文章目录
- 前言
- 正文
- 线程池提供的两个重要方法
- Any类的设计
- Semaphore
- Result的实现
- Cache模式解释
- 会遇到死锁问题
- 第二个死锁问题,移植到Linux发生
- 项目重构
- 大致流程
- 总结
前言
开发环境:
- Linux,要求g++版本能够支持C++17以上;
- vs2019下开发,需要将C++标准调制C++17以上。
涉及知识点:
- 熟悉C++11多线程编程 thread、mutex、atomic、condition_variable、unique_lock等。
- C++17和C++20标准的内容,C++17的any类型和C++20的信号量semaphore,项目上都我们自己用代码实现
- 熟悉多线程理论:多线程基本知识、线程互斥、线程同步、原子操作、CAS等。
正文
项目链接,可以下载项目下来,边看边学效果更加!
码云,点击直达~
ThreadPool 线程池类型
线程池支持的类型:
- MODE_FIXED标识固定线程的数量,线程不会中途扩容,适合长任务。
- MODE_CACHED模式可以实现线程数量中途增加减少,适合小型任务,但任务海量到来的时候会进行适当的增加线程数,会有上限阈值。
如果是一开始设计,实际上线程池只需要
std::vector<std::shared_ptr<Thread>> threads_; // 线程列表,避免手动释放线程列表来实现,后面改成了std::unordered_map<int, std::unique_ptr<Thread>> threads_;// 线程列表是因为我们需要给每一个线程一个自定义的id,因为ThreadPool需要动态删除线程的时候,需要找到对应的线程,此时如果遍历数组的效率低,我们后面改成哈希表。
总结:
如果是MODE_FIXED模式,这里用vector存储线程是可以的。
但是如果是MODE_CACHED,则需要使用哈希表。
// 线程支持的模式
enum class PoolMode
{
MODE_FIXED,// 固定数量的线程 -- 不需要考虑线程安全问题
MODE_CACHED, // 线程数量可动态增长 -- 需要考虑线程安全问题
};
注意:
std::queue<std::shared_ptr<Task>> taskQue_;如果存储任务,我们需要使用到多态,所以我们这里要用基类的指针,但是如果使用std::queue<Task*> 是有问题的,因为用户若创建一个临时的任务对象,用户调用submitTask回来后,我们queue记录到任务,但是任务已经被销毁了。 但是如果用shared_ptr<Task>后,其实这个任务的生命周期已经是threadFunc线程的函数里面执行完,就会将任务进行析构。- 任务的个数也是需要记录的,因为后续threadFunc不执行了,线程退出的时候,需要保证taskSize_ 已经没有任务了,我们才能够释放锁。因为使用到锁的时候都已经释放了。
其他线程的字段:
std::unordered_map<int, std::unique_ptr> threads_; 不需要shared_ptr,因为线程不会发生拷贝,所以用unique_ptr就可以了。
// std::vector<std::shared_ptr<Thread>> threads_; // 线程列表,避免手动释放线程列表
std::unordered_map<int, std::unique_ptr<Thread>> threads_;// 线程列表
int initThreadSize_; // 初始的线程数量
std::atomic_int curThreadSize_;// 记录当前线程池里面的线程总数量
int threadSizeThreshHold_; // 线程数量的上限阈值
// std::atomic_int idleThreadSize_;// 记录空闲线程的数量
int idleThreadSize_;// 记录空闲线程的数量
std::queue<std::shared_ptr<Task>> taskQue_;// 这里不用基类的裸指针,并且这里保证要基类,因为我们要用到多态
std::atomic_int taskSize_; // 任务的数量
int taskQueMaxThreshHold_; // 任务最大的上限,超过上线会阻塞生产者,直到队列有新的线程执行任务
std::mutex taskQueMtx_; // 保证任务队列的原子性
std::condition_variable notFull_; // 表示任务队列不满
std::condition_variable nonEmpty_; // 表示任务队列不空
std::condition_variable exitCond_; // 等待线程资源全部回收
PoolMode poolMode_; // 线程模式
std::atomic_bool isPoolRunning_;// 线程是否在运行
线程池提供的两个重要方法
线程池需要提供的方法:
其实线程池就重要的就是submitTask和threadFunc函数,一个是放任务,一个是取任务。其他的都是设置一下相关的成员变量,方便使用。
由于这两个函数关系紧密,我们放到一起讲,就不分开了。
public:
// 线程池构造
ThreadPool();
// 线程池析构
~ThreadPool();
// 设置线程池的工作模式
void setMode(PoolMode mode);
// 设置线程池cached模式下线程阈值
void setThreadSizeThreshHold(int threshhold);
// 设置task任务队列上线阈值
void setTaskQueMaxThreshHold(int threshhold);
// 给线程池提交任务
Result submitTask(std::shared_ptr<Task> sp);
// 开启线程池,指定线程里面的数量的多少,初始化这里给一次就可以了
void start(int initThreadSize = 4);
// 不希望线程池对象进行拷贝构造和赋值
