paper:OTA: Optimal Transport Assignment for Object Detection
code:https://github.com/Megvii-BaseDetection/OTA
背景
标签分配(Label Assignment)是目标检测中重要的一环,经典的标签分配策略采用预定义的规则为每个anchor匹配对应的gt或背景类。比如RetinaNet采用IoU作为划分正负样本的阈值标准,anchor-free检测器比如FCOS将ground truth物体的bbox内或bbox中心区域内的anchor point作为正样本。这种静态分配策略忽略了这样一个事实,即对于不同大小、形状、遮挡状态的对象,最适合的正负样本划分的边界可能是不同的。
基于此很多动态分配方法被提出,比如ATSS基于统计特征为每个gt设置划分边界,Freeanchor、Autoassign、PAA等方法提出anchor的预测分数可以作为一个合适的指标用来设计动态分配策略。
但是,不考虑上下文单独的为每个gt分配正负样本的方法可能不是最优的。对于模糊的anchor,即可能作为正样本分配给多个gt的anchor,现有的策略都是基于人工定义的准则,比如Min Area或Max IoU。作者指出把ambiguous anchor分配给任一个gt,对其他gt的学习都是不利的(introduce harmful gradients w.r.t. other gts),因此分配还需要更多的信息。一个更好的分配策略应该摆脱对每个gt单独追求最优分配的思想,转而全局最优的思想,找到一张图像中所有gt的综合最优分配策略。
本文的创新点
本文提出把标签分配当做最优传输问题,具体是把每个gt定义成一个supplier,它可以提供一定数量的label。把每个anchor定义成demander,它需要一个label。如果一个anchor从某个gt那得到了足够数量的positive label,这个anchor就被当做这个gt的一个正样本。每个gt可以提供的positive label的数量可以理解为这个gt在训练过程中需要多少个正样本来更好的收敛。每对anchor-gt的传输cost定义为它们之间的分类和回归loss的加权和。此外,背景类也被定义为supplier,它提供negative label,anchor-background之间的传输cost定义为它们之间的分类loss。这样标签分配问题就被转化为了最优传输问题,最终是为了找到全局最优的分配方法而不再是为每个gt单独寻找最优anchor。
具体方法
Optimal Transport
最优传输问题可以表述为:假设有 \(m\) 个supplier和 \(n\) 个demander,第 \(i\) 个supplier有 \(s_{i}\) 个物品,第 \(j\) 个demander需要 \(d_{j}\) 个物品,每个物品从第 \(i\) 个supplier运到第 \(j\) 个demander的运输运输成本为 \(c_{ij}\),最优传输的目标是找到一个最优传输方案 \(\pi^{*}=\left \{ \pi_{i,j}|i=1,2,...m,j=1,2,...n \right \} \) 能以最小的运输成本把所有的物品从supplier运输到demander。
OT for Label Assignment
