📫作者简介:小明java问道之路,专注于研究 Java/ Liunx内核/ C++及汇编/计算机底层原理/源码,就职于大型金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的架构设计与演进、系统优化与稳定性建设。
📫 热衷分享,喜欢原创~ 关注我会给你带来一些不一样的认知和成长。
🏆 InfoQ签约作者、CSDN专家博主/后端领域优质创作者/内容合伙人、阿里云专家/签约博主、51CTO专家 🏆
🔥如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主~
本文目录
本文导读
一、MySQL 执行计划分析
1、查看 SQL 执行计划
1.1、explain详解
1.2、desc 以及 show create table 解析
2、通过配置文件(Profile )查找查询成本消耗
3、通过 Optimizer Trace (优化器跟踪)表查看 SQL 执行计划树
二、MySQL 查询优化器
三、MySQL 执行计划查询分析
1、key_len计算规则
2、MySQL常见参数
四、如何优化 SQL
1、SQL索引篇
1.1、索引扫描
1.2、哪些列是适合业务需要的索引
1.3、模糊匹配查询
2、排序篇
3、查询选择篇
4、MySQL 内部优化 SQL
5、SQL 编写规范
总结
本文导读
本文详细介绍MySQL执行计划及其原理,并且对SQL调优提高查询效率,如何优化SQL做出指导性建议,同时本文也是前面16篇文章的一个优化与实战思路的指导综合。
可以学习本文之前,建议重点学习《深入理解MySQL索引原理》*、《深入理解MySQL索引优化器原理》*、《MySQL体系结构与内部组件工作原理解析》*、《高性能高可用设计实战-索引篇》*、《MySQL数据库锁使用与InnoDB加锁的原理解析》
一、MySQL 执行计划分析
首先确定SQL调优的都是什么,在我们工作中,不会什么SQL上来就是调优,当我们发现当慢查询或SQL执行遇到瓶颈时,首先我们要分析SQL的执行计划,找到导致慢SQL的原因。
为什么要关注sql执行计划?
因为sql执行计划可以告诉我们很多关于如何优化sql的信息。如何通过SQL计划访问中的数据(是使用全表扫描还是索引查找)一个表中的多个表中可能有不同的索引。表的类型是什么,它们是子查询、关联查询等等。
1、查看 SQL 执行计划
-- 查看sql执行计划
explain SQL;
-- 查看表结构
desc 表名;
-- 查看建表语句
show create table 表名;1.1、explain详解

id:
每个select都会对应一个id,id值越大,执行优先级越高,相同的id值,从上往下依次执行
select_type:查询类型
下面给出 select_type 类型:
simple:简单查询,不包含子查询和 union;
primary:复杂查询的最外层查询;
subquary:包含在select中不包含在from的子查询;
derived:包含在from中的子查询,mysql会把这些数据放到临时表中,也称为派生查询;
union:在union中第二个和随后的select。
