本文探讨以下问题:哪种智能合约语言更有优势,Solidity 还是 Vyper?最近,关于哪种是“最好的”智能合约语言存在很多争论,当然了,每一种语言都有它的支持者。
这篇文章是为了回答这场辩论最根本的问题:
我应该使用哪一种智能合约语言?
为了弄清问题的本质,我们将先讨论语言的工具和可用性,然后再考虑智能合约开发者主要关心的问题之一:gas 优化。具体来说,我们将研究四种 EVM 语言(可以在 Ethereum、Avalanche、Polygon 等链上运行的语言):Solidity、Vyper、Huff 和 Yul。Rust 并不在其中,它应该出现在一篇关于非 EVM 链的文章。
但首先,剧透一下结果。
Solidity、Vyper、Huff 和 Yul 都是可以让你完成工作的优秀语言。 Solidity 和 Vyper 是高级语言,大多数人都会用到。但是如果你有兴趣编写近乎汇编的代码,那 Yul 和 Huff 也可以胜任。
所以如果你坚持选择其中一个使用,那就抛硬币吧:因为无论你选择哪种语言,都是可以完成项目的。如果你是智能合约的新手,完全可以使用任何一种语言来开始你旅程。
此外,这些语言也一直在变化,你可以挑选特定的智能合约和数据,从而使得运行它们的不同的语言,表现出来的更好或者更差的效果。所以请注意,为了避免不客观,我们在比较不同语言在 gas 优化上的优劣时,都选择了最简的智能合约作为例子,如果你有更好的例子,也请分享给我们!
现在,如果你是这个领域的老手,让我们深入了解这些语言,看看它们的细节吧。
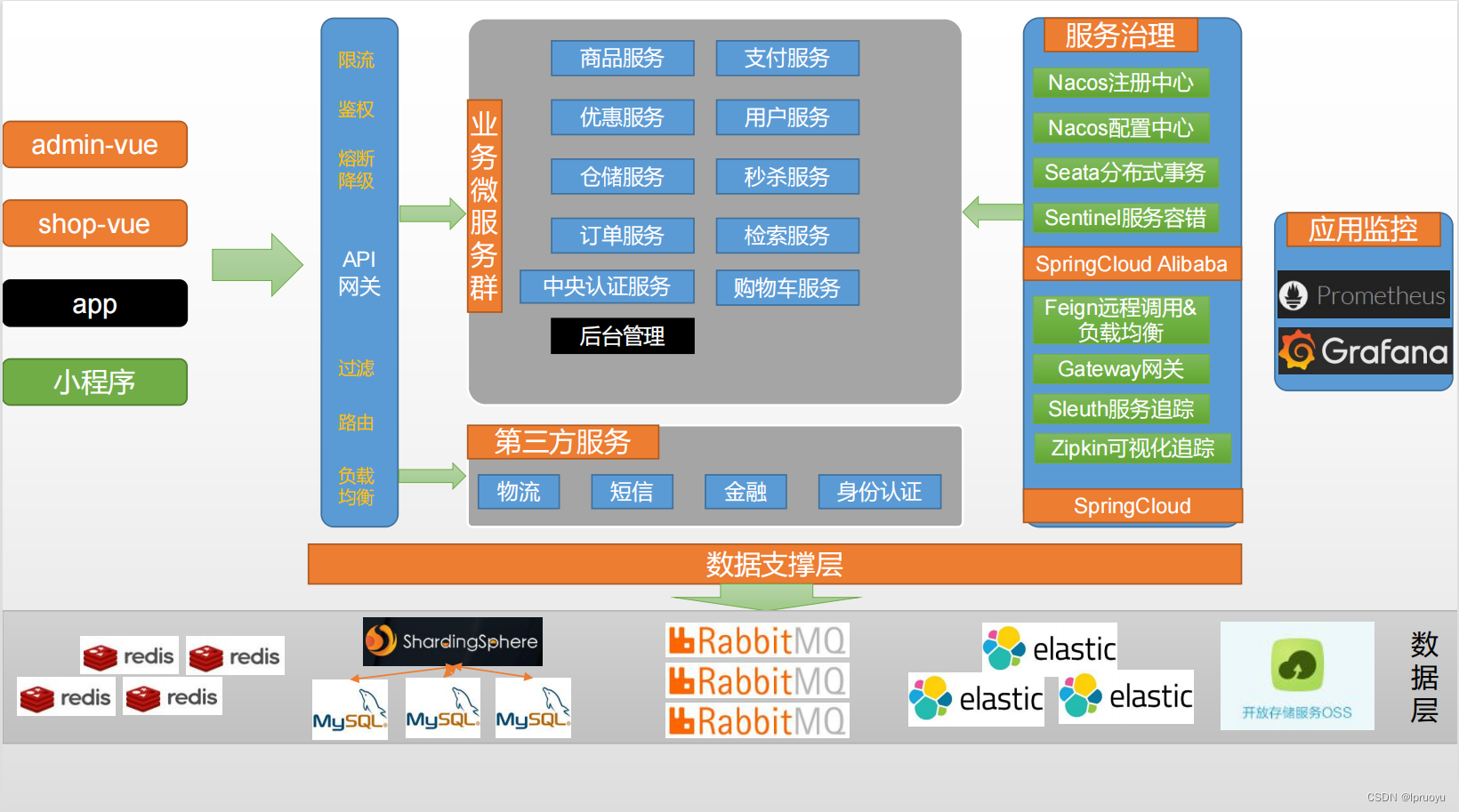
EVM 编程语言
我们将要研究的四种语言如下:
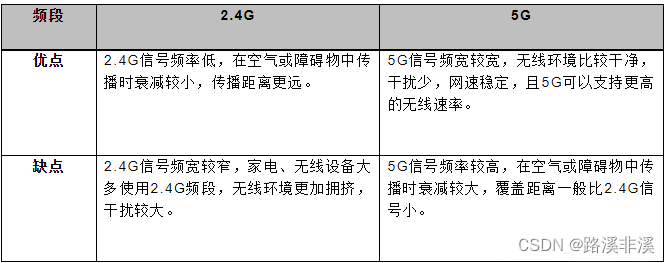
- Solidity:目前 DeFi TVL (DeFi 锁定的通证价值)占比最大的语言。是一种高级语言,类似于 JavaScript。
- Vyper:目前 DeFi TVL 排名第二的语言。也是一种高级语言,类似于 Python。
- Huff:一种类似于汇编的底层语言。
- Yul:一种类似于汇编的底层语言,内置于 Solidity(尽管有人认为它仍然是高级语言)。
为什么是这四个?
使用这四种语言,是因为它们都与 EVM 兼容,而且其中的 Solidity 和 Vyper 是迄今为止最受欢迎的两种语言。我添加了 Yul,因为在不考虑 Yul 的情况下,与 Solidity 进行 gas 优化比较是不全面的。我们添加了 Huff 是因为想以一种不是 Yul,但是与几乎就是在用 opcode 编写合约的语言作为基准。
就 EVM 而言,在 Vyper 和 Solidity 之后,第三、第四和第五的流行程度也越来越高。对于没有在本文中比较的语言;只是因为它们的使用度不高。然而,有许多很有前景的智能合约语言正在兴起,我期待能够在未来尝试它们。
什么是 Solidity?
Solidity 是一种面向对象的编程语言,用于在以太坊和其他区块链上来编写智能合约。 Solidity 深受 C++、Python 和 JavaScript 的影响,并且专为 EVM 而设计。
什么是 Vyper?
Vyper 是一种面向合约的类似于 Python 的编程语言,也是为 EVM 设计的。 Vyper 增强了可读性,并且限制了某些用法,从而改进了 Solidity。理论上,Vyper 提升了智能合约的安全性和可审计性。
当前的情况