对于目标检测问题,假设一张图片有 \(m\) 个gt和 \(n\) 个anchor(所有FPN level加起来),每个gt当做一个supplier,持有 \(k\) 个正标签 \((i.e.,s_{i}=k,i=1,2,...,m)\),每个anchor当做一个demander,需要一个标签 \((i.e.,d_{j}=1,j=1,2,...,n)\)。从 \(gt_{i}\) 传输一个正标签到anchor \(a_{j}\) 的运输成本 \(f^{fg}\) 定义为它们之间的分类损失和回归损失的加权和
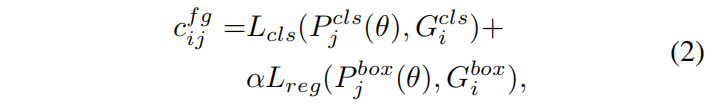
其中 \(\theta\) 是模型参数,\(P_{j}^{cls}\) 和 \(P_{j}^{reg}\) 分别表示anchor \(a_{j}\) 的预测的分类得分和bounding box。\(G_{i}^{cls}\) 和 \(G_{i}^{box}\) 分别表示 \(gt_{i}\) 的ground truth类别和bounding box。\(L_{cls}\) 和 \(L_{reg}\) 分别表示交叉熵loss和IoU loss,也可以分别替换成Focal loss和GIoU/Smooth L1 loss,\(\alpha\) 是权重系数。
此外,还有另一种提供负标签的supplier,背景类。在标准的最优传输问题中,supply的数量和demand的数量是相等的。因此背景类一共可以提供 \(n-m\times k\) 个负标签,从背景类传输一个负标签到 \(a_{j}\) 的成本为
![]()
其中 \(\oslash\) 表示背景类,把 \(c^{bg}\in \mathbb{R}^{1\times n}\) 拼接到 \(c^{fg}\in \mathbb{R}^{m\times n}\) 的最后一行即得到了完整的cost matrix \(c\in \mathbb{R}^{(m+1)\times n}\)。supply vector \(s\) 需要按下式更新
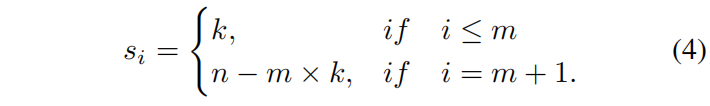
现在有了cost matrix \(c\),supply vector \(s\in \mathbb{R}^{m+1}\),demand vector \(d\in \mathbb{R}^{n}\),则最优传输路径 \(\pi^{*}\in \mathbb{R}^{(m+1)\times n}\) 可通过现有的Sinkhorn-Knopp Iteration算法求得。得到 \(\pi^{*}\) 后,对应的标签分配就是将每个anchor分配给传输给这个anchor最多标签的gt。
Advanced Designs
Center Prior
center prior即只从gt的中心有限区域挑选正样本,而不是整个bounding box范围内选择。强迫模型关注潜在positive areas即中心区域有助于稳定训练,特别是在训练的早期阶段,模型的最终性能也会更好。作者发现center prior对OTA的训练也有帮助,因此引入了center prior策略。
具体做法是,对于每个gt,只挑选每个FPN层中距离bounding box中心最近的 \(r^{2}\) 个anchor,对于bounding box内 \(r^{2}\) 之外的anchor,cost matrix中对应的cost会加上一个额外的常数项cost,这样就减少了训练阶段它们被分配为正样本的概率。
Dynamic \(k\) Estimation
