文章目录
- 1 实验背景与要求
- 1.1 TCP的数据分片与重组问题
- 1.2 实验具体任务
- 2 重组器的设计架构
- 2.1 整体架构
- 2.2 数据结构设计
- 3 重组器处理的关键场景分析
- 3.1 按序到达的子串(直接写入)
- 3.2 乱序到达的子串(需要存储)
- 3.3 与已处理区域重叠的子串
- 3.4 与待处理子串重叠的情况
- 3.5 超出容量的子串
- 3.6 结束标记处理
- 4 insert方法的实现流程
- 4.1 入口处理
- 4.2 已处理字节的检查
- 4.3 容量限制检查
- 4.4 直接写入处理
- 4.5 子串存储与合并
- 4.6 结束处理
- 5 count_bytes_pending实现
- 6 调试经验
1 实验背景与要求
在网络传输的过程中,TCP协议必须解决一个关键挑战:如何将不可靠的网络上传输的、可能乱序、丢失、重复或重叠的数据包片段重新组装成连续的字节流?这正是Stanford CS144 Lab1中我们要实现的Reassembler(重组器)组件的核心功能。
1.1 TCP的数据分片与重组问题
TCP协议在发送数据时,会将应用层的字节流划分为多个较小的段(segment),每个段封装在一个IP数据包中进行传输。然而,在网络传输过程中,这些数据包可能会:
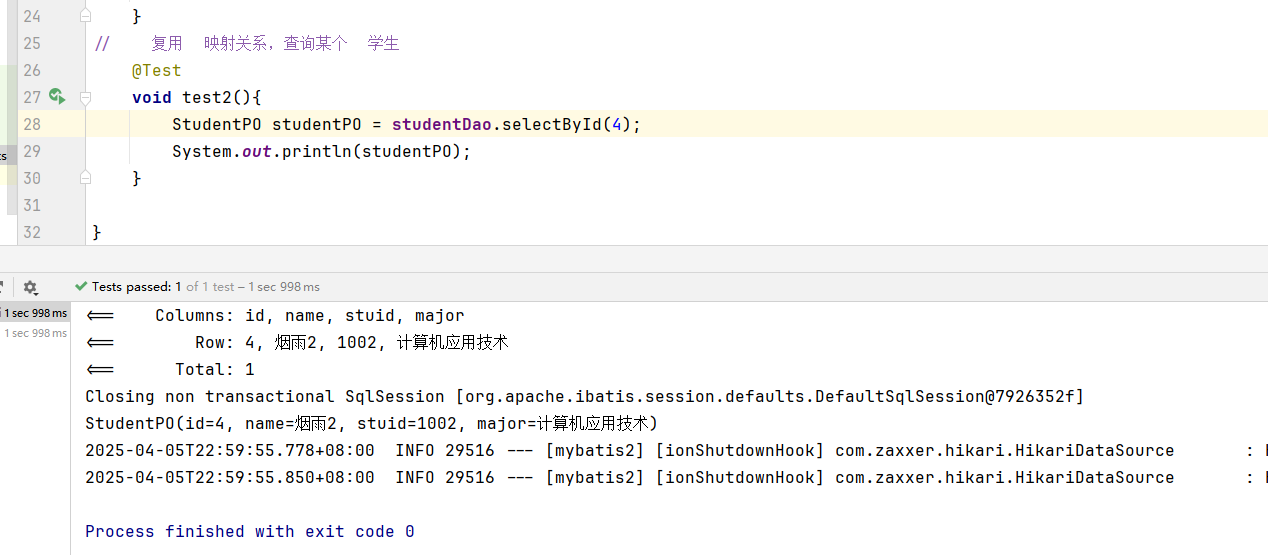
- 乱序到达:后发送的数据包可能先到达
- 完全丢失:某些数据包永远不会到达目的地
- 重复到达:同一个数据包可能被网络复制并多次传递
- 部分重叠:重传的包可能与原包内容有部分重叠
接收方必须能够处理这些情况,将所有正确接收的数据按照原始顺序重新组装成连续的字节流,并传递给应用层。这就是重组器(Reassembler)需要解决的问题。
1.2 实验具体任务
在Lab1中,我们需要实现一个Reassembler类,其主要API如下:
// 插入一个新的子字符串,以便重组为一个ByteStream
void insert(uint64_t first_index, std::string data, bool is_last_substring);
// 计算重组器内部存储的字节数量
uint64_t count_bytes_pending() const;
// 访问输出流的读取器
Reader& reader();
这个重组器要处理以下核心任务:
- 子串的重组:将不同的子串按照它们在原始流中的顺序重新组装
- 对ByteStream的写入:尽快地将重组好的字节写入输出流
- 内部存储管理:对于暂时无法写入(存在空洞)的子串进行存储
- 容量限制:考虑ByteStream容量限制,丢弃超出容量的字节
- 流结束处理:当接收到标记为最后的子串,并且所有数据都已写入时,关闭输出流
Github的实现代码:https://github.com/HeZephyr/minnow
2 重组器的设计架构
2.1 整体架构
重组器的整体架构如下图所示:
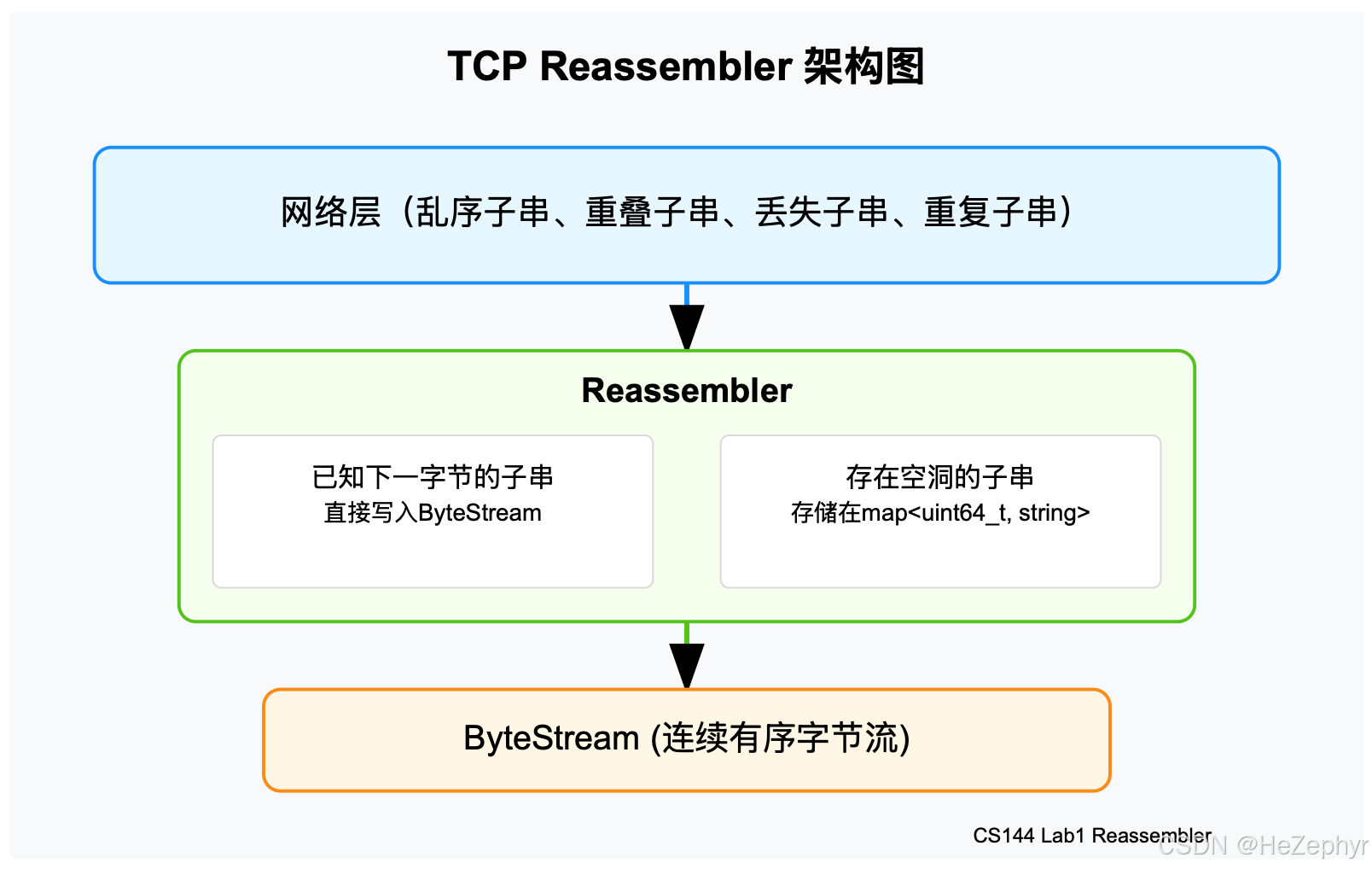
重组器处于网络层和应用层之间,负责将网络传输的不可靠、乱序的数据片段转换为应用层可以使用的可靠、有序的字节流。它的内部需要处理两种情况:
- 可以直接写入ByteStream的子串(下一个期望的字节)
- 需要暂时存储的子串(存在空洞,不能立即写入)
