【推荐阅读】
代码大佬的【Linux内核开发笔记】分享,前人栽树后人乘凉!
一文了解Linux内核的Oops
一篇长文叙述Linux内核虚拟地址空间的基本概括
路由选择协议——RIP协议
深入理解Intel CPU体系结构【值得收藏!】
内存体系结构
1. UMA VS NUMA
有两种类型的计算机,分别以不同的方式管理物理内存:
1)UMA(uniform memory access)计算机,将内存以连续的方式组织起来。SMP系统中每个处理器都是访问同一块内存。
2)NUMA(non-uniform memory access)计算机,总是多处理器计算机,系统各个CPU有各自本地的内存访问,各个处理器之间的总线是连着的,可以访问其他CPU,但是要慢一些。
UMA总线逻辑更简单,但是访问速度要慢,带宽低;NUMA总线逻辑更复杂,但是访问更高效,带宽高,也更容易伸缩。UMA更适合分时系统,NUMA更适合实时系统,UMA并行能力特别差。下面我们讲解的主要是NUMA系统,因为弄懂了NUMA系统的内存管理,UMA就特别容易理解了。
2. 内核空间-内存组织
- 内存划分为节点(pg_data_t),每个节点关联到系统中的一个处理器
每个节点有划分成内存域(zone),目前内存域分为四种:(三个内核内存域,一个用户内存域)ZONE_DMA/ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM。通过划分内存域可以更好的管理,针对不同的场景进行更好的优化。
· ZONE_DMA标记适合DMA的内存域,在IA-32计算机上,一般的现在是16MB,该区域供I/O设备直接访问,不需要通过MMU管理,连续分配,具有更高的性能。
· ZONE_DMA32,标记了使用32位地址可寻址、适合DMA的内存域,显然只有64位系统上,才会有该内存域。
· ZONE_NORMAL,可以直接映射到内核段的普通内存域,这是所有体系机构上保证都会存在的唯一内存域,在IA-32系统上,该域可访问的最大内存不超过896MiB,超过该值的内存只能能通过高端内存寻址访问ZONE_HIGHMEM中的内存。
· ZONE_HIGHMEM,超出了内核段的物理内存。只有在可用物理内存多余可映射的内核内存时,才会访问该域,显然一般只有32位系统上才会有可能有该区域。通过kmap及kunmap将该域内存映射到内核虚拟地址空间。
· ZONE_MOVEABLE,这个区域主要是给用户空间分配使用。
前三个zone主要为内核所用到,最后一个主要被用户空间用到,内核空间内存域具体划分见下图:

内核空间内存域zone划分
由于内核核心不依赖于高端内存,所以一般优先分配高端内存,高端内存分配完毕后才会分配普通内存。
内存组织结构见下图:
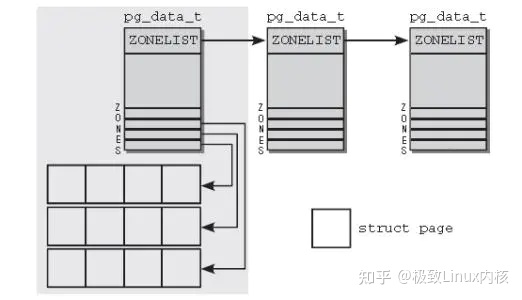
NUMA系统中的内存划分
数据结构如下:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; /*内存域*/
struct zonelist node_zonelists[MAX_ZONELISTS]; /* 备域(NUMA备用节点) */
int nr_zones; /* 内存域数目 */
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map; /* 所有内存域中的页 */
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext; /* 内存页的更多描述信息*/
#endif
#endif
unsigned long node_start_pfn; /* 节点起始页帧编号(系统中的所有节点的页帧编号唯一) */
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait; /* kswapd的等待队列*/
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_order;
enum zone_type kswapd_classzone_idx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
...
} pg_data_t;
struct zone {
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long _watermark[NR_WMARK]; /* min, low, high,不同内存水位代表内存有不同的压力,后续会详细介绍kswapd*/
unsigned long watermark_boost;
unsigned long nr_reserved_highatomic;
long lowmem_reserve[MAX_NR_ZONES]; /* 指定数量的内存页,用于无论如何都不能失败的关键性内存分配,不同的域有不同的计算方式*/
#ifdef CONFIG_NUMA
int node; /* 代表第n个节点*/
#endif
struct pglist_data *zone_pgdat; /* 所在的节点 */
struct per_cpu_pageset __percpu *pageset; /* 热/冷页帧列表,详情见下面的描述及slab分配器 */
#ifndef CONFIG_SPARSEMEM
... /* 高级新特性,后续研究完了再补一下*/
#endif
...
#ifdef CONFIG_MEMORY_ISOLATION
... /* 高级新特性,后续研究完了再补一下*/
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
... /* 高级新特性,后续研究完了再补一下*/
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_) /* CPU高速缓存行,缓存填充,确保自旋锁处于自身的缓存行中*/
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER]; /* 伙伴系统,负责实际页帧的分配 */
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
unsigned long percpu_drift_mark;
...
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp /*最优高速缓存行对齐*/;2.1 冷热页
冷热页主要是针对于CPU缓存的,热页就是已经加载入CPU缓存,相反冷页则说明页不在CPU高速缓存中,关于CPU高速缓存将在slab内存管理中统一描述。
struct per_cpu_pageset {
struct per_cpu_pages pcp;
...
};
struct per_cpu_pages {
int count; /* number of pages in the list */
int high; /* high watermark, emptying needed */
int batch; /* chunk size for buddy add/remove */
/* Lists of pages, one per migrate type stored on the pcp-lists */
struct list_head lists[MIGRATE_PCPTYPES];
};2.2 页帧
页帧代表系统物理内存映射的最小单位,对应于struct page,IA-32系统中标准页的长度为4KiB。页帧被伙伴系统管理着,所以当一个或多个page被分配出来时,由伙伴系统管理page对应的元信息,page中的数据可能是匿名映射首页、slab缓存首页、伙伴页或者页表页。
具体数据结构如下:
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct { /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* zone_lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
};
struct { /* slab, slob and slub */
union {
struct list_head slab_list; /* uses lru */
struct { /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union {
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
struct { /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
};
struct { /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
unsigned long _compound_pad_2;
struct list_head deferred_list;
};
struct { /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union {
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
};
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
};
struct { /* ZONE_DEVICE pages */
/** @pgmap: Points to the hosting device page map. */
struct dev_pagemap *pgmap;
unsigned long hmm_data;
unsigned long _zd_pad_1; /* uses mapping */
};
/** @rcu_head: You can use this to free a page by RCU. */
struct rcu_head rcu_head;
};
union { /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
unsigned int active; /* SLAB */
int units; /* SLOB */
};
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
#ifdef CONFIG_MEMCG
struct mem_cgroup *mem_cgroup;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
} _struct_page_alignment;2.3 页表
页表建立了虚拟地址到物理地址的映射关联。其通过radix tree来快速查找虚拟地址对应的物理地址,内核空间的映射基本是一致性映射。内核内存管理总是假定使用四级页表,但有些体系结构并不是采用四级页表,比如IA-32系统,只有2级页表,所以体系结构需要对于对于第三、第四级页表进行模拟处理。这里面比较复杂,先只考虑四级页表的情况。
内存地址分解