每个gt需要的正样本数量应该是不同的并且基于很多因素,比如物体大小、尺度、遮挡情况等。由于很难将这些因素和所需anchor数量直接映射起来,本文提出了一种简单有效的方法,根据预测框和对应gt的IoU值来粗略估计每个gt合适的正样本数量。具体来说,对于每个gt,选择IoU最大的 \(q\) 个个预测,将这 \(q\) 个IoU值的和作为这个gt正样本数量的粗略估计值。这样做是基于直觉:某个gt的所需合适的postive anchor数量与和这个gt拟合的很好的anchor的数量正相关。
OTA的完整流程如下图所示
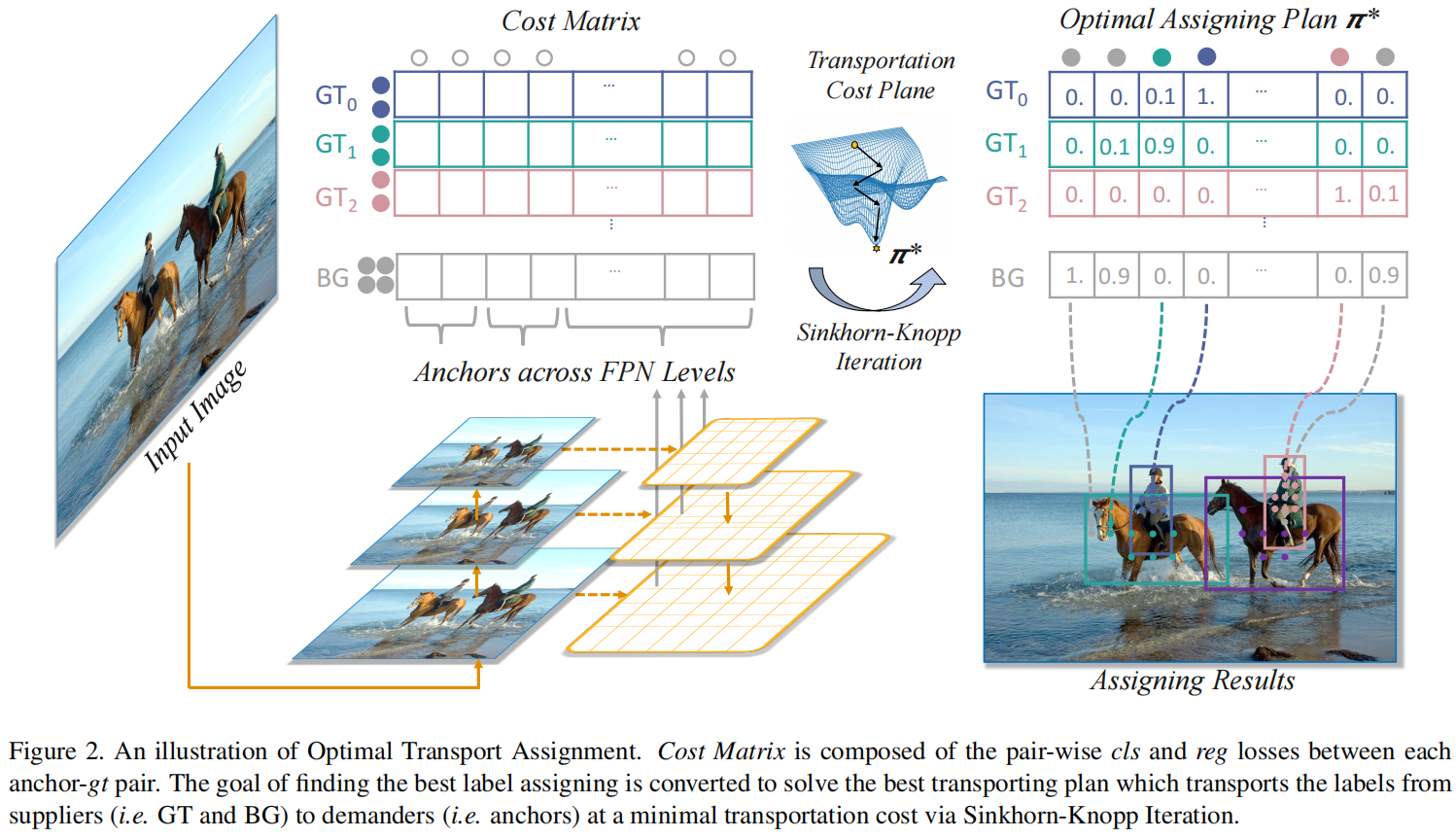
包含center prior和dynamic k estimation的完整流程伪代码如下所示

代码解读
这里batch_size=2,输入shape=(2, 3, 1085, 800),前景loss权重系数 \(\alpha=1.5\),center prior超参 \(r=2.5\),dynamic \(k\) estmation中 \(q=20\)。
其中line96计算前景loss和中的 1e6*(1-is_in_boxes.float()) 就是中心区域外的anchor额外加的常数项cost,line105将背景的cost拼接到前景cost矩阵最后就得到了最终的cost matrix,这里的loss就是cost matrix。mu和nu分别是上面的supply vector \(s\) 和 demand vector \(d\)。
核心代码如下,加了一些注释,其中sinkhorn算法没有专门了解原理,这里就直接用吧。
def get_ground_truth(self, shifts, targets, box_cls, box_delta, box_iou):
# shifts
# [[(13600,2),(3400,2),(850,2),(221,2),(63,2)],
# [(13600,2),(3400,2),(850,2),(221,2),(63,2)]]
# targets
# [Instances(num_instances=2, image_height=1085, image_width=800,
# fields=[gt_boxes = Boxes(tensor([[216.9492, 217.0000, 605.6497, 965.1979], [246.3277, 160.4896, 501.6949, 641.9583]], device='cuda:0')),
# gt_classes = tensor([12, 14], device='cuda:0'), ]),
# Instances(num_instances=2, image_height=1085, image_width=800,
# fields=[gt_boxes = Boxes(tensor([[216.9492, 217.0000, 605.6497, 965.1979], [246.3277, 160.4896, 501.6949, 641.9583]], device='cuda:0')),
# gt_classes = tensor([12, 14], device='cuda:0'), ])]
gt_classes = []
gt_shifts_deltas = []
gt_ious = []
assigned_units = []
box_cls = [permute_to_N_HWA_K(x, self.num_classes) for x in box_cls]