ThreadPool(const ThreadPool&) = delete;
ThreadPool& operator=(const ThreadPool&) = delete;
private:
// 定义线程函数
void threadFunc(int threadid);
bool checkRunningState() const;
线程池初始化批量线程,将线程绑定了线程函数,后续Thread::start就可以直接用到线程池当中的私有成员变量(如任务队列等等)。
所以线程函数我们是放在线程池当中,而不是放到线程当中。
// 开启线程池
void ThreadPool::start(int initThreadSize)
{
// 设置线程池的运行状态
isPoolRunning_ = true;
// 记录初始线程的个数
initThreadSize_ = initThreadSize;
curThreadSize_ = initThreadSize;
// 创建线程对象
for (int i = 0; i < initThreadSize_ ;++ i)
{
// 这里把线程函数传递给线程
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this,std::placeholders::_1));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
/*threads_.emplace_back(std::move(ptr));*/
}
// 启动所有线程
for (int i = 0; i < initThreadSize_; ++i)
{
// 创建线程,启动线程,执行线程函数:即查看任务队列是否有任务,若有就拿走执行
threads_[i]->start();
idleThreadSize_++; // 记录初始空闲线程的数量
}
}
线程里面就存储函数对象
// 线程类型
class Thread
{
public:
using ThreadFunc = std::function<void(int)>;//void threadFunc();
Thread(ThreadFunc func);
~Thread();
// 启动线程
void start();
// 获取线程的id
int getId() const;
private:
ThreadFunc func_;
static int generateId_;
int threadId_; // 保存线程的id
};
启动线程的时候就通过函数对象来跑就行了。
设置成分离线程,主线程退出的时候分离线程没执行完线程函数后也会退出。
// 启动线程,线程函数要访问的锁,条件变量都在ThreadPool里面,所以线程函数要放到ThreadPool里面
void Thread::start()
{
// 创建一个线程函数,这里的thread的方法就是在构造函数里面执行的
std::thread t(func_,threadId_); // C++11 来说,线程对象t 和线程函数func_
t.detach(); // 设置为分离线程,主线程和从线程func_
}
wait 就是阻塞的等待,wait_for 就是等待的时间长度会说,wait_util强调等待得时间结点会说。如果主线程放任务的过程超过1s,那么此时返回一个valid 为false 的Result,标识放任务失败。那么用户需要对返回值进行判断。
// 给线程池提交任务
Result ThreadPool::submitTask(std::shared_ptr<Task> sp)
{
// 获取锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
// 线程的通信 --判断是否队列中的任务到达了上限
// 在 nonempty 条件变量进行等待,Pred条件不满足才会跳出wait
// 用户提交任务,最长不能超过1s,否则判断任务失败,返回
// wait(与时间无关) wait_for(持续等待的时间) wait_until(等待的终点)
// wait_for 返回值判断
if (!notFull_.wait_for(lock, std::chrono::seconds(1), [&]()->bool {return taskQue_.size() < taskQueMaxThreshHold_; }))
{
// 返回值为false,条件依旧没有满足,任务队列满的
std::cerr << "task queue is full,submit task fail." << std::endl;
return Result(sp,false); // Task Result
}
//taskQue_.push(std::move(sp));// bug
taskQue_.emplace(sp);
taskSize_++;
// 通知消费者消费
nonEmpty_.notify_all();
// cached模式 需要根据任务数量和空闲线程数量,判断是否需要创建新的线程
// 应用场景: 小而快的任务
if (poolMode_ == PoolMode::MODE_CACHED
&& taskSize_ > idleThreadSize_
&& curThreadSize_< threadSizeThreshHold_)
{
std::cout << ">>> create new thread" << std::endl;
// 创建新的线程对象
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this,std::placeholders::_1));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
threads_[threadId]->start();
// 修改线程个数相关的变量
curThreadSize_++;
idleThreadSize_++;
}
return Result(sp);
}