2.2 数据结构设计
为了实现重组器的功能,我们需要设计适当的数据结构。这里我选择了以下成员变量:
ByteStream output_; // 输出流
uint64_t next_index_ = 0; // 下一个要写入的字节索引
bool eof_ = false; // 是否收到了标记为最后的子串
uint64_t eof_index_ = 0; // 流的结束索引位置
std::map<uint64_t, std::string> unassembled_; // 存储未组装的子串
这些数据结构的详细说明:
- ByteStream output_:重组器将重组好的数据写入这个流,应用程序从这个流的读取端获取数据
- uint64_t next_index_:表示下一个期望接收的字节的索引位置,初始值为0,每写入一个字节就增加1。用于判断新到的子串是否可以直接写入
- bool eof_:标记是否已收到流的最后一个子串,当收到
is_last_substring=true的子串时设置为true - uint64_t eof_index_:记录流的总长度(最后一个字节之后的位置),当
next_index_ == eof_index_时,表示所有数据都已处理完毕 - std::map<uint64_t, std::string> unassembled_:存储那些已接收但因为前面有空洞而不能立即写入的子串,键为子串的起始索引,值为子串内容,使用map可以自动按索引排序,便于查找和合并
这种设计的优势在于:
- 使用有序映射(std::map)能够高效地管理乱序到达的子串
- 通过比较
next_index_和子串的起始位置,可以快速判断子串是否可以直接写入 - 当空洞被填补时,能够方便地找到并处理下一个连续的子串
3 重组器处理的关键场景分析
在实现重组器时,需要处理多种不同的子串到达场景。以下通过图解分析重组器需要处理的典型情况:
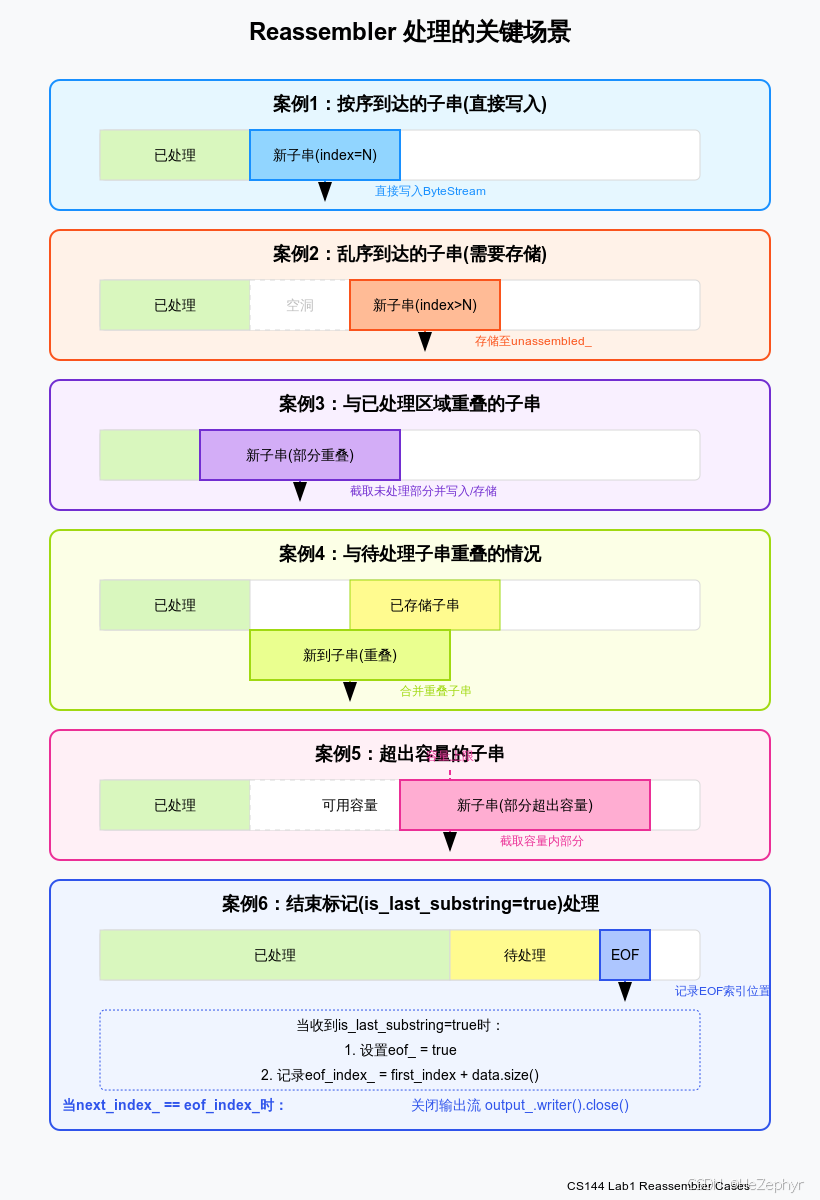
3.1 按序到达的子串(直接写入)
当接收到的子串的起始索引恰好等于当前期望的下一个字节索引(first_index == next_index_)时,可以直接将该子串写入输出流。这是最简单的情况,不需要任何临时存储。
处理逻辑:
- 将子串内容通过
output_.writer().push(data)直接写入ByteStream - 更新
next_index_ += data.size() - 检查是否有后续已存储的子串现在可以连续写入
示例:假设当前next_index_ = 5,收到子串insert(5, "hello", false),可以直接将"hello"写入ByteStream,并更新next_index_ = 10
3.2 乱序到达的子串(需要存储)
当接收到的子串起始索引大于当前期望的下一个字节索引(first_index > next_index_)时,表示中间存在"空洞"。这种情况下,需要将子串临时存储在unassembled_映射中,等待空洞被填补。
处理逻辑:
- 检查子串是否超出容量限制
- 如果未超出,将子串存储在
unassembled_[first_index] = data - 可能需要处理与已存储子串的重叠情况