# [(2,13600,20),(2,3400,20),(2,850,20),(2,221,20),(2,63,20)]
box_delta = [permute_to_N_HWA_K(x, 4) for x in box_delta]
# [(2,13600,4),(2,3400,4),(2,850,4),(2,221,4),(2,63,4)]
box_iou = [permute_to_N_HWA_K(x, 1) for x in box_iou]
# [(2,13600,1),(2,3400,1),(2,850,1),(2,221,1),(2,63,1)]
box_cls = torch.cat(box_cls, dim=1) # (2,18134,20)
box_delta = torch.cat(box_delta, dim=1) # (2,18134,4)
box_iou = torch.cat(box_iou, dim=1) # (2,18134,1)
for shifts_per_image, targets_per_image, box_cls_per_image, \
box_delta_per_image, box_iou_per_image in zip(
shifts, targets, box_cls, box_delta, box_iou):
shifts_over_all = torch.cat(shifts_per_image, dim=0) # (18134,2)
gt_boxes = targets_per_image.gt_boxes # (2,4)
# In gt box and center.
deltas = self.shift2box_transform.get_deltas(
shifts_over_all, gt_boxes.tensor.unsqueeze(1)) # (18134,2),(2,1,4) -> (2,18134,4)
is_in_boxes = deltas.min(dim=-1).values > 0.01 # (2,18134)
center_sampling_radius = 2.5
centers = gt_boxes.get_centers() # (2,2),
# tensor([[388.7006, 591.0990],
# [425.9887, 401.2239]], device='cuda:0')
# 因为数据增强的, gt_bboxes和centers每次运行结果都会变化
is_in_centers = []
for stride, shifts_i in zip(self.fpn_strides, shifts_per_image): # [8, 16, 32, 64, 128], _
radius = stride * center_sampling_radius
center_boxes = torch.cat((
torch.max(centers - radius, gt_boxes.tensor[:, :2]),
torch.min(centers + radius, gt_boxes.tensor[:, 2:]),
), dim=-1) # (2,4)
center_deltas = self.shift2box_transform.get_deltas(
shifts_i, center_boxes.unsqueeze(1)) # (13600,2),(2,1,4) -> (2,13600,4)
is_in_centers.append(center_deltas.min(dim=-1).values > 0)
