文章目录
- Pre
- 引言
- 案例
- 何谓查询分离?
- 何种场景下使用查询分离?
- 查询分离实现思路
- 1. 如何触发查询分离?
- 方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。
- 方式二:修改业务代码:在写入常规数据后,异步建立查询数据。
- 方式三: 监控数据库日志:如有数据变更,更新查询数据。
- 方案对比
- 适用场景
- 2. 如何实现查询分离?
- 3. 查询数据如何存储?
- 4. 查询数据如何使用?
- 整体方案
- 历史数据迁移
- 查询分离解决方案的不足

Pre
MySQL索引原理与优化指南:深入解析B+Tree与高效查询策略
MySQL - 事务隔离级别和锁的机制
MySQL - 读多写少场景下的优化数据查询方案
MySQL - 写多读少的场景下如何优化数据存储方案
MySQL - 冷热分离:表数据量大读写缓慢的优化方案
引言
MySQL - 冷热分离:表数据量大读写缓慢的优化方案中提到了冷热分离解决方案的性价比高,但它并不是一个最优的方案,仍然存在诸多不足,比如:查询冷数据慢、业务无法再修改冷数据、冷数据多到一定程度系统依旧扛不住,我们如果想把这些问题一一解决掉,可以用另外一种解决方案——查询分离。

注意:查询分离与读写分离还是有区别的
案例
某系统工单表中存放了几千万条数据,且查询工单表数据时需要关联十几个子表,每个子表的数据也是超亿条。
如此庞大的数据量,跟前面的冷热分离一样,每次查询数据时几十秒才能返回结果,即便使用了索引、SQL 等数据库优化技巧,效果依然不明显。
加上工单表中有些数据是几年前的,因业务原因,需要继续保持更新,因此无法将这些旧数据封存到别的地方,也就没法通过前面的冷热分离方案来解决。
最终采用了查询分离的解决方案,才得以将这个问题顺利解决:将更新的数据放在一个数据库里,而查询的数据放在另外一个系统里。因为数据的更新都是单表更新,不需要关联也没有外键,所以更新速度立马得到提升,数据的查询则通过一个专门处理大数据量的查询引擎来解决,也快速地满足了需求。
通过这种解决方案处理后,每次查询数据时,500ms 内就可得到返回结果。
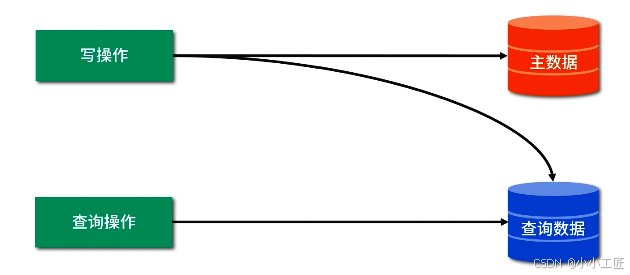
何谓查询分离?
每次写数据时保存一份数据到另外的存储系统里,用户查询数据时直接从另外的存储系统里获取数据,示意图如下:
何种场景下使用查询分离?
当在实际业务中遇到以下情形,则可以考虑使用查询分离解决方案。
-
数据量大;
-
所有写数据的请求效率尚可;
-
查询数据的请求效率很低;
-
所有的数据任何时候都可能被修改;
-
业务希望我们优化查询数据的功能。
查询分离实现思路
查询分离解决方案的实现思路如下:
-
如何触发查询分离?
-
如何实现查询分离?
-
查询数据如何存储?
-
查询数据如何使用?
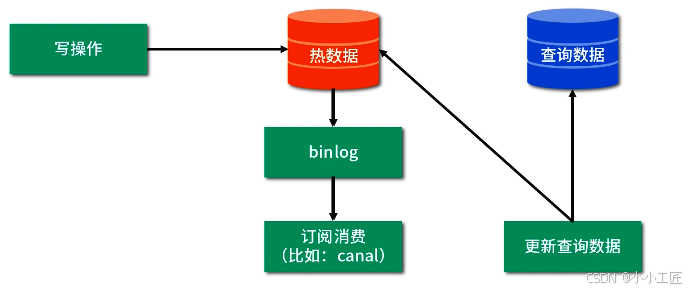
1. 如何触发查询分离?
这个问题说明的是我们应该在什么时候保存一份数据到查询数据中,即什么时候触发查询分离这个动作。
一般来说,查询分离的触发逻辑分为 3 种。
方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。