table:表示 explain 正在访问哪张表。
type:表示关系类型或者访问类型,即 mysql 如何查找表中的行。
下面给出 type 类型:
NULL:MySQL在优化阶段分解查询语句,在执行阶段不需要访问索引树或表的查询类型
system:这是常量的特殊情况。当表中只有一条数据时,常量查询为system
const:MySQL优化了查询的一部分,并将其转换为常量。将主键与常量进行比较时,表最多返回一条记录。
eq_ref:当主键或非主键索引的所有部分都被引用时,最多只返回一条记录。简单选择查询不会显示此类型。
ref:使用唯一索引是不实际的。如果使用公共索引或唯一索引的前缀部分,则与值进行比较时,索引可能会返回多行
range:范围扫描,in between
index:可以通过扫描整个索引获得结果。通常,扫描二级索引。此扫描不会从根节点开始快速搜索,而是直接扫描辅助索引的子节点。速度相对较慢。这种查询通常用于覆盖索引。次要索引通常较小,比所有索引都快
All:全表扫描,扫描聚集索引的所有单词节点。通常,这种情况需要优化。
possible_keys:这一列显示可能用到哪些索引。
key:mysql在查询过程中使用到的索引。
key_len:mysql在查询中使用索引的长度。
ref:显示在key列记录的索引中,表查找时所用到的列或常量,常见的有 const 常量,字段名 film.id。
extra:额外信息,常见的重要信息,例如 useing index 使用覆盖索引。
1.2、desc 以及 show create table 解析
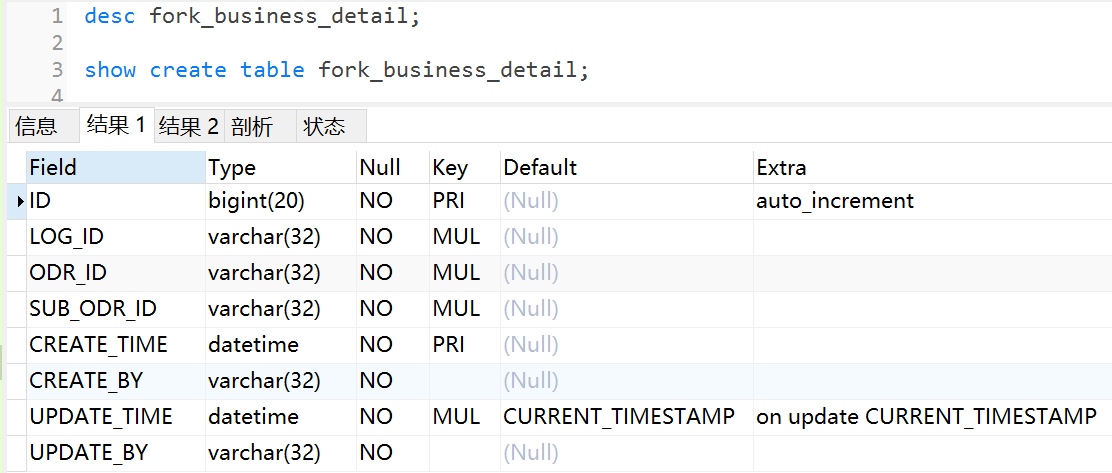

2、通过配置文件(Profile )查找查询成本消耗
-- 开启性能分析
set profiling=1;
-- 执行 SQL
select * from fork_business_detail where ODR_ID='123';
-- 获取 Query_ID
show profiles;
-- 查看详细的 profile 信息
show profile for query Query_ID;3、通过 Optimizer Trace (优化器跟踪)表查看 SQL 执行计划树
-- 开启 optimizer Trace 表查看 SQL 执行计划树
set session optimizer_trace='enabled=on';
-- 执行 SQL
select * from fork_business_detail where ODR_ID='123';
查询 information_schema.optimizer_trace 表,获取 SQL 查询计划树
-- 开启此项影响性能,记得用后关闭
set session optimizer_trace='enabled=off';二、MySQL 查询优化器
学习本节之前,建议重点学习《深入理解MySQL索引优化器原理》、《MySQL体系结构与内部组件工作原理解析》
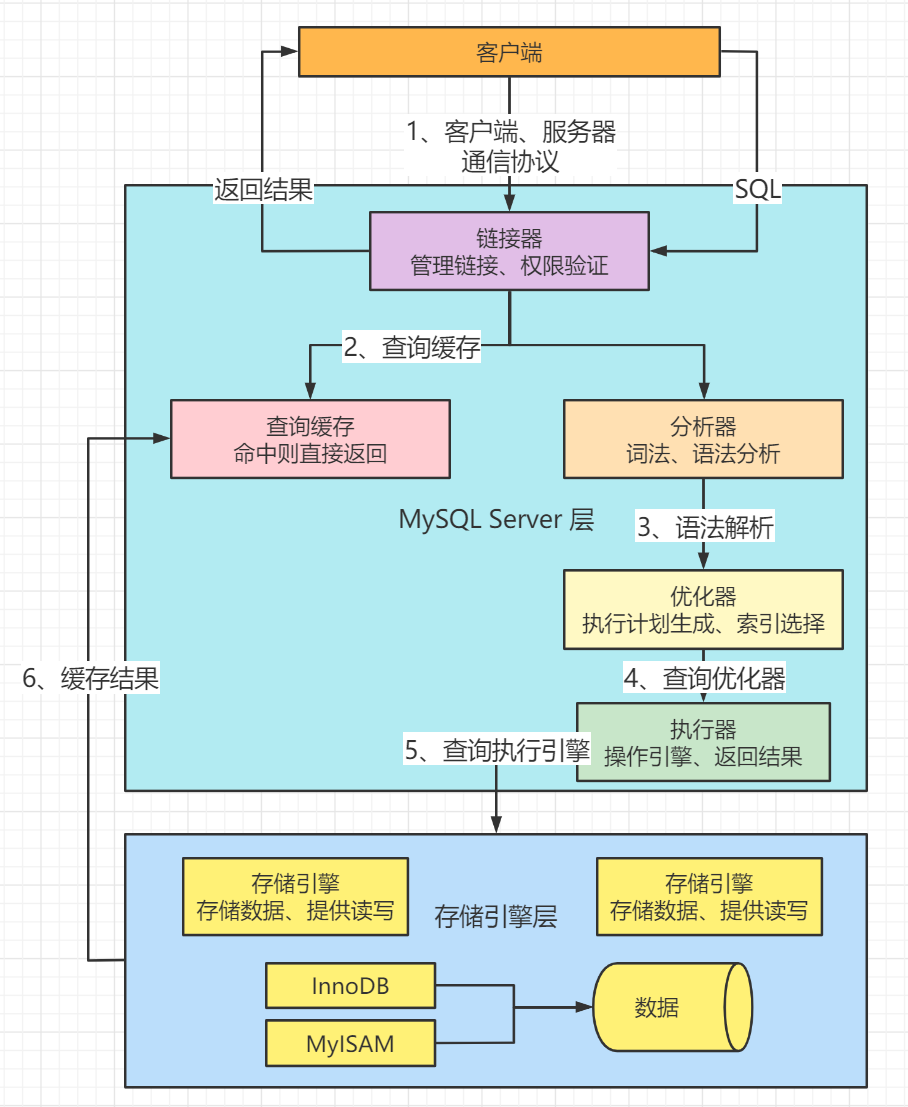
1、客户端向服务器发送SELECT查询;
