目录
第1关:准备实验数据
任务描述:
相关知识:
一、获取数据:
二、读取数据集:
三、如何找出对应的数据列:
编程要求:
测试说明:
第二关:数据预处理
任务描述:
相关知识:
数据标准化:
主成分分析降维:
编程要求:
第三关:SVM模型训练
任务描述:
相关知识:
一、分割数据集:
二、建立SVM模型:
三、模型测试:
编程要求:
第四关:数据可视化:
任务描述:
相关知识:
一、AUCC曲线含义:
二、绘制AUC曲线:
第1关:准备实验数据
任务描述:
本关任务:补充数据准备模块代码,应用Panads模块,生成训练数据集。 读取航空发动机模拟数据,每个发动机的第一条数据为正常状态数据,最后一条数据为故障状态数据,共有4个故障状态,分别为1,2,3,4,正常状态label为0
相关知识:
为了完成本关任务,你需要掌握:1.如何获取数据,2.如何创建数据集。
一、获取数据:
通过Pandas读取数据集文件,将每个发动机的第一条数据作为正常状态样本,最后一条数据作为故障样本,数据集通过Pandas中的read_csv函数读取数据,并依据iloc函数获取数据列。
data = pd.read_csv(data_path_file, sep=' ');//读取某个路径下的csv文件,其中数据列以空格为间隔list = data_ext\fract['NO'].unique();//获取NO列中不同元素,以列表形式返回df_first = data_ext\fract[data_ext\fract.NO == i].iloc[0];//获取NO列为i值的第一行数据
二、读取数据集:
本实验选用的数据为美国国家航空航天局(NASA)提供的涡扇发动机降解模拟数据集合(TEDS)。该数据集在操作条件和故障模式的不同组合下,模拟了四种不同故障场景,记录多个传感器通道数据来描述故障演化,即从发动机正常状态到最终发动机故障停止运转。 该数据集由多个时间序列组成。数据包含26列,由空格分隔,分别为发动机编号、时间周期、操作设置、传感器测量值。 通过Pandas读取数据文件,并输出数据描述 示例如下:
import pandas as pd
data = pd.read_csv(data_path+file, sep=' ')
print(data.describe());//输出数据描述
print(data.head());//输出数据的前5行输出:
op1 op2 op3 para1 para10 \ count 2832.000000 2832.000000 2832.000000 2832.000000 2832.000000 mean 18.206817 0.418590 95.974576 484.307945 1.151949 std 17.367195 0.374573 12.035949 31.503325 0.142425 min -0.006900 -0.000600 60.000000 445.000000 0.930000 25% 0.001400 0.000100 100.000000 449.440000 1.020000 50% 19.998900 0.620000 100.000000 489.050000 1.080000 75% 35.006700 0.840000 100.000000 518.670000 1.300000 max 42.008000 0.842000 100.000000 518.670000 1.320000
三、如何找出对应的数据列:
Pandas中的 iloc 函数是用基于整数的下标来进行数据定位/选择 iloc 的语法是 data.iloc[, ], iloc 在Pandas中是用来通过数字来选择数据中具体的某些行和列。你可以设想每一行都有一个对应的下标(0,1,2,...),通过 iloc 我们可以利用这些下标去选择相应的行数据。同理,对于行也一样,想象每一列也有对应的下标(0,1,2,...),通过这些下标也可以选择相应的列数据。
编程要求:
根据提示,在右侧编辑器补充代码,计算并输出数据集合的尺寸shape。
测试说明:
预期输出: (2832, 26)
import os
import pandas as pd
import pickle
import numpy as np
import os
data_path =r'data/'
#将每个发动机的第一行数据作为正常样本,最后一行作为故障样本
def get_local_data(data):
data_extract = data.iloc[:, 0:26]
list = data_extract['NO'].unique()
data_norm = pd.DataFrame()
data_x = pd.DataFrame()
for i in list:
#**********Begin**********#
#第一步 进行数据读取 在两个空内分别填入切片索引
df_first = data_extract[data_extract.NO == i].iloc[0]#此处填入切片索引
