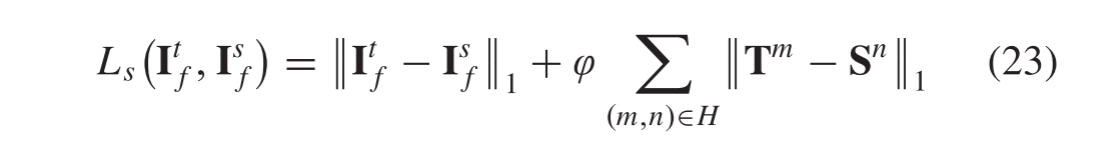逻辑回归 — 适用于二分类问题
使用逻辑回归算法会得到的输出标签y,y在监督问题中全是0或者1,因此这是一种针对二分类问题的算法。
给定的输入特征向量x和一幅图像对应,我们希望识别这是否是一张猫的图片。因此我们想要一种算法能够输出一个预测值, 我们称之为y帽(yhat y ^ \widehat{y} y ),这代表对真是标签Y的估计。形式上讲yhat是当给定特定输入特征x时,预测标签y为1的概率。换种说法就是当x是一张图像时,你想要yhat告诉你这张图是猫的概率。
x是一个 x n x_n xn维的向量,约定逻辑回归的参数是w,w也是一个 x n x_n xn维的向量,另外,参数b是一个实数,因此给定了一个输入x,以及参数w和b,那么如何产生输出yhat呢?
尝试让 y ^ = w . T ∗ x + b \widehat{y} = w.T*x+b y =w.T∗x+b,这是输入x的一个线性函数输出,事实上,如果使用线性回归,就是这样操作的,但是这对二分类并不是一个好的算法,因为你希望yhat能够输出y为1的概率。因此yhat的值应该在0和1之间。而这种算法很难实现这个要求。因为 w . T ∗ x + b w.T*x+b w.T∗x+b可能会比1大很多或者是一个负数,这对于概率就失去了意义。
让逻辑回归中的输出yhat等于这个值应用sigmoid函数的结果。
G i v e x , w a n t y ^ = P ( y = 1 ∣ x ) , 其 中 ( 0 ≤ y ^ ≤ 1 ) Give\ \ x, want \ \ \widehat{y} = P(y =1 | x) \ \ ,其中 (0 ≤ \widehat{y} ≤1) Give x,want y =P(y=1∣x) ,其中(0≤y ≤1)

sigmoid函数是这样的,如果水平轴的标签为z,那么函数sigmoid(z)是这样的,它从0平滑地升高到1,它会在0.5处和竖直轴交叉。

因此这就是sigmoid(z)函数,这里z表示 ( w . T ∗ x + b ) (w.T*x+b) (w.T∗x+b)。
当z是一个实数,sigmoid(z)就等于 1 1 + e − z \frac 1 {1+e^{-z}} 1+e−z1
这里需要注意几件事情,如果z非常大时,e^(-z)就会接近0,所以sigmoid(z)就约等于 1 1 + 0 \frac 1 {1+0} 1+01,即等于1。就如上图显示,如果z非常大时,sigmoid(z)也就会越接近1。相反的,如果z非常小时,sigmoid(z)也就会越接近0。
因此当你实现逻辑回归时,你的目标是尽力学到参数w和b,因此yhat就能很好地估计y等于1的概率。
当进行神经网络编程时,我们通常会将参数w和参数b分开看待。这里的b对应一个偏置量。
一些其他的课程会这样做

事实上,实现神经网络时,将b和w当做互相独立的参数会更加简单。
接下来为了改变参数w和b,需要定义一个代价函数(逻辑回归代价函数)。
逻辑回归代价函数
为了优化逻辑回归模型的参数w和b,需要定义一个代价函数。

