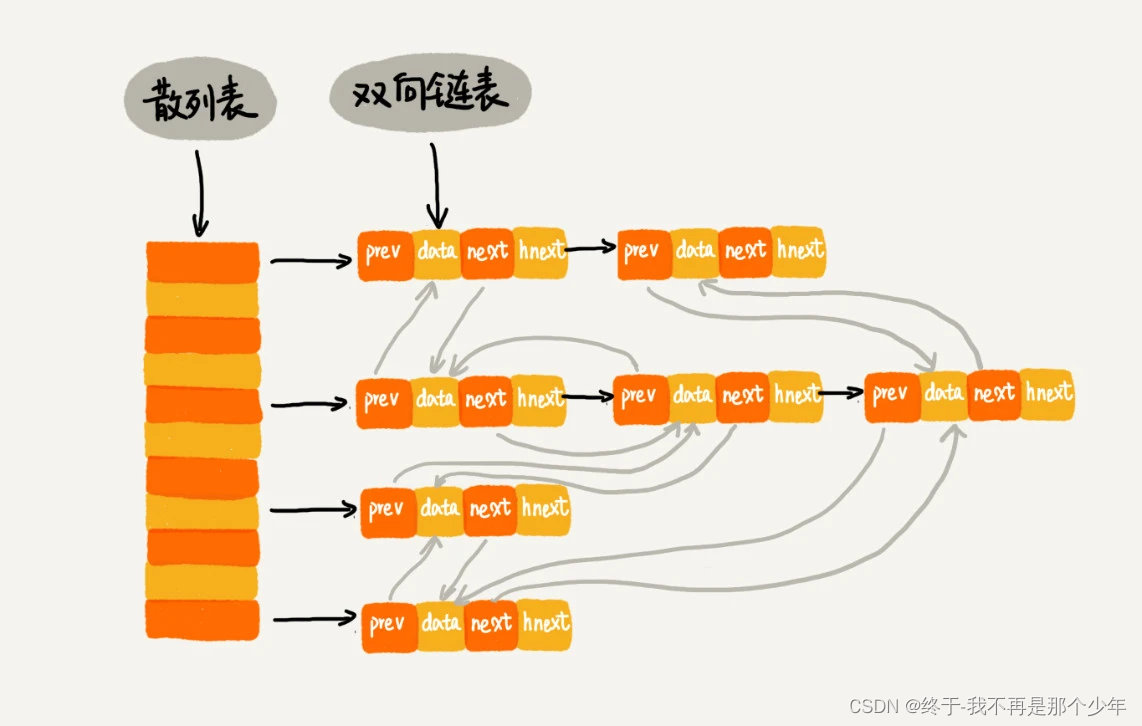
1.概述
1.1 论文相关
- 题目:注意你所有需要的(Attention Is All You Need)
- 发表时间:2017
- 出版:NIPS
- 原文地址:经典模型了,网上一搜就能搜索到
- 代码:
1.2 动机
因为循环神经网络通常是沿着符号输入输出序列的位置来考虑计算,将这些位置与计算时间中的步骤对齐,它们生成一系列隐藏状态
h
t
h_t
ht,作为前一个隐藏状态
h
t
−
1
h_{t−1}
ht−1和位置t的输入的函数。这种固有的顺序让训练示例不能使用并行计算,让序列长度成为了关键,因为容量极限限制了每个batch输入的示例。
因此作者就提出了一种新的模型Transformer,这种模型避免了循环而是完全依赖于注意力机制在输入输出之间绘制全局关系,并且Transformer模型允许并行计算,在机器翻译上也取得突出的成绩。
2 算法
2.1 自注意力机制
- 对于输入的数据,你的关注点是什么?
