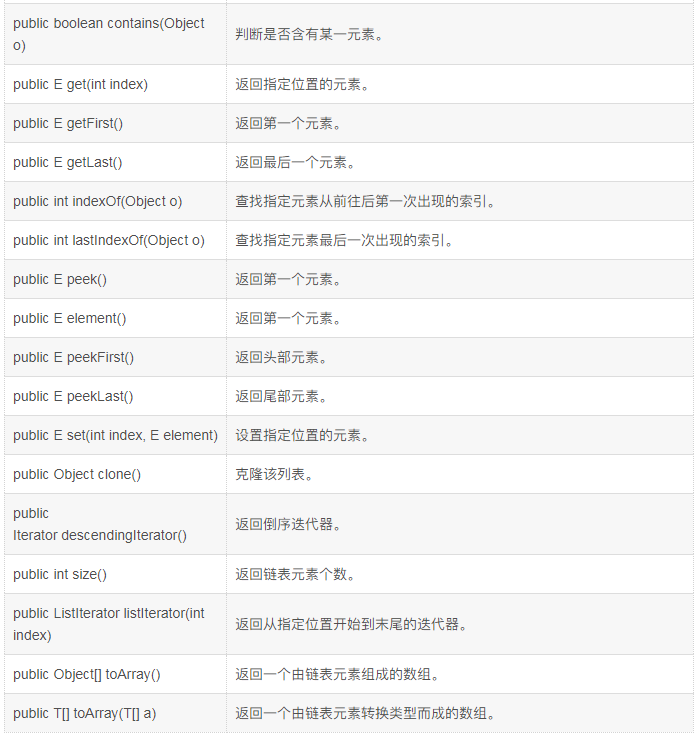
文本表示学习就是将一段文本映射到低纬向量空间,获取句子的语义表示,大致经历过四个阶段:
-
阶段 1:统计类型,此阶段比较典型的是利用 TD-IDF 抽取关键词,用关键词表示表征整个句子。
-
阶段 2:深度模型阶段,此阶段方式较多,自从 glove、word2vec 等词粒度的表示出现后,在此基础有比较多的魔改,从对句子中的词向量简单平均、到有偏平均 SIF [1],后来引入 CNN、LSTM 等模型利用双塔、单塔方式进行学习句子表示,比较典型的几个工作有:
-
微软在排序搜索场景的 DSSM [2],将 word 进行 hash 减少词汇个数,对 word 的表示进行平均得到句子原始表达,经过三层 MLP 获取句子表示。
-
多伦多大学提出的 Skip-Thought [3],是 word2vec 的 skip-ngram 在句子表达的延伸,输入三个句子,用中间一句话,预测前后两句话。
-
IBM 的 Siam-CNN [4],提出了四种单塔、双塔不同的架构,利用 pairwise loss 作为损失函数。
-
facebook 的 InferSent [5],在双塔的表示基础上,增加了充分的交互。
-
阶段 3:Bert、Ernie 等预训练大模型阶段,在此阶段比较基础典型的工作有:
-
由于 Bert 通过 SEP 分割,利用 CLS 运用到匹配任务场景存在计算量过大的问题,Sentence-BERT [6] 提出将句子拆开,每个句子单独过 encoder,借鉴 InferSent 的表示交互,来学习句子表达。
-
阶段 4:20 年在图像领域兴起的对比学习引入到 NLP。
2.2 对比学习
对比学习是一种模型架构,也是无监督学习的一种,最开始是应用到了 CV 领域,通过对 M 图片进行数据增强得到 N 图片,将 M 和 N 图片输入 encoder 后得到表示 Vm 和 Vn,如果两个表达相近则说明 encoder 学习的效果比较好。




比如上面四张图片,对于有监督的分类任务来说,需要分辨出每张图片到底是孙悟空还是猪八戒,训练数据需要具体标注出每一张图片的 label。而对于无监督的对比学习来说,不需要区分图片是孙悟空还是猪八戒,只需要学习的表示能够表达前两张图片是相似的,后两张图片是相似的即可,也就是『相似的东西表示越相似,不相似的东西越不相似』。








![[ros2实操]2-ros2的消息和ros1的消息转换](https://img-blog.csdnimg.cn/562035ea8b8542798295ca21d9a0228d.png)
![[附源码]SSM计算机毕业设计基于ssm的电子网上商城JAVA](https://img-blog.csdnimg.cn/834b864897154020a15fa78220c5ff6f.png)