2、服务器首先检查查询缓存。如果缓存被命中,存储在缓存中的结果将立即返回。否则,进入下一阶段;
3、服务器执行SQL解析、预处理,查询优化器生成相应的执行计划;
4、MySQL调用存储引擎的API,根据优化器生成的执行计划执行查询;
5、结果将返回到客户端,并同时放入查询缓存。
三、MySQL 执行计划查询分析
1、key_len计算规则
字符串:
char(n) varchar(n),n代表字符数,不是字节数,utf-8中;char(n) 就是3n字节;varchar(n)是3n+2个字节 2用来存储字符串的长度(因为varchar是可变长的)
数值类型:
tinyint 1字节;smallint 2字节;int 4字节;bigint 8字节
时间类型:
date 3字节;timestamp 4字节;datetime 8字节
如果字符串可以为null需要1字节记录字符串是否weinull,索引最大长度为768字节,当字符串过长,mysql会做一个类似最左前缀索引的处理,将前半部分字节提取出来做索引。
2、MySQL常见参数
参数 slow_query_log,是否启用慢速查询日志。ON或1表示启用,OFF或0表示禁用。
参数 long_query_time,设置慢速查询阈值。MySQL 5.7支持微秒。
参数 slow_query_log_file,慢查询文件存储路径。
参数 log_queries_not_using_indexes,指示是否将非索引查找SQL记录到慢速查询文件中。
参数 log_throttle_queries_not_using_indexes,表示每分钟记录到没有索引的慢速查询文件中的SQL语句的上限,0表示没有限制。
参数 max_execution_time,用于控制SELECT语句的最大执行时间,以毫秒为单位。如果超过此值,MySQL将自动终止查询。
四、如何优化 SQL
学习本节之前,建议重点学习 《深入理解MySQL索引原理》、《深入理解MySQL索引优化器原理》、《高性能高可用设计实战-索引篇》、《MySQL数据库锁使用与InnoDB加锁的原理解析》
1、SQL索引篇
1.1、索引扫描
对于大表,如果扫描整个表,则返回查询需要很长时间,必须使用索引扫描来加快查询速度。但索引过多也会降低写入和修改的速度。而且,如果表数据和索引数据的比例失调,不利于后期的正常维护。
1.2、哪些列是适合业务需要的索引
创建具有高选择性的索引,也可以在状态列上创建索引(不是一定不可创建)。创建索引时,除了某些特殊情况外,应避免冗余索引。创建索引后,尽量不要过于频繁地修改它。对于可以在索引中完成的查询,不要返回到表。
与多个表关联的SQL必须在关联列上具有索引,并且具有一致的字段类型,以便MySQL在执行嵌套循环连接查找时可以使用索引,并且不会因为字段类型不匹配而发生隐式转换,从而导致无法使用索引。
当关联多个表时,请尝试使用具有小结果集的表作为驱动表,小结果集的表不是小表。
1.3、模糊匹配查询
当查询条件完全模糊时,例如“%**%”,则不能使用索引,在这种情况下,必须加具有高选择性的其他列或 where 条件,作为加快查询速度的补充。对于这种全模糊匹配场景,可以在 ES (elasticsearch)中求解。
2、排序篇