- 如何才能让计算机关注到这些有价值的信息?
self-attention在对自己进行编码的时候,每个词都是句子当中的一部分,但是在融合语义信息的时候方法也不是一样的,因为每个词语在其中的权重不同,不仅只考虑自己当前这个词,还要考虑全局的信息。
比如下面这两句话:

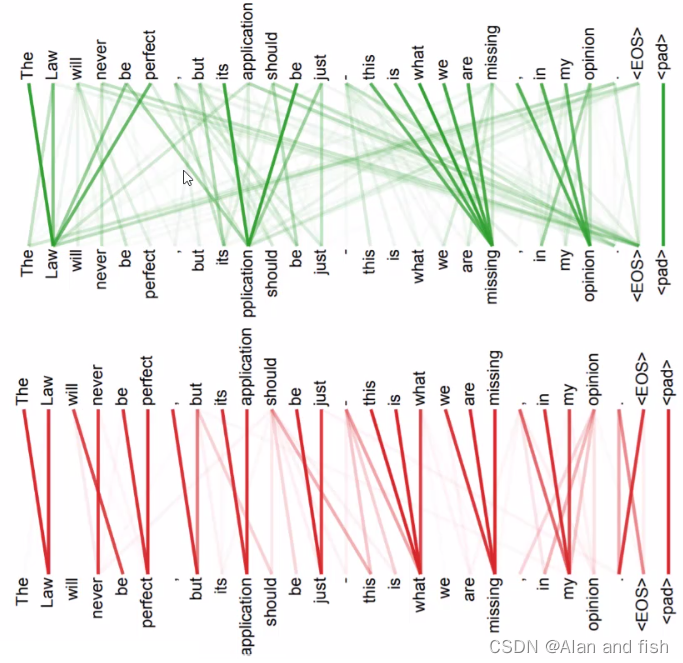
第一句话中的it指代的是animal,第二句话中指代的是street,两句话中的it所指代的内容不一样,所以他在编码的时候考虑的权重也是不一样的。
2.2 self-attention计算方法
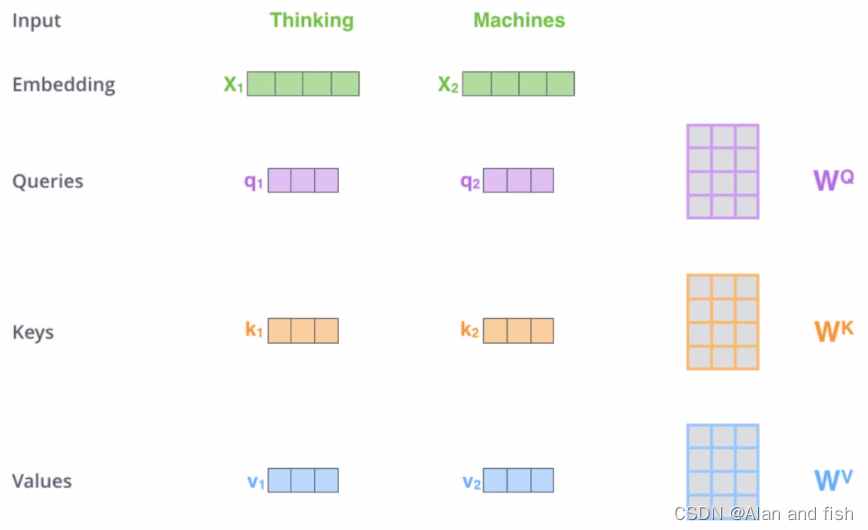
selef-attention的计算方法,结合上图进行分析:
- 第一步:对输入的单词进行一个编码转换成一个四维的向量
- 第二步:如何提取特征,第一个词要考虑这两个词对自己做了什么贡献,然后重新的进行向量编码,因此设置了3个矩阵:Queries,keys,values,借助这三个矩阵,对词语编码的时候怎么考虑到上下文。其实也就是三个权重参数。