示例:假设当前next_index_ = 5,收到子串insert(10, "world", false),由于10 > 5,表示5-9的字节尚未收到,将"world"存储在unassembled_[10] = "world",等待空洞被填补。
3.3 与已处理区域重叠的子串
有时接收到的子串可能与已处理的区域有重叠(first_index < next_index_)。在这种情况下,需要截取未处理的部分进行处理。
处理逻辑:
- 计算重叠部分:
overlap = next_index_ - first_index - 截取未处理部分:
data.substr(overlap) - 按照非重叠子串的处理方式继续处理
示例:假设当前next_index_ = 5,收到子串insert(3, "hello", false),字节3-4已处理,只需要处理"llo",截取后处理:data = data.substr(2) -> “llo”,使用新索引first_index = 5和新数据"llo"继续处理。
3.4 与待处理子串重叠的情况
当新到达的子串与已经存储在unassembled_中的子串有重叠时,需要合并这些子串以避免重复存储。
处理逻辑:
- 查找可能重叠的子串:使用
lower_bound和前向遍历 - 检查前面的子串是否与当前子串重叠
- 检查后面的子串是否与当前子串重叠
- 合并所有重叠的子串,生成一个更大的连续子串
- 更新
unassembled_映射
示例:假设已存储unassembled_[10] = "world",收到新子串insert(8, "hellowr", false),检测到重叠:8+8 > 10,合并为一个更大的子串:“hellowrld”,更新unassembled_[8] = "hellowrld",并删除原来的条目。
3.5 超出容量的子串
ByteStream有固定容量,而重组器应该尊重这个容量限制。对于超出容量的子串部分,应该直接丢弃。
处理逻辑:
- 计算可接受的最大索引:
acceptable_end = next_index_ + output_.writer().available_capacity() - 判断子串是否完全超出:
first_index >= acceptable_end - 对于部分超出的子串,截取有效部分:
actual_end = min(first_index + data.size(), acceptable_end)
示例:假设当前next_index_ = 5,可用容量为10,可接受的最大索引为5 + 10 = 15,收到子串insert(12, "hello world", false),由于"hello world"长度为11,超出了可接受范围,截取前3个字节"hel"进行处理,丢弃后续字节。
3.6 结束标记处理
当收到标记为最后的子串(is_last_substring = true)时,需要记录流的结束位置,并在所有数据都处理完毕时关闭输出流。
处理逻辑:
- 设置
eof_ = true - 计算并记录结束索引:
eof_index_ = first_index + data.size() - 在每次处理完子串后,检查
next_index_ == eof_index_ - 如果条件满足且
eof_ == true,调用output_.writer().close()关闭流
