目录
集合处理数据的弊端
Stream流的获取方式
对于Collection的实现类
对于Map
对于数组
Stream常用方法介绍
count
forEach
filter
limit
skip
map
sorted
distinct
match
find
max和min
reduce
mapToInt
concat
Stream结果收集
结果收集到集合中
结果收集到数组中
对流中的数据做聚合计算
对流中数据做分组操作
对流中的数据做分区操作
对流中的数据做拼接
并行的Stream流
串行的Stream流
并行流
线程安全问题
集合处理数据的弊端
当我们在需要对集合中的元素进行操作的时候,除了必需的添加,删除,获取外,最典型的操作就是 集合遍历
看这个例子:
public class StreamTest1 {
@Test
public void test() {
// 定义一个List集合
List<String> list = Arrays.asList("张三", "张三丰", "成龙", "周星驰");
// 1.获取所有 姓张的信息
List<String> list1 = new ArrayList<>();
for (String s : list) {
if (s.startsWith("张")) {
list1.add(s);
}
}
// 2.获取名称长度为3的用户
List<String> list2 = new ArrayList<>();
for (String s : list1) {
if (s.length() == 3) {
list2.add(s);
}
}
// 3. 输出满足条件的所有用户的信息
for (String s : list2) {
System.out.println(s);
}
}
}上面的代码针对与我们不同的需求总是一次次的循环循环循环.这时我们希望有更加高效的处理方式,这 时我们就可以通过JDK8中提供的Stream API来解决这个问题了。
Stream更加优雅的解决方案:
@Test
public void test2(){
List<String> list = Arrays.asList("张三", "张三丰", "成龙", "周星驰");
list.stream()
.filter(s->s.startsWith("张"))
.filter(s->s.length()==3)
.forEach(System.out::println);
}看上面的代码够简短吧。获取流,过滤张,过滤长度,逐一打印。代码相比于上面的案例更加的简 洁直观,接下来我们就来学习学习stream流。
Stream流的获取方式
对于Collection的实现类
首先,java.util.Collection 接口中加入了default方法 stream,也就是说Collection接口下的所有的实 现都可以通过steam方法来获取Stream流。
public class getStreamTest {
@Test
public void test1(){
ArrayList<Object> objects = new ArrayList<>();
objects.stream();
HashSet<Object> objects1 = new HashSet<>();
objects1.stream();
Vector<Object> objects2 = new Vector<>();
objects2.stream();
}
}对于Map
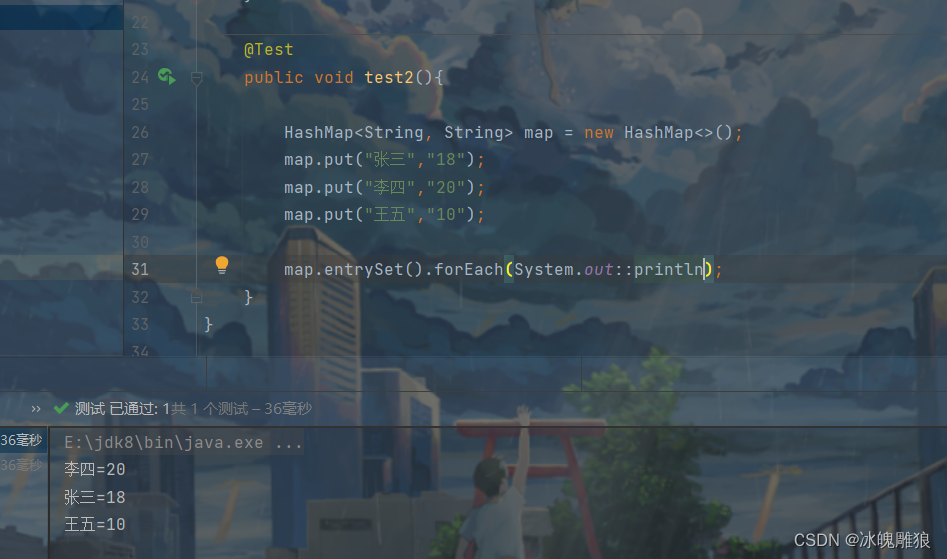
Map接口别没有实现Collection接口,那这时怎么办呢?这时我们可以根据Map的 entrySet() 方法获取对应的key value的集合。
@Test
public void test2(){
HashMap<String, String> map = new HashMap<>();
map.entrySet().stream();
}初学者可能不太好理解这个entrySet方法。这样想,map本来是存放一组组键值对的一个容器嘛,那我们要对容器里面的键值对进行遍历,但是遍历不了哇,要么就只能遍历键,要么就只能遍历值,无法完成我们的需求,所以有了entrySet方法,用来将map容器里面的这些键值对一组组的分好,这么一看,是不是这个容器就类似Collection了,这样我们每次遍历的时候每一项都是一个键值对映射项。看下面这个例子:
对于数组
在实际开发中我们不可避免的还是会操作到数组中的数据,由于数组对象不可能添加默认方法,所 有Stream接口中提供了静态方法of。
@Test
public void test3(){
String[] a={"aa","bb","cc"};
Stream<String> a1 = Stream.of(a);
a1.forEach(System.out::println);
Integer[] b={1,23,8,5};
Stream<Integer> b1 = Stream.of(b);
b1.forEach(System.out::println);
//基本数据类型不行
int[] c={1,5,3,6};
Stream<int[]> c1 = Stream.of(c);
c1.forEach(System.out::println);
}但是注意:基本数据类型的数组不行,必须要是包装数据类型数组。
Stream常用方法介绍
Stream流的操作很丰富,这里只介绍一些常用的API。这些方法可以被分成两种:
终结方法:返回值类型不再是 Stream 类型的方法,不再支持链式调用,常用的有count方法和forEach方法。
非终结方法:返回值类型仍然是 Stream 类型的方法,支持链式调用。除了终结方法以外的都是非终结方法。
Stream注意事项(重要):
- Stream只能操作一次
- Stream方法返回的是新的流
- Stream不调用终结方法,中间的操作不会执行
count
该方法返回一个long值,表示元素的个数
public static void main(String[] args) {
long count = Stream.of("a1", "a2", "a3").count();
System.out.println(count);
}forEach
该方法接收一个Consumer函数式接口,会将元素遍历交给函数处理
public static void main(String[] args) {
Stream.of("a1", "a2", "a3").forEach(System.out::println);;
}
filter
filter方法的作用是用来过滤数据的。返回符合条件的数据。该接口接收一个Predicate函数式接口参数作为筛选条件
public static void main(String[] args) {
Stream.of("a1", "a2", "a3","bb","cc","aa","dd")
.filter((s)->s.contains("a"))
.forEach(System.out::println);
}
limit
参数是一个long类型的数值,对该集合的前n个元素进行截取