df_last = data_extract[data_extract.NO == i].iloc[-1]#此处填入切片索引
data_norm = data_norm.append(df_first, ignore_index=True)
data_x = data_x.append(df_last, ignore_index=True)
#**********End**********#
return data_norm,data_x
#读取csv数据文件
def get_data(tag="labeled"):
data_norm = pd.DataFrame()
for root, _, files in os.walk(data_path):
for file in files:
if 'txt' not in file:
continue
#**********Begin**********#
#第二步 读取csv数据文件 在空内填入文件路径,并设置数据读取间隔
data = pd.read_csv(data_path+file, sep=' ') #此处填写read_csv函数,用于读取csv文件,数据间隔为' '
#**********End**********#
if "001" in file:
data_norm_1,data_1 = get_local_data(data)
if "002" in file:
data_norm_2,data_2 = get_local_data(data)
if "003" in file:
data_norm_3,data_3 = get_local_data(data)
if "004" in file:
data_norm_4,data_4 = get_local_data(data)
if "111" in file:
data_norm_5,data_11 = get_local_data(data)
if "222" in file:
data_norm_6,data_22 = get_local_data(data)
if "333" in file:
data_norm_7,data_33 = get_local_data(data)
if "444" in file:
data_norm_8,data_44 = get_local_data(data)
data_norm = data_norm.append([data_norm_1,data_norm_2,data_norm_3,data_norm_4,data_norm_5,data_norm_6,data_norm_7,data_norm_8],ignore_index=True)
data_1 = data_1.append(data_11,ignore_index=True)
data_2 = data_2.append(data_22, ignore_index=True)
data_3 = data_3.append(data_33, ignore_index=True)
data_4 = data_4.append(data_44, ignore_index=True)
return data_norm, data_1,data_2,data_3,data_4
def get_numpy_data(data):
data = data.iloc[:,1:-1]
#print(data.describe())
#print(data.head())
return np.array(data)
#错误类
class LABEL(object):
NL = 0
FE = 1
FF = 2
HE = 3
HF = 4
def run():
data_norm, data_1,data_2,data_3,data_4= get_data()
normal,fault_1, fault_2, fault_3,fault_4 = [LABEL.NL]*data_norm.shape[0],[LABEL.FE]*data_1.shape[0],\
[LABEL.FF]*data_2.shape[0],[LABEL.HE]*data_3.shape[0],[LABEL.HF]*data_4.shape[0]
labels = normal+fault_1+fault_2+fault_3+fault_4
labels = np.array(labels)
labels = np.array(labels > 0).astype(np.int)
data_select = data_norm.append([data_1,data_2,data_3,data_4])
data_select_array = get_numpy_data(data_select)
jsj_data_file = data_path +'jsj_data.pkl'
jsj_data = open(jsj_data_file, 'wb')
