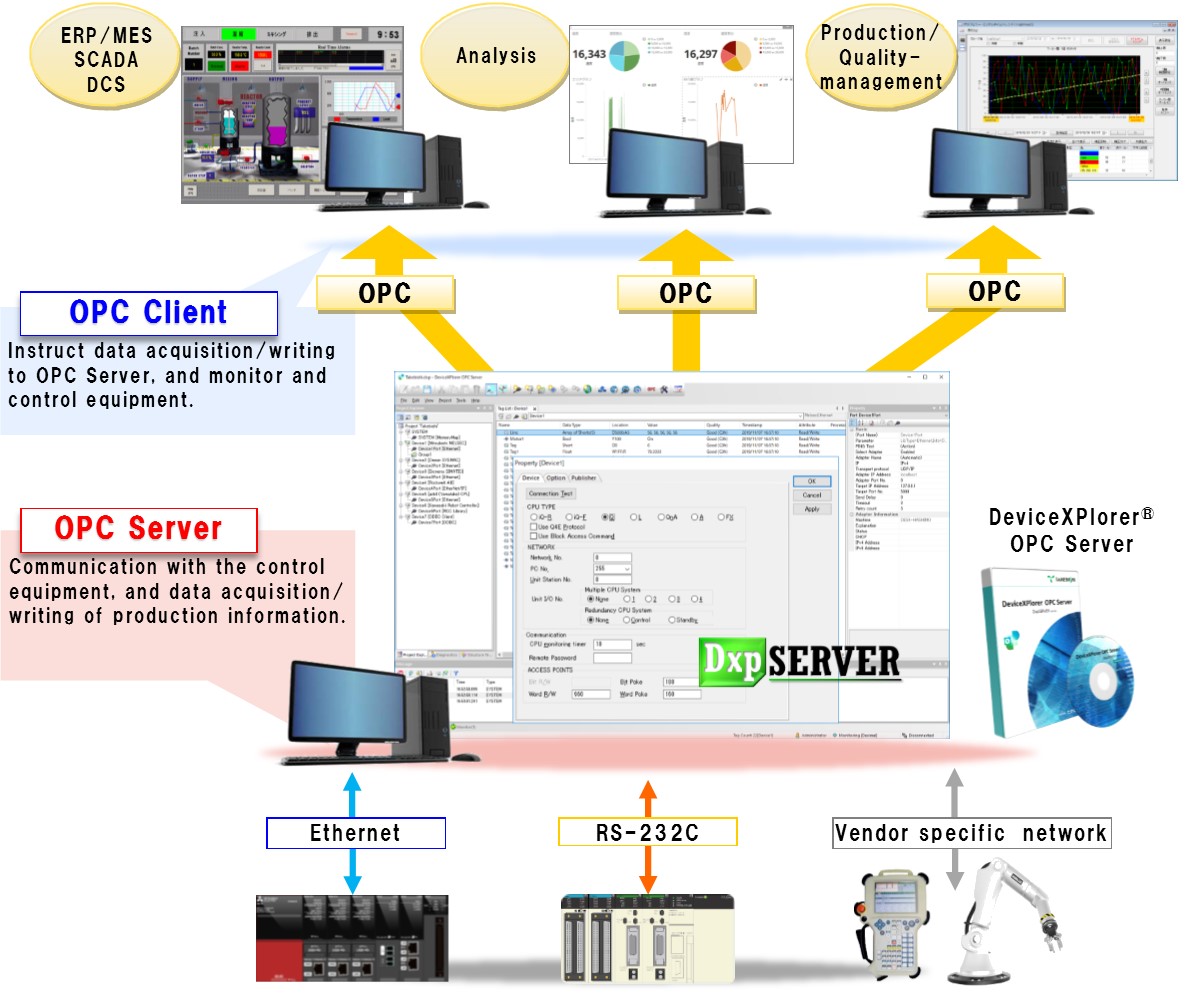
论文地址
Motivation:
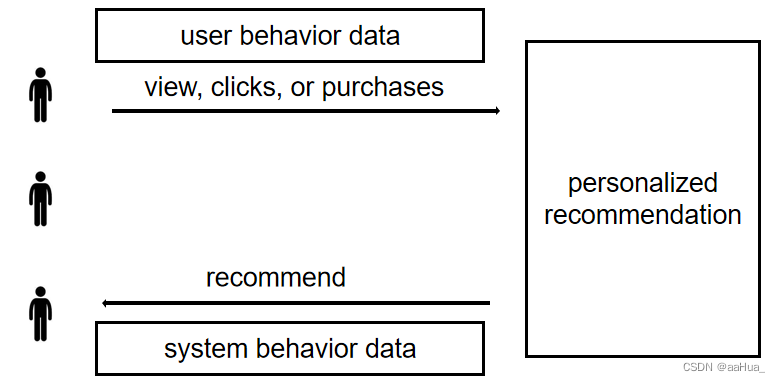
现阶段对于用户行为的保护仅仅从用户端来考虑,比如用户的行为数据等。然而推荐系统是一个闭环的过程,即用户交互了物品,推荐系统根据用户的交互信息去推荐物品,用户也会根据推荐系统推荐的物品做消费。如果仅从用户的行为数据考虑保护是不够的,系统的行为数据也会泄露用户的一些行为信息。
所以本文从系统的行为数据出发(系统推荐\暴露的数据)考虑对用户的行为信息进行保护。
Contribute:
1.指出了一个新的隐私泄露风险,推荐系统暴露的信息可以推理出用户的历史行为信息。
2.提出一个攻击推理模型去执行用户隐私信息推理。
3.提出一个保护机制去缓解隐私泄露的风险。
Method:
1.攻击推理模型:
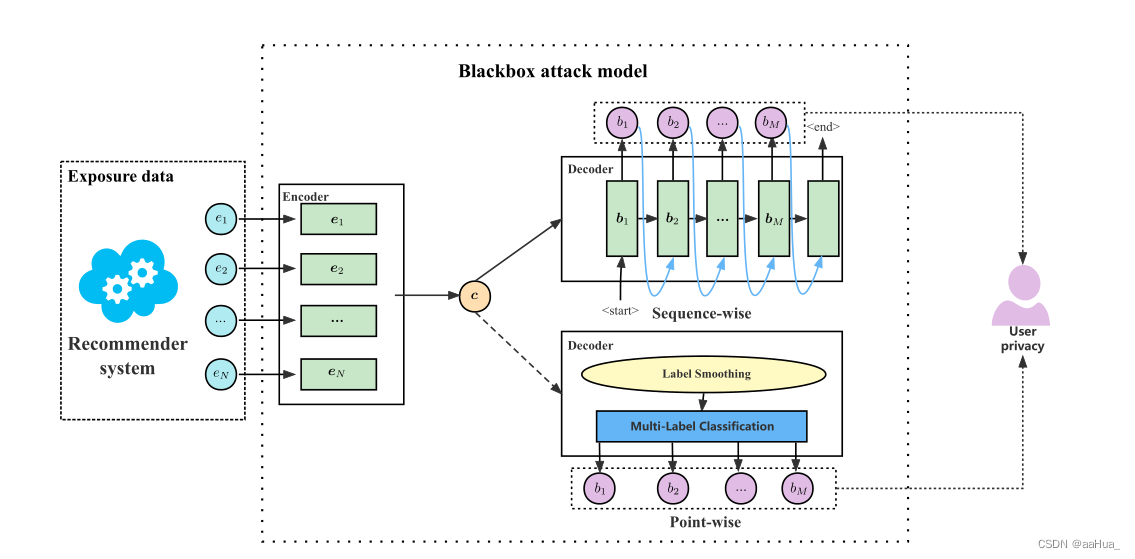
采用简单的encoder-decoder模型,encoder的功能是将推荐系统暴露的数据生成一个向量c,decoder的功能是将向量c通过两种不同的技术去推理用户的历史行为数据。