exec函数:
exec 函数的执行,是执行程序,并且将返回值放到Task当中的Result*当中。
exec封装了setVal,实际上就是提前判断result_是否存在,存在才设置。
void Task::exec()
{
if (result_ != nullptr)
{
result_->setVal(run()); // 这里发生多态调用
}
}
设置结果在Result的构造函数中执行。
void Task::setResult(Result* res)
{
result_ = res;
}
get函数:
isValid_ 当任务没放到任务队列的时候会被设置为false,此时用户即使是调用get方法获取返回值也是会失败的。
if (!notFull_.wait_for(lock, std::chrono::seconds(1), [&]()->bool {return taskQue_.size() < taskQueMaxThreshHold_; }))
{
// 返回值为false,条件依旧没有满足,任务队列满的
std::cerr << "task queue is full,submit task fail." << std::endl;
return Result(sp,false); // Task Result
}
// 用户调用
Any Result::get()
{
if (!isValid_)
{
return nullptr;
}
sem_.wait(); // 任务如果没有执行完,这里会阻塞用户
return std::move(any_);
}
Any类的设计
首先要构造函数要能接受任意类型,那么我们一定有一个构造函数是函数模板;
然后需要Any类是这个接受类型的父类,那么我们可以定义一个子类Derive,专门接受不同类型的,然后保存在子类当中;父类不需要模板,Any类放一个unique_ptr<Base>,然后构造函数 Any(T data) :base_(std::make_unique<Derive<T>>(data)) {} 这样base_ 就指向了任意类型,并且是父类。若要使用的时候可以通过转化为子类(dynamic_cast)然后cast_操作就会将保存的值进行返回。
// Any 类型:可以接受任意数据的类型
class Any
{
public:
Any() = default;
~Any() = default;
Any(const Any&) = delete;// 成员禁止左值拷贝和赋值
Any& operator=(const Any&) = delete;
Any(Any&&) = default;
Any& operator=(Any&&) = default;
// 模板收任意类型的数据来构造一个对象
template<typename T>
Any(T data) :base_(std::make_unique<Derive<T>>(data))
{}
// 这个方法能把Any对象里面存储的data对象提取出来
template<typename T>
T cast_()
{
// 我们怎么从base_找到它所指向的Derive对象,从他里面取出data成员变量
// 基类指针 =》 派生类指针
// base.get_() 就是获取裸指针
Derive<T>* pd = dynamic_cast<Derive<T>*>(base_.get());
// 类型不匹配就会失败
if (pd == nullptr)
{
throw "type is unmatch !";
}
return pd->data_;
}
private:
class Base
{
public:
virtual ~Base() = default;
};
// 派生类类型
template<typename T>
class Derive : public Base
{
public:
Derive(T data):data_(data)
{}
public:
T data_; // 保存了任意其他类型
};
private:
std::unique_ptr<Base> base_;// 基类指针
};
Result 就是提供给外部的,封装了Any,定义Any成员变量作为返回值,外部通过Result简介可以通过Any的cast_方法拿到想要的返回值。
但是如果cast_ 的类型不匹配,会返回nullptr。即外部定义MyTask的返回值sum的类型需要确定。
// 实现接受任务提交到线程池的task任务执行完成后的返回值类型Result
class Result
{
public:
Result(std::shared_ptr<Task> task, bool isValid = true);
~Result() = default;
// 问题一:setVal 方法,获取任务执行完的返回值的
void setVal(Any any);
// 问题二: get方法,用户调用这个方法获取task的返回值
Any get();
private:
Any any_; // 存储任务返回值
Semaphore sem_; // 线程通信信号量 ,默认二元
std::shared_ptr<Task> task_;// 指向获取返回值的任务对象
std::atomic_bool isValid_; // 返回值是否有效,任务提交失败那肯定时无效的
};
使用范例,由于调用方肯定知道返回值的类型,那么就可以拿到Result当中的Any对象存储的值提取成相应的返回值。
Result res1 = pool.submitTask(std::make_shared<MyTask>(1, 100000000));
pool.submitTask(std::make_shared<MyTask>(200000001, 300000000));
ull sum1 = res1.get().cast_<ull>();
Semaphore
信号量和mutex的区别:
二元信号量其实已经有了互斥的语义,但是信号量的P,V可以在不同线程,而mutex必须在一个线程。
C++20 提供了,但是我们自己实现。