为了了解你的模型参数,这里有一组用于优化m参数的示例。,你会很自然想找出参数w和b,至少在获得训练集和输出值时,对于训练集的假定,我们只需提出y-hat(i)将接近从训练集中获得的实际y_i。为了更详细的描述上述方程式。
上标括号指的是数据
X、Y、Z以及其他字母与i-th训练示例相关联
损失函数(误差函数)可以用来检测算法运行情况,如在算法输出时定义损失,yhat和实标Y有可能是一个或者半个平方误差 L ( y ^ , y ) = 1 2 ( y ^ , y ) 2 L(\widehat{y},y) = \frac 1 2(\widehat{y},y)^2 L(y ,y)=21(y ,y)2,你可以如此操作,但是在一般逻辑回归里不进行此操作,因为当研究参数时,我们讨论的优化问题会变为非凸问题,所以优化问题会产生多个局部最优解,梯度算法也就无法找到全局最优解。
函数L被成为损失函数,需要进行设定,才能在实标为y时,对输出值yhat进行检测,平方误差整体是个合理的选择,除了无法让梯度下降算法良好运行,所以在逻辑回归中,我们回设定一个不同的损失函数充当平方误差,这样能产生一个凸象最优问题,将使之后的优化问题变得容易。所以,实际使用的逻辑回归损失函数为
L ( y ^ , y ) = − ( y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ) L(\widehat{y},y) = -(ylog\widehat{y} + (1-y)log(1-\widehat{y})) L(y ,y)=−(ylogy +(1−y)log(1−y ))
为什么使用这个损失函数有意义,如果使用平方误差,平方误差需要尽可能小,在此逻辑回归损失函数里,我们也要让这个数值尽可能小。
举个例子:
1、我们假定y=1,
L
(
y
^
,
y
)
=
−
l
o
g
y
^
L(\widehat{y},y) = -log\widehat{y}
L(y
,y)=−logy
,要使得L特别小,那么就要使得
l
o
g
y
^
log\widehat{y}
logy
数值必须特别大,但是
y
^
\widehat{y}
y
时sigmoid函数,它无法大于1,也是是说如果y=1,
y
^
\widehat{y}
y
值要尽可能打,但却打不过1,所以
y
^
\widehat{y}
y
要无限接近1。
2、我们假定y=0,即损失函数
L
(
y
^
,
y
)
=
−
l
o
g
(
1
−
y
^
)
L(\widehat{y},y) = -log(1-\widehat{y})
L(y
,y)=−log(1−y
),所以在学习过程中,需要将损失函数值变小,意味着
l
o
g
(
1
−
y
^
)
log(1-\widehat{y})
log(1−y
)的值要大,即要使得
y
^
\widehat{y}
y
尽可能的小。即如果y=0,损失函数将会作用于参数使得yhat无限趋近于0.
目前有很多函数具有拉菲拉效应,也就是如果y=1,yhat的值要变大;如果y=0,yhat的值要变小。
接下来设定代价函数,来检测优化组的整体运行情况,所以运用参数w和b的代价函数J是取m(训练集)的平均值、损失函数的总和运用于训练集,你的逻辑回归算法预计的输出值,用于一组特定的w和b参数。
所以我们要做的是损失函数适用于像这样单一的训练集。
代价函数:
C
o
s
t
F
u
n
c
t
i
o
n
:
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
y
^
,
y
)
=
−
1
m
(
∑
i
=
1
m
(
y
(
i
)
l
o
g
y
^
(
i
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
y
^
(
i
)
)
)
)
Cost \ Function: \ J(w,b) = \frac 1 m\displaystyle\sum_{i=1}^mL(\widehat{y},y) = -\frac 1 m(\displaystyle\sum_{i=1}^m(y^{(i)}log\widehat{y}^{(i)} + (1-y^{(i)})log(1-\widehat{y}^{(i)}) ))
Cost Function: J(w,b)=m1i=1∑mL(y
,y)=−m1(i=1∑m(y(i)logy
(i)+(1−y(i))log(1−y
(i))))
L ( y ^ , y ) = − ( y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ) L(\widehat{y},y) = -(ylog\widehat{y} + (1-y)log(1-\widehat{y})) L(y ,y)=−(ylogy +(1−y)log(1−y )),此损失函数,只适用于单个的训练样本。
Cost Function基于参数的总损失,所以在训练逻辑回归模型时,我们要找到合适的参数w和b,让代价函数J尽可能地小。
逻辑回归可以被看作是一个非常小的神经网络。
Tips:符号定义
x:表示一个 n x n_x nx维数据,为输入数据,维度为( n x n_x nx,1)
y:表示输出的结果,取值为(0,1)
( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)):表示第i组数据,可能是训练数据,也可能是测试数据,此处默认为训练数据。
X = [ ( x ( 1 ) , x ( 2 ) , . . . , x ( m ) ) ] X=[(x^{(1)},x^{(2)},...,x^{(m)})] X=[(x(1),x(2),...,x(m))]:表示所有训练数据集的输入值,放在一个 n x n_x nxx m的矩阵中,其中m表示样本数目。
Y = [ ( y ( 1 ) , y ( 2 ) , . . . , y ( m ) ) ] Y=[(y^{(1)},y^{(2)},...,y^{(m)})] Y=[(y(1),y(2),...,y(m))]:表示所有训练数据集的输出值,维度为 1 x m。





![[附源码]计算机毕业设计JAVA基于web的电子产品网络购物平台](https://img-blog.csdnimg.cn/c3443017e63f4c3c8b96991be3d151f2.png)