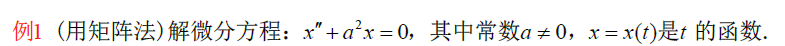1 transformer最经典的理解:
http://jalammar.github.io/illustrated-transformer/
2 位置编码
相对位置编码(relative position representation):https://zhuanlan.zhihu.com/p/397269153
Transformer中的相对位置编码(Relative Position Embedding):https://blog.csdn.net/chenf1995/article/details/122971023?spm=1001.2014.3001.5502
Swin Transformer之相对位置编码详解:https://zhuanlan.zhihu.com/p/577855860
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
3 理解,计算哪个词的注意力结果,就是以哪个词为位置中心进行计算,得到其他词的相对位置,相对位置也是直接查表,其他的词相对于中心词的位置不同,在加上词向量本身,就能得到不同的结果
如果我们以其中一个单词为中心,那么其有左边也有右边的单词,假设我们一个句子的长度为5,那么将有9个embedding向量可学习,一个embedding向量表示当前词,其中4个embedding向量用来表示其左边的单词,另外4个embedding向量来表示其左边的单词。为什么是9个embedding向量呢?因为我们在实际计算时候,5个单词都有可能作为中心词。上图中以第5个位置(索引为4)的单词为中心,那么其左边的单词的编号为:-1,-2,-3,-4,右边的单词的编号为:+1,+2,+3,+4 。
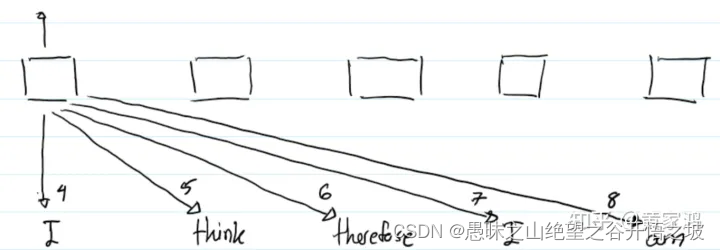
对于第一个位置的单词“I”,当transformer计算“I”跟“therefore”的attention信息时候,"therefore"会采用第6个位置编码,因为我们是以第4个索引为中心,“therefore”是位于“I”的右边相对于“I”的相对距离为2,所以其采用的是第6个embedding向量。
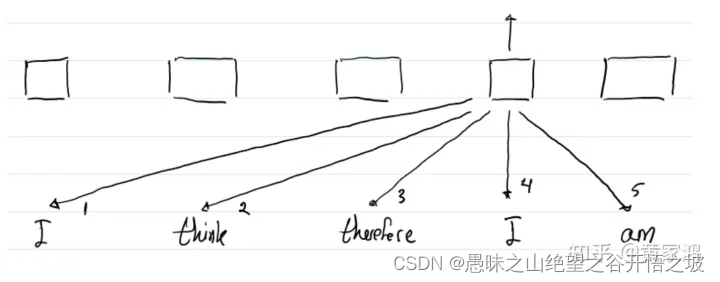
跟之前一样,当计算到第二个“I”和其他单词的attention信息时,如计算其跟左边“therefore”的attention信息,那么“therefore”采用的位置编码为第3个embedding向量,因为它在“I”的左边相对于“I”偏离1个距离,索引应该采用第3个embedding向量。
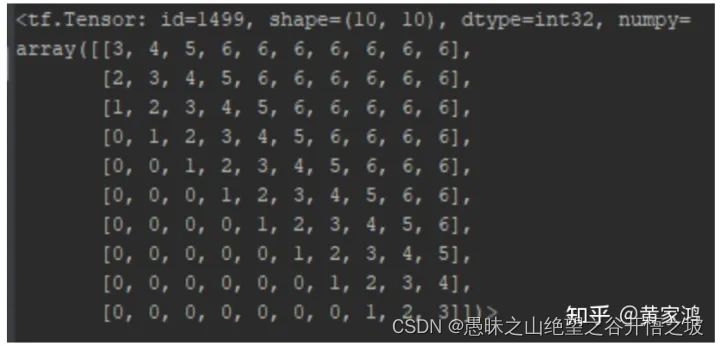
注意,有两个位置编码向量需要学习,一个是为了计算zi,一个是为了计算eij。最大的长度也会被考虑在内,如果我们中间索引为k,那么会有2k+1个相对位置编码向量需要学习,其中k个是其左边的,k个是其右边的,还有一个属于自己。如果长度超过2k+1,那么其右边超过k的全部置为k,左边超过k的全部置为0。下面是个长度为10的句子的例子,其中k=3,那么它到相对位置编码表中拿向量的索引为:
这么做的原因有:
1.作者认为超出范围的位置还采用精准的位置编码时没必要的
2.clip最大长度是的模型可以学到训练集中没见过的长度
3.1 对比,在计算过程融入相对位置信息即可



对比两种计算方式,比较容易看出来,其实是在计算zi的时候,计算完j跟权重w后加上i相对于j的相对位置编码。而在计算eij时候同理,计算完j跟权重w后加上ij的相对位置编码。注意这里两种权重矩阵是不同的,理解transformer中的q,k,v 这三个向量分别对应过去。