由于拿返回值的时候可能存在线程池中的线程暂时还没处理完任务,所以得阻塞。
实现信号量可以用条件变量,用锁搭配条件变量实现通知,用resLimit_说明资源的数量。
class Semaphore
{
public:
Semaphore(int limit = 0)
:resLimit_(limit)
{}
~Semaphore() = default;
// 获取一个信号量资源
void wait()
{
std::unique_lock<std::mutex> lock(mtx_);
// 等待信号量有资源,没有资源的话,会阻塞当前线程
cond_.wait(lock, [&]()->bool {return resLimit_ > 0; }); // 该条件满足就退出
resLimit_--;
}
// 增加一个信号量资源
void post()
{
std::unique_lock<std::mutex> lock(mtx_);
resLimit_++;
cond_.notify_all();
}
private:
int resLimit_; // 资源的一个数量
std::mutex mtx_; // 需要互斥
std::condition_variable cond_; // 需要通知
};
submitTask 返回任务的结果,不能够通过往Task对象添加成员方法来实现,即task->getResult();这种是不行的。但是Result(task)这种是没有问题的。 原因是:task的生命周期比Result的短。
Result的实现
Result的构造函数,会将对应的Task结构绑定起来。
其中std::shared_ptr<Task> task作为形参也是延续了Task的生命周期,至此task的生命周期由Result管控。
总结步骤
- 1.Result的构造函数,在submitTask,失败或者成功都会调用,不同在于isValid_是否会被设置为false,默认设置true,标识放任务成功。Task和Result绑定成功。
- 2.用户此时若访问Result获取返回值,会调用get方法然后在信号量下等待。
- 3.线程池拿到任务,执行任务,将任务结果设置到Result的any_,唤醒用户线程。
特殊情况:若是任务没有成功放到队列的话,就会返回nullptr给any_,从any_此时提取不出来返回值。因为base_ 里面存的是nullptr,dynamic_ptr的时候返回nullptr,我们内部做了抛异常处理。
// Result 方法的实现
Result::Result(std::shared_ptr<Task> task, bool isValid)
:isValid_(isValid)
,task_(task)
{
task_->setResult(this);
}
// setResult 设置Task的返回结果
void Task::setResult(Result* res)
{
result_ = res;
}
// 用户调用,若是isValid_ 是false就表示任务都没传进来,其他情况就等待信号量。
Any Result::get()
{
if (!isValid_)
{
return nullptr;
}
sem_.wait(); // 任务如果没有执行完,这里会阻塞用户
return std::move(any_);
}
// 线程池内部线程调用
/// 设置返回值的调用
void Result::setVal(Any any)
{
// 存储task的返回值
this->any_ = std::move(any);
sem_.post(); // 已经获取了任务的返回值
}
/// 线程池内部调用exec函数会将用户传进来的run()方法跑了,返回值给到setVal方法,进行保存并且通知用户。
void Task::exec()
{
if (result_ != nullptr)
{
result_->setVal(run()); // 这里发生多态调用
}
}
Result的生命周期什么时候结束。出了用户的生命周期才会析构。
所有的set方法都要在进程没被run起来之前被设置。
// 设置线程池的工作模式
void ThreadPool::setMode(PoolMode mode)
{
// 启动之后不允许设置线程池状态
if (checkRunningState())
return;
poolMode_ = mode;
}
Cache模式解释
若是处于Cache模式:
Thread的成员变量threadid_ 就是为这里考虑的。因为删除线程的时候需要找到通过id来找,这样会比较优雅。
由于需要判断是否需要增加或者删除线程,用idleThreadSize_来记录空闲线程的数量,curThreadSize_ 来记录已经创建了的线程总数(空闲+非空闲),taskSize_记录任务的任务队列中数量,后续可以通过空闲的线程数量和taskSize_进行比较,从而来增加/删除线程。
submitTask:
负责提交,提交的时候需要考虑已有的任务若是比线程多,那么就可以动态的创建适量线程来执行任务。因为提交任务可以对任务进行初步的判断,考虑是否需要增加线程处理。
增加的时间点,只要是cache,并且当前的线程数没有达到上限值,任务数量大于空闲线程数,就可以进行创建。
// cached模式 需要根据任务数量和空闲线程数量,判断是否需要创建新的线程
// 应用场景: 小而快的任务
if (poolMode_ == PoolMode::MODE_CACHED
&& taskSize_ > idleThreadSize_
&& curThreadSize_< threadSizeThreshHold_)
{
std::cout << ">>> create new thread" << std::endl;
// 创建新的线程对象
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this,std::placeholders::_1));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