encoder:1.mean pooling 2.max pooling 3. self-attention mechanism
decoder:1.Point-wise :相当于一个多标签分类器 2.Sequence-wise:传统处理序列的技术(GRU、LSTM、Transformer)
2. 隐私保护模型:(two-stage)
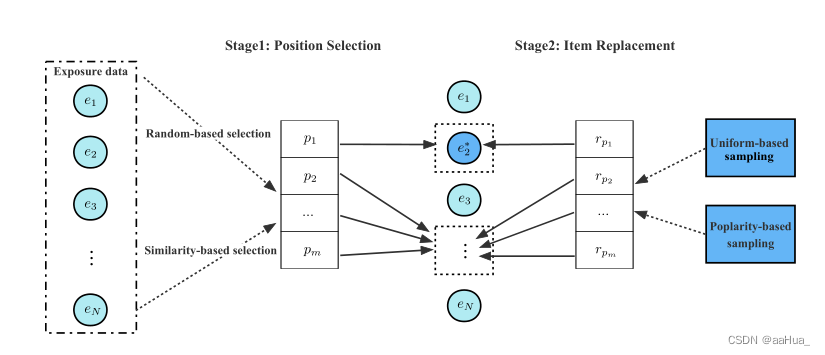
two-stage:第一阶段是位置的挑选,从推荐系统暴露的数据中挑选百分比的物品选出准备要替换的物品。第二阶段是物品的替换,从其他物品中挑选出一些物品替换掉第一阶段挑选出来的物品。
Position Selection:1. Random selection 2.Similarity selection: 使用用户历史行为数据预训练用户交互的物品embedding,每个用户的历史行为bu可以表示为该用户u交互过的所有物品embedding做mean pooling,然后bu与系统暴露的数据做softmax cosine similarity,选的位置就是相似度低的系统暴露数据。