那么这三个矩阵是有什么作用呢?见下图:
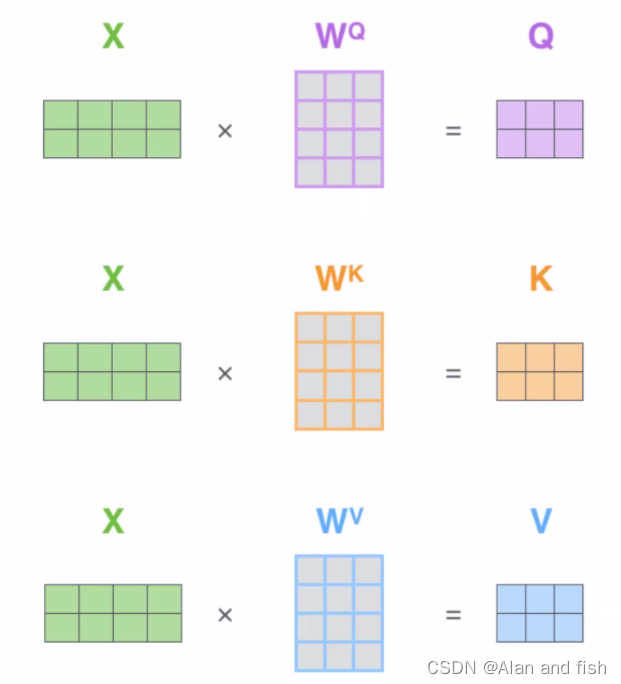
- Q:query,要查询与每个词之间的关系
- K:key,等着被查
- V:value,实际的特征信息
X与 W q W^q Wq矩阵相乘得到了 q 1 q_1 q1, q 2 q_2 q2l两个特征,X与 W k W^k Wk矩阵相乘得到了 k 1 k_1 k1, k 2 k_2 k2l两个特征,X与 W v W^v Wv矩阵相乘得到了 v 1 v_1 v1, v 2 v_2 v2两个特征。
- 第三步:每一个词的Q会与每一个Q计算得分
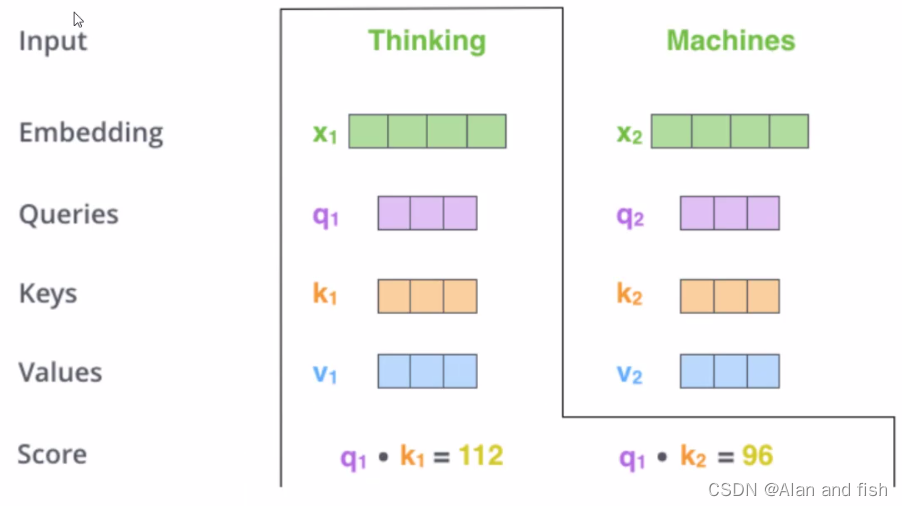
然后计算每一个词与上下文之间的关系权重:
1)q与k的内积表示有多匹配,因为如果两个向量没有关系就是垂直,垂直内积为0,如果不垂直,则内积绝对不为0.
