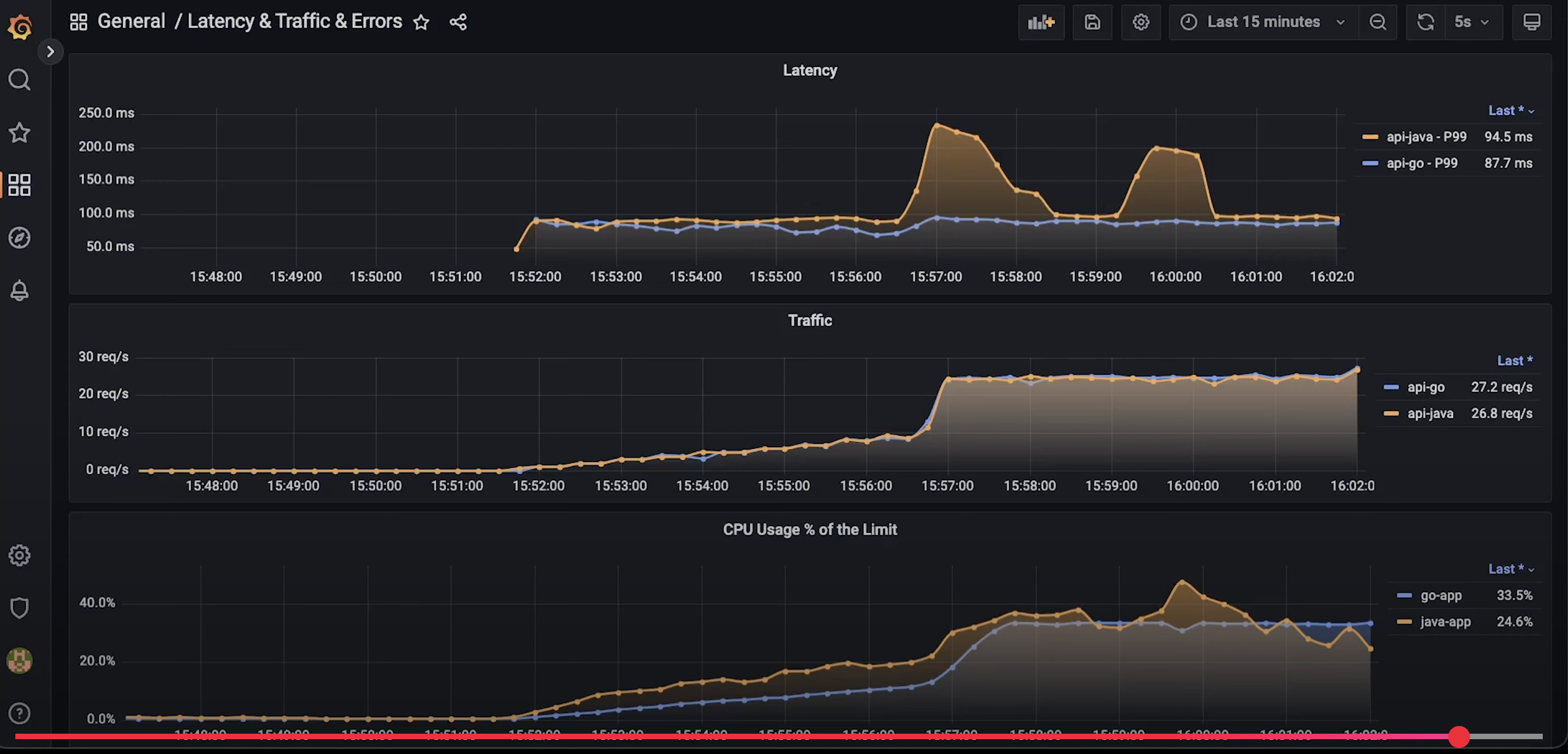
- 保证事务持久性,用于崩溃恢复,崩溃恢复时,把redo上记载的页读到内存,对其修改,变为脏页,刷盘
- 运用于WAL技术,将随机写改为顺序写
redo log有三种状态:
- 存在 redo log buffer 中,物理上是在 MySQL 进程内存中
- 写到内核中的一片缓冲区 (write),但是没有持久化(fsync) 到硬盘,物理上是在文件系统的 page cache 里面
- 持久化到磁盘
innodb_flush_log_at_trx_commit 参数,它有三种可能取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 (啥也不干,纯靠后台线程帮忙持久化);
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘(write + fsync);
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache(write)。
事务还没提交,redo会被持久化到硬盘吗?
- 第一种情况:InnoDB 有一个后台线程,每隔 1 秒轮询一次,具体的操作是这样的:调用 write 将 redolog buffer 中的日志写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。而在事务执行中间过程的 redolog 都是直接写在 redolog buffer 中的,也就是说,一个没有提交的事务的 redolog,也是有可能会被后台线程一起持久化到磁盘的。
- 第二种情况:假设事务 A 执行到一半,已经写了一些 redolog 到 redolog buffer 中,这时候有另外一个事务 B 提交,按照 innodb_flush_log_at_trx_commit = 1 的逻辑,事务 B 要把 redolog buffer 里的日志全部持久化到磁盘,这时候,就会带上事务 A 在 redolog buffer 里的日志一起持久化到磁盘,(redolog buffer事务共享)
- 第三种情况:redo log buffer 占用的空间达到 redolog buffer 大小(由参数 innodb_log_buffer_size 控制,默认是 8MB)一半的时候,后台线程会主动写盘。不过由于这个事务并没有提交,所以这个写盘动作只是 write 到了文件系统的 page cache,仍然是在内存中,并没有调用 fsync 真正落盘
redo log 记录了此次事务「完成后」的数据状态,记录的是更新之后的值;
undo log 记录了此次事务「开始前」的数据状态,记录的是更新之前的值;