#**********Begin**********#
#第三步 pickle保存数据 在空内填入保存参数
pickle.dump(data_select_array,jsj_data) #填入参数以保存data_select数据
pickle.dump(labels,jsj_data) #填入参数保存labels数据
#**********End**********#
jsj_data.close()
if __name__ == "__main__":
run()第二关:数据预处理
任务描述:
本关任务:要求对第一关获取的数据进行数据预处理,包括数据标准化与主成分分析降维。
相关知识:
为了完成本关任务,你需要掌握:1.如何应用sklearn进行数据标准化,2.如何应用sklearn进行数据降维。
数据标准化:
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据均值设置为0,,标准差设置为1。 实现方法为:z = (x - u) / s 其中u为样本均值,s为样本标准差 sklearn提供了StandardScaler类能够快速实现数据标准化处理
normalizer = StandardScaler().fit(data);//声明一个StandardScaler对象data_scale = normalizer.transform(data);//调用该对象的transform函数,得到标准化后的数据print(data_scale.mean(axis=0).astype(int));//输出均值print(data_scale.std(axis=0));//输出标准差
输出:[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
主成分分析降维:
数据降维是一种对高维度特征数据预处理方法,能够将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征。主成分分析方法(Principal Component Analysis,PCA),是一种使用最广泛的数据降维算法。PCA主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。 PCA通过计算数据协方差矩阵的特征值与特征向量,从原始数据空间顺序找出一组相互正交的坐标轴,其中特征值最大的特征向量代表原始数据中方差最大的方向。以此类推,得到n个坐标方向,即可保留包含绝大部分方差的维度特征,且忽略方差几乎为0的特征维度,实现对数据特征的降维处理。 sklearn提供了PCA类能够快速实现数据标准化处理 示例如下:
pca = PCA(n_components=21)newX = pca.fit_transform(data_scale)print (pca.explained_variance_ratio_)print(np.sum(np.array(pca.explained_variance_ratio_)))
输出:0.99
编程要求:
根据提示,在右侧编辑器补充代码,完成实验任务。
from sklearn.preprocessing import StandardScaler
import pickle
from sklearn.decomposition import PCA
import os
data_path =r'data/'
def Stage_2():
#**********Begin**********#
#第一步 读取Stage_1保存的数据文件,在空内填入保存参数
f = open(data_path+'jsj_data.pkl','rb')#填空,按照字节读取pkl数据
data = pickle.load( f) #填空获取训练数据
labels = pickle.load(f )#填空获取标签
#**********End**********#
f.close()
#**********Begin**********#
#第二步 进行数据归一化处理,在空内填入参数
normalizer = StandardScaler().fit(data) # 数据归一化
data_scale = normalizer.transform(data ) #填空,对数据进行归一化,得到data_scale
pca = PCA(n_components= 21) #填空,确定PCA参数
#**********End**********#
#**********Begin**********#
#第三步 进行数据PCA,在空内填入参数
data_PCA = pca.fit_transform(data_scale) #填入参数
#**********End**********#
jsj_data_file = data_path +'data_pca.pkl'
jsj_data = open(jsj_data_file, 'wb')