order by/group by SQL涉及排序,必须在索引中包含排序字段,并使排序字段的排序顺序与索引列中的排序顺序相同,这可以避免排序或减少排序次数。
MySQL不关心 from 中出现的表的顺序,也不关心 where 中的顺序。
3、查询选择篇
MySQL也非常擅长处理简短的SQL。总体时间将更短,并且不会产生臃肿的SQL,这很难理解和优化。
尽量不要使用子查询。重新扫描由子查询生成的临时表时,将没有要查询的索引,只能执行完整的表扫描。
4、MySQL 内部优化 SQL
1、重新定义表的关联顺序。当查询多个表时,MySQL 优化器将自动选择驱动器表和表的联接顺序,基于成本规则,SQL 执行时间将大大减少。
2、使用等效变化规则,MySQL 可以合并或减少一些比较,并删除一些总是正确或不正确的判断。
3、优化 count()、min() 和 max()。索引和列是否可以为空通常可以帮助 MySQL 优化此类表达式。例如,要查找最小值,只需查找索引树最左侧的第一条记录。
5、SQL 编写规范
1、SELECT只获取必需的字段,尽量避免 SELECT *,这可以减少网络带宽消耗,有效地使用覆盖指数,并且改变表结构对程序的影响很小。
2、用 in 替换 or,SQL语句中的 in 不应包含太多的值,该值应小于1000,过多的随机IO会增加并影响性能。
3、不要使用order by rand() ,因为会将向表中添加几个伪列,然后使用rand() 函数计算每行数据的 rand() 值。最后,根据行进行排序。这通常会在磁盘上生成一个临时表,因此效率很低。建议您首先使用 rand() 函数获取随机主键值,然后使用主键获取数据。
4、在具有不确定结果的SQL_函数中使用 now()、rand()、sysdate()、current_user()谨慎使用。在语句级复制场景中,主数据和从数据不一致;QUERY CACHE 查询缓存不能用于由值不确定的函数生成的SQL语句。
5、重要的SQL必须编制索引,其中条件列包括更新和删除、排序依据、分组依据、不同字段和多表联接字段。
6、禁止使用%前导查询,避免B+树索引失效。
7、禁用not in、!=、<>、not like否定查询。
8、EXPLAIN 判断 SQL 语句是否正确使用索引,并尽量避免 Using File Sort、Using Temporary 等 extra 列出现。
9、尝试使用批处理SQL语句,减少与数据库的交互次数。
10、在获取数量数据时,建议分批获取数据。每次获得的数据少于5000条,结果集应少于1M。
11、将复杂 SQL 拆分为多个小 SQL 以避免事务,减少锁表时间。简单 SQL 易于与 QUERY CACHE 查询缓存一起使用。
总结
本文详细介绍MySQL执行计划及其原理,并且对SQL调优提高查询效率,如何优化SQL做出指导性建议,同时本文也是前面16篇文章的一个优化与实战思路的指导综合。
学习本文之前,建议重点学习《深入理解MySQL索引原理》*、《深入理解MySQL索引优化器原理》*、《MySQL体系结构与内部组件工作原理解析》*、《高性能高可用设计实战-索引篇》*、《MySQL数据库锁使用与InnoDB加锁的原理解析》