来源于 DefiLlama 语言分析数据
根据 DefiLlama 的数据,截至目前,在 DeFi 领域,Solidity 智能合约获得了 87% 的 TVL,而 Vyper 智能合约获得了 8%。
因此,如果你纯粹基于受欢迎程度来选择语言的话,除了 Solidity,就不需要看别的了。
比较相同的合约
现在让我们了解每种语言写出的合约的是什么样的,然后比较它们的 gas 性能。
这是用每种语言编写的四份几乎相同的合同。做了大致相同的事情,它们都:
- Storage slot 0 有一个私有变量 number (uint256)。
- 有一个带有 readNumber() 函数签名的函数,它读取 storage slot 0 中的内容。
- 允许你使用 storeNumber(uint256) 函数签名更新该变量。
这就是这个合约做的操作。
我们用来比较语言的所有代码都在这个 GitHub repo 中。
🐉 Solidity

🐍 Vyper

♞ Huff

🧮 Yul

开发体验
通过查看这四张图片,我们可以大概了解编写每种语言的感受。就开发人员经验而言,编写 Solidity 和 Vyper 代码要快得多。这些语言是高级语言,而 Yul 和 Huff 是更底层的语言。仅出于这个原因,就很容易理解为什么这么多人采用 Vyper 和 Solidity(同时它们存在的时间也更长)。
看一下 Vyper 和 Solidity,你可以清楚地感觉到 Vyper 是从 Python 中汲取了灵感,而 Solidity 是从 JavaScript 和 Java 中汲取灵感。因此,如果你对于这几种语言更熟悉的话,那就能很好地使用对应的智能合约语言。
Vyper 旨在成为一种简约、易于审计的编程语言,而 Solidity 旨在成为一种通用的智能合约语言。编码的体验在语法层面上也是如此,但每个人肯定都有自己的主观感受。
我不会过多地讨论工具,因为大多数这些语言都有非常相似的工具。主流框架,包括 Hardhat、ape、titanoboa、Brownie 和 Foundry,都支持 Vyper 和 Solidity。 Solidity 在这大多数框架中,都被优先支持,而 Vyper 需要使用插件才能与 Hardhat 等工具一起使用。然而,titanoboa 是专为与 Vyper 一起工作而构建的,除此以外,大多数工具对二者支持都很好。
哪一种智能合约语言更节省 gas?
现在是重头戏。在比较智能合约的 gas 性能时,需要牢记两点:
- 合约创建 gas 成本
- 运行时 gas 成本
你如何实现智能合约会对这些因素产生重大影响。例如,你可能在合约代码中存储大量数组,这使得部署成本高昂但运行函数的成本更低。或者,你可以让你的函数动态生成数组,从而使合约的部署成本更低,但运行函数成本更高。
那么,让我们看看这四个合约,并将它们的合约创建 gas 消耗与其运行时 gas 消耗进行比较。你可以在我的 sc-language-comparison repo 中找到所有的代码,包括用于比较它们所使用的框架和工具。
Gas 消耗比较 - 总结
以下是我们如何编译本节的智能合约:
vyper src/vyper/VSimpleStorage.vy
huffc src/huff/HSimpleStorage.huff -b
solc --strict-assembly --optimize --optimize-runs 20000
yul/YYSimpleStorage.yul --bin
solc --optimize --optimize-runs 20000 src/yulsol/YSimpleStorage.sol --bin
solc --optimize --optimize-runs 20000 src/solidity/SSimpleStorage.sol --bin
注意:我也可以为 Solidity 编译使用 –via-ir 标志。另请注意,Vyper 和 Solidity 在其合约末尾添加了“metadata”。这占总 gas 成本的一小部分增加,但不足以改变下面的排名。我将在 metadata 部分详细讨论这一点。
结果:

创建合约时各个语言所消耗的 gas 费
正如我们所见,像 Huff 和 Yul 这样的底层语言比 Vyper 和 Solidity 的 gas 效率更高,但这是为什么呢? Vyper 似乎比 Solidity 更高效,我们有这个新的“Sol and Yul”部分。那是因为你实际上可以在 Solidity 中编写 Yul。 Yul 是作为 Solidity 开发人员在写更接近机器代码时而创建的。
因此,在上图中,我们比较了原始 Yul、原始 Solidity 和 Solidity-Yul 组合。我们代码的 Solidity-Yul 版本如下所示:

Yul 和 Solidity 结合的合约
稍后你将看到一个示例,其中这个 inline-Yul 对 gas 消耗产生了重大影响。稍后我们将看看为什么存在这些 gas 差异,但现在让我们看看与 Foundry 中的单个测试相关的 gas 消耗。

我们的测试函数
这将测试将数字 77 存储在 storage 中,然后从 storage 中读取这个数字的 gas 成本。以下是运行此测试 的结果。

SimpleStorage 读和写的 gas 对比
我们没有 Yul 的数据,因为获取这个数据必须制作一个 Yul-Foundry 插件,我不想做 - 而且结果可能会与 Huff 相似。请记住,这是运行整个测试函数的 gas 成本,而不仅仅是单个函数。
Gas 消耗对比
好,我们来分析一下这个数据。我们需要回答的第一个问题是:为什么 Huff 和 Yul 合约的创建比 Vyper 和 Solidity 的 gas 效率高得多?我们可以通过直接查看这些合约的字节码来找到答案。
当你写智能合约时,它通常被分成两个或三个不同的部分。
- 合约创建代码
- 运行时代码
- Metadata (非必需)
对于这部分,了解 opcode 的基础知识很重要。 OpenZeppelin 关于解构合约的博客帮助你从零开始学习相关知识。
合约创建代码
合约创建代码是字节码的第一部分,告诉 EVM 将该合约写到到链上。你通常可以通过在生成的二进制文件中查找 CODECOPY opcode (39),然后找到它在链上的位置,并使用 RETURN opcode (f3) 返回并结束调用。
Huff:
602f8060093d393df3
Yul:
603e80600c6000396000f3fe
Vyper:
61006b61000f60003961006b6000f3
Solidity:
6080604052348015600f57600080fd5b5060ac8061001e6000396000f3fe
Solidity-Yul:
608060405234801561001057600080fd5b5060bc8061001f6000396000f3fe
你还会注意到很多 fe opcode,这是 INVALID 操作码。 Solidity 添加这些作为标记以显示运行时、合约创建和 metadata 代码之间的差异。
f3 是 RETURN 操作码,通常是函数或 context 的结尾。
你可能会认为,因为 Yul-Solidity 的合约创建字节码所占空间最大而 Huff 的字节码所占空间最小,所以 Huff 最便宜而 Yul-Solidity 最贵。但是当你复制整个代码库并将其发到到链上时,代码库的大小会产生很大的差异,这才是决定性因素。然而,这个合约创建代码确实让我们了解了编译器的工作原理,即他们将如何编译合约。
怎么读取 Opcode 和 Stack
目前,EVM 是一个基于堆栈的机器,这意味着你所做的大部分“事情”都是从堆栈中 push 和 pull 内容。你会在左边看到我们有 opcode,在右边我们有两个斜杠 (//) 表示它们是注释,以及在同一行执行 opcode 后堆栈的样子,左边是栈顶部,右边是栈底。
Huff opcode 的解释
Huff 合约的创建只做了它能做的最简单的事情。它获取你编写的代码,并将其返回到链上。
PUSH 0x2f // [2f]
DUP1 // [2f, 2f]
PUSH 0x09 // [09, 2f, 2f]
RETURNDATASIZE // [0, 09, 2f, 2f]
CODECOPY // [2f]
RETURNDATASIZE // [0, 2f]
RETURN // []
Yul opcode 的解释
Yul 做同样的事情,它使用了一些不同的 opcode,但本质上,它只是将你的合约代码放在链上,使用尽可能少的操作码和一个 INVALID opcode。
PUSH 0x3e // [3e]
DUP1 // [3e, 3e]
PUSH 0x0c // [0c, 3e, 3e]
PUSH 0x0 // [0, 0c, 3e, 3e]
CODECOPY // [3e]
PUSH 0x0 // [0, e3]
RETURN // []
INVALID // []
Vyper opcode 解释
Vyper 也基本做了同样的事情。
PUSH2 0x06B // [06B]
PUSH2 0x0F // [0F, 06B]
PUSH1 0x0 // [0, 0F, 06B]
CODECOPY // []
PUSH2 0x06B // [06B]
PUSH1 0x0 // [0, 06B]
RETURN // []
Solidity opcode 解释
现在让我们看看 Solidity 的 opcode。
// Free Memory Pointer
PUSH1 0x80 // [80]
PUSH1 0x40 // [40]
MSTORE // []
// Check msg.value
CALLVALUE // [msg.value]
DUP1 // [msg.value, msg.value]
ISZERO // [msg.value == 0, msg.value]
PUSH1 0xF // [F, msg.value == 0, msg.value]
JUMPI // [msg.value] Jump to JUMPDEST if value is not sent
// We only reach this part if msg.value has value
PUSH1 0x0 // [0, msg.value]
DUP1 // [0, 0, msg.value]
REVERT // [msg.value]
// Finally, put our code on-chain
JUMPDEST // [msg.value]
POP // []
PUSH1 0xAC // [AC]
DUP1 // [AC, AC]
PUSH2 0x1E // [1E, AC, AC]
PUSH1 0x0 // [0, 1E, AC, AC]
CODECOPY // [AC]
PUSH1 0x0 // [0, AC]
RETURN // []
INVALID // []
Solidity 做了更多的事情。 Solidity 做的第一件事是创建一个叫 Free Memory Pointer 的东西。为了在内存中创建动态数组,你需要记录内存的哪些部分是空闲可供使用的。我们不会在合约构造代码中使用这个 Free Memory Pointer,但这是它在背后需要做的第一件事。这是语言之间的第一个主要区别:内存管理。每种语言处理内存的方式不同。
接下来,Solidity 编译器查看你的代码,并注意到你的构造函数不是 payable。因此,为了确保你不会在创建合约时错误地发送了 ETH,它使用 CALLVALUE opcode 检查以确保你没有在创建合约时发送任何通证。这是语言之间的第二个主要区别:它们各自对常见问题有不同的检查和保护。
最后,Solidity 也做了其他语言所做的事情:它将你的合约发到在链上。
我们将跳过 Solidity-Yul,它的工作方式与 Solidity 自身类似。
检查和保护
从这个意义上说,Solidity 似乎“更安全”,因为它比其他语言有更多的保护。但是,如果你要向 Vyper 代码添加一个构造函数然后重新编译,你会注意到一些不同之处。