public static void main(String[] args) {
Stream.of("a1", "a2", "a3","bb","cc","aa","dd")
.limit(3)
.forEach(System.out::println);
}
skip
参数是一个long类型的数值,对该集合的前n个元素进行跳过,和limit恰好相反
public static void main(String[] args) {
Stream.of("a1", "a2", "a3","bb","cc","aa","dd")
.skip(3)
.forEach(System.out::println);
}
map
该接口需要一个Function函数式接口参数,然后对元素进行遍历操作
@Test
public void test4(){
String[] str= {"cc2","2cl2","3vv"};
List<Integer> collect = Stream.of(str).map(String::length).collect(Collectors.toList());
System.out.println(collect);
}sorted
对数据进行排序,默认是可以自然排序,也可以自己实现排序规则
@Test
public void test5(){
Integer[] a={1,8,2,6,58,6};
Stream.of(a)
//.sorted() //默认为自然排序
.sorted((i,j)->j-i)//自定义规则,这里我们是逆序
.forEach(System.out::println);
}distinct
对数据进行去重操作。
Stream流中的distinct方法对于基本数据类型是可以直接出重的,但是对于自定义类型,我们是需要重写hashCode和equals方法来定义规则。
@Test
public void test6(){
Integer[] a={1,8,2,6,58,6};
Stream.of(a)
//.sorted() //默认为自然排序
.sorted((i,j)->j-i)//自定义规则,这里我们是逆序
.distinct()
.forEach(System.out::println);
}match
如果需要判断数据是否匹配指定的条件,可以使用match相关的方法
boolean anyMatch(Predicate predicate); // 元素是否有任意一个满足条件 boolean allMatch(Predicate predicate); // 元素是否都满足条件
boolean noneMatch(Predicate predicate); // 元素是否都不满足条件
public static void main(String[] args) {
boolean b = Stream.of("1", "3", "3", "4", "5", "1", "7")
.map(Integer::parseInt)
//.allMatch(s -> s > 0)
//.anyMatch(s -> s >4)
.noneMatch(s -> s > 4);
System.out.println(b);
}注意match是一个终结方法
find
如果我们需要找到某些数据,可以使用find方法来实现
Optional findFirst();
Optional findAny();
public static void main(String[] args) {
Optional<String> first = Stream.of("1", "3", "3", "4", "5", "1","7").findFirst();
System.out.println(first.get());
Optional<String> any = Stream.of("1", "3", "3", "4", "5", "1","7").findAny();
System.out.println(any.get());
}
max和min
如果我们想要获取最大值和最小值,那么可以使用max和min方法
Optional min(Comparator comparator);
Optional max(Comparator comparator);
public static void main(String[] args) {
Optional<Integer> max = Stream.of("1", "3", "3", "4", "5", "1", "7")
.map(Integer::parseInt)
.max((o1,o2)->o1-o2);
System.out.println(max.get());
Optional<Integer> min = Stream.of("1", "3", "3", "4", "5", "1", "7")
.map(Integer::parseInt)
.min((o1,o2)->o1-o2);
System.out.println(min.get());
}
reduce
如果需要将所有数据归纳得到一个数据,可以使用reduce方法
public static void main(String[] args) {
Integer sum = Stream.of(4, 5, 3, 9)
// identity默认值
// 第一次的时候会将默认值赋值给x
// 之后每次会将 上一次的操作结果赋值给x y就是每次从数据中获取的元素
.reduce(0, (x, y) -> {
System.out.println("x="+x+",y="+y);
return x + y;
});
System.out.println(sum);
// 获取 最大值
Integer max = Stream.of(4, 5, 3, 9)
.reduce(0, (x, y) -> {
return x > y ? x : y;
});
System.out.println(max);
}
mapToInt
如果需要将Stream中的Integer类型转换成int类型,可以使用mapToInt方法来实现
public static void main(String[] args) {
// Integer占用的内存比int多很多,在Stream流操作中会自动装修和拆箱操作
Integer arr[] = {1, 2, 3, 5, 6, 8};
Stream.of(arr)
.filter(i -> i > 0)
.forEach(System.out::println);
// 为了提高程序代码的效率,我们可以先将流中Integer数据转换为int数据,然后再操作
IntStream intStream = Stream.of(arr)
.mapToInt(Integer::intValue);
intStream.filter(i -> i > 3)
.forEach(System.out::println);
}concat
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat
public static void main(String[] args) {
Stream<String> stream1 = Stream.of("a","b","c");
Stream<String> stream2 = Stream.of("x", "y", "z");
// 通过concat方法将两个流合并为一个新的流
Stream.concat(stream1,stream2).forEach(System.out::println);
}Stream结果收集
结果收集到集合中
@Test
public void test7(){
List<String> list = Stream.of("a", "b", "c")
.collect(Collectors.toList());
System.out.println(list);
Set<String> set = Stream.of("a", "b", "c")
.collect(Collectors.toSet());
System.out.println(set);
ArrayList<String> arrayList = Stream.of("a", "b", "c")
.collect(Collectors.toCollection(ArrayList::new));
System.out.println(arrayList);
HashSet<String> hashSet = Stream.of("a", "b", "c")
.collect(Collectors.toCollection(HashSet::new));
System.out.println(hashSet);
}结果收集到数组中
Stream中提供了toArray方法来将结果放到一个数组中,返回值类型是Object[],如果我们要指定返回的 类型,那么可以使用另一个重载的toArray(IntFunction f)方法
@Test
public void test8(){
Object[] objects = Stream.of("a", "b", "c")
.toArray();
System.out.println(objects);
String[] strings = Stream.of("a", "b", "c")
.toArray(String[]::new);
System.out.println(strings);
}对流中的数据做聚合计算
@Test
public void test9() {
// 获取年龄的最大值
Optional<Person> maxAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).collect(Collectors.maxBy((p1, p2) -> p1.getAge() - p2.getAge()));
System.out.println("最大年龄:" + maxAge.get());
// 获取年龄的最小值
Optional<Person> minAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).collect(Collectors.minBy((p1, p2) -> p1.getAge() - p2.getAge()));
System.out.println("最新年龄:" + minAge.get());
// 求所有人的年龄之和
Integer sumAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).collect(Collectors.summingInt(Person::getAge));
System.out.println("年龄总和:" + sumAge);
// 年龄的平均值
Double avgAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).collect(Collectors.averagingInt(Person::getAge));
System.out.println("年龄的平均值:" + avgAge);
// 统计数量
Long count = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).filter(p -> p.getAge() > 18)
.collect(Collectors.counting());
System.out.println("满足条件的记录数:" + count);
}对流中数据做分组操作
当我们使用Stream流处理数据后,可以根据某个属性将数据分组
@Test
public void test10() {
// 根据账号对数据进行分组
Map<String, List<Person>> map1 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).collect(Collectors.groupingBy(Person::getName));
map1.forEach((k, v) -> System.out.println("k=" + k + "\t" + "v=" + v));
// 根据年龄分组 如果大于等于18 成年否则未成年
Map<String, List<Person>> map2 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).collect(Collectors.groupingBy(p -> p.getAge() >= 18 ? "成年" : "未成年"));
map2.forEach((k, v) -> System.out.println("k=" + k + "\t" + "v=" + v));
}对流中的数据做分区操作
Collectors.partitioningBy会根据值是否为true,把集合中的数据分割为两个列表,一个true列表,一个 false列表
@Test
public void test11() {
Map<Boolean, List<Person>> map = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).collect(Collectors.partitioningBy(p -> p.getAge() > 18));
map.forEach((k, v) -> System.out.println(k + "\t" + v));
}对流中的数据做拼接
Collectors.joining会根据指定的连接符,将所有的元素连接成一个字符串
@Test
public void test12() {
String s1 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).map(Person::getName)
.collect(Collectors.joining());
// 张三李四张三李四张三
System.out.println(s1);