pickle.dump(data_PCA,jsj_data)
pickle.dump(labels,jsj_data)
jsj_data.close()第三关:SVM模型训练
任务描述:
本关任务:训练SVM并进行测试。
相关知识:
为了完成本关任务,你需要掌握:1.如何分割数据集为训练样本与测试样本,2.如何建立SVM模型,3.如何进行模型测试。
一、分割数据集:
把数据集分为两部分:分别用于训练和测试 sklearn提供一个将数据集切分成训练集和测试集的函数train_test_split。
Xd_train,Xd_test,y_train,y_test=train_test_split(X_d,y,random_state=14);//对数据集合X_d和标签数据集y进行分割,得到训练数据与测试数据System.out.println(Xd_train.shape);//显示训练数据的大小
输出:(2000,26)
二、建立SVM模型:
SVM算法是一种二值分类器方法。其基本的观点是,找到两类之间的一个线性可分的直线(或超平面)。首先假设二分类目标是-1或者1,有许多条直线可以分割两类目标,但是定义分割两类目标有最大距离的直线为最佳线性分类器。 sklearn提供了SVC对象用于构建SVM模型,下面是不同参数对SVM性能的影响 **核函数(kernel)**:一些线性不可分的问题可能是非线性可分的,即特征空间存在超曲面将正类和负类分开。使用非线性函数可以将非线性可分问题从原始的特征空间映射至更高维空间,从而转化为线性可分问题,这样的非线性函数称为核函数。目前常用的核函数有多项式核(Poly)、径向基函数核(RBF)、拉普拉斯核、Sigmoid核。 **度(degree)**:针对于Poly核的参数,默认为3,代表使用三次多项式构建核函数,维度越多能够对训练数据分割越明显,但可能会出现过拟合现象,选择其他核函数时会忽略。 **惩罚系数(C)**:用于控制超平面附近错误分类力度,C越大,等价于对错误分类的惩罚增大,模型更多地趋向于训练集全对的情况,这样对训练集测试时准确率很高,但泛化能力弱;C值越小,对误分类的惩罚减小,允许容错,训练后的模型泛化能力较强。
**核函数幅宽(gamma)**:针对于RBF、Poly与Sigmoid核的参数,该参数控制每个支持向量对应的作用范围,即gamma越大,支持向量作用范围越小,对未知样本分类效果较差,但是如果设置过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率,默认为1/n_features值。 **核函数常数项(coef0)**:针对于Poly与Sigmoid核的参数,用于控制低维向量通过核函数映射后得到高维向量的偏置,默认为0。 **停止误差值(tol)**:模型停止训练的误差值,用于控制模型拟合训练集程度,默认为1e-3,误差值越小,对训练集测试时准确率越高。 **最大迭代次数(max_iter)**:模型训练的最大迭代次数,默认为-1代表无限制,与停止误差一起用于控制模型训练过程。 SVM主要调节参数为:C、kernel、degree、gamma、coef 示例如下:
clf = SVC(probability=True)clf.fit(trainX,trainY)
三、模型测试:
模型的测试是由已经训练好的模型对测试样本进行预测得出的。 sklearn提供一个计算准确度函数accu\fracy_score用于直接比对真实标签与模型预测标签的准确率,即相同的标签个数除以样本总数
predict_results=clf.predict(testX)print(accu\fracy_score(predict_results, testY))
输出:0.85
编程要求:
根据提示,在右侧编辑器补充代码,完成实验任务。
import pickle
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import os
data_path =r'data/data_pca.pkl'
def Stage_3_1():
f = open('data/data_pca.pkl','rb')#按照字节读取pkl数据
data_PCA = pickle.load(f) #获取训练数据
labels = pickle.load(f)#获取标签
f.close()
#**********Begin**********#
#第一步 分割数据集
trainX, testX, trainY, testY = train_test_split(data_PCA, labels, test_size=0.1, random_state=42) #填空,将数据集分为测试样本与训练样本,分割度为10%
#**********End**********#
return trainX, testX, trainY, testY
def Stage_3_2(trainX,trainY):
#**********Begin**********#
