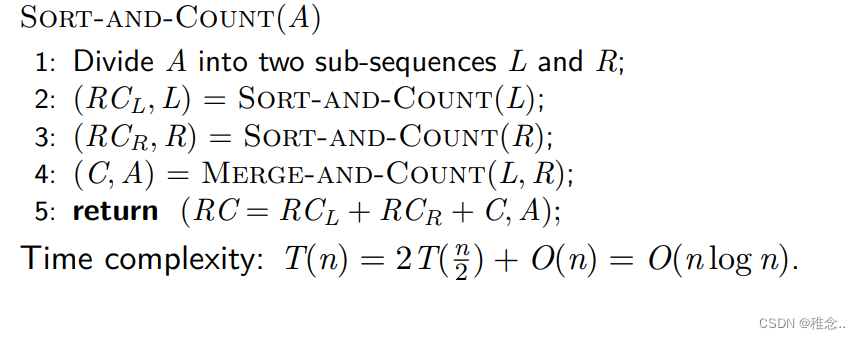文章目录
- 1. 冒泡排序
- 2. 选择排序
- 3. 简单插入排序
- 4. 希尔排序-->简单插入排序演变
- 5. 归并排序(递归版本)
- 6. 归并排序(非递归版本)
- 7. 荷兰国旗问题
- 8.由荷兰国旗问题进而引出快速排序 and 快速排序1.0版本
- 9.快速排序2.0版本(挖坑法)
- 10.快速排序 3.0版本(随机取数法)
- 11.堆排序
- 12.计数排序
- 193.基数排序
- 14 李珣版 爱心代码
1. 冒泡排序
冒泡排序思想: 其实这个排序还是挺有意思的,就打个比方,打擂台 张三和李四打擂,张三赢了,但是此时又冒出来一个王五,这又打了起来,再次打擂最终的擂主是三个人中最厉害的,就好比说王五赢了。那么例如此时的数组nums = {5,2,6,8},我们规定要降序排序。那么此时的5 和 2 比较 5 > 2 符合降序,然后 2 和 6 比较 不符合降序标准,那么此时两个元素交换位置 那么此时的数组就为{5,6,2,8},然后继续向右遍历 2 < 8不符合降序标准那么2 和 8 的位置交换。那么此时的数组nums = {5,6,8,2},这样最小的元素是不是就到了最后的位置。然后我们的扫描指针又回到0下标,又开始比较。
冒泡排序图例:


冒泡排序代码:
public class TestDemo5 {
public static void bottleSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
for(int i = 0;i < nums.length - 1;i++){ //外部循环是比较的趟数
for(int j = 0;j < nums.length - i - 1;j++){ //内部循环是比较的次数
if(nums[j] > nums[j + 1]){ //此时我们是按升序排序的,如果要改成降序,那么就把这个>改成<
swap(nums,j ,j + 1);
}
}
}
}
public static void swap(int []nums,int x,int y){
int temp = nums[x];
nums[x] = nums[y];
nums[y] = temp;
}
public static void main(String[] args) {
int []nums = {9,8,7,6,5,4,3,2,1,0};
bottleSort(nums);
System.out.println(Arrays.toString(nums));
}
}
时间复杂度: O(n ^ 2)
空间复杂度: 因为在排序的时候额外的申请空间,那么此时的空间复杂度就为O(1)
稳定性: 稳定
2. 选择排序
选择排序思想: 其实就是在数组中选定一个元素的位置下标,然后遍历这个下标之后的元素,我们以升序排序为例。如果这个定位元素 > 遍历过程中的每一个元素,那么就进行交换。一直把这个定位元素之后的元素遍历完,那么此时的这个定位元素就是数组中的最小值,然后这个定位向右移动,在从定位之后遍历所有的元素,找到这个数组中的第二个小的元素。直到这个定位遍历到了数组的末尾,那么此时的数组就是一个排序好的升序序列。
选择排序图例:


选择排序代码:
public class TestDemo6 {
public static void selectSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
for(int i = 0;i <nums.length;i++){
for(int j = i +1;j < nums.length;j++){
if(nums[i] > nums[j]){
swap(nums,i,j);
}
}
}
}
public static void swap(int []nums,int x,int y){
int temp = nums[x];
nums[x] = nums[y];
nums[y] = temp;
}
public static void main(String[] args) {
int []nums = {9,8,7,6,5,43,2,1,0};
selectSort(nums);
System.out.println(Arrays.toString(nums));
}
}
时间复杂度: O(n ^ 2)
空间复杂度: O(1)
稳定性: 不稳定
其实还有一种高阶版本的选择排序,遍历一次数组可以确定一个最大值和一个值。
还是看图吧: 设置两个指针 一个指针为left 另一个指针为right 还有就是设置两个变量max,min 分别为在遍历数组的时候,记录当前遍历的最小值和最大值

相关代码:
public class TestDemo10 {
public static void selectSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
int left = 0;
int right = nums.length - 1;
while(left < right){
int max = left;
int min = left;
for(int i = left;i <= right;i++){
if(nums[min] > nums[i]){
min = i;
}
if(nums[max] < nums[i]){
max = i;
}
}
swap(nums,left,min);
//防止最大值在left下标,而前面left下标的值已经被交换了
if (max == left) {
max = min;
}
swap(nums,right,max);
left++;
right--;
}
}
private static void swap(int[] nums, int x, int y) {
int temp = nums[x];
nums[x] = nums[y];
nums[y] = temp;
}
public static void main(String[] args) {
int []nums = {9,8,7,6,5,4,3,2,1,0};
selectSort(nums);
System.out.println(Arrays.toString(nums));
}
}
3. 简单插入排序
插入排序思想: 老铁们平时玩纸牌吗,我们在得到牌之后,是不是要对手中的牌,做出排序,插入排序类型于将我们完的扑克,将牌一张一张插入到我们的序列中,形成一个有序的序列。

插入排序图例:


插入排序代码:
public class TestDemo3 {
public static void main(String[] args) {
int[] nums = {9, 8, 7, 6, 5, 4, 3, 2, 1, 0};
insertSort(nums);
System.out.println(Arrays.toString(nums));
}
public static void insertSort(int[] nums) {
if (nums == null || nums.length == 0) {
return;
}
for(int i = 1;i < nums.length;i++){
int temp = nums[i];
int j = i - 1;
for(;j>=0;j--){
if(nums[j] > temp){
nums[j +1] = nums[j];
}else {
break;
}
}
nums[j + 1] = temp;
}
}
}
时间复杂度: O(n ^ 2) 元素集合越接近有序,直接插入排序算法的时间效率越高 以我们要把数组设置为升序排序,那么此时刚好待排序数组是一个升序序列,就等于说不用排序就是一个升序的。那么此时的时间复杂度为O(n).但是我们的最坏的时间复杂度是O(n ^ 2) 为什么呢? 其实如果我们此时的原数组是一个数组。我们要排序成的序列为 {0,1,2,3,4,5,6,7,8,9},但是此时的原数组为{9,8,7,6,5,4,3,2,1,0},那么此时数组中的每一个元素都要在数组中遍历n次,我们有n和元素,一共要遍历n次,那么此时的时间复杂度就为O(n ^ 2)
空间复杂度: O(1)
稳定性: 稳定
4. 希尔排序–>简单插入排序演变
希尔排序思想: 希尔排序就是分组进行插入排序 , 当增量 gap 为 5 时, 数组就以 5 个数为一组 , 每一趟分组排序结束后 , 数组的元素都接近有序 , 当 gap 越来越小的时候 , 元素也越来越接近有序 , 当 gap 为 1 时 , 就是进行一趟插入排序 , 所以能保证最后的元素是有序的
希尔排序图例:


插入排序代码:
public static void shellSort(int []array,int gap){
for(int i = gap;i<array.length;i++){
int j = i-gap;
int temp = array[i];
for(;j>=0;j-=gap){
if(array[j] > temp){
array[j+gap] = array[j];
}else{
break;
}
}
array[j+gap] = temp;
}
}
public static void shell(int []array){
//希尔排序其实就是在直接插入排序上的优化,把数组分为若干组,然后对每一组进行直接插入排序,每组之间的组距逐渐减小
int gap = array.length;
while(gap > 1){
shellSort(array,gap);
gap = gap/2; //每次分组都是上一次分组的2分之1 .第一次是 array.length / 2
}
shellSort(array,gap);//最后为一组,就是直接插入排序
}
时间复杂度: O(n ^ (1.3 - 2))
空间复杂度: O(1)
稳定性: 不稳定
5. 归并排序(递归版本)
首先我们先看看这道题:现在有两个有序的数组,现在要把这两个数组合并成一个有序的大数组。
对应解析: 相关算法思想,设置两个指针,假设此时的一个数组为nums1,另一个数组为nums2,两个指针分别为i,j 我们设置一个新数组bigNum,index 为这个大的数组遍历的指针,这个数组的长度就是两个小的有序数组的长度之和,那么此时的两个指针遍历对应的数组 即 如果nums1[i] <= nums2[j]或者 nums2[j] <= nums1[i] 那么此时bigNum[index++] = nums1[i] <= nums2[j] ? nums1[i] : nums2[j].
那么如果当这两个小的数组的长度是不相同的,那么就总有一个子数组被遍历完。那么就把另外的一个数组,添加到bigNum后面。
有关代码:
public static void main(String[] args) {
int []nums1 = {1,3,4,5,6,7,8,9};
int []nums2 = {-1,3,4,10,45};
int []bigNums = new int[nums1.length + nums2.length];
int p1 = 0;
int p2 = 0;
int index = 0;
int len1 = nums1.length - 1;
int len2 = nums2.length - 1;
while(p1 <= len1 && p2 <= len2){
bigNums[index++] = nums1[p1] <= nums2[p2] ? nums1[p1++] : nums2[p2++];
}
while(p1 <= len1){
bigNums[index++] = nums1[p1++];
}
while(p2 <= len2){
bigNums[index++] = nums2[p2++];
}
System.out.println(Arrays.toString(bigNums));
}
归并排序思想:
其实说实在的这里的归并排序就是,我们把数组每次划分成两个数组,一直对半分,一直对半分。直到分到的数只有一个,那么此时在合并两个元素,那么是怎样合并的呢,那么就依据我们上面所说的,整一个大的数组,把两个小的数组排好序添加到这个大的数组中。
归并排序图例:


归并排序代码:
public static void margeSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
margeSort(nums,0,nums.length - 1);
}
public static void margeSort(int []nums,int left,int right){
if(left >= right){
return;
}
int mid = left + right >> 1;
margeSort(nums,left,mid);
margeSort(nums,mid + 1,right);
marge(nums,left,mid,right);
}
public static void marge(int []nums,int left,int mid,int right){
//这里其实就是把一个大的数组分成了两个小的子数组,两个排好序的子数组,排序成排好的大数组
int p1 = left; //第一个子数组的起点为left 第一个子数组下标终点mid
int p2 = mid + 1; //第二个子数组的起点 mid + 1 第二个子数组的终点right
int index = 0;
int []temp = new int[right - left + 1];
while(p1 <= mid && p2 <= right){
temp[index++] = nums[p1] <= nums[p2] ? nums[p1++] : nums[p2++];
}
while(p1 <= mid){
temp[index++] = nums[p1++];
}
while(p2 <= right){
temp[index++] = nums[p2++];
}
//将temp数组中的元素打会原数组中+
for(int i = 0;i < temp.length;i++){
nums[left + i] = temp[i];
}
}
public static void main(String[] args) {
int []nums = {9,8,7,6,5,4,3,2,1,0};
margeSort(nums);
System.out.println(Arrays.toString(nums));
}
时间复杂度:
用递归树的方法,归并排序的递归树是一棵满二叉树,每层合并总耗时都是n,共logn层,故时间复杂度为O(n*logn)。
和快排不同,归并排序无论何时时间复杂度都是O(n*logn),不会退化
空间复杂度: 辅助数组temp带来O(n)的空间复杂度。递归带来的空间复杂度是O(logn),数量级较小就忽略了。
所以归并排序虽然时间复杂度稳定在O(nlogn),但其空间复杂度是O(n),不适用于对数据规模大的数组进行排序,因为那样额外的内存消耗就太高了。
稳定性: 稳定,因为 p1 <= mid && p2 <= right
6. 归并排序(非递归版本)
归并排序非递归版本思想: 其实总体来说一下说明的这种方法还是换汤不换药,我们只是手动的把数组中的元素进行分组,让每一小组中的元变(marge)有序,然后把分组的长度* 2 得到新的分组长度,使用这个值在数组中又分组,然后又marge…一直重复直到分组长度 countLength > nums.length,那么此时数组就整体有序了。
归并排序非递归版本图例:

归并排序非递归版本代码:
public static void disMargeSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
int countLength = 1;
int N = nums.length;
while(countLength < N){
int left = 0;
while(left < N){
int mid = countLength + left - 1;
if(mid >= N){
break;
}
//如果此时在分组时,countLength + mid > nums.length 那么也就是说在这一组中没有countLength个元素,其实这也是分组的最后一组,那么此时它的right边界就是nums.length - 1 即数组中的最后一个元素的下标
int right = Math.min(countLength + mid , N - 1);
marge(nums,left,mid,right);//numsleft ~ right的元素排序
left = right + 1; //下一个分组的left指针
}
//此处为什么countLength > N / 2 因为设置是为了防止整型溢出
if(countLength > N / 2){
break;
}
countLength = countLength << 1; //分组长度 * 2
//为什么不使用* ? 因为使用*,在计算机中* 其实就是累加,这里的 << 表示的是这个数的二进制向左移动一位,那么也就是*2
//并且使用位运算,效率高
}
}
public static void marge(int []nums,int left,int mid,int right){
int p1 = left;
int p2 = mid + 1;
int index = 0;
int []temp = new int[right - left + 1];
while(p1 <= mid && p2 <= right){
temp[index++] = nums[p1] <= nums[p2] ? nums[p1++] : nums[p2++];
}
while(p1 <= mid){
temp[index++] = nums[p1++];
}
while(p2 <= right){
temp[index++] = nums[p2++];
}
//将temp数组中的元素打会原数组中
for(int i = 0;i < temp.length;i++){
nums[left + i] = temp[i];
}
}
public static void main(String[] args) {
int []nums = {9,8,7,6,5,4,3,2,1};
disMargeSort(nums);
System.out.println(Arrays.toString(nums));
}
时间复杂度: 我们可以想一想,如果此时的待排序元素有8个,我们第一次分组的分组长度为1,其实就等于说我们这次没有进行排序,然后countLength = countLength << 1 countLength 就变成了2,然后再marge,然后countLength = countLength << 1 countLength== 4 然后再marge,r然后countLength = countLength << 1 countLength == 8.那么此时我们可以看到此时的分组情况是:1 2 4 8 其实也是一个递归树。那么此时时间复杂度就为O(n * logn)
空间复杂度: O(n * logn)
稳定性: 稳定 因为 while(p1 <= mid && p2 <= right)
7. 荷兰国旗问题

所谓荷兰国旗问题简单的说就是:使用一个数作为标志位,使用这个标志位,把一个数组分成3块。左边的一块是 小于这个数的区间,中间的这一块是等于这个标志位的一块,那么右边的一块就是大于这个标志位的一块。 形象的说就是把这个荷兰国旗90度旋转一下。红色的就是小于区域,白色的就是等于区域。蓝色的就是大于区域。
图例:

那么我们该通过怎样的步骤,得到下面的这个数组呢?
具体算法:
步骤1: 设置less指针来遍历小于区的数组元素,more指针来遍历大于区的数组元素,index指针来遍历我们的整个数组。
步骤2: 我们此时定义这个数组为nums,并且把nums数组中的最右面的元素作为标志位,用这个标志位target在数组中遍历并且比较元素。
步骤3: 我们设置小于区指针(下标)为less = left - 1 也就是数组的-1下标,-1下标就当做是一个标记,其实-1下标是不存在的,它是less的初值,more大于区指针(下标) more = right.index在遍历数组的时候,进行交换操作。
步骤4: 当等于区的index >= more(大于区指针)的时候,那么就是说明此时我们已经根据最右面的标志位,已经把数组分成了3分,那么此时我们的标志位就要被放到等于区的最后一个位置。
以上为具体算法,如果没有完全理解,那么请对比一下图例方便理解:
移动元素到大于区:

部分代码:
private void swap(int []nums,int left,int right){
//不使用第三方参数交换元素
//nums[left] = nums[left] ^ nums[right];
//nums[right] = nums[left] ^ nums[right];
//nums[left] = nums[left] ^ nums[right];
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
public void heLanFlag(int []nums,int left,int right){
int more = right;
int index = left;
int less = left - 1;
if(nums[index] > nums[right]){ //大于区
swap(nums,index,--more);
}
}
移动元素到等于区:

部分代码:
private void swap(int []nums,int left,int right){
//不使用第三方参数交换元素
//nums[left] = nums[left] ^ nums[right];
//nums[right] = nums[left] ^ nums[right];
//nums[left] = nums[left] ^ nums[right];
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
public void heLanFlag(int []nums,int left,int right){
int more = right;
int index = left;
int less = left - 1;
if(nums[index] > nums[right]){ //大于区
swap(nums,index,--more);
}else if(nums[index] == nums[right]){ //等于区
index++;
}
}
移动元素到小于区:

private void swap(int []nums,int left,int right){
//不使用第三方参数交换元素
//nums[left] = nums[left] ^ nums[right];
//nums[right] = nums[left] ^ nums[right];
//nums[left] = nums[left] ^ nums[right];
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
public void heLanFlag(int []nums,int left,int right){
int more = right;
int index = left;
int less = left - 1;
if(nums[index] > nums[right]){ //大于区
swap(nums,index,--more);
}else if(nums[index] == nums[right]){ //等于区
index++;
}else{
swap(nums,index++,++less);
}
}

此时还有一个关键的步骤就是把现在的target和nums[more]做交换,在做完交换之后,我们就把整个数组,使用targer,也就是使用元素5,分成了小于5的,等于5的,大于5的三部分。