threads_[threadId]->start();
// 修改线程个数相关的变量
curThreadSize_++;
idleThreadSize_++;
}
threadFunc:
线程池中的线程在wait_for进行等待,当被唤醒的时候判断如果是timeout了,表示一定时间内没有任务了,此时若是线程的数量超过初始的,就可以让线程销毁了。
我们这里规定,就是从等待任务的时候,每1s timeout一次,直到时间已经超过60s,那么线程就不能留着了。
if (poolMode_ == PoolMode::MODE_CACHED)
{
if (std::cv_status::timeout == nonEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
auto now = std::chrono::high_resolution_clock().now();
auto dur = std::chrono::duration_cast<std::chrono::seconds>(now - lastTime);
if (dur.count() >= THREAD_MAX_IDLE_TIME
&& curThreadSize_ > initThreadSize_)
{
// 开始回收当前线程
// 记录线程数量的相关变量的值修改
// 把线程对象从线程列表容器中删除 到那时没有办法直到对应的thread的线程对象
// threadid => thread对象
threads_.erase(threadid);// 删除id,不能用this_thread里面的id
curThreadSize_--;
idleThreadSize_--;
std::cout << "threadid:" << std::this_thread::get_id() <<
"exit !" << std::endl;
return;
}
}
}
setThreadSizeThreshHold:
若是要设置线程为Cache模式,需要判断线程是否有启动。
会遇到死锁问题
- 当ThreadPool的析构函数不做处理的时候,线程池已有的线程由于会访问到ThreadPool的数据结构,而线程池的线程都是detach状态,只有主线程退出才能够进行释放,所以我们需要在~ThreadPool() 当中把所有等待在nonEmpty条件变量下的线程唤醒,并且设置isPoolRunning_状态。
// 线程池析构
ThreadPool::~ThreadPool()
{
isPoolRunning_ = false;
//nonEmpty_.notify_all();// 唤醒所有的线程 -- 这里唤醒的话,会有一种情况唤醒不了
// 等待线程池里面所有的线程返回,有两种状态: 阻塞 & 正在执行的任务
std::unique_lock<std::mutex> lock{ taskQueMtx_ };
nonEmpty_.notify_all();// 唤醒所有的线程
// 所有线程都释放,这里才会彻底退出
exitCond_.wait(lock, [&]()->bool {return threads_.size() == 0; });
}
若是nonEmpty的唤醒放在notify前面,有可能还会造成死锁,这个问题是非闭环的,一定要逻辑清晰。
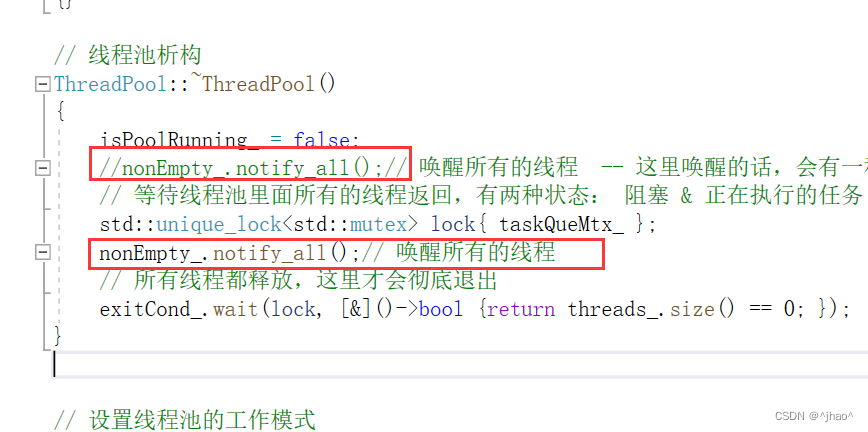
即下面这种特殊情况。那为什么nonEmpty的唤醒放下面就没有问题呢? 因为即使获取锁后唤醒,那么我们可以通过双重判断解决。
~ThreadPool() 如果是先唤醒,在获取锁,(此时可能)就有可能主线程和线程池的线程都在等待唤醒的情况。但是如果是先获取锁,那么线程池的线程在第二次判断isPoolRunning这里,就一定会被判断失败,然后去执行任务。 其实单纯的只是析构函数唤醒的时候线程切换,就有可能发生部分线程执行任务的时候进入了临界区执行任务,但是没任务又wait了。
下图的说法是错误的,是一开始总结的时候想的:其实这里不用考虑切换,都上锁了,这里肯定是串行的。愚蠢。
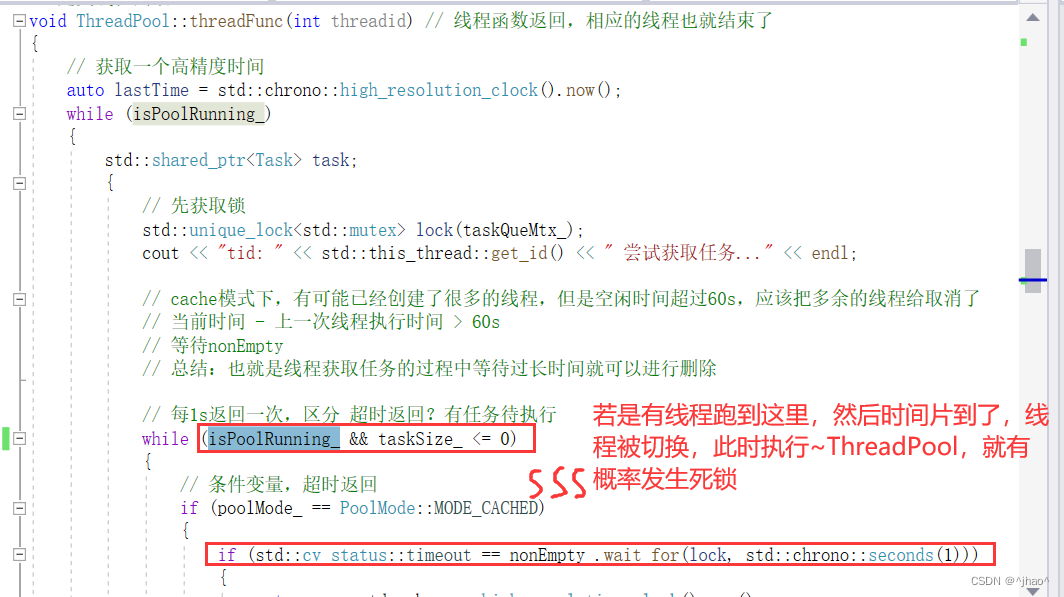
析构函数代码如上。
// 线程池析构
ThreadPool::~ThreadPool()
{
isPoolRunning_ = false;
//nonEmpty_.notify_all();// 唤醒所有的线程 -- 这里唤醒的话,会有一种情况唤醒不了
// 等待线程池里面所有的线程返回,有两种状态: 阻塞 & 正在执行的任务
std::unique_lock<std::mutex> lock{ taskQueMtx_ };
nonEmpty_.notify_all();// 唤醒所有的线程
// 所有线程都释放,这里才会彻底退出
exitCond_.wait(lock, [&]()->bool {return threads_.size() == 0; });
}
配合线程函数,可以彻底解决死锁问题。
这种线程执行可以保证,已经在任务队列的任务都能执行完再退出。
// 定义线程函数
void ThreadPool::threadFunc(int threadid) // 线程函数返回,相应的线程也就结束了
{
// 获取一个高精度时间
auto lastTime = std::chrono::high_resolution_clock().now();
while (isPoolRunning_)
{
std::shared_ptr<Task> task;
{
// 先获取锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
cout << "tid: " << std::this_thread::get_id() << " 尝试获取任务..." << endl;
// cache模式下,有可能已经创建了很多的线程,但是空闲时间超过60s,应该把多余的线程给取消了
// 当前时间 - 上一次线程执行时间 > 60s
// 等待nonEmpty