示例:假设已处理到next_index_ = 15,收到子串insert(15, "end", true),设置eof_ = true,eof_index_ = 15 + 3 = 18,处理完"end"后,next_index_ = 18,由于next_index_ == eof_index_且eof_ == true,关闭输出流。
4 insert方法的实现流程
4.1 入口处理
首先,处理一些边界情况:
- 空字符串的特殊处理,特别是当它被标记为最后一个子串时
- 记录EOF信息,包括是否到达EOF以及EOF的确切位置
void Reassembler::insert(uint64_t first_index, string data, bool is_last_substring)
{
// 处理空字符串情况
if (data.empty()) {
if (is_last_substring) {
eof_ = true;
eof_index_ = first_index;
if (next_index_ == eof_index_) {
output_.writer().close();
}
}
return;
}
// 更新EOF信息
if (is_last_substring) {
eof_ = true;
eof_index_ = first_index + data.size();
}
4.2 已处理字节的检查
接下来,检查子串是否已经完全处理过,如果子串的结束位置不超过当前已处理的位置,则整个子串都已被处理,可以直接返回。
// 丢弃完全在已处理范围内的子串
if (first_index + data.size() <= next_index_) {
// 子串完全在已处理的范围内,忽略
if (eof_ && next_index_ == eof_index_) {
output_.writer().close();
}
return;
}
4.3 容量限制检查
然后,我们需要考虑ByteStream的容量限制:
- 计算ByteStream的可用容量
- 确定可接受的最大索引位置
- 对于超出容量的子串,只保留在容量范围内的部分
- 通过截取得到可用的子串部分
// 计算ByteStream可用容量
uint64_t available_capacity = output_.writer().available_capacity();
// 计算这个子串在可接受范围内的结束位置
uint64_t acceptable_end = next_index_ + available_capacity;
// 如果子串起始位置超出可接受范围,丢弃
if (first_index >= acceptable_end) {
return;
}
// 截取子串中在可接受范围内的部分
uint64_t actual_start = max(first_index, next_index_);
uint64_t actual_end = min(first_index + data.size(), acceptable_end);
// 子串中有效部分的偏移量和长度
uint64_t offset = actual_start - first_index;
uint64_t length = actual_end - actual_start;
// 截取可用部分
