考:如果要求当前值,信息可以从什么方向获得
- 思考:如果要求目标值,怎么减小问题规模,怎么利用以前信息
(3)空间优化
动态规划是对时间复杂度的一种优化,一般来说,可以将时间复杂度降到多项式时间
但在动态规划的框架下,对于某些情况,还能使用滚动数组来对空间复杂度进行优化
使用滚动数组一般可以将二维数组压缩成一维数组,或者将一维数组压缩成常数
什么情况下才能使用滚动数组,以及滚动数组究竟要怎么用呢?
如果在填充数组的过程中,要求当前值只需要用到之前的某些值,那么我们就没必要保存完整的数组
而只需要用更小的数组保存以后需要的值就好,这就是滚动数组的思想
(4)记录过程
通过动态规划,我们可以求出问题的最值,但是我们能不能知道经过怎样的过程才能得到这个最值呢
答案是肯定的,不过我们需要对求解的过程做一些修改
一种思路是我们在填充数组时,不仅仅要记录结果值,还要记录到达此结果的路径
这样当到达目标值时,就能知道怎么到达这个目标的,这种方法返回结果快,但是需要额外的空间
而另一种思路是在填充数组时,还是只会记录结果值,当需要求路径时再通过某些方法回溯
这种方法返回结果会比较慢,但无需额外的存储空间保存路径