// 总结:也就是线程获取任务的过程中等待过长时间就可以进行删除
// 每1s返回一次,区分 超时返回?有任务待执行
while (isPoolRunning_ && taskSize_ <= 0)
{
// 条件变量,超时返回
if (poolMode_ == PoolMode::MODE_CACHED)
{
if (std::cv_status::timeout == nonEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
auto now = std::chrono::high_resolution_clock().now();
auto dur = std::chrono::duration_cast<std::chrono::seconds>(now - lastTime);
if (dur.count() >= THREAD_MAX_IDLE_TIME
&& curThreadSize_ > initThreadSize_)
{
// 开始回收当前线程
// 记录线程数量的相关变量的值修改
// 把线程对象从线程列表容器中删除 到那时没有办法直到对应的thread的线程对象
// threadid => thread对象
threads_.erase(threadid);// 删除id,不能用this_thread里面的id
curThreadSize_--;
idleThreadSize_--;
std::cout << "threadid:" << std::this_thread::get_id() <<
"exit !" << std::endl;
return;
}
}
}
else
{
nonEmpty_.wait(lock);
}
// 线程等待被唤醒后,两种情况都检查是被谁唤醒
// 线程池要结束,回收线程资源
if (!isPoolRunning_)
{
// erase就是调用了unique_ptr的析构函数,会把Thread删除,这里就已经删除线程了
threads_.erase(threadid);// 删除id,不能用this_thread里面的id
std::cout << "threadid:" << std::this_thread::get_id() <<
"exit !" << std::endl;
exitCond_.notify_all();
return;
}
}
taskSize_--;
}
idleThreadSize_--;
cout << "tid: " << std::this_thread::get_id() << " 获取任务成功" << endl;
// 取任务
task = taskQue_.front();
taskQue_.pop();
// 如果依然有剩余的任务,继续通知其他线程执行任务
if (taskQue_.size() > 0)
{// 第一个吃螃蟹的通知其他人吃螃蟹
nonEmpty_.notify_all();
}
// 取出一个任务,进行通知,通知可以继续提交生产任务
notFull_.notify_all();
// 释放锁,执行任务
if (task != nullptr)
{
// task->run();
// 执行任务:把任务的返回值通过setVal方法给到Result
task->exec();
}
// 返回值处理
idleThreadSize_++;// 线程执行完了任务,空闲线程++
// 更新线程调度执行完任务的时间
lastTime = std::chrono::high_resolution_clock().now();
}
// isRunLooping_表示部分线程在线程池要退出的时候刚好在执行任务,执行后到这里
threads_.erase(threadid);// 删除id,不能用this_thread里面的id
std::cout << "threadid:" << std::this_thread::get_id() <<
"exit !" << std::endl;
exitCond_.notify_all();
}
第二个死锁问题,移植到Linux发生
若项目移植到Linux下会发生错误,在Semaphore 提供一个变量isExit_可以解决。
具体调试步骤,发生死锁,查看进程id

1号是main线程,我们看看2号线程是在哪里阻塞了;
很明显,线程执行notify_all的时候进入睡眠了。
原因:此时的条件变量已经析构了。vs下没出问题是因为对条件变量的资源进行了删除,而Linux下没有对条件变量析构做处理。
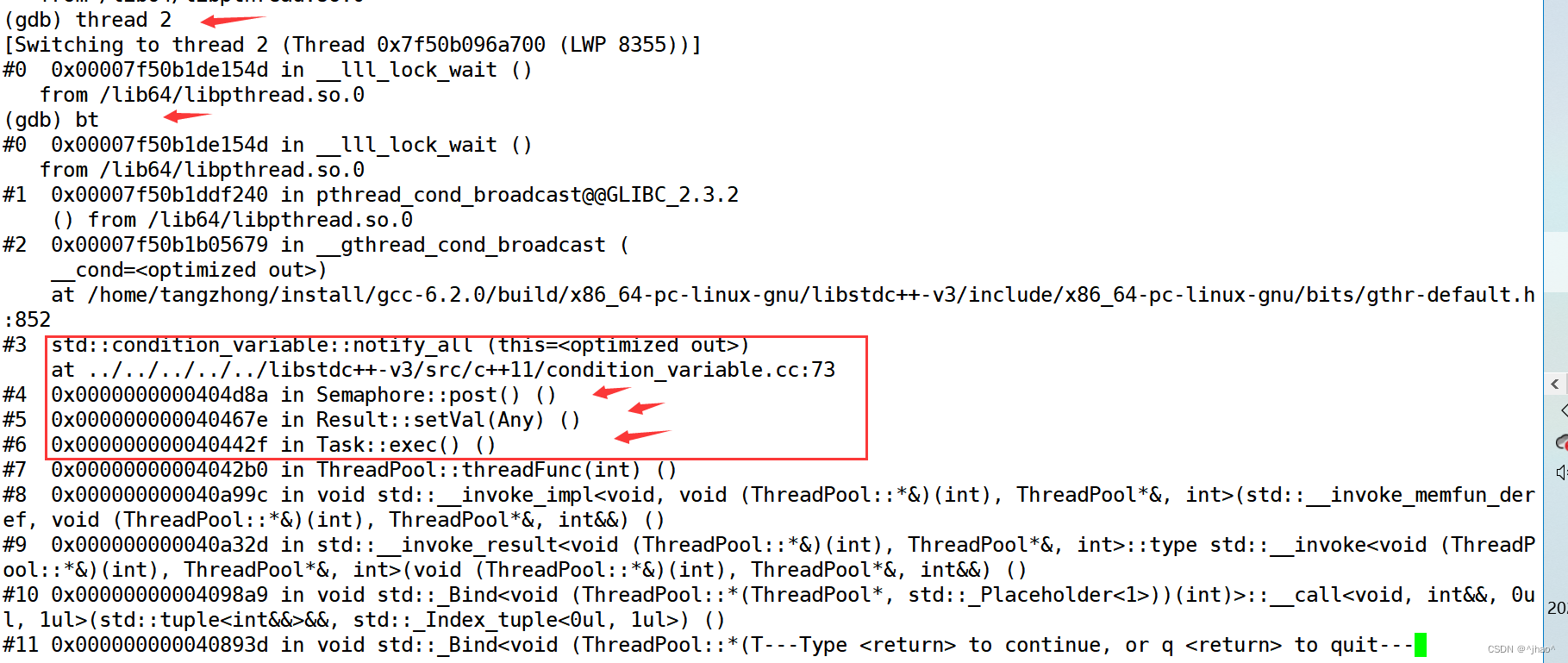
那为啥Semaphore会被析构呢?
Semaphore 是在Result中被使用,是用来用户进行获取返回值的时候进行使用的。但是有一种场景:
如下图,解释也在图中。
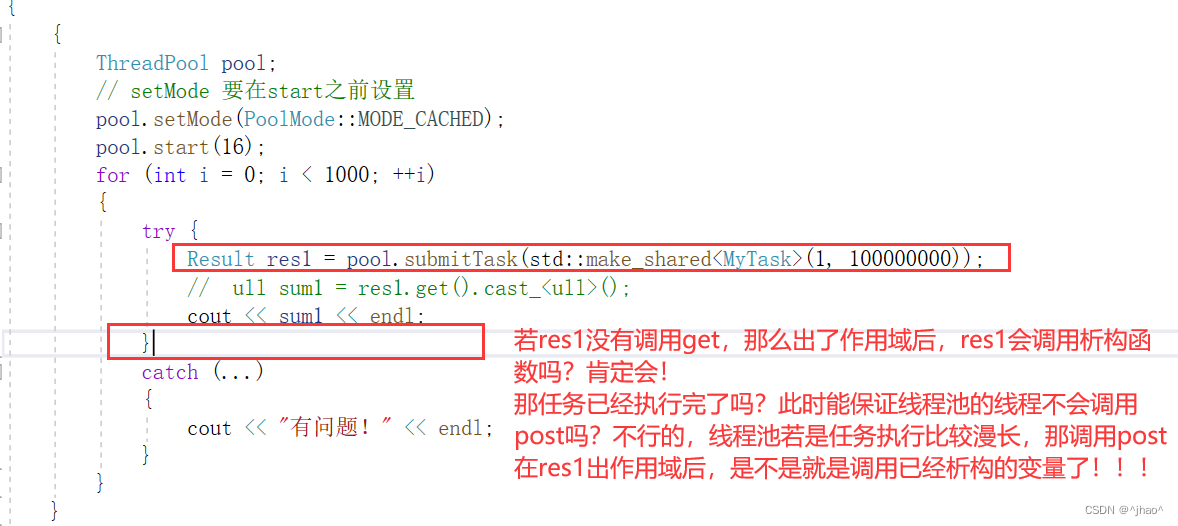
解决办法,每次wait,post操作对isExit_进行判断。
// 实现一个信号量类
class Semaphore
{
public:
Semaphore(int limit = 0)
:resLimit_(limit)
,isExit_(false)
{}
~Semaphore()
{
isExit_ = true;
}
// 获取一个信号量资源
void wait()
{
if(isExit_)
{
return ;
}
std::unique_lock<std::mutex> lock(mtx_);
// 等待信号量有资源,没有资源的话,会阻塞当前线程
cond_.wait(lock, [&]()->bool {return resLimit_ > 0; }); // 该条件满足就退出
resLimit_--;
}
// 增加一个信号量资源
void post()
{
// 如果已经不存在了,那么可以不做任何事情了
if(isExit_)
{
return ;
}
std::unique_lock<std::mutex> lock(mtx_);
resLimit_++;