string usable_data = data.substr(offset, length);
uint64_t usable_index = actual_start;
4.4 直接写入处理
如果子串正好是下一个期望的字节,可以直接写入:
- 将可用的子串直接写入ByteStream
- 更新
next_index_ - 检查
unassembled_中是否有可以继续写入的子串 - 尝试写入尽可能多的连续子串
// 如果可以直接写入输出流
if (usable_index == next_index_) {
output_.writer().push(usable_data);
next_index_ += usable_data.size();
// 检查是否有更多可以写入的子串
while (!unassembled_.empty()) {
auto it = unassembled_.begin();
if (it->first > next_index_) {
break; // 有空洞,不能继续写入
}
// 计算这个子串中有多少新的字节
uint64_t overlap = next_index_ - it->first;
if (overlap < it->second.size()) {
string new_data = it->second.substr(overlap);
output_.writer().push(new_data);
next_index_ += new_data.size();
}
// 移除已处理的子串
unassembled_.erase(it);
}
4.5 子串存储与合并
如果子串不能直接写入,需要存储并处理可能的重叠:
- 使用
lower_bound查找可能重叠的子串 - 检查并合并与前面子串的重叠
- 检查并合并与后面子串的重叠
- 存储合并后的子串
} else if (usable_data.size() > 0) {
// 将子串添加到未组装的映射中
// 首先检查是否有重叠的子串,可能需要合并
auto it = unassembled_.lower_bound(usable_index);
// 检查前面的子串
if (it != unassembled_.begin()) {
auto prev = prev(it);
uint64_t prev_end = prev->first + prev->second.size();
// 如果前面的子串与当前子串重叠或相邻
if (prev_end >= usable_index) {
// 合并子串
if (prev_end < usable_index + usable_data.size()) {
uint64_t extend_len = usable_index + usable_data.size() - prev_end;
prev->second += usable_data.substr(usable_data.size() - extend_len);
}
// 如果完全被前面的子串覆盖,则无需存储
if (prev_end >= usable_index + usable_data.size()) {
// 检查是否已完成
if (eof_ && next_index_ == eof_index_) {
