RabbitMQ
概述
- RabbitMQ 是⼀个开源的⾼性能、可扩展、消息中间件(Message Broker),实现了 Advanced Message
Queuing Protocol(AMQP)协议,可以帮助不同应⽤程序之间进⾏通信和数据交换。 - RabbitMQ 是由 Erlang 开发的,⽀持多种编程语⾔,包括 Java、Python、Ruby、PHP、C# 等。它的
核⼼思想是将发送者(producer)与接收者(consumer)完全解耦,实现异步处理和低耦合度的系统架构。
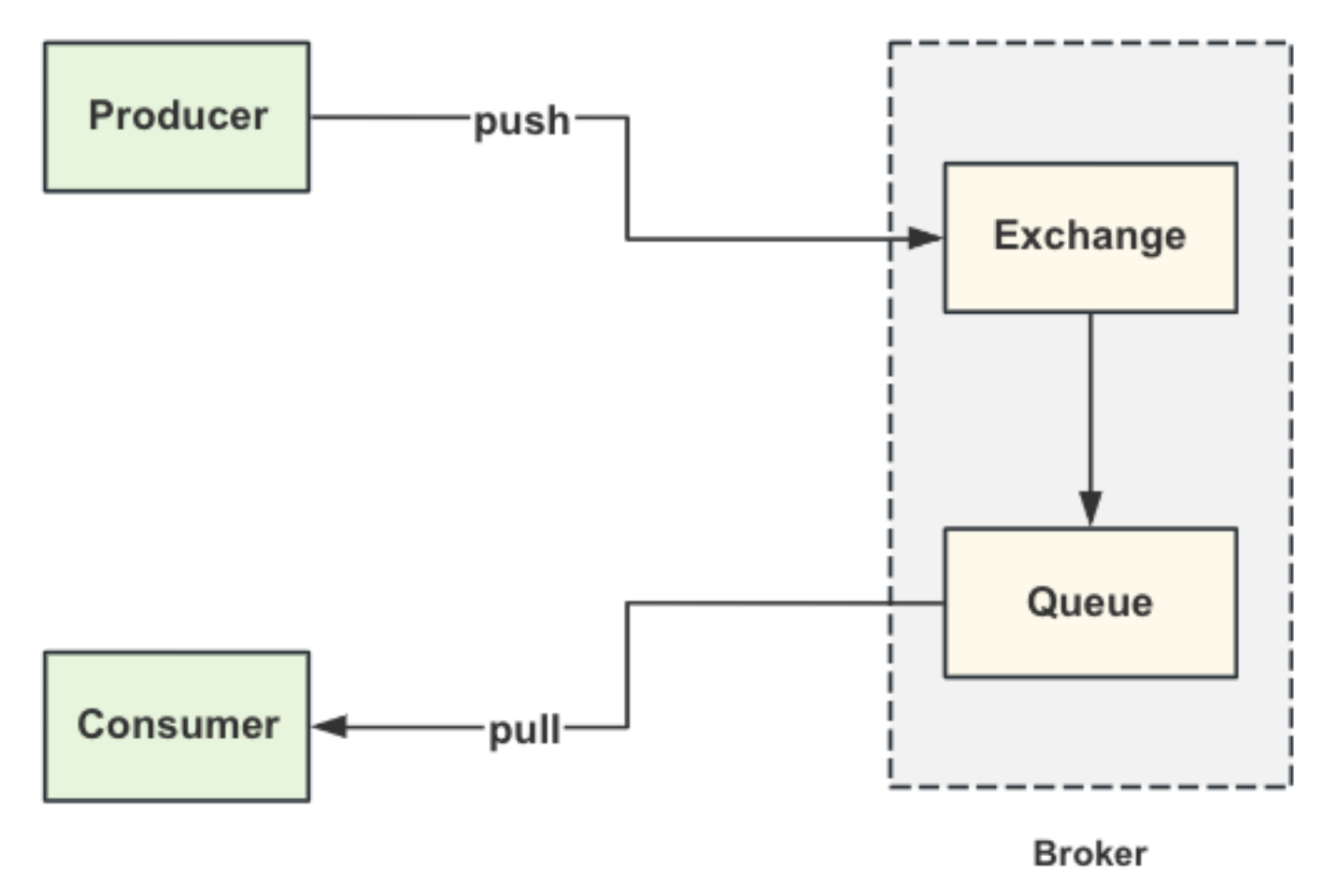
RabbitMQ的消息消费链路
消息会exchange复制,然后派发到多个不同的队列上。同⼀条消息需要占⽤多份存储空间,空间利⽤率不是很⾼。