// 这里会有问题,因为Linuxcond_不释放资源,会发生无故阻塞
cond_.notify_all();
}
private:
int resLimit_;// 资源的一个数量
std::mutex mtx_;
std::condition_variable cond_;
std::atomic_bool isExit_;
};
项目重构
用C++11,14 来进行代码重构,摒弃自己的Result,Task,Semaphore等等,用packaged_task 和 future类型来实现。
类似thread(func,12,3),我们希望给submitTask传参的时候也可以使用这种类似的方式,而不是自己手动创建任务,然后将任务传参。
简单的一些前置知识铺垫:
- packaged_task类似上述Task,不过支持了传函数。packaged_task重载的operator()就是对任务进行执行,并且设置了返回值(和Task的exec方法类似)。
- packaged_task与 functional一样,都是函数对象,就是将任务进行打包。但是packaged_task能够帮助获得返回值,返回值是future<返回值类型>。
- packaged_task的get_future方法返回一个future<返回值类型>的对象, 相当于先前我们写的submitTask的时候返回的Result(sp);
总结:
暂时可以将packaged_task 看作上面的Task方法,future 看作上面的Result方法。
注意:packaged_task的operator()重载中若是执行失败,会返回future_error的异常,通常若是发生这个异常,可能是任务没有被执行。

submitTask改造,其中返回值类型用了auto,这是C++14提供的,std::future<decltype(func(args…))>用来推导返回值类型是没有问题的,和sizeof类似,func(args…)并不会真正执行,只进行推导。
- 若是任务提交成功,则保存函数对象,注意Task是以值引用方式传递给了taskQue_里面,线程会拿到taskQue_ 里面的函数对象直接执行。
// 给线程池提交任务
// 使用可变参模板变成,让submitTask接受任意任务函数和任意数量的参数
// pool.submitTask(sum1,10,20)
template<typename Func,typename ...Args>
auto submitTask(Func&& func, Args&& ...args) -> std::future<decltype(func(args...))>
{
// 打包任务,放入任务队列
// 返回值类型重命名
using RType = decltype(func(args ...));
auto task = std::make_shared<std::packaged_task<RType()>>(
std::bind(std::forward<Func>(func), std::forward<Args>(args)...)
);
std::unique_lock<std::mutex> lock(taskQueMtx_);
// 线程的通信 --判断是否队列中的任务到达了上限
// 在 nonempty 条件变量进行等待,Pred条件不满足才会跳出wait
// 用户提交任务,最长不能超过1s,否则判断任务失败,返回
// wait(与时间无关) wait_for(持续等待的时间) wait_until(等待的终点)
// wait_for 返回值判断
if (!notFull_.wait_for(lock, std::chrono::seconds(1), [&]()->bool {return taskQue_.size() < taskQueMaxThreshHold_; }))
{
// 返回值为false,条件依旧没有满足,任务队列满的
std::cerr << "task queue is full,submit task fail." << std::endl;
auto task = std::make_shared<std::packaged_task<RType()>>(
[]()->RType {return RType(); } // 返回一个空值的任务
);
(*task)(); // 相当于主线程来执行这个不成功的例子了
return task->get_future(); // Task Result
}
//taskQue_.push(std::move(sp));// bug
//taskQue_.emplace(sp);
// using Task = std::function<void()>;
taskQue_.emplace([task]() { // 以值形式拷贝,相当于shared_ptr的拷贝了一份,疑问,这个函数体返回值不是void吗
// 去执行下面的任务
(*task)(); // 执行任务,以及设置任务的返回值
});
taskSize_++;
// 通知消费者消费
nonEmpty_.notify_all();
// cached模式 需要根据任务数量和空闲线程数量,判断是否需要创建新的线程
// 应用场景: 小而快的任务
if (poolMode_ == PoolMode::MODE_CACHED
&& taskSize_ > idleThreadSize_
&& curThreadSize_ < threadSizeThreshHold_)
{
std::cout << ">>> create new thread" << std::endl;
// 创建新的线程对象
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
threads_[threadId]->start();
// 修改线程个数相关的变量
curThreadSize_++;
idleThreadSize_++;
}
return task->get_future();
}
