目录
引入
node embedding
Deep Graph Encoders的引入
Basics of Deep Learning
Deep Learning for Graphs
编辑A Naive Approach
GCN
GCN的基本idea
Aggregate Neighbors
训练GCN
Unsupervised Training
Supervised Training
Oview
整体流程
Inductive capability
引入
node embedding
(1)定义
将节点映射到d-维空间,使在图中相似的节点嵌入的更相近。
(2)两个关键组件Encoder Decoder

(3)shallow Encoders的缺陷
- 需要O(|V|)的参数
- 不能产生训练集里没有出现过的节点的嵌入(如果出现新节点,还需要再走一遍random walk)
- 没有利用图上的features信息

Deep Graph Encoders的引入
1.deep encoders是基于图结构的多层非线性转换,deep encoders可以和讲过的节点相似性函数结合起来。

2.现代深度学习工具箱设计用于简单的序列和网格(sequence&grid),但实际上networks更加负责
- 任意的大小和复杂的拓扑结构(没有像grid的空间位置)
- 没有固定的节点顺序或者参考节点(sequence的左右,grid的上下左右)
- 经常是动态的和具有多模态特征

Basics of Deep Learning

Deep Learning for Graphs
基本定义
 A Naive Approach
A Naive Approach
将邻接矩阵和节点features拼在一起输入到DNN中
存在问题:1)参数O(V);2)不适用于不同大小的图;3)对节点顺序敏感(如果节点编号顺序改变的话,矩阵就会改变,因此如果这样做的话,就必须保持节点编号顺序保持不变)

GCN
推广CNN到图上,并利用节点属性。
但Graphs和images不同的是:在图上没有固定的局部性或者滑动窗口的概念;且图是排列不变的,节点顺序不固定。


将邻居节点的信息转换,并结合它们。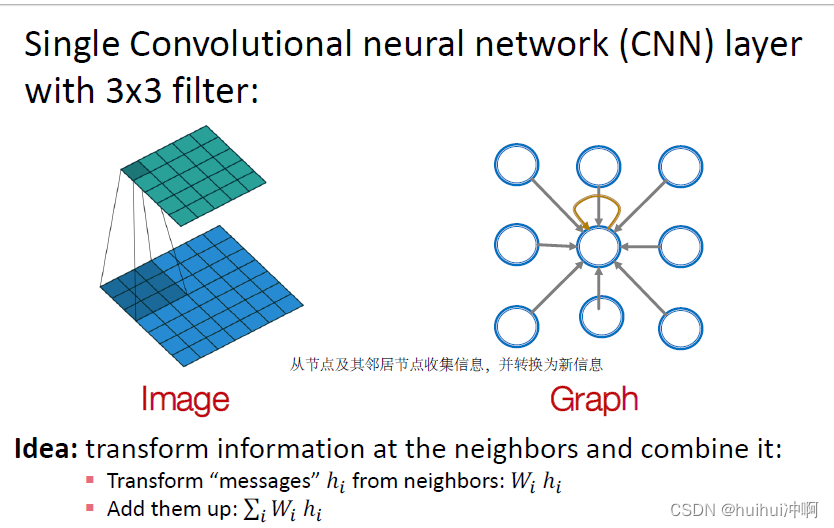
GCN的基本idea
- 基于局部邻居节点定义一个计算图
- 在计算图上传播并转换信息

Aggregate Neighbors
基于局部邻居产生节点embedding,节点使用神经网络从邻居节点聚合信息。每一层同一节点产生的embedding不同。0-layer的嵌入为节点的feature。仅会在有限层数里进行,例如研究Khops,那神经网络层数就为K。
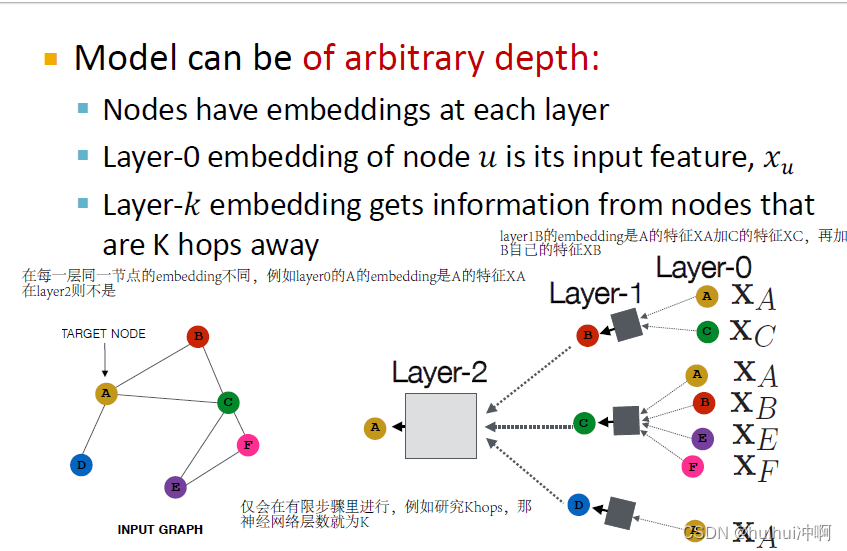
每一个节点都可以定义自己的神经网络结构,因此需要训练和学习多个神经网络。这些节点的计算图或神经网络结构是基于邻居节点定义的,
由于节点顺序是任意的,因此聚合运算要具有排列不变性,即节点可以有任何顺序,但聚合结果相同。如何定义转换,怎么将他们参数化,如何学习他们?基本方式:对邻居节点信息求平均并应用一个神经网络。
对节点v上一层邻居节点的嵌入求平均的结果 节点v上一层的嵌入 加权求和再经过一个非线性激活函数。得到节点v此层的嵌入。

训练GCN
可以将这些嵌入输入到任何损失函数中,并运行 SGD 来训练权重参数:Wk邻域聚合的权重矩阵;Bk用于变换自身上一层嵌入向量的权重矩阵

一些聚合可以用矩阵计算更有效的实现,将求和转换为矩阵乘积



Unsupervised Training

Supervised Training
直接使用一个有监督的学习任务(节点分类)训练。

Oview
整体流程
1) 定义一个neighborhood aggregation function
2)为嵌入定义一个loss function
3)在一个节点集上训练
4)通过正向传播产生需要的节点的嵌入(甚至可以为没有在训练集里出现的节点产生embedding)
意味着可以在一个图上训练再应用到另一个图上。也可以再子图上训练,应用于整个图,无需再重新训练
Inductive capability
所有节点共享aggregation parameters
W与B的参数数量仅取决于embedding与特征的维度,与图的大小无关,因为第一层嵌入为特征维度。维度和上下层嵌入的维度有关。








![[附源码]计算机毕业设计JAVA基于web的电子产品网络购物平台](https://img-blog.csdnimg.cn/c3443017e63f4c3c8b96991be3d151f2.png)