2)输入两个向量得到一个分值
例如要查找第一个词与它自己的关系,就用 q 1 ∗ k 1 q_1*k_1 q1∗k1得到一个关系值,查第一个词与第二个词之间的关系,则就用 q 1 ∗ k 2 q_1*k_2 q1∗k2到到关系值。 - 第四步:softmax进行归一化
然后使用softmax对这些关系权重进行归一化得到当前单词的与每个单词的权重,然后将权重与v相乘得到了它的编码。
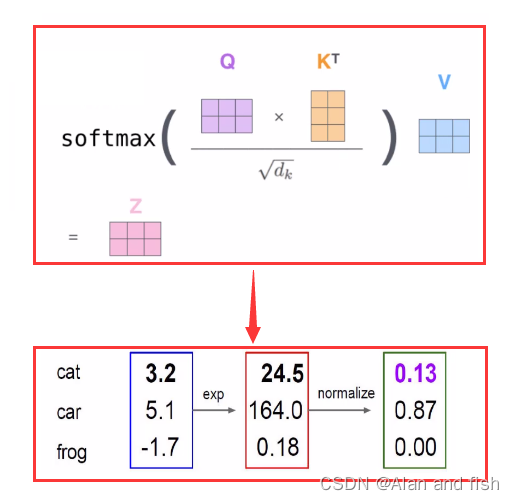
如上图:则 x 1 x_1 x1的编码为0.13* v 1 v_1 v1+0.87* v 2 v_2 v2+0.0* v 3 v_3 v3
每一个词的会跟整个序列中的每一个K计算得分,然后基于得分再分配特征。
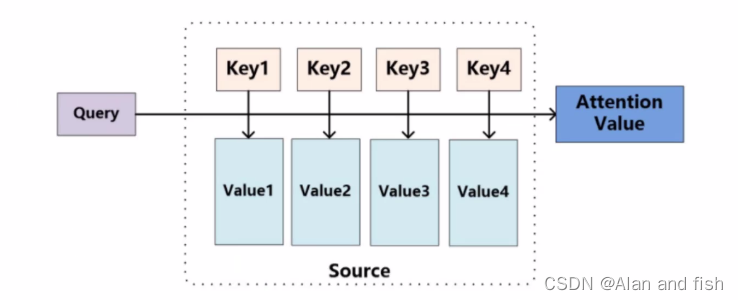
小结:
Attention整体计算流程: - 每个词的Q会跟每-个K计算得分
- Softmax后就得到整个加权结果
- 此时每个词看的不只是它前面的序列
- 而是整个输入序列
- 同一时间计算出所有词的表示结果

2.3 多头机制
通过不同的head得到多个特征表示的,将所有特征拼接到一起,可以通过再一层全连接来降低维度,一般设置8个头。