方式二:修改业务代码:在写入常规数据后,异步建立查询数据。
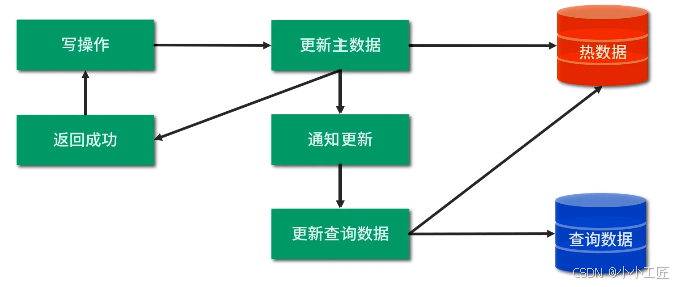
方式三: 监控数据库日志:如有数据变更,更新查询数据。
方案对比

适用场景

2. 如何实现查询分离?
以上共3 种触发逻辑,第 1 种是同步建立查询数据的过程比较简单,这里就不展开说明,接下来我们主要围绕第 2 种来展开。
关于第 2 种触发方案:修改业务代码异步建立查询数据,最基本的实现方式是单独起一个线程建立查询数据,不过这种做法会出现如下情况:
-
写操作较多且线程太多,最终撑爆 JVM;
-
建查询数据的线程出错了,如何自动重试;
-
多线程并发时,很多并发场景需要解决。
面对以上三种情况,我们该如何处理?此时使用 MQ 管理这些线程即可解决。
MQ 的具体操作思路为每次主数据写操作请求处理时,都会发一个通知给 MQ,MQ 收到通知后唤醒一个线程更新查询数据
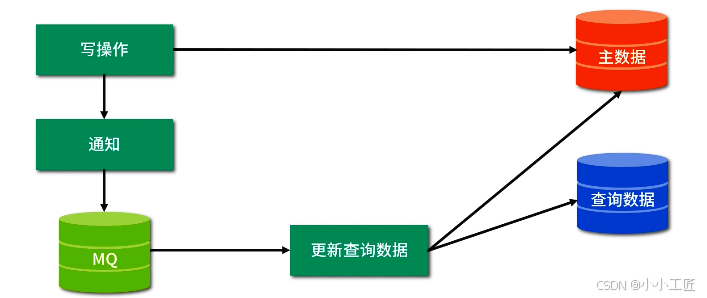
了解了 MQ 的具体操作思路后,还应该考虑以下 5 大问题。
问题一:MQ 如何选型?
从易用性和代码工作量角度考量即可。
问题二:MQ 宕机了怎么办?
如果 MQ 宕机了,我们只需要保证主流程正常进行,且 MQ 恢复后数据正常处理即可,具体方案分为三大步骤。
-
每次写操作时,在主数据中加个标识:
NeedUpdateQueryData=true,这样发到 MQ 的消息就很简单,只是一个简单的信号告知更新数据,并不包含更新的数据 id。 -
MQ 的消费者获取信号后,先批量查询待更新的主数据,然后批量更新查询数据,更新完后查询数据的主数据标识
NeedUpdateQueryData就更新成 false 了。 -
当然还存在多个消费者同时搬运动作的情况,这就涉及并发性的问题,因此问题冷热分离中的并发性处理逻辑类似。
问题三:更新查询数据的线程失败了怎么办?
如果更新的线程失败了,NeedUpdateQueryData 的标识就不会更新,后面的消费者会再次将有 NeedUpdateQueryData 标识的数据拿出来处理。但如果一直失败,我们可以在主数据中多添加一个尝试搬运次数,比如每次尝试搬运时 +1,成功后就清零,以此监控那些尝试搬运次数过多的数据。
问题四:消息的幂等消费
在编程中,一个幂等操作的特点是多次执行某个操作均与执行一次操作的影响相同。
举个例子,比如主数据的订单 A 更新后,我们在查询数据中插入了 A,可是此时系统出问题了,系统误以为查询数据没更新,又把订单 A 插入更新了一次。
所谓幂等,就是不管更新查询数据的逻辑执行几次,结果都是我们想要的结果。因此,考虑消费端并发性的问题时,我们需要保证更新查询数据幂等。
问题五:消息的时序性问题
比如某个订单 A 更新了 1 次数据变成 A1,线程甲将 A1 的数据搬到查询数据中。不一会儿,后台订单 A 又更新了 1 次数据变成 A2,线程乙也启动工作,将 A2 的数据搬到查询数据中。