分解虚拟内存地址
地址空间包括5个部分,前四个部分用于选择页,最后一个部分用于选择页内位置,BITS_PER_LONG用于表示地址空间长度,PGD:全局目录项;PUD:上层目录项;PMD:中间页目录项;PTE:直接页表项。
3. 初始化内存管理
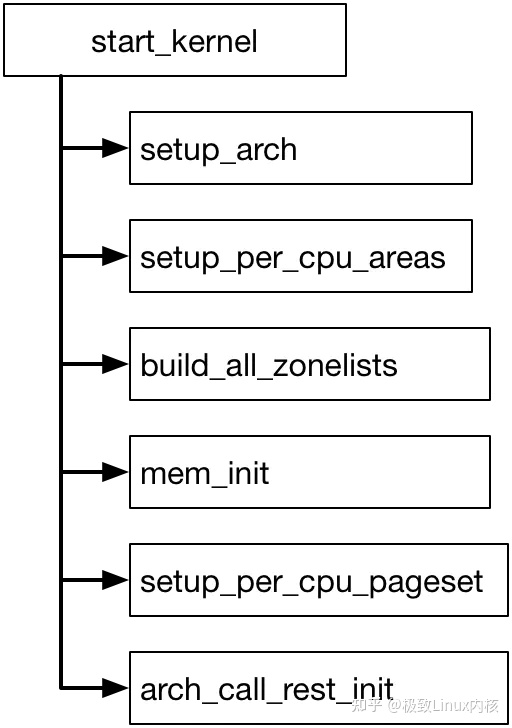
内核内存初始化
setup_arch:初始化自举分配器;
setup_per_cpu_areas:在SMP系统中为每个CPU分配一些PER_CPU的静态宏变量的副本;
build_all_zonelists:构建各个节点和内存域,在NUMA计算机中,还会建立节点的备用节点;
mem_init: 特定于体系结构,将内存分配器从bootmem迁移到真实的内存分配函数。
setup_per_cpu_pageset:初始化高速缓存及slab分配器。
这里需要特殊说明的就是build_all_zonelists中的备用节点的建立,在UMA中will do nothing,但是在NUMA会建立起相关zonelist结构
arch_call_rest_init:做一些扫尾工作,其中最重要的就是会初始化各个pages并分配到伙伴系统中,具体到在伙伴系统相关知识中详细介绍。
typedef struct pglist_data {
...
struct zonelist node_zonelists[MAX_ZONELISTS];
...
}
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
void __ref build_all_zonelists(pg_data_t *pgdat)
{
if (system_state == SYSTEM_BOOTING) {
build_all_zonelists_init(); /* __build_all_zonelists(NULL); */
} else {
__build_all_zonelists(pgdat);
/* cpuset refresh routine should be here */
}
...
}
static void __build_all_zonelists(void *data)
{
...
if (self && !node_online(self->node_id)) { / * non-booting*/
build_zonelists(self);
} else { / * when booting, init all nodes*/
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid); /* 根据node_id 查询pg_data_t*/
build_zonelists(pgdat);
}
...
}
...
}
static void build_zonelists(pg_data_t *pgdat)
{
static int node_order[MAX_NUMNODES]; /* 备用节点,按优先级排序,优先级的计算与节点的到当前节点的距离,节点的负载相关; 具体见find_next_best_node */
int node, load, nr_nodes = 0;
nodemask_t used_mask;
int local_node, prev_node;
/* NUMA-aware ordering of nodes */
local_node = pgdat->node_id;
load = nr_online_nodes; /* 可用的内存节点数 */
prev_node = local_node;
nodes_clear(used_mask);
memset(node_order, 0, sizeof(node_order));
while ((node = find_next_best_node(local_node, &used_mask)) >= 0) {
/*
* We don't want to pressure a particular node.
* So adding penalty to the first node in same
* distance group to make it round-robin.
*/
if (node_distance(local_node, node) !=
node_distance(local_node, prev_node))
node_load[node] = load;
node_order[nr_nodes++] = node;
prev_node = node;
load--;
}
build_zonelists_in_node_order(pgdat, node_order, nr_nodes);
build_thisnode_zonelists(pgdat);
}
static void build_zonelists_in_node_order(pg_data_t *pgdat, int *node_order,
unsigned nr_nodes)
{
struct zoneref *zonerefs;
int i;
zonerefs = pgdat->node_zonelists[ZONELIST_FALLBACK]._zonerefs;
for (i = 0; i < nr_nodes; i++) {
int nr_zones;
pg_data_t *node = NODE_DATA(node_order[i]);
nr_zones = build_zonerefs_node(node, zonerefs); // 分配了 nr_zones个zone,zonerefs需要向后移nr_zones
zonerefs += nr_zones;
}
zonerefs->zone = NULL;
zonerefs->zone_idx = 0;
}
static int build_zonerefs_node(pg_data_t *pgdat, struct zoneref *zonerefs)
{
struct zone *zone;
enum zone_type zone_type = MAX_NR_ZONES; // 内存域种类
int nr_zones = 0;
do {
zone_type--; // 内存域分配由廉价到昂贵
zone = pgdat->node_zones + zone_type;
if (managed_zone(zone)) { // 确保zone存在
zoneref_set_zone(zone, &zonerefs[nr_zones++]);
check_highest_zone(zone_type); // 检查并设置非moveable的最高的zone
}
} while (zone_type);
return nr_zones;
}假设一个有四个节点的NUMA计算机其最终备用域的分配可能类似于下图:

连续填充备用域示意图
linux内核起始段物理内存布局

linux内核进程起始段物理内存布局
该图给出了内核内存的前几兆字节,这些字节加载了内核进程的代码段,只读数据段,初始化数据段。第一个页帧主要供BIOS使用,后续的640Kib也基本不使用,用于映射各种ROM(系统BIOS和显卡ROM)。
在IA-32系统中一般是从0x100000开始加载内核代码。

内存初始化流程图
该图给出了系统加载内核内存管理模块的流程。
paging_init负责初始化内核页表并启用内存分页;
最终分配完后的内核内存布局如图:

内核内存地址空间
内核的普通内存(normalmem)大部分内存是直接直接映射的。前面说到内核地址只能通过直接映射使用前896MiB的数据,后续的128M被叫做高端内存(highmem),而高端内存有三种访问方式,vmalloc:可以在这个区域分配不连续的内存;持久映射:用于将高端内存中的非持久页映射到内核中;固定映射:与固定的内核物理地址关联,但具体关联的页帧可以自由选择。

虚拟地址和物理地址的管理
内核初始化完成后,物理内存管理的管理基本是由伙伴系统承担,伙伴系统以一种非常简单而高效的方式伴随了linux40多年,结合了优秀内存分配器的特点:速度与效率。而内核还为内核提供了非连续分配内存及管理缓存及小额内存分配的slab,slub及slob,这些将后续一一描述。