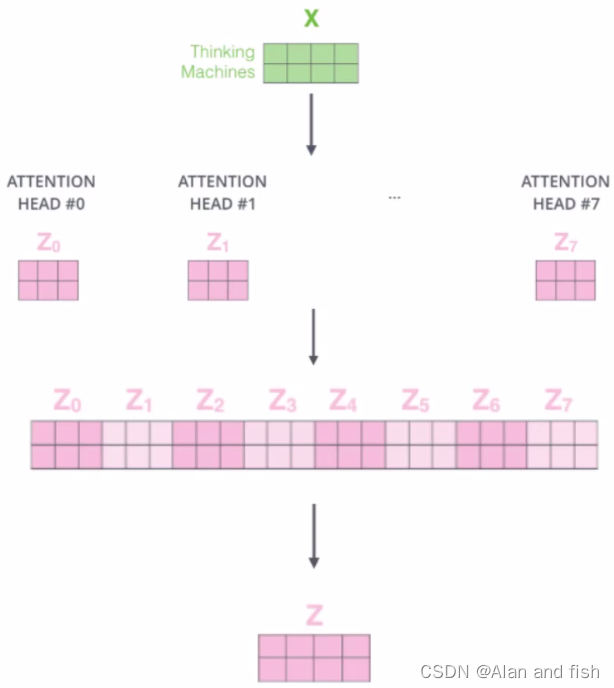
多头注意力机制的执行过程:
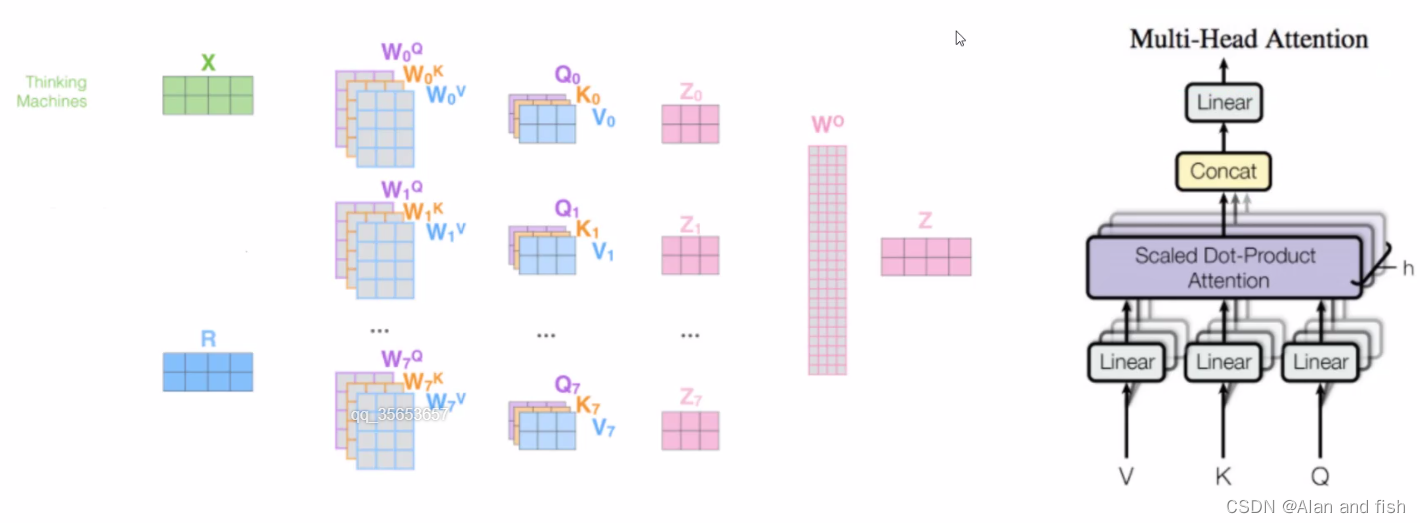
多头注意里机制不同的注意力结果不同,得到的特征向量的表达式有也不同。
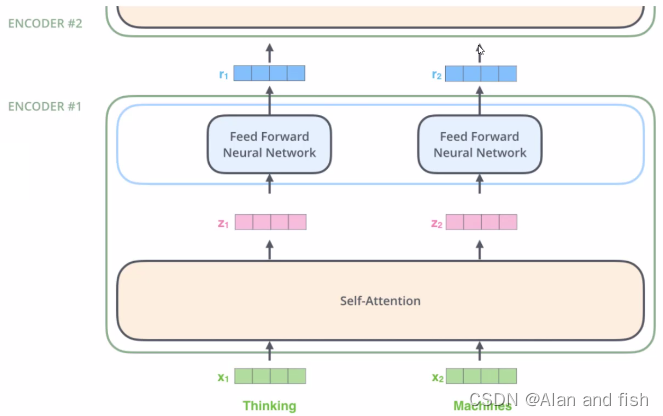
2.4 位置编码和多层堆叠
多层堆叠
上面是经过一次self-attention得到的结果,随后输出的还是向量,既然是向量那我们还可以继续对他进行一次self-attention,这也就是多层堆叠。
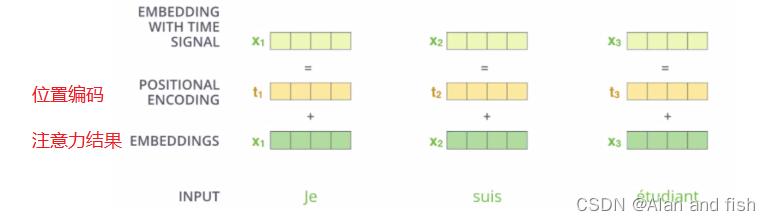
位置信息编码
在self- attention中每个词都会考虑整个序列的加权,所以其出现位置并不会对结果产生什么影响,相当于放哪都无所谓,但是这跟实际就有些不符合了,我们希望模型能对位置有额外的认识。
本文中的位置编码使用的是余弦周期进行编码的。
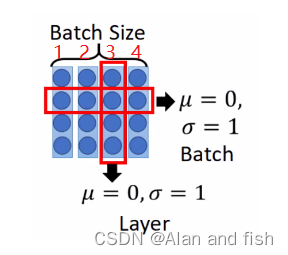
层级归一化(layerNormlize)
首先了解一下batch-Normlize,如下图中一个batch有四个数据,然后把一个batch的某一层的特征按照batch的维度,让他均值为0,标出差为1.