线程执行的函数基本上不用变,执行函数从task->exec() 换成 task() 即可,相当于执行了packaged_task的operator() 函数。
// 定义线程函数
void threadFunc(int threadid)
{
// 获取一个高精度时间
auto lastTime = std::chrono::high_resolution_clock().now();
while (isPoolRunning_)
{
Task task;
{
// 先获取锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
cout << "tid: " << std::this_thread::get_id() << " 尝试获取任务..." << endl;
// cache模式下,有可能已经创建了很多的线程,但是空闲时间超过60s,应该把多余的线程给取消了
// 当前时间 - 上一次线程执行时间 > 60s
// 等待nonEmpty
// 总结:也就是线程获取任务的过程中等待过长时间就可以进行删除
// 每1s返回一次,区分 超时返回?有任务待执行
while (taskSize_ <= 0)
{
// 条件变量,超时返回
if (poolMode_ == PoolMode::MODE_CACHED)
{
if (std::cv_status::timeout == nonEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
auto now = std::chrono::high_resolution_clock().now();
auto dur = std::chrono::duration_cast<std::chrono::seconds>(now - lastTime);
if (dur.count() >= THREAD_MAX_IDLE_TIME
&& curThreadSize_ > initThreadSize_)
{
// 开始回收当前线程
// 记录线程数量的相关变量的值修改
// 把线程对象从线程列表容器中删除 到那时没有办法直到对应的thread的线程对象
// threadid => thread对象
threads_.erase(threadid);// 删除id,不能用this_thread里面的id
curThreadSize_--;
idleThreadSize_--;
std::cout << "threadid:" << std::this_thread::get_id() <<
"exit !" << std::endl;
return;
}
}
}
else
{
nonEmpty_.wait(lock);
}
// 线程等待被唤醒后,两种情况都检查是被谁唤醒
// 线程池要结束,回收线程资源
if (!isPoolRunning_)
{
// erase就是调用了unique_ptr的析构函数,会把Thread删除,这里就已经删除线程了
threads_.erase(threadid);// 删除id,不能用this_thread里面的id
std::cout << "threadid:" << std::this_thread::get_id() <<
"exit !" << std::endl;
exitCond_.notify_all();
return;
}
}
taskSize_--;
}
idleThreadSize_--;
cout << "tid: " << std::this_thread::get_id() << " 获取任务成功" << endl;
// 取任务
task = taskQue_.front();
taskQue_.pop();
// 如果依然有剩余的任务,继续通知其他线程执行任务
if (taskQue_.size() > 0)
{// 第一个吃螃蟹的通知其他人吃螃蟹
nonEmpty_.notify_all();
}
// 取出一个任务,进行通知,通知可以继续提交生产任务
notFull_.notify_all();
// 释放锁,执行任务
if (task != nullptr)
{
// task->run();
// 执行任务:把任务的返回值通过setVal方法给到Result
//task->exec();
task(); // 执行package_task封装的函数,执行完会post
}
// 返回值处理
idleThreadSize_++;// 线程执行完了任务,空闲线程++
// 更新线程调度执行完任务的时间
lastTime = std::chrono::high_resolution_clock().now();
}
// isRunLooping_表示部分线程在线程池要退出的时候刚好在执行任务,执行后到这里
threads_.erase(threadid);// 删除id,不能用this_thread里面的id
std::cout << "threadid:" << std::this_thread::get_id() <<
"exit !" << std::endl;
exitCond_.notify_all();
}
大致流程
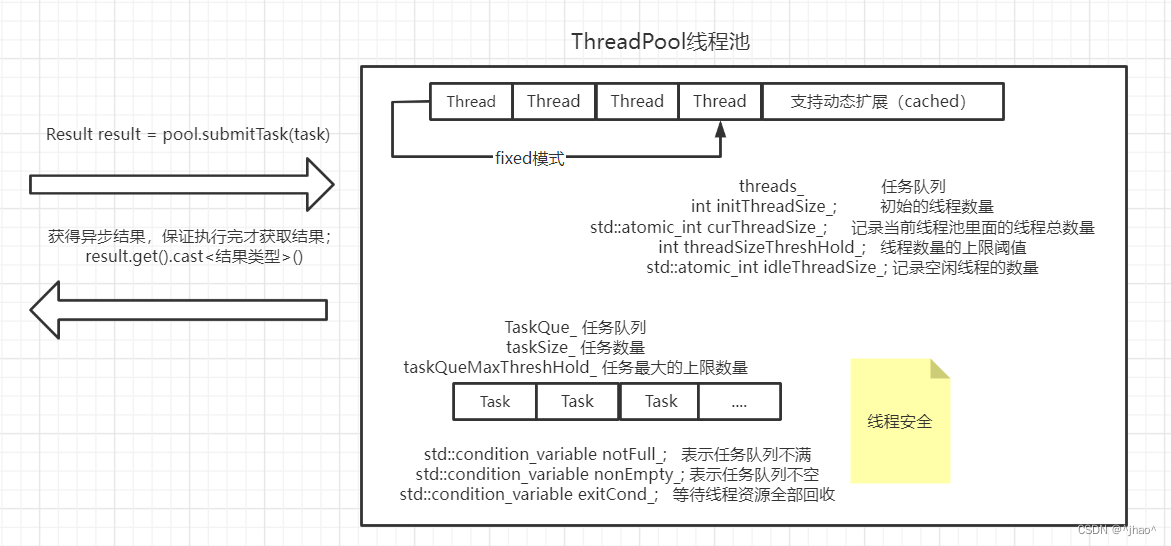
总结
该项目可能会碰到两次死锁,并且会碰到Linux平台和windows平台运行结果不一致的情况,均解决了。
项目链接:
码云,点击直达~

![[附源码]java毕业设计校园期刊网络投稿系统](https://img-blog.csdnimg.cn/c3661afa3b7d4fc38869d6a5b16d122e.png)










![[ros2实操]2-ros2的消息和ros1的消息转换](https://img-blog.csdnimg.cn/562035ea8b8542798295ca21d9a0228d.png)
![[附源码]SSM计算机毕业设计基于ssm的电子网上商城JAVA](https://img-blog.csdnimg.cn/834b864897154020a15fa78220c5ff6f.png)