Vyper 语言的构造函数
编译它,你的合约创建代码看起来更像 Solidity 的。
// First, we check the callvalue, and jump to a JUMPDEST much later in the opcodes
CALLVALUE
PUSH2 0x080
JUMPI
// This part is identical to the original compilation
PUSH2 0x06B
PUSH2 0x014
PUSH1 0x0
CODECOPY
PUSH2 0x06B
PUSH1 0x0
RETURN
它仍然没有 Solidity 所具有的内存管理,但是你会看到它使用构造函数检查 callvalue。如果你使构造函数 payable 并重新编译,则该检查将消失。
因此,仅通过查看这些合约创建时的配置,我们就可以得出两个结论:
- 在 Huff and Yul 中,你需要自己显性地写检查操作。
- 而 Solidity 和 Vyper 将为你进行检查,Solidity 可能会做更多的检查和保护。
这将是语言之间最大的权衡之一:它们在幕后执行哪些检查?Huff 和 Yul 这两种语言不会在幕后做任何事情。所以你的代码会更省 gas,但你会更难避免和追踪错误。
运行时代码
现在我们对幕后发生的事情有了一定的了解,我们可以看看合约的不同函数是如何执行的,以及它们为何以这种方式执行。
让我们看看调用 storeNumber() 函数,在每种语言中,它的值都为 77。我通过使用像 forge test –debug “testStorageAndReadSol” 这样的命令使用 Forge Debug Feature 来获取 opcode。我还使用了 Huff VSCode Extension。
Huff opcode 解释
// First, we get the function selector of the call and jump to the code for our storeNumber function
PUSH 0x0 // [0]
CALLDATALOAD // [b6339418] The function selector for storing
PUSH 0xe // [e, b6339418]
SHR // [b6339418]
DUP1 // [b6339418, b6339418]
PUSH 0xb6339418 // [b6339418, b6339418, b6339418]
EQ // [true, b6339418]
PUSH 0x1c // [1c, true, b6339418]
JUMPI // [b6339418]
// We skip a bunch of opcodes since we jumped
// We place the 77 in storage, and end the call
JUMPDEST // [b6339418]
PUSH 0x4 // [4, b6339418]
CALLDATALOAD // [4d, b6339418] We load 77 from the calldata
PUSH 0x0 // [0, 4d, b6339418]
SSTORE // [b6339418] Place the 77 in storage
STOP // [b6339418] End call
有趣的是,如果我们没有 STOP 操作码,我们的 Huff 代码实际上会添加一组 opcode来返回我们刚刚存储的值,使其比 Vyper 代码更贵。不过这段代码看起来还是很直观的,那我们就来看看 Vyper 是怎么做的吧。我们暂时跳过 Yul,因为结果会非常相似。
Vyper opcode 解释
// First, we do a check on the calldata size to make sure we have at least 4 bytes for a function selector
PUSH 0x3 // [3]
CALLDATASIZE // [3, 24]
GT // [true]
PUSH 0x000c // [000c, true]
JUMPI // []
// Then, we jump to our location, and get the function selector
JUMPDEST
PUSH 0x0 // [0]
CALLDATALOAD // [b6339418]
PUSH 0xe // [e, b6339418]
SHR // [b6339418]
// And we do a check for sending value
CALLVALUE // [0, b6339418]
PUSH 0x0059 // [59, 0, b6339418]
JUMPI // [b6339418]
// Value looks good, so we compare selectors, and jump if the selector is something else
PUSH 0xb6339418 // [b6339418, b6339418]
DUP2 // [b6339418, b6339418, b6339418]
XOR // [0, b6339418]
PUSH 0x0032 // [32, 0, b6339418]
JUMPI // [b6339418]
// We do a check to make sure the calldata size is big enough for a function selector and a uint256
PUSH 0x24 // [24, b6339418]
CALLDATASIZE // [24, 24, b6339418]
XOR // [0, b6339418]
PUSH 0x0059 // [59, 0, b6339418]
JUMPI // [b6339418]
// Then, we store the variable and end the call
PUSH 0x04 // [4, b6339418]
CALLDATALOAD // [4d, b6339418]
PUSH 0x0 // [0, 4d, b6339418]
SSTORE // [b6339418]
STOP
可以看到在存储值的同时做了一些检查:
- 对于 function selector 来说,calldata 是否有足够的字节?