这里加上了一个layerNormlize,目的就是让它训练的更稳定更快。
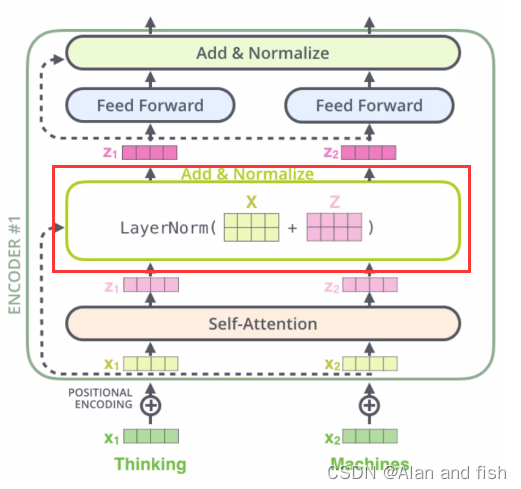
** 残差连接**
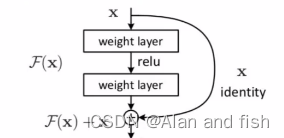
因为一个参数经过多层的堆叠之后,进行层级归一化的效果不一定是最完美的,于是就做了2手准备,看看是经过多层堆叠的效果最好呢还是直接经过一个self-attention的效果好,然后对比结果,那个结果好就选择那个,这个就叫做残差连接,其实就是做两手准备。
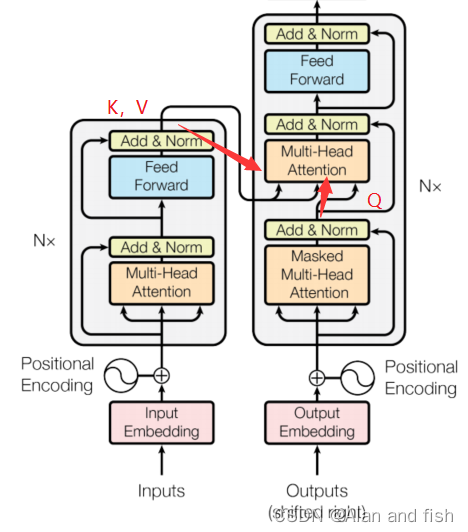