is_in_centers = torch.cat(is_in_centers, dim=1) # (2,18134)
del centers, center_boxes, deltas, center_deltas
is_in_boxes = (is_in_boxes & is_in_centers)
num_gt = len(targets_per_image)
num_anchor = len(shifts_over_all)
shape = (num_gt, num_anchor, -1) # (2,18134,-1)
gt_cls_per_image = F.one_hot(
targets_per_image.gt_classes, self.num_classes
).float() # (2,20)
with torch.no_grad():
loss_cls = sigmoid_focal_loss_jit(
box_cls_per_image.unsqueeze(0).expand(shape), # (18134,20)->(1,18134,20)->(2,18134,20)
gt_cls_per_image.unsqueeze(1).expand(shape), # (2,20)->(2,1,20)->(2,18134,20)
alpha=self.focal_loss_alpha, # 0.25
gamma=self.focal_loss_gamma, # 2
).sum(dim=-1) # (2,18134,20)->(2,18134)
loss_cls_bg = sigmoid_focal_loss_jit(
box_cls_per_image, # (18134,20)
torch.zeros_like(box_cls_per_image),
alpha=self.focal_loss_alpha,
gamma=self.focal_loss_gamma,
).sum(dim=-1) # (18134,20)->(18134)
gt_delta_per_image = self.shift2box_transform.get_deltas(
shifts_over_all, gt_boxes.tensor.unsqueeze(1) # (18134,2), (2,4)->(2,1,4)
) # (2,18134,4)
ious, loss_delta = get_ious_and_iou_loss(
box_delta_per_image.unsqueeze(0).expand(shape), # (18134,4)->(1,18134,4)->(2,18134,4)
gt_delta_per_image,
box_mode="ltrb",
loss_type='iou'
) # (2,18134),(2,18134)
loss = loss_cls + self.reg_weight * loss_delta + 1e6 * (1 - is_in_boxes.float()) # 1.5
# (2,18134)
# Performing Dynamic k Estimation
topk_ious, _ = torch.topk(ious * is_in_boxes.float(), self.top_candidates, dim=1) # (2,18134),20 -> (2,20)
mu = ious.new_ones(num_gt + 1) # torch.Size([3]), tensor([1., 1., 1.], device='cuda:0')