Item Replacement:1.Uniform sampling :在整个物品集合里随机挑选物品作为替换物品。 2.Popularity sampling : 根据热门物品替换(热门计算方式我没注意,我的理解是物品在所有用户交互中出现的次数),又分为整体热门和批量(in-batch)热门,挺好理解吧…
Dataset:
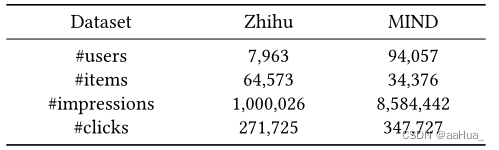
impressions表示系统暴露的数据量,给定一个时间戳t和用户u,t之前用户点击过M个物品作为用户行为数据,N个系统暴露数据也截止到时间戳t。 其中文章设定N=10,M=5。
Experiments:
实验跟随着回答一下三个问题。

RQ1:
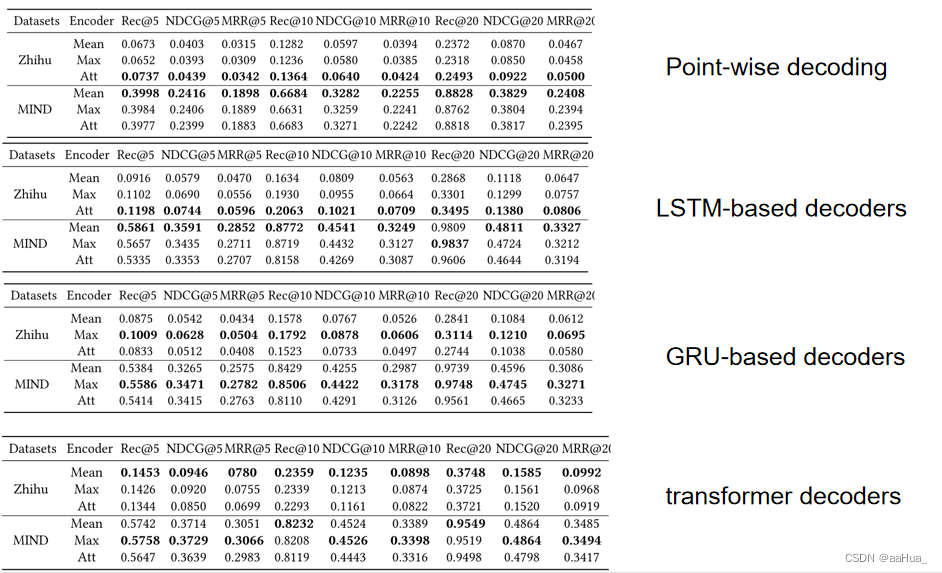
1.在不同数据集中,简单的编码方式也可以取得好的攻击效果。它进一步证明了隐私泄露的风险,因为攻击可以在没有琐碎和复杂的编码方法的情况下执行。