String s2 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).map(Person::getName)
.collect(Collectors.joining("_"));
// 张三_李四_张三_李四_张三
System.out.println(s2);
String s3 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).map(Person::getName)
.collect(Collectors.joining("_", "###", "$$$"));
// ###张三_李四_张三_李四_张三$$$
System.out.println(s3);
}并行的Stream流
串行的Stream流
我们前面使用的Stream流都是串行,也就是在一个线程上面执行。
@Test
public void test01(){
Stream.of(5,6,8,3,1,6)
.filter(s->{
System.out.println(Thread.currentThread() + "" + s);
return s > 3;
}).count();
}
Thread[main,5,main]5
Thread[main,5,main]6
Thread[main,5,main]8
Thread[main,5,main]3
Thread[main,5,main]1
Thread[main,5,main]6
并行流
parallelStream其实就是一个并行执行的流,它通过默认的ForkJoinPool,可以提高多线程任务的速度。
我们可以通过两种方式来获取并行流:
- 通过List接口中的parallelStream方法来获取
- 通过已有的串行流转换为并行流(parallel)
@Test
public void test02(){
List<Integer> list = new ArrayList<>();
// 通过List 接口 直接获取并行流
Stream<Integer> integerStream = list.parallelStream();
// 将已有的串行流转换为并行流
Stream<Integer> parallel = Stream.of(1, 2, 3).parallel();
}
测试:
@Test
public void test03(){
Stream.of(1,4,2,6,1,5,9)
.parallel() // 将流转换为并发流,Stream处理的时候就会通过多线程处理
.filter(s->{
System.out.println(Thread.currentThread() + " s=" +s);
return s > 2;
}).count();
}Thread[main,5,main] s=1
Thread[ForkJoinPool.commonPool-worker-2,5,main] s=9 Thread[ForkJoinPool.commonPool-worker-6,5,main] s=6 Thread[ForkJoinPool.commonPool-worker-13,5,main] s=2 Thread[ForkJoinPool.commonPool-worker-9,5,main] s=4 Thread[ForkJoinPool.commonPool-worker-4,5,main] s=5 Thread[ForkJoinPool.commonPool-worker-11,5,main] s=1
线程安全问题
在多线程的处理下,肯定会出现数据安全问题。如下:
@Test
public void test9(){
ArrayList<Integer> arrayList1 = new ArrayList<>();
for (int i=0;i<1000;i++){
arrayList1.add(i);
}
ArrayList<Integer> arrayList2 = new ArrayList<>();
arrayList1.parallelStream()
.forEach(arrayList2::add);
System.out.println(arrayList2.size());
}运行以后结果并不是1000
针对这个问题,我们的解决方案有哪些呢?
- 加同步锁
- 使用线程安全的容器
- 通过Stream中的toArray/collect操作
//加同步锁
@Test
public void test9() {
Object o = new Object();
ArrayList<Integer> arrayList1 = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
arrayList1.add(i);
}
ArrayList<Integer> arrayList2 = new ArrayList<>();
arrayList1.parallelStream()
.forEach((a) -> {
synchronized (o) {
arrayList2.add(a);
}
});
System.out.println(arrayList2.size());
} //使用线程安全的容器
@Test
public void test10() {
Vector<Integer> objects = new Vector<>();
for (int i = 0; i < 1000; i++) {
objects.add(i);
}
Vector<Integer> vector = new Vector<>();
objects.parallelStream()
.forEach((a) -> {
vector.add(a);
});
System.out.println(vector.size());
} //将线程不安全的容器包装为线程安全的容器
@Test
public void test11() {
List<Integer> listNew = new ArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(listNew);
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
synchronizedList.add(i);
});
System.out.println(synchronizedList.size());
} //通过Stream中的 toArray方法或者 collect方法来操作
@Test
public void test12() {
List<Integer> list = IntStream.rangeClosed(1, 1000)
.parallel()
.boxed()
.collect(Collectors.toList());
System.out.println(list.size());
}







![[附源码]java毕业设计新冠疫苗线上预约系统](https://img-blog.csdnimg.cn/9426cd7ba95244b8b2730a8fd6b6331d.png)