swift提供了3种不同的API来绑定/重新绑定指针
- assumingMemoryBound(to:)
- bindMemory(to: capacity:)
- withMemoryRebound(to: capacity: body:)
绕过编译器检查 - assumingMemoryBound
就是假定内存绑定
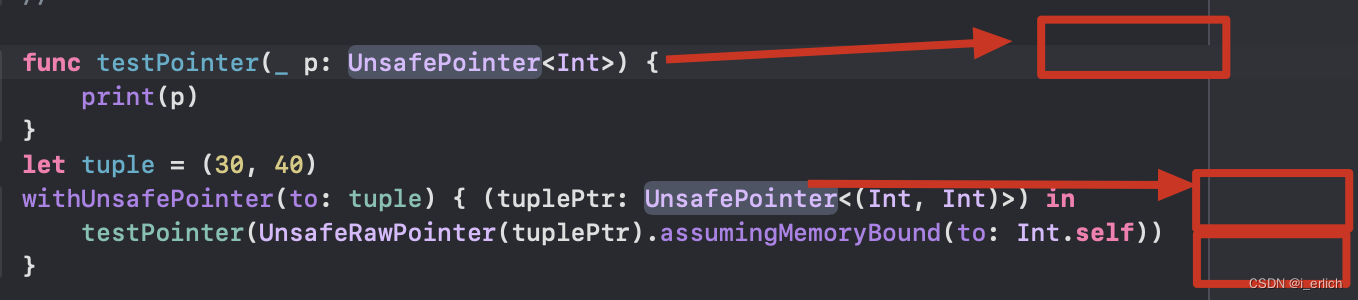
func testPointer(_ p: UnsafePointer<Int>) {
print(p)
}
let tuple = (30, 40)
withUnsafePointer(to: tuple) { (tuplePtr: UnsafePointer<(Int, Int)>) in
testPointer(UnsafeRawPointer(tuplePtr)
.assumingMemoryBound(to: Int.self))
}
结果
0x000000016fdff240
其实 两者本质没什么区别,都是指向内存的指针
UnsafePointer 指向1块Int内存
UnsafePointer<Int, Int> 指向一个元组tuple内存, 也就是一块连续的内存,包含连个连续的Int
两者都是首地址
一种方式就是不 强转 UnsafePointer<Int, Int> 为 UnsafePointer
- 先把 元组指针转换成原始指针 UnsafeRawPointer(tuplePtr)
- 原始指针调用 assumingMemoryBound 绑定成Int 指针 UnsafeRawPointer(tuplePtr).assumingMemoryBound(to: Int.self)
func testPointer(_ p: UnsafePointer<Int>) {
print(p[0])
print(p[1])
}
let tuple = (30, 40)
withUnsafePointer(to: tuple) { (tuplePtr: UnsafePointer<(Int, Int)>) in
testPointer(UnsafeRawPointer(tuplePtr).assumingMemoryBound(to: Int.self))
}
结果
30
40
assumingMemoryBound的意义在于:
有时候不想做指针类型转换来增加代码的复杂度
就可以调用 此api绕过编译器检查,但是并没有发生实际的指针转换
内存转换 - bindMemory
实际发生了转换,改变当前内存指针绑定的类型
func testPointer(_ p: UnsafePointer<Int>) {
print(p[0])
print(p[1])
}
let tuple = (30, 40)
withUnsafePointer(to: tuple) { (tuplePtr: UnsafePointer<(Int, Int)>) in
testPointer(UnsafeRawPointer(tuplePtr)
.bindMemory(to: Int.self, capacity: 1))
}
结果
30
40
bindMemory - 相比于assumingMemoryBound,就是改变内存绑定类型
临时改变内存绑定 - withMemoryRebound
func testPointer(_ p: UnsafePointer<Int8>) {
print(p)
}
let UInt8Ptr = UnsafePointer<UInt8>.init(bitPattern: 30)
UInt8Ptr?.withMemoryRebound(to: Int8.self, capacity: 1,
{ (Int8Ptr: UnsafePointer<Int8>) in
testPointer(Int8Ptr)
})
结果
0x000000000000001e
withMemoryRebound意义在于:
临时改变内存绑定,出了api 尾随闭包作用域之后,绑定就不存在了
最后,补充一个小tip
也许你会对swift 闭包 函数的语法形式感觉会不习惯,编译器也会自动直接转变为函数体
其实高级语言语法习惯仅仅就是一种语法而已
底层其实是函数栈的形式
一个函数 包括 函数名(也就是方法指针),多个参数,函数体(包含多个变量与调用)
内存表达函数的方式就是栈的形式:
入栈顺序: 函数指针,参数顺序入栈,函数体内部逐行顺序入栈
按照这个逻辑,最后一个尾随闭包参数就可以直接变为函数体,这样并不影响函数栈的入栈方式



![[Linux打怪升级之路]-环境变量](https://img-blog.csdnimg.cn/31e5b1c0a81e4ecea7bc0e9d301b3136.png)