2.5 Decoder
** Decoder aattention**
解码的过程需要用到解码器的Q去查询编码器中的K和V,总之得把编码器中的训练的信息要用起来。
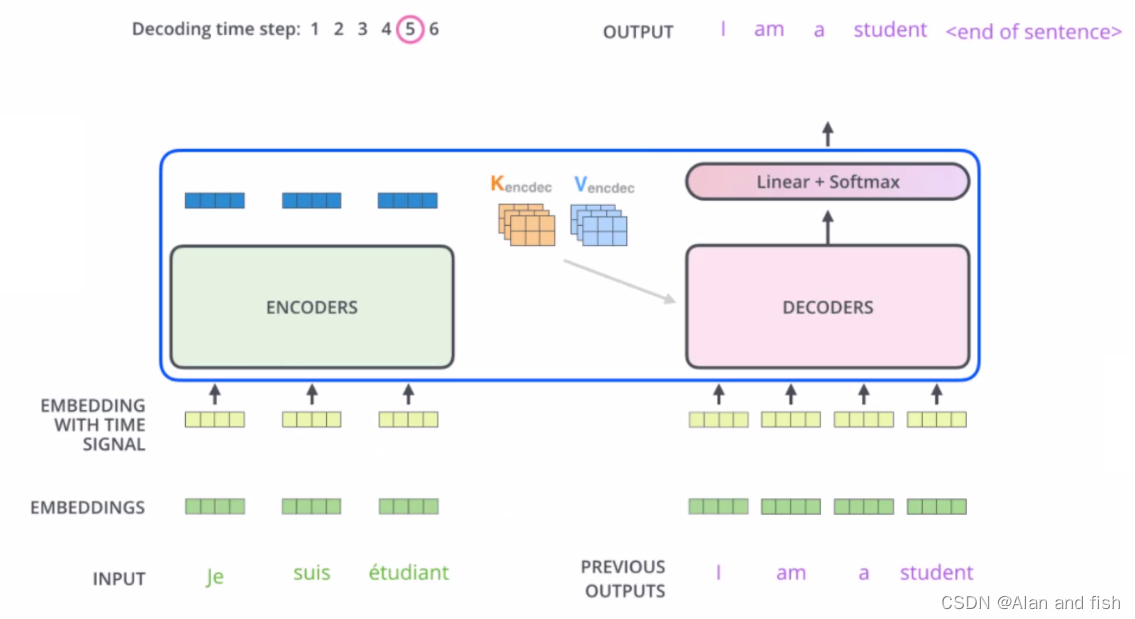
** mask机制**
Decoder预测结果是基于前面一个词预测下一个词,那么既然是预测下一个词,那就不能提前知道这个词,所有就把他mask掉,相当于遮住,然后让他自己预测。
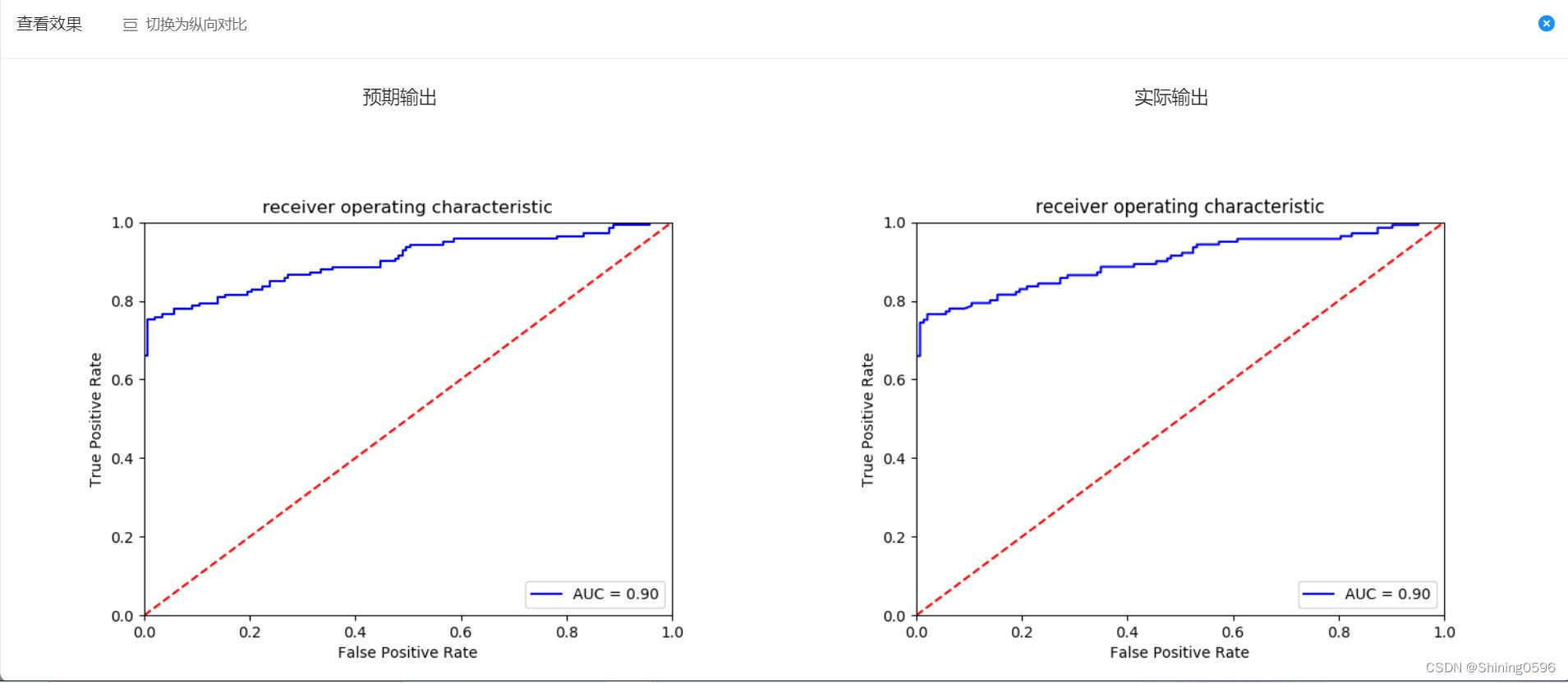
4. 实验及结果
4. 总结
后面再继续完善