mu[:-1] = torch.clamp(topk_ious.sum(1).int(), min=1).float() # s_{i}(i=1,...,m)
mu[-1] = num_anchor - mu[:-1].sum() # s_{m+1}
nu = ious.new_ones(num_anchor) # (18134), d_{j}(j=1,..,n)
loss = torch.cat([loss, loss_cls_bg.unsqueeze(0)], dim=0) # (2,18134),(18134)->(1,18134), -> (3,18134)
# Solving Optimal-Transportation-Plan pi via Sinkhorn-Iteration.
_, pi = self.sinkhorn(mu, nu, loss) # (3,),(18134,),(3,18134) -> (3,18134)
# Rescale pi so that the max pi for each gt equals to 1.
rescale_factor, _ = pi.max(dim=1) # (3,)
pi = pi / rescale_factor.unsqueeze(1) # (3,18134)
max_assigned_units, matched_gt_inds = torch.max(pi, dim=0)
gt_classes_i = targets_per_image.gt_classes.new_ones(num_anchor) * self.num_classes
fg_mask = matched_gt_inds != num_gt
gt_classes_i[fg_mask] = targets_per_image.gt_classes[matched_gt_inds[fg_mask]]
gt_classes.append(gt_classes_i)
assigned_units.append(max_assigned_units)
box_target_per_image = gt_delta_per_image.new_zeros((num_anchor, 4))
box_target_per_image[fg_mask] = \
gt_delta_per_image[matched_gt_inds[fg_mask], torch.arange(num_anchor)[fg_mask]]
gt_shifts_deltas.append(box_target_per_image)
gt_ious_per_image = ious.new_zeros((num_anchor, 1))
gt_ious_per_image[fg_mask] = ious[matched_gt_inds[fg_mask],
torch.arange(num_anchor)[fg_mask]].unsqueeze(1)
gt_ious.append(gt_ious_per_image)
return torch.cat(gt_classes), torch.cat(gt_shifts_deltas), torch.cat(gt_ious)Experiments
Alation Studies and Analysis
Effects of Individual Components