- 他们的 value 是通过 call 发送的吗?
- calldata 的大小和 function selector + uint256 的大小一样吗?
所有这些检查都增加了我们的计算量,但它们也意味着我们更有可能不犯错误。
Solidity opcode 解释
// Free Memory Pointer
PUSH 0x80 // [80]
PUSH 0x40 // [40,80]
MSTORE // []
// msg.value check, jump to function, revert otherwise
CALLVALUE // [0]
DUP1 // [0,0]
ISZERO // [true, 0]
PUSH 0x0f // [0f, true, 0]
JUMPI // [0]
// Skip reverting code
// We do a check to make sure the calldata size is big enough for a function selector and a uint256
JUMPDEST // [0]
POP // []
PUSH 0x04 // [4]
CALLDATASIZE // [24, 4]
LT // [false]
PUSH 0x32 // [32, false]
JUMPI // []
// Find the function selector and jump to it's code
PUSH 0x00 // [0]
CALLDATALOAD // [b6339418]
PUSH 0xe0 // [e0, b6339418]
SHR // [b6339418]
DUP1 // [b6339418, b6339418]
PUSH 0xb6339418 // [b6339418, b6339418, b6339418]
EQ // [true, b6339418]
PUSH 0x37 // [37, true, b6339418]
JUMPI // [b6339418]
// Setup the function by checking the calldata size, and setup the stack for the function
JUMPDEST
PUSH 0x47 // [47, b6339418]
PUSH 0x42 // [42, 47, b6339418]
CALLDATASIZE // [24, 42, 47, b6339418]
PUSH 0x04 // [4, 24, 42, 47, b6339418]
PUSH 0x5e // [5e, 4, 24, 42, 47, b6339418]
JUMP // [4, 24, 42, 47, b6339418]
JUMPDEST // [4, 24, 42, 47, b6339418]
PUSH 0x00 // [0, 4, 24, 42, 47, b6339418]
PUSH 0x20 // [20, 0, 4, 24, 42, 47, b6339418]
DUP3 // [4, 20, 0, 4, 24, 42, 47, b6339418]
DUP5 // [24, 4, 20, 0, 4, 24, 42, 47, b6339418]
SUB // [20, 20, 0, 4, 24, 42, 47, b6339418]
// See if the calldatasize minus the function selector size is smaller than 32 bytes
SLT // [false(0), 0, 4, 24, 42, 47, b6339418]
ISZERO // [true, 0, 4, 24, 42, 47, b6339418]
PUSH 0x6f // [6f, true, 0, 4, 24, 42, 47, b6339418]
JUMPI // [0, 4, 24, 42, 47, b6339418]
// Get the 77 value, and jump to the function selector code
JUMPDEST
POP // [24, 42, 47, b6339418]
CALLDATALOAD // [4d, 24, 42, 47, b6339418]
SWAP2 // [42, 24, 4d, 47, b6339418]
SWAP1 // [24, 42, 4d, 47, b6339418]
POP // [42, 4d, 47, b6339418]
JUMP // [4d, 47, b6339418]
JUMPDEST // [4d, 47, b6339418]
// Store our 77 value to storage and end the function call
PUSH 0x00 // [0, 4d, 47, b6339418]
SSTORE // [47, b6339418]
JUMP // [b6339418]
JUMPDEST // [b6339418]
STOP
这里有很多东西要解释。这与 Huff 代码之间的一些主要区别是什么?
- 我们设置了一个 free memory pointer。
- 我们检查了发送的 value。
- 我们检查了 function selector 的 calldata 大小。
- 我们检查了 uint256 的大小。
Solidity 和 Vyper 之间的主要区别是什么?
- Free memory pointer 的设置。
- Stack 在某些时候要深度要大很多。
这两者结合起来似乎是 Vyper 比 Solidity 便宜的原因。同样有趣的是,Solidity 使用 ISZERO opcode 进行检查,而 Vyper 使用 XOR opcode;两者似乎都需要大约相同的 gas。正是这些微小的设计差异造成所有的不同。
所以我们现在可以明白为什么 Huff 和 Yul 在 gas 上更便宜:它们只执行你告诉他们的操作,仅此而已,而 Vyper 和 Solidity 试图保护你不犯错误。
Free Memory Pointer
那么这个 free memory pointer 有什么用呢? Solidity 与 Vyper 之间的 gas 消耗似乎存在很大差异。free memory pointer 是一个控制内存管理的特性——任何时候你添加一些东西到你的内存数组,你的 free memory pointer 都只是指向它的末尾,就像这样:

这很有用,因为我们可能需要将动态数组等数据结构加载到内存中。对于动态数组,我们不知道它有多大,所以我们需要知道内存在哪里结束。
在 Vyper 中,因为没有动态的数据结构,你不得不说出像数组这样的对象到底有多大。知道这一点,Vyper 可以在编译时分配内存,并且没有 free memory pointer。

这意味着在内存管理方面,Vyper 可以比 Solidity 进行更多的 gas 优化。缺点是使用 Vyper 你需要明确说明你的数据结构的大小并且不能有动态内存。然而,Vyper 团队实际上将此视为一个优势。
动态数组
暂且不谈内存问题,使用 Vyper 确实必须声明数组的边界。在 Solidity 中,你可以声明一个没有大小的数组。在 Vyper 中,你可以有一个动态数组,但它必须是“有界的”。
这对开发人员体验很不好,但是,在 Web3 中,这也可以被视为针对拒绝服务(DOS)攻击的保护措施,并防止你的函数中产生大量 gas 成本。
如果你的数组变得太大,并且你对其进行遍历,则可能会消耗大量 gas。但是,如果你显性地声明数组的边界,你将知道最坏情况。
Solidity vs. Yul vs. SolYul
看看我上面的图表,使用 Solidity 和 Yul 似乎是最糟糕的选择,因为合约创建代码要贵得多。这可能适用于较小的项目,因为 Solidity 做了一些操作来让 Yul 运行,但大规模呢?
以 Solidity 版本和 SolYul 版本编写的最受欢迎的项目之一是 Seaport 项目。