2.考虑序列的顺序可以获得更好的攻击效果。
3.知乎数据集每个回答可能隐含问题,攻击者无法建模的很好,导致在知乎数据集效果不如mind数据集。mind数据集在lstm解码器中recall20接近了98.09%。
RQ2:
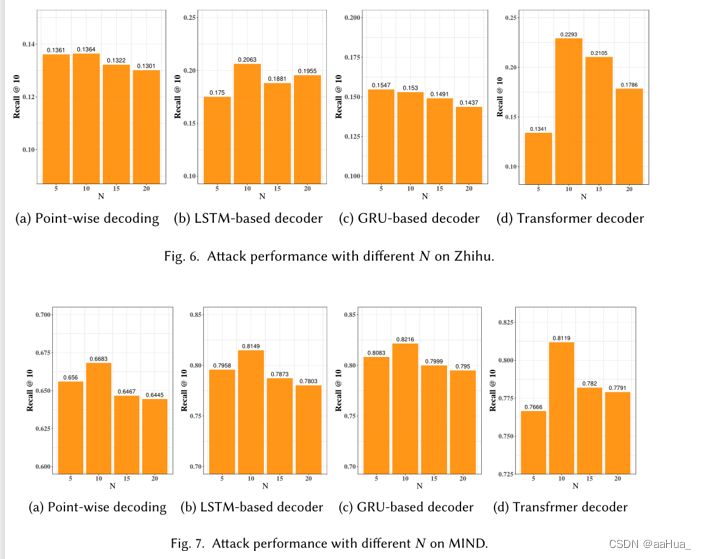
1在知乎数据集当使用point-wise解码时,不同的暴露物品数量有相似的攻击性能。然而,当使用序列式解码时,攻击性能要好得多,并且随着不同的数量而变化得更多。原因可能是知乎的推荐场景是答案推荐。每个答案都属于一个潜在的问题。point-wise解码没有对用户行为的顺序进行建模,无法捕捉答案中潜在问题的变化,导致攻击性能比较差。
然而,顺序解码基于先前的推理结果进行推理;这种方法能够从先前的推理结果中学习潜在的潜在问题的变化。因此,通过适当设置暴露物品数量,基于序列解码实现了高得多的攻击性能。
2.暴露物品N=10效果最好。暴露项目较少,攻击模型可能不会学习到推断用户行为隐私的强信号。过多的暴露项目也可能引入额外的噪声,这进一步混淆了模型并降低了攻击性能。