OTA可以既可以用于anchor-based detector也可以用于anchor-free detector,本文采用FCOS,同时额外加入了IoU分支,从下图可以看出随着添加IoU branch、center prior、dynamic k estimation,性能持续提升,并且比对应的原始FCOS的精度要高。

Effects of \(r\)
center prior的半径 \(r\) 控制每个gt的正样本数量,\(r\) 值小,只有最靠近gt中心的高质量anchor才被当做正样本,有助于模型的学习。\(r\) 越大,引入的低质量的正样本anchor越多,导致了优化过程中潜在的不稳定。从下表可以看出,随着 \(r\) 的增大,三种模型的精度都出现了不同程度的下降,但OTA下降的最少,表明OTA对 \(r\) 值的变化不那么敏感,同时不同的 \(r\) 值下,OTA的精度也是最高的。
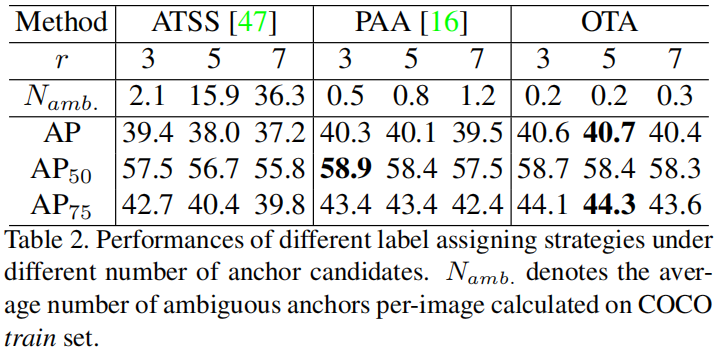
Ambiguous Anchors Handling
当发生遮挡或者多个对象靠的非常近时,一个anchor可能是多个ground truth的合格候选对象(比如Faster RCNN中一个anchor与多个gt的IoU都大于0.5),这种anchor定义为ambiguous anchor。之前的方法主要通过人工设定的规则来处理这种情况,比如Min Area、Max IoU、Min Loss等。本文将 \(max\ \pi^{*}_{j}<0.9\) 的anchor \(a_{j}\) 定义为ambiguous anchor,然后统计在不同的 \(r\) 值下ATSS、PAA、OTA的ambiguous anchor的数量以及对应的精度。从上表(2)中可以看出,随着 \(r\) 的增大,ATSS中ambiguous anchor的数量显著增加,AP也降了1.8个点。PAA中ambiguous anchor的数量对 \(r\) 的变化不那么敏感,但AP也降了0.8个点。而OTA中ambiguous anchor的数量既对 \(r\) 的变化不敏感,和ATSS、PAA相比数量也是最少的,同时AP也只下降了0.3个点。这是因为当多个gt试图将positive label传输到同一个anchor时,OT算法会基于全局最小传输成本的准则自动解决它们之间的冲突。
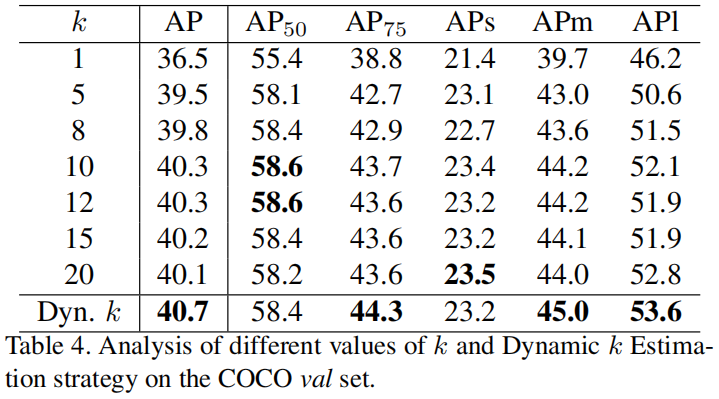
Effects of \(k\)
如下表所示,作者对比了 \(k\) 设置为不同的常数值以及采用dynamic \(k\) 时模型的精度,可以看出随着 \(k\) 的增大,模型精度越来越高,当 \(k\) 取10或12时,模型达到最高的精度,随后开始下降。但最高的精度也比采用dynamic \(k\) 的精度低。从直觉上讲,每个gt的大小、尺度、遮挡情况都不同,因此每个gt所需的postive anchor的数量应该也是不同的。
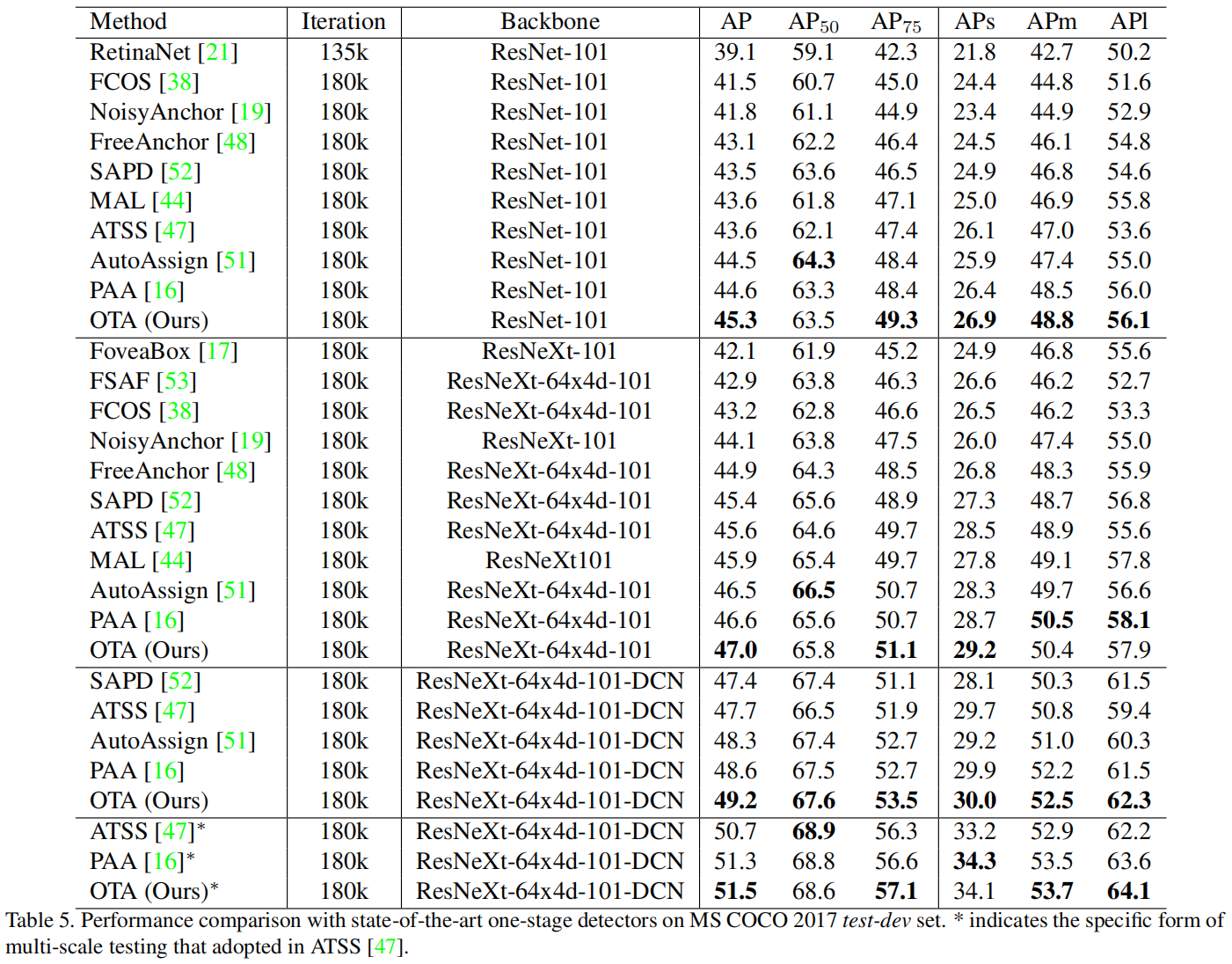
Comparison with State-of-the-art Methods
从下表可以看出,采用ResNet-101-FPN结构,OTA的AP达到了45.3%,超过了其它所有相同backbone的方法,如ATSS(43.6% AP)、AutoAssign(44.5% AP)、PAA(44.6% AP)。






![[Java] 浅析rpc的原理及所用到的基本底层技术](https://img-blog.csdnimg.cn/9d3ffb7a1aa643cdb58ae2f89f4be0f1.png)