所谓的时序性就是如果线程甲启动比乙早,但搬运数据动作比线程乙还晚完成,就有可能出现查询数据最终变成过期的 A1。如下图(动作前面的序号代表实际动作的先后顺序):
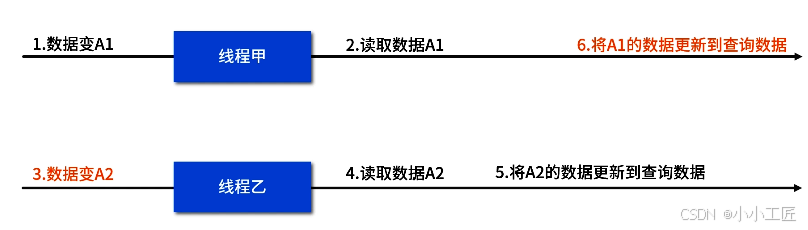
此时解决方案为主数据每次更新时,都更新上次更新时间 last_update_time,然后每个线程更新查询数据后,检查当前订单 A 的 last_update_time 是否跟线程刚开始获得的时间一样,且 NeedUpdateQueryData 是否等于 false,如果都满足的话,我们就将 NeedUpdateQueryData 改为 true,然后再做一次搬运。
MQ 在这里的作用只是一个触发信号的工具,如果不用 MQ 好像也没啥问题啊,但是MQ的作用不仅体现在这里,还有以下:
-
服务的解耦: 这样主业务逻辑就不会依赖更新查询数据这个服务了。
-
控制更新查询数据服务的并发量: 如果我们直接调用更新查询数据服务,因写操作速度快,更新查询数据速度慢,写操作一旦并发量高,会给更新查询数据服务造成超负荷压力。如果通过消息触发更新查询数据服务,我们就可以通过控制消息消费者的线程数来控制负载。
3. 查询数据如何存储?
我们应该使用什么技术存储查询数据呢?目前,市面上主要使用 Elasticsearch 实现大数据量的搜索查询,当然还可能会使用到 MongoDB、HBase 这些技术,这就需要我们对各种技术的特性了如指掌,再进行技术选型。
关于技术选型这个问题,很多时候我们不能单单只考虑业务功能的需求,还需要考虑组织结构。比如当初设计架构方案时,为什么选择用 Elasticsearch,除 ES 对查询的扩展性支持外,最关键的一点是团队对 Elasticsearch 很熟悉。
4. 查询数据如何使用?
因 ES 自带 API,所以使用查询数据时,我们在查询业务代码中直接调用 ES 的 API 就行。
不过,这个办法会出现一个问题:数据查询更新完前,查询数据不一致怎么办?
2 种解决思路。
-
在查询数据更新到最新前,不允许用户查询。(我们没用过这种设计,但我确实见过市面上有这样的设计。)
-
给用户提示:您目前查询到的数据可能是 1 秒前的数据,如果发现数据不准确,可以尝试刷新一下,这种提示用户一般比较容易接受。
整体方案
以上,我们已经把四个问题都讨论完了,我们再一起看下查询分离的整体方案,如下图所示:
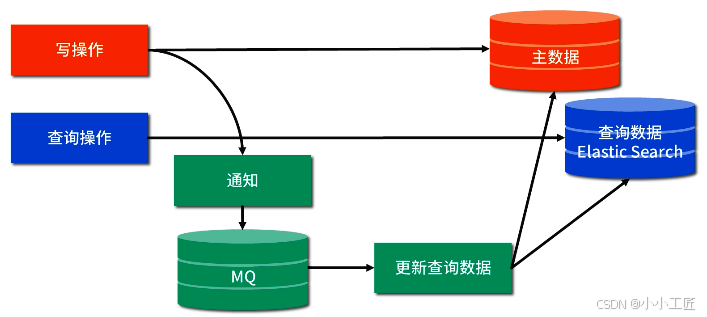
历史数据迁移
新的架构方案上线后,旧的数据如何适用新的架构方案?这是实际业务中需要我们考虑的问题。
在这个方案里,我们只需要把所有的历史数据加上这个标识:NeedUpdateQueryData=true,程序就会自动处理了。
查询分离解决方案的不足
查询分离这个解决方案虽然能解决一些问题,但我们也要清醒地认识到它的不足。
不足一: 使用 Elasticsearch 存储查询数据时,注意事项是什么 ?
不足二: 主数据量越来越大后,写操作还是慢,到时还是会出问题。
不足三: 主数据和查询数据不一致时,假设业务逻辑需要查询数据保持一致性呢?