RQ3:
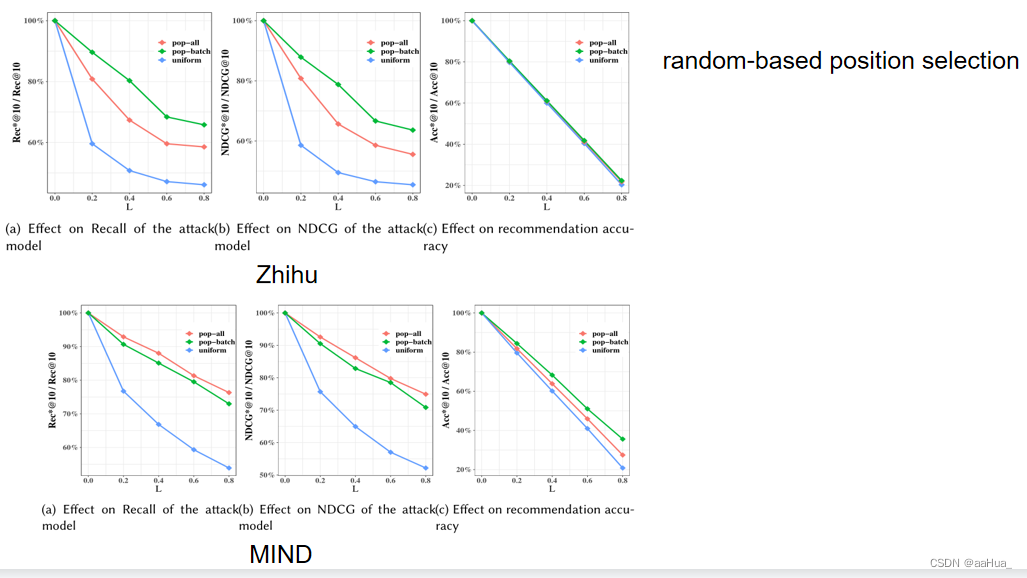
1.随着替换率L的增加,攻击性能显著减小。说明暴露物品准确推理出用户的行为越来越差。
2.基于随机的位置挑选可以保证好的隐私,但是不能保证好的推荐效果。所以需要在性能和隐私之间进行权衡。
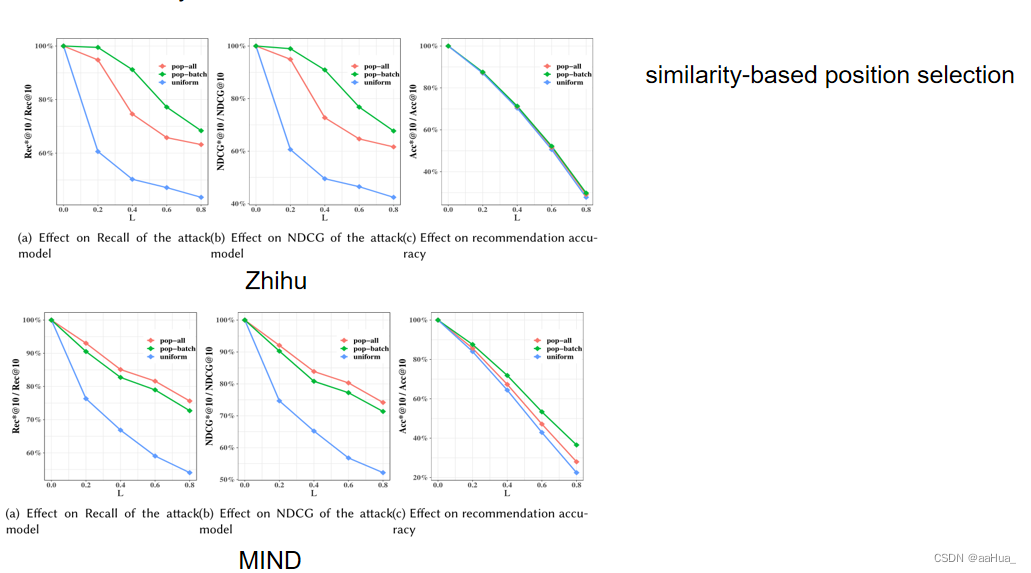
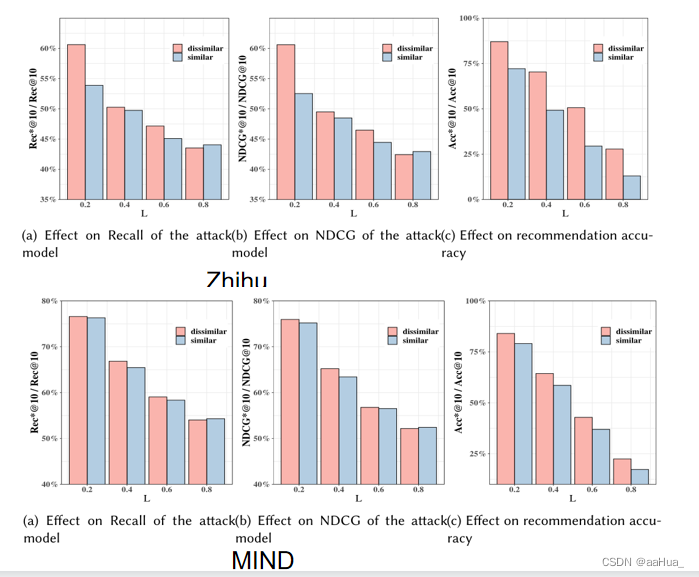
1.在保护机制的第一阶段,就是选取位置的阶段,基于相似度的选取位置是选取分数低的暴露物品,也就是选取不相似的暴露物品进行替换。
但是与用户行为相关的是那些暴露的相似物品,所以更有可能推理出用户的行为信息。因此又做了对比试验,选取了相似度高的物品替换,可以进一步提升隐私保护能力,但是推荐性能下降。
![[Java] 浅析rpc的原理及所用到的基本底层技术](https://img-blog.csdnimg.cn/9d3ffb7a1aa643cdb58ae2f89f4be0f1.png)