output_.writer().close();
}
return;
}
// 更新待处理的子串信息
usable_index = prev->first;
usable_data = prev->second;
unassembled_.erase(prev);
}
}
// 检查和合并后面的子串
while (it != unassembled_.end() && it->first <= usable_index + usable_data.size()) {
uint64_t it_end = it->first + it->second.size();
// 如果后面的子串延伸超过当前子串
if (it_end > usable_index + usable_data.size()) {
uint64_t extend_len = it_end - (usable_index + usable_data.size());
usable_data += it->second.substr(it->second.size() - extend_len);
}
auto to_erase = it;
++it;
unassembled_.erase(to_erase);
}
// 存储合并后的子串
unassembled_[usable_index] = usable_data;
}
4.6 结束处理
最后,检查是否需要关闭输出流:当所有预期的数据都已处理完毕,且已收到标记为最后的子串时,关闭输出流。
// 检查是否已经处理完所有数据
if (eof_ && next_index_ == eof_index_) {
output_.writer().close();
}
}
5 count_bytes_pending实现
除了insert方法外,还需要实现count_bytes_pending方法来计算未组装的字节数:
- 只计算未处理的部分(排除与已处理区域重叠的部分)
- 由于子串可能有重叠,需要计算每个子串的有效长度
uint64_t Reassembler::count_bytes_pending() const
{
uint64_t total = 0;
for (const auto& [index, data] : unassembled_) {
// 只计算还未处理的字节
if (index + data.size() > next_index_) {
uint64_t valid_start = max(index, next_index_);
total += (index + data.size()) - valid_start;
}
}
return total;
}
6 调试经验
- 最困难的部分是正确处理子串重叠,考虑子串重叠处理的边界情况。实现之前最好使用纸笔推演各种情况,确保边界处理正确。
- 考虑容量限制。需明确区分ByteStream的容量和Reassembler可以存储的字节数,确保两者之和不超过总容量。
- 确定何时检查并关闭输出流。建议在每次处理子串后都检查是否满足关闭条件,确保不会错过关闭时机。



![协同推荐算法实现的智能商品推荐系统 - [基于springboot +vue]](https://i-blog.csdnimg.cn/direct/f56aace797e04e46aac5ee9783213d0b.png)