#第二步 进行SVM模型设置并训练
clf = SVC(probability=True) #填空,构建SVM模型
clf.fit(trainX,trainY) #填空,进行SVM模型训练,以trainX为训练样本集,trainY为训练样本标签
#**********End**********#
return clf第四关:数据可视化:
任务描述:
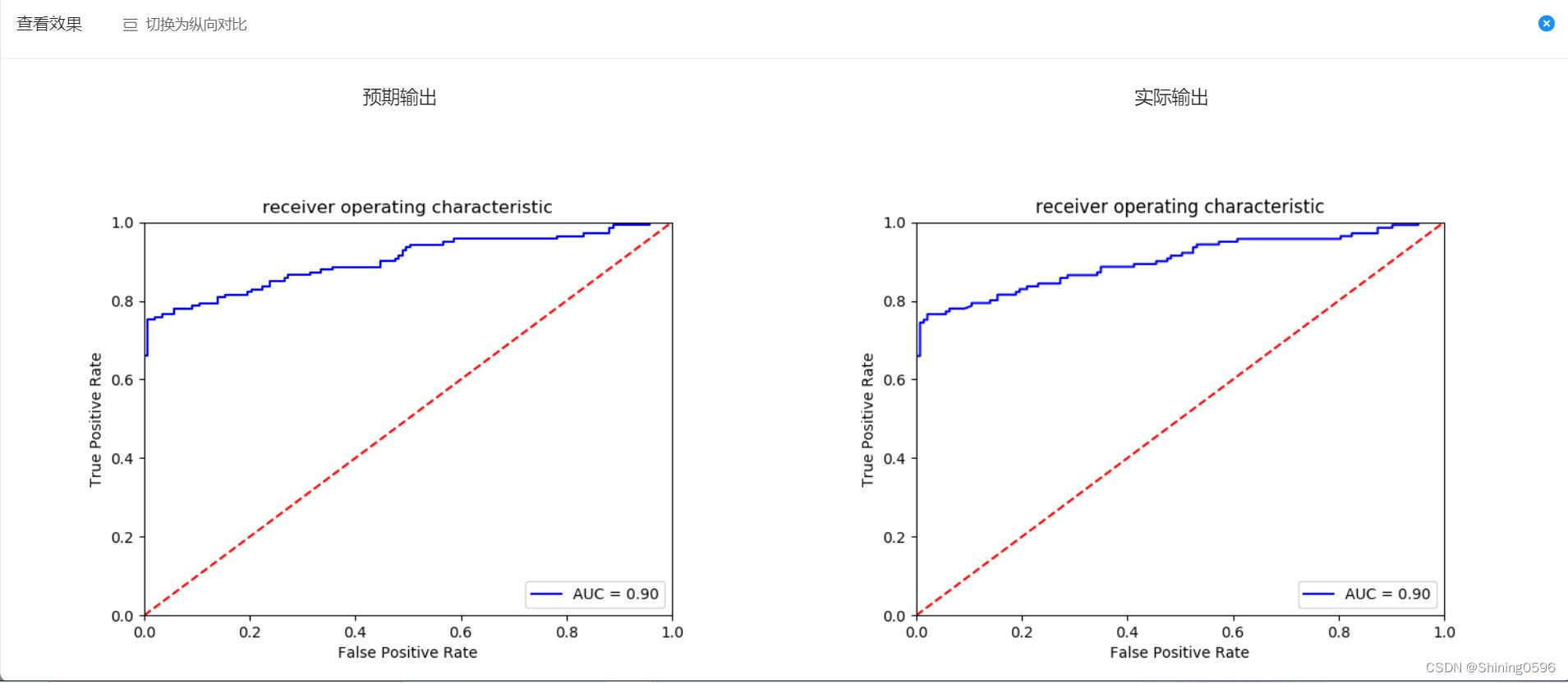
本关任务:绘制ROC曲线。
相关知识:
为了完成本关任务,你需要掌握:1.AUC曲线的含义,2.绘制AUC曲线。
一、AUCC曲线含义:
AUC: AUC 的全称是 Area under the Curve of ROC,也就是ROC曲线下方的面积。在机器学习领域,经常用 AUC 值来评价一个二分类模型的训练效果。 在机器学习理论中,可用ROC曲线来分析二元分类模型。在二分类问题中,数据的标签通常用(0/1)来表示,在模型训练完成后进行测试时,会对测试集的每个样本计算一个介于0~1之间的概率,表征模型认为该样本为阳性的概率。 我们可以选定一个阈值,将模型计算出的概率进行二值化,比如选定阈值等于0.5,那么当模型输出的值大于等于0.5时,我们就认为模型将该样本预测为阳性,也就是标签为 1,反之亦然。 选定的阈值不同,模型预测的结果也会相应地改变。二元分类模型的单个样本预测有四种结果: 真阳性(TP):判断为阳性,实际也是阳性。
伪阳性(FP):判断为阳性,实际却是阴性。
真阴性(TN):判断为阴性,实际也是阴性。
伪阴性(FN):判断为阴性,实际却是阳性。
ROC曲线将假阳性率(FPR)定义为X轴,真阳性率(TPR)定义为Y轴。
其中:TPR :在所有实际为阳性的样本中,被正确地判断为阳性的样本比率 。
TPR=TP/(TP+FN)
FPR:在所有实际为阴性的样本中,被错误地判断为阳性的样本比率。
FPR=FP/(FP+TN)
给定一个二分类模型和它的阈值,就可以根据所有测试集样本点的真实值和预测 值计算出一个(X=FPR,Y=TPR)坐标点,使用单点绘图方法即可得到ROC曲线。
AUC被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。在检验模型时,AUC值越大的模型,正确率越高。
二、绘制AUC曲线:
对于AUC曲线,sklearn提供roc_curve函数 matplotlib模块提供绘图工具
示例如下:
false_positive_rate, true_positive_rate, thresholds = roc_curve(testY,predict_prob[:,1])
roc_auc=auc(false_positive_rate, true_positive_rate)
plt.figure()
plt.plot(false_positive_rate, true_positive_rate,'b',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('receiver operating cha\fracteristic')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.legend(loc="lower right")
plt.show()import matplotlib
import matplotlib.pyplot as plt
matplotlib.use("Agg")
def draw_ROC(false_positive_rate,true_positive_rate,roc_auc):
#**********Begin**********#
#绘制ROC曲线 设置plt参数
plt.plot(false_positive_rate, true_positive_rate,'b',label='AUC = %0.2f'% roc_auc)#填空,绘制AUC曲线
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlabel('False Positive Rate')#填空,设置xlabel为'False Positive Rate'
plt.ylabel('True Positive Rate')#填空,设置ylabel为'True Positive Rate'
plt.title('receiver operating characteristic')#填空,设置title为'receiver operating characteristic'
#**********End**********#
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.legend(loc="lower right")
#plt.show()
plt.savefig('Stage4/plt_image_cor/correct_fig.png')