代码:
private void swap(int []nums,int left,int right){
//不使用第三方参数交换元素
//nums[left] = nums[left] ^ nums[right];
//nums[right] = nums[left] ^ nums[right];
//nums[left] = nums[left] ^ nums[right];
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
public void heLanFlag(int []nums,int left,int right){
int more = right;
int index = left;
int less = left - 1;
if(nums[index] > nums[right]){ //大于区
swap(nums,index,--more);
}else if(nums[index] == nums[right]){ //等于区
index++;
}else{
swap(nums,index++,++less);
}
swap(nums,more,right);
}
8.由荷兰国旗问题进而引出快速排序 and 快速排序1.0版本
在我们讲荷兰国旗问题的时候,使用数组中的一个元素把整个数组分成了小于这个数的一部分,等于这个数的一部分,大于这个数的一部分。那么我们想一想,我们是否可以使用荷兰国旗问题在排序上,其实是可以使用的。我们已经把数组分成了
< 区=区>区那么也就是说此时我在下一次排序的时候,不需要排
=区中的元素,直接递归数组的左半边和右半边就好了。在数组的左半边和右半边又玩荷兰国旗问题,那么此时我们的排序其不就成了,其实这就使用了我们的分治思想。这也就是快速排序
public static int []helaiflag(int []nums,int left,int right){
if(left > right){
return new int[]{-1,-1};
}
if(left == right){
return new int[]{left,right};
}
int less = left - 1;
int index = left;
int more = right;
while(index < more){
//等于区,遍历到和nums[right]相同的元素,也就是等于去的元素,直接index++
if(nums[index] == nums[right]){
index++;
}else if(nums[index] < nums[right]){
//小于区 ,遍历到比nums[right]小的元素,那么此时就把下标为index的元素和++less位置中的元素做交换,++less是因为原来的less指向的下标为-1,然后再把index++,也就是和小于区的右一个元素做交换
swap(nums,index++,++less);
}else{
//大于区
//当index遍历到 nums[index] > nums[right]的时候,和大于区的左边的一个元素做交换
swap(nums,index,--more);
}
}
//那么此时除了nums[right]以外,我们已经把数组分成了3分,因为此时的nums[right]和等于区的元素大小相同,并且此时index == more,那么此时就swap(nums,more,right)
swap(nums,more,right);
//此处返回的是等于区的下标区间
return new int[]{less+1,more};
}
private static void swap(int[] nums, int x, int y) {
int temp = nums[x];
nums[x] = nums[y];
nums[y] = temp;
}
public static void process(int []nums,int left,int right){
if(left >= right){
return;
}
//玩荷兰国旗问题把数组分成 小于 等于 大于 三份
int []flag = helaiflag(nums,left,right);
//在数组的左半边玩荷兰国旗问题,把数组变得有序
process(nums,left,flag[0] - 1);
//在数组的右半边玩荷兰国旗问题,把数组变得有序
process(nums,flag[1] + 1,right);
}
public static void quickSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
process(nums,0,nums.length - 1);
}
其实我们还有一种算法,是快速排序的另一种思想,但是也是分治思想
还是设置一个标识位,记为 temp ,在数组中使用left和right下标遍历数组中的所有元素,left指针开始从下标为0的元素向右遍历,right指针开始从下标为nums.length - 1的元素向左遍历。如果在left指针在遍历数组的途中,如果array[left] < temp left指针就就继续向右遍历 即left++,否则就停下,right指针也是同理,如果在right指针在遍历数组的途中,如果array[right] > temp ,right指针就继续向左遍历 即right++,否则就停下来,那么此时的nums[left] > temp nums[right] < temp ,那么此时的nums[left] 和 nums[right] 交换就就满足了继续遍历下去的条件,如果此时的left >= right,那么此时就停止遍历,并且把标志位temp 和 nums[left]做交换,此时的nums[left] 和 nums[right]是相同的,swap(nums,temp所在的下标,left) 或者 swap(nums,temp所在的下标,right)。
详细图例:


相关代码:
//快速排序
public static void quickSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
quickSort(nums,0,nums.length - 1);
}
public static void quickSort(int []nums,int left,int right){
if(left >= right){
return;
}
int part = getProcess(nums,left,right);
quickSort(nums,left,part - 1);
quickSort(nums,part + 1,right);
}
private static int getProcess(int[] nums, int left, int right) {
int cur = left;
int temp = nums[left];
while(left < right){
while(left < right && nums[right] >= temp){
right--;
}
while(left < right && nums[left] <= temp){
left++;
}
if(left < right){
swap(nums,left,right);
}
}
swap(nums,cur,left);
return left;
}
public static void swap(int []nums,int x,int y){
int temp = nums[x];
nums[x] = nums[y];
nums[y] = temp;
}
public static void main(String[] args) {
int []nums = {6 ,1 ,2, 7, 9, 3, 4, 5, 10, 8};
quickSort(nums);
System.out.println(Arrays.toString(nums));
}
快速排序的时间复杂度:
其实我们可以看到,我们在写代码的时候,是不是不行的构成了一棵递归树。

那么这个递归树的高度就是logn高度,那么此时一共有n个元素,在排序,那么此时的时间复杂度就为O(n * logn) 其实博主感觉面向找工作的编程,我们知道时间复杂度这样算的就可以了,不需要大量的数学运算。但是我们计算的这个时间复杂度时平均的时间复杂度,最坏的时间复杂度为O(n ^ 2) 为什么呢?如果当原来的数组就是一个有序的呢?
快速排序的空间复杂度: O(logn)
快速排序的稳定性: 稳定因为我们在排序的时候,相同的数据,没有打乱他们的位置。
while(left < right && nums[right] >= temp){ //因为这里的等于 ,如果要改成不稳定的也是可以滴
right--;
}
while(left < right && nums[left] <= temp){
left++;
}
9.快速排序2.0版本(挖坑法)
算法思想: 我们此时记此时数组最左边的位置的元素,为基准位,那么此时使用一个变量temp标记这个标记位,即temp = nums[left];
那么我们就可以想象此时原本的这个nums[left] 一个空位,那么这个位置就是一个坑 。假设我们此时要把数组中的所有元素排序之后,为一个升序的元素序列。那么此时数组的左边就是小于temp的位置,数组的右半边就是大于temp的位置。
- 设置两个指针 两个指针分别为 left 和 right。
- 先从原数组的右边开始遍历,如果遇到了比temp大于或者等于的数组元素,即nums[right] >= temp 那么就继续向左遍历 即 right–.如果在向左遍历的过程中,遇到了比 temp 小的元素,即 nums[right] < temp 那么此时就要添坑啦! nums[left] = nums[right] 那么这个较小的元素就跑到了数组的左半边。那么此时的right指针所在的位置就是一个坑,然后我们在遍历左半边数组的时候,在添上这个坑。
- 那么此时就到了left指针向右遍历,如果left指针在遍历数组时候,此时的nums[left] < temp 那么就继续向右开始遍历,如果此时的nums[left] > temp 那就把这个left指针指向的元素,填到上面的nums[right]坑中,那么此时的left指针指向的元素又变成了一个坑,继续遍历右边的数组,填上left指针指向的这个坑。
- 一直循环 2 3 步骤,直到left == right的时候,跳出循环,那么此时就把这个left 和 right共同指向的坑位,让temp占据 即 nums[left] = temp 或者 nums[right] = temp
- 这样在数组中temp的右边都是大于temp的元素,temp的左边的元素都是比temp小的元素,即temp这个元素就找到了自己在这个数组中排好位置。
详细图例:


时间复杂度: 其实这个算法的时间复杂度还是O(n * logn) 还是形成了一个递归树,它的高度为logn,一共有n个元素。此时时间复杂度为 O(n * logn)
空间复杂度: O(logn)
稳定性: 稳定,我们要知道稳定的算法可以改成不稳定的,但是本身就是不稳定的算法是不能改成稳定的!!!
相关代码:
public static void quickSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
quickSort(nums,0,nums.length - 1);
}
public static void quickSort(int []nums,int left,int right){
if(left >= right){
return;
}
int part = getPart(nums,left,right);
quickSort(nums,left,part - 1);
quickSort(nums,part + 1,right);
}
//挖坑法
private static int getPart(int[] nums, int left, int right) {
int temp = nums[left];
while(left < right){
while(left < right && nums[right] >= temp){
right--;
}
nums[left] = nums[right];
while(left < right && nums[left] <= temp){
left++;
}
nums[right] = nums[left];
}
nums[left] = temp;
return left;
}
public static void main(String[] args) {
int []nums = {6 ,1 ,2, 7, 9, 3, 4, 5, 10, 8};
quickSort(nums);
System.out.println(Arrays.toString(nums));
}
10.快速排序 3.0版本(随机取数法)
我们此时可以想一想,快速排序的最坏的情况下,以上这些算法的时间复杂度是多少? 博主可以告诉各位老铁们,它的时间复杂度为O(n ^ 2) 那么为什么呢?
不好想就直接上图:


我们使用荷兰国旗版本的快速排序举例,只需要改改标志位就可以了。
public static int []helaiflag(int []nums,int left,int right){
if(left > right){
return new int[]{-1,-1};
}
if(left == right){
return new int[]{left,right};
}
int less = left - 1;
int index = left;
int more = right;
while(index < more){
//等于区,遍历到和nums[right]相同的元素,也就是等于去的元素,直接index++
if(nums[index] == nums[right]){
index++;
}else if(nums[index] < nums[right]){
//小于区 ,遍历到比nums[right]小的元素,那么此时就把下标为index的元素和++less位置中的元素做交换,++less是因为原来的less指向的下标为-1,然后再把index++,也就是和小于区的右一个元素做交换
swap(nums,index++,++less);
}else{
//大于区
//当index遍历到 nums[index] > nums[right]的时候,和大于区的左边的一个元素做交换
swap(nums,index,--more);
}
}
//那么此时除了nums[right]以外,我们已经把数组分成了3分,因为此时的nums[right]和等于区的元素大小相同,并且此时index == more,那么此时就swap(nums,more,right)
swap(nums,more,right);
//此处返回的是等于区的下标区间
return new int[]{less+1,more};
}
private static void swap(int[] nums, int x, int y) {
int temp = nums[x];
nums[x] = nums[y];
nums[y] = temp;
}
public static void process(int []nums,int left,int right){
if(left >= right){
return;
}
//更换原有数组中元素的位置,在这里我们以数组中最右边的元素作为标志位,那么此时这样一换,就有几率此时我们的nums[right]不是此时数组中最大的一个,或者是最小的一个,那么就把时间复杂度为O(n ^ 2) 的几率降低
swap(nums, left + (int) (Math.random() * (right - left + 1)), right);
//玩荷兰国旗问题把数组分成 小于 等于 大于 三份
int []flag = helaiflag(nums,left,right);
//在数组的左半边玩荷兰国旗问题,把数组变得有序
process(nums,left,flag[0] - 1);
//在数组的右半边玩荷兰国旗问题,把数组变得有序
process(nums,flag[1] + 1,right);
}
public static void quickSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
process(nums,0,nums.length - 1);
}
综合所述,我们的快速排序时候于排那中非常乱序的数组。
11.堆排序
大顶堆,小顶堆定义:
首先我们说一下堆的定义:其实就是一个完全二叉树,大家肯定知道完全二叉树的的定义吧。就是在一棵树的节点,根据层数依次从左到右排列,呵,还是不懂? 直接看图!
完全二叉树:

小顶堆: 其实就是在完全二叉树的定义上再加了一个限制条件,就是在这个完全二叉树中每棵子树的根节点都是这棵子树中最小的一个节点(针对的是value值)
图例:

大顶堆: 其实就是在完全二叉树的定义上再加了一个限制条件,就是在这个完全二叉树中每棵子树的根节点都是这棵子树中最大的一个节点(针对的是value值)
图例:

创建一个大/小顶堆:
这里我们以创建大顶堆为例:
public class TestDemo9 {
public static class MyMaxHeap {
private int[] heap;
private final int limit;
private int heapSize;
public MyMaxHeap(int limit) {
heap = new int[limit];
this.limit = limit; //limit表示的是这个大顶堆中最多可以装下多找个数
heapSize = 0; //表示的是堆中元素的多少
}
//判断大顶堆是否为空
public boolean isEmpty() {
return heapSize == 0;
}
//判断大顶堆是否是满的
public boolean isFull() {
return heapSize == limit;
}
//在堆中添加元素
public void push(int value) {
//如果是的堆已经满了,那么就抛出异常
if (heapSize == limit) {
throw new RuntimeException("heap is full");
}
//在数组的尾部添加元素
heap[heapSize] = value;
heapInsert(heap, heapSize++);
}
//在堆中删除元素,我们默认删除的是堆顶元素,然后再进行调整
public int pop() {
int ans = heap[0];
swap(heap, 0, --heapSize);
heapify(heap, 0, heapSize);
return ans;
}
private void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
// 从index位置,往下看,不断的下沉,
// 停:我的孩子都不再比我大;已经没孩子了
private void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1;
while (left < heapSize) {
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index) {
break;
}
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
private void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
public static void main(String[] args) {
MyMaxHeap myMaxHeap = new MyMaxHeap(10);
myMaxHeap.heap = new int[10];
int []nums = {1,5,8,69,6,3,5,6,7,4};
for(int i = 0;i < nums.length;i++){
myMaxHeap.heapInsert(nums,i);
}
System.out.println(Arrays.toString(nums));
}
}
我们此时详解一下这个插入到大顶堆元素的方法
private void heapInsert(int[] arr, int index) {
//此时这个index表示新加入到堆中的元素下标,那么在堆中就可以找到这个亲加入节点的父亲节点,判断两个元素的大小
while (arr[index] > arr[(index - 1) / 2]) {
//如果新加入的元素 > 这个下标元素的父亲节点。然后判断此时交换元素之后,对上面子树的影响
swap(arr, index, (index - 1) / 2);
//向上
index = (index - 1) / 2;
}
}
图例:

对在大顶堆中删除元素做详解:
public int pop() {
int ans = heap[0]; //使用ans标记堆顶元素 heap[0],作为返回值
swap(heap, 0, --heapSize); //堆顶元素和堆尾元素做交换,然后堆中的元素减少一个,其实就是减去了堆顶元素的在堆中的站位
heapify(heap, 0, heapSize); //向下调整
return ans;//返回堆顶元素
}
图例:

堆排序思想: 那么现在我们现在说一下堆排序吧。
思想1: 首先我们要根据原本的数组创建出一个大顶堆。 在这个大顶堆中要保证每棵子树的根节点都是这棵子树中最大的一个节点中的值。
思想2: 然后我们删除堆顶元素,把堆顶元素和堆尾元素(这里说的堆尾其实就是大顶堆中最后一层中的最后一个元素)交换。在交换之后,然后又重新整理大顶堆,因为在交换之后,必定会打乱大顶堆。然后把大顶堆中的元素个数减一。依次循环,直到最后数组有序。
堆排序图例:


堆排序代码:
public class TestDemo4 {
//创建一个大顶柜
//在大顶堆中 整个二叉树是一个完全二叉树
//并且在二叉树中首个元素,也就是堆顶元素,是这个完全二叉树中最大的元素
public static void heapSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
//那么此时的heapInsert方法的时间复杂度为O(logn)
//那么此时就是 n * logn
//把数组中的元素添加到堆中,在添加的过程中,每次都进行整理,向上
// for(int i = 0;i < nums.length;i++){
// heapInsert(nums,i);
// }
//还有一种方法就是在所有的元素都添加到array中,之后,我们此时在这个数组中进行调整
//从树的底部开始遍历,如果遍历到的这个元素,计算出它的左右子树的节点的最大值,如果此时这个根节点的值小于这个最大值,那么此时就要把这两个元素交换
for(int i = nums.length - 1; i >= 0;i--){
heaplify(nums,i,nums.length);
}
//那么此时这颗树就是一棵大顶堆
int size = nums.length;
swap(nums,0,--size); //交换堆顶元素和堆尾元素
//在交换完之后,那么此时的堆可能不是一个大顶堆。那么此时就要进行调整,在调整之后再进行把堆中的第一个元素和堆尾的元素交换--size
while(size > 0){
heaplify(nums,0,size);
swap(nums,0,--size);
}
}
//向下调整
public static void heaplify(int []array,int index,int size){
int left = index * 2 + 1; //表示的是左边节点的下标
while(left < size){
//判断此时这个节点它有没有右子节点,如果有的话,那么就计算出两个节点的最大值
int large = left + 1 < size && array[left + 1] > array[left] ? left+1 : left;
//得到上面求的最大值的下标。如果此时的这个下标,就是我们的index那么就直接跳出,就不许要进行调整
large = array[large] > array[index] ? large : index;
if(large == index){
break;
}
//把两个下标的是交换
swap(array,large,index);
index = large;
left = 2 * index + 1; //向下
}
}
//向上调整
public static void heapInsert(int []array,int index){
while(index < array.length){
//如果在一棵树中它的子节点比他的父节点大,那么此时就要进行调整
if(array[index] > array[(index - 1)/ 2]){
swap(array,index,(index - 1) / 2); //交换
}
index = (index - 1) / 2; //向上
}
}
public static void swap(int []array,int x,int y){
array[x] = array[x] ^ array[y];
array[y] = array[x] ^ array[y];
array[x] = array[x] ^ array[y];
}
//堆排序
//在堆排序过程中,首先要把创建一个大顶堆,然后得到堆顶元素,把堆顶元素和堆尾的元素进行交换,然后除了堆尾元素,然后把其他的元素都进行向下调整
public static void main(String[] args) {
int []nums = {7,8,9,4,5,6,1,2,3};
heapSort(nums);
System.out.println(Arrays.toString(nums));
}
}
时间复杂度: O(n * logn)
空间复杂度:O(1)
稳定性:不稳定
有名的Topk问题: 215. 数组中的第K个最大元素 - 力扣(LeetCode)

解题分析: 有些同学第一次拿到这个题的时候可能会想,呵,这不就很简单嘛,不就是把所有的元素都排序(升序排序),排序之后找到倒数第k个元素就可以了嘛。但是如果你使用冒泡排序光是排序就是O(n ^ 2) 选择排序O(n ^ 2) 快速排序 O(n * logn) 插入排序 O(n * logn) 归并排序O(n * logn) 那么这些都不符合我们这个题目要求的时间复杂度必须要在O(n) 我们已经在上面的文章中学过堆排序,向堆排序靠靠。这里提供一个类 在 Java中封装了一个优先队列PriorityQueue,我们实例化一个对象,默认这个queue是小顶堆。
PriorityQueue< Integer> queue = new PriorityQueue<>(). 其实解这道题的步骤很简单。在题目中我们不是要找到数组中的第k个元素嘛。我们限制在这个小顶堆中添加的元素个数。在添加完k个元素之后,如果仍然要在堆中添加元素,那么就使用堆顶元素和将要添加到堆中的元素比较。我们记这个即将要添加到堆中的元素为 temp 堆顶为heap[0].那么此时的heap[0],就是在这个有k个元素的堆中最小的一个。如果temp > heap[0] ,那么把堆顶元素删除,把这个temp添加到堆中。
图例:

解题代码:
class Solution {
public int findKthLargest(int[] nums, int k) {
if(nums.length == 0){
return -1;
}
if(k == 0){
return -1;
}
PriorityQueue<Integer> queue = new PriorityQueue<>();
for(int i = 0;i<nums.length;i++){
if(i < k){
queue.offer(nums[i]);
}else{
int num = queue.peek(); //得到堆顶元素
if(num < nums[i]){ //将要添加到堆中的元素 > 堆顶元素
queue.poll(); //删除堆顶元素
queue.offer(nums[i]); //在堆中插入元素
}
}
}
return queue.peek(); //那么此时堆顶元素就是这个堆中的第k大的元素
}
}
时间复杂度分析: 二叉堆插入和删除的时间复杂度和堆中的元素个数有关,在这里我们堆的大小不会超过
k,所以插入和删除元素的复杂度是O(logK),再套一层 for 循环,总的时间复杂度就是O(NlogK)。
12.计数排序
接下来我们要说的是两种不基于比较交换的排序,一种是计数排序,另一种是基数排序。这两种排序的时间复杂度都是O(n),但是这两种排序都有各自的缺点。如果我们在以后的面试题中如果需要写有关排序的算法,除了重点说明之外,那么我们都是用基于比较和交换的排序算法。否则就是用基数排序和计数排序。
计数排序思想: 其实博主感觉这个计数排序是所有的排序算法中最简单的一个,不信,那那就看看吧,绝对简单到离谱!!!
其实大的思想就是桶排序 假设我们在这个排序中不考虑负数,在待排序的数组中,使用一个指针遍历该数组,找到数组中最大的元素 max ,然后创建出一个数组bruck这个数组的长度为 max + 1 把原数组的每个下标中的值,作为这个的下标。如果这个下标在原数组nums中存在,那么就标记这个bruck[nums[i]]++,那么此时bruck数组已经利用自身的下标排序好了nums数组中的所有元素,然后我们在把bruck数组中非0的元素对应的下标写到nums中,那么此时的nums中就是排序好的元素。
计数排序图例:


计数排序有关代码:
public class TestDemo4 {
public static void countSort(int []nums){
if(nums == null || nums.length == 0){
return;
}
int max = Integer.MIN_VALUE;
for(int i = 0;i < nums.length;i++){
max = Math.max(max,nums[i]);
}
int []bruck = new int[max + 1];
//标记
for(int i = 0;i < nums.length;i++){
bruck[nums[i]]++;
}
int i = 0;
//下标打回原数组
for(int j = 0;j < bruck.length;j++){
while(bruck[j]-- > 0){
nums[i++] = j;
}
}
}
public static void main(String[] args) {
int []nums = {10,5,8,6,9,3,1,4};
countSort(nums);
System.out.println(Arrays.toString(nums));
}
}
**计数排序的缺点:**不知道大家有没有注意到这个排序的弊端,其实我们在上述图例的时候,已经表现出来的,就是容易造成空间浪费。就是在这个排序中要找到数组中的最大值,如果此时这个较大的是是21 0000 0000 0000 0000 在原数组中还包括 1 ,2 ,3 ,那么这个排序算法就会傻傻的为我们创建出好大好大的数组空间,这个老大的数组的空间要21 0000 0000 0000 0000大,但是我们比较这4个数,想想都好笑😂😂😂😂😂,其实这种排序算法应用的场景是在待排序数组中最大数字不是特别大,元素和元素之间相差不大的序列。其实这种排序算法也不常用,写写就头一乐呵。😏😏😏❤️❤️❤️
193.基数排序
基数排序思想: 其实计数排序的思想非常简单,就是遍历数组在数组中找到最大的元素,然后在得到这个最大元素的数位有几个。例如此时的待排序数组有[20,2,8,90,521] 此时遍历数组的得到的最大值为512 ,得到的数位有3位。然后从每个元素的个位开始向最高位开始遍历,我们建十个队列分别表示此时 数位数组是0的队列,1的队列,2的队列…9的队列,那么在十进制位中只有从0 ~ 9呀,所以我们创建出10个队列。然后20的个位数为 0 ,2的个位数为2,8的个位数为8,90的个位数为0,521的个位数为1. 那么此时就排序的结果为 20 90 521 2 8 ,这个排序结果此时是每个元素中的个位数比较并排序的结果。然后在根据每个元素的十位数开始排序得到的结果为 [2,8,20,521,90],然后再根据百位数进行排序最终的结果为[2,8,20,90,521].那么数组此时已经有序了。
基数排序图例:

基数排序代码:
但是此时这个基数排序可不好写哦。那么有些童鞋就说为什么呢?哈哈😃😃😃❤️❤️其实是已经为如果我们要为每个数位创建出0~9数位值的队列,是不是有点浪费空间了,并且在我们的动图中也会看到有些队列根本就没有使用到.
其实使用10个队列也不是不可以,博主就感觉太麻烦了。
public class TestDemo {
//在我们的这个代码中不考虑负数
public static void radixSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
radixSort(arr, 0, arr.length - 1, maxbits(arr));
}
//这个方法的算法思想就是 在数组中得到最大的元素,然后得到最大元素的数位个数。
public static int maxbits(int[] arr) {
int max = Integer.MIN_VALUE;
//得到最大值
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);
}
int res = 0;
//得到数位
while (max != 0) {
res++;
max /= 10;
}
return res;
}
// arr[l..r]排序 , digit
// l..r 3 56 17 100 3
public static void radixSort(int[] arr, int L, int R, int digit) {
final int radix = 10;
int i = 0, j = 0;
// 有多少个数准备多少个辅助空间
int[] help = new int[R - L + 1];
for (int d = 1; d <= digit; d++) { // 有多少位就进出几次
// 10个空间
// count[0] 当前位(d位)是0的数字有多少个
// count[1] 当前位(d位)是(0和1)的数字有多少个
// count[2] 当前位(d位)是(0、1和2)的数字有多少个
// count[i] 当前位(d位)是(0~i)的数字有多少个
int[] count = new int[radix]; // count[0..9]
for (i = L; i <= R; i++) {
// 103 1 3
// 209 1 9
j = getDigit(arr[i], d); //从右向左得到每个元素中的数位值。 例如此时 getDigit(103,1) 得到的就是个位上的数位值为3
count[j]++; //比较每一个数位值出现的次数
}
//更新count数组为此时小于i的数位在数组中有几个。
for (i = 1; i < radix; i++) {
count[i] = count[i] + count[i - 1];
}
for (i = R; i >= L; i--) {
j = getDigit(arr[i], d);
help[count[j] - 1] = arr[i];
count[j]--;
}
for (i = L, j = 0; i <= R; i++, j++) {
arr[i] = help[j];
}
}
}
public static int getDigit ( int x, int d){
return ((x / ((int) Math.pow(10, d - 1))) % 10);
}
public static void main(String[] args) {
int []nums = {2,90,20,8,512};
radixSort(nums);
System.out.println(Arrays.toString(nums));
}
}
代码分析:

14 李珣版 爱心代码
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE> New Document </TITLE>
<META NAME="Generator" CONTENT="EditPlus">
<META NAME="Author" CONTENT="">
<META NAME="Keywords" CONTENT="">
<META NAME="Description" CONTENT="">
<style>
html, body {
height: 100%;
padding: 0;
margin: 0;
background: #000;
}
canvas {
position: absolute;
width: 100%;
height: 100%;
}
</style>
</HEAD>
<BODY>
<canvas id="pinkboard"></canvas>
<script>
/*
* Settings
*/
var settings = {
particles: {
length: 500, // maximum amount of particles
duration: 2, // particle duration in sec
velocity: 100, // particle velocity in pixels/sec
effect: -0.75, // play with this for a nice effect
size: 30, // particle size in pixels
},
};
/*
* RequestAnimationFrame polyfill by Erik Möller
*/
(function(){var b=0;var c=["ms","moz","webkit","o"];for(var a=0;a<c.length&&!window.requestAnimationFrame;++a){window.requestAnimationFrame=window[c[a]+"RequestAnimationFrame"];window.cancelAnimationFrame=window[c[a]+"CancelAnimationFrame"]||window[c[a]+"CancelRequestAnimationFrame"]}if(!window.requestAnimationFrame){window.requestAnimationFrame=function(h,e){var d=new Date().getTime();var f=Math.max(0,16-(d-b));var g=window.setTimeout(function(){h(d+f)},f);b=d+f;return g}}if(!window.cancelAnimationFrame){window.cancelAnimationFrame=function(d){clearTimeout(d)}}}());
/*
* Point class
*/
var Point = (function() {
function Point(x, y) {
this.x = (typeof x !== 'undefined') ? x : 0;
this.y = (typeof y !== 'undefined') ? y : 0;
}
Point.prototype.clone = function() {
return new Point(this.x, this.y);
};
Point.prototype.length = function(length) {
if (typeof length == 'undefined')
return Math.sqrt(this.x * this.x + this.y * this.y);
this.normalize();
this.x *= length;
this.y *= length;
return this;
};
Point.prototype.normalize = function() {
var length = this.length();
this.x /= length;
this.y /= length;
return this;
};
return Point;
})();
/*
* Particle class
*/
var Particle = (function() {
function Particle() {
this.position = new Point();
this.velocity = new Point();
this.acceleration = new Point();
this.age = 0;
}
Particle.prototype.initialize = function(x, y, dx, dy) {
this.position.x = x;
this.position.y = y;
this.velocity.x = dx;
this.velocity.y = dy;
this.acceleration.x = dx * settings.particles.effect;
this.acceleration.y = dy * settings.particles.effect;
this.age = 0;
};
Particle.prototype.update = function(deltaTime) {
this.position.x += this.velocity.x * deltaTime;
this.position.y += this.velocity.y * deltaTime;
this.velocity.x += this.acceleration.x * deltaTime;
this.velocity.y += this.acceleration.y * deltaTime;
this.age += deltaTime;
};
Particle.prototype.draw = function(context, image) {
function ease(t) {
return (--t) * t * t + 1;
}
var size = image.width * ease(this.age / settings.particles.duration);
context.globalAlpha = 1 - this.age / settings.particles.duration;
context.drawImage(image, this.position.x - size / 2, this.position.y - size / 2, size, size);
};
return Particle;
})();
/*
* ParticlePool class
*/
var ParticlePool = (function() {
var particles,
firstActive = 0,
firstFree = 0,
duration = settings.particles.duration;
function ParticlePool(length) {
// create and populate particle pool
particles = new Array(length);
for (var i = 0; i < particles.length; i++)
particles[i] = new Particle();
}
ParticlePool.prototype.add = function(x, y, dx, dy) {
particles[firstFree].initialize(x, y, dx, dy);
// handle circular queue
firstFree++;
if (firstFree == particles.length) firstFree = 0;
if (firstActive == firstFree ) firstActive++;
if (firstActive == particles.length) firstActive = 0;
};
ParticlePool.prototype.update = function(deltaTime) {
var i;
// update active particles
if (firstActive < firstFree) {
for (i = firstActive; i < firstFree; i++)
particles[i].update(deltaTime);
}
if (firstFree < firstActive) {
for (i = firstActive; i < particles.length; i++)
particles[i].update(deltaTime);
for (i = 0; i < firstFree; i++)
particles[i].update(deltaTime);
}
// remove inactive particles
while (particles[firstActive].age >= duration && firstActive != firstFree) {
firstActive++;
if (firstActive == particles.length) firstActive = 0;
}
};
ParticlePool.prototype.draw = function(context, image) {
// draw active particles
if (firstActive < firstFree) {
for (i = firstActive; i < firstFree; i++)
particles[i].draw(context, image);
}
if (firstFree < firstActive) {
for (i = firstActive; i < particles.length; i++)
particles[i].draw(context, image);
for (i = 0; i < firstFree; i++)
particles[i].draw(context, image);
}
};
return ParticlePool;
})();
/*
* Putting it all together
*/
(function(canvas) {
var context = canvas.getContext('2d'),
particles = new ParticlePool(settings.particles.length),
particleRate = settings.particles.length / settings.particles.duration, // particles/sec
time;
// get point on heart with -PI <= t <= PI
function pointOnHeart(t) {
return new Point(
160 * Math.pow(Math.sin(t), 3),
130 * Math.cos(t) - 50 * Math.cos(2 * t) - 20 * Math.cos(3 * t) - 10 * Math.cos(4 * t) + 25
);
}
// creating the particle image using a dummy canvas
var image = (function() {
var canvas = document.createElement('canvas'),
context = canvas.getContext('2d');
canvas.width = settings.particles.size;
canvas.height = settings.particles.size;
// helper function to create the path
function to(t) {
var point = pointOnHeart(t);
point.x = settings.particles.size / 2 + point.x * settings.particles.size / 350;
point.y = settings.particles.size / 2 - point.y * settings.particles.size / 350;
return point;
}
// create the path
context.beginPath();
var t = -Math.PI;
var point = to(t);
context.moveTo(point.x, point.y);
while (t < Math.PI) {
t += 0.01; // baby steps!
point = to(t);
context.lineTo(point.x, point.y);
}
context.closePath();
// create the fill
context.fillStyle = '#ea80b0';
context.fill();
// create the image
var image = new Image();
image.src = canvas.toDataURL();
return image;
})();
// render that thing!
function render() {
// next animation frame
requestAnimationFrame(render);
// update time
var newTime = new Date().getTime() / 1000,
deltaTime = newTime - (time || newTime);
time = newTime;
// clear canvas
context.clearRect(0, 0, canvas.width, canvas.height);
// create new particles
var amount = particleRate * deltaTime;
for (var i = 0; i < amount; i++) {
var pos = pointOnHeart(Math.PI - 2 * Math.PI * Math.random());
var dir = pos.clone().length(settings.particles.velocity);
particles.add(canvas.width / 2 + pos.x, canvas.height / 2 - pos.y, dir.x, -dir.y);
}
// update and draw particles
particles.update(deltaTime);
particles.draw(context, image);
}
// handle (re-)sizing of the canvas
function onResize() {
canvas.width = canvas.clientWidth;
canvas.height = canvas.clientHeight;
}
window.onresize = onResize;
// delay rendering bootstrap
setTimeout(function() {
onResize();
render();
}, 10);
})(document.getElementById('pinkboard'));
</script>
</BODY>
</HTML>



![[ros2实操]2-ros2的消息和ros1的消息转换](https://img-blog.csdnimg.cn/562035ea8b8542798295ca21d9a0228d.png)
![[附源码]SSM计算机毕业设计基于ssm的电子网上商城JAVA](https://img-blog.csdnimg.cn/834b864897154020a15fa78220c5ff6f.png)