Seaport 项目 Logo.
使用这些语言的最佳方面之一是你可以运行命令来直接从源代码测试每个合约的 gas 使用效率。我们添加了一个 PR 来帮助测试纯 Solidity 合约的 gas 消耗的命令,因为 Sol-Yul 合约已经进行了测试。结果非常惊人,你可以在 gas-report.txt 和 gas-report-reference.txt 中看到所有数据。

Seaport 中合约创建 gas 消耗的差别

Seaport 中函数调用 gas 消耗的差别
平均而言,函数调用在 SolYul 版本上的性能提高了 25%,而合约创建的性能提高了 40%。
这节省了大量的 gas。我想知道他们在纯粹的 Yul 中可以节省多少?我想知道他们在 Vyper vs. Sol-Yul 中会节省多少?
Metadata
最后,Metadata。 Vyper 和 Solidity 都在合约末尾附加了一些额外的“Metadata”。虽然数量很少,但我们在这里的比较中基本上会忽略它。你可以手动将其删除(并根据你的 Solidity 代码的长度调整标记),但 Solidity 团队也在建一个 PR,你可以在编译时将其删除。
总结
以下是我对这些语言的看法:
- 如果你正在编写智能合约,请使用 Vyper 或 Solidity。它们都是高级语言,有检查和保护,比如说检查调用数据大小以及你是否在不应该的情况下不小心发送了 ETH。它们都是很棒的语言,所以选择其中一个并慢慢学习。
- 如果你需要性能特别的高的代码,Yul 和 Huff 是很棒的工具。虽然我不建议大多数人用这些语言编程,但它们还是值得学习和理解,会让你更好地了解 EVM。
- Solidity 和 Vyper 之间 gas 成本的主要区别之一是 Solidity 中的 free memory pointer -一旦你达到高级水平并希望了解工具之间的潜在差异之一,请记住这一点。
Looking Forward
这些语言将继续发展,我们也可能会看到更多的语言出现,比如 Reach programming language 和 fe。
Solidity 和 Vyper 团队致力于开发 intermediate representation compilation step。 Solidity 团队有一个 –via-ir 的 flag,这将有助于优化 Solidity 代码,Vyper 团队也有他们的 venom 作为 intermediate representation。
无论你选择哪种语言,你都可以编写一些很棒的智能合约。祝编码愉快!
这篇文章中表达的观点仅代表作者,并不反映 Chainlink。
欢迎关注 Chainlink 预言机并且私信加入开发者社区,有大量关于智能合约的学习资料以及关于区块链的话题!