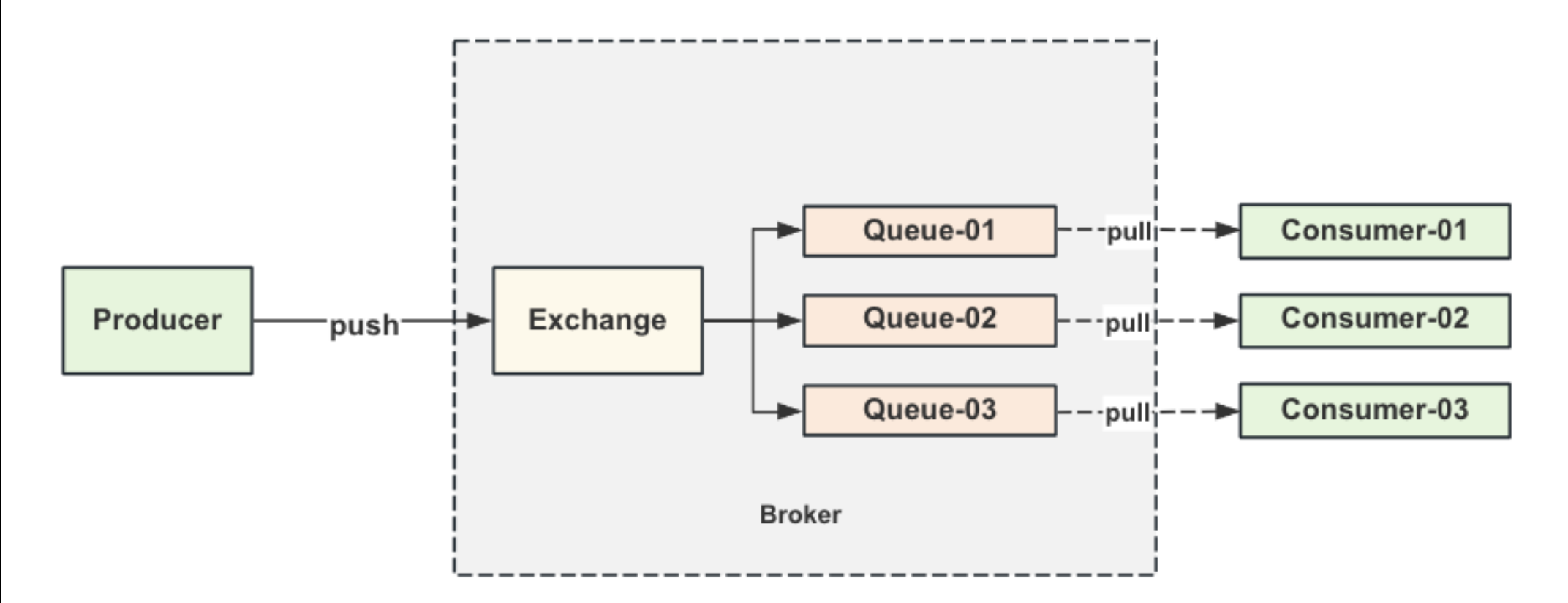
Broker
在消息队列(Message Queue,MQ)系统中,Broker 是核心组件,负责消息的接收、存储、路由和传递。它作为消息中间件的服务器端,协调生产者(Producer)和消费者(Consumer)之间的通信,确保消息可靠传输。
Broker 的工作流程
-
生产者将消息发送到 Broker。
-
Broker 根据配置的路由规则将消息存储到指定队列或主题。
-
Broker 将消息推送给消费者(Push 模式)或等待消费者拉取(Pull 模式)。
-
Broker 确认消息消费成功(ACK 机制),或重新投递未确认的消息。
Broker 的重要性
-
解耦:分离生产者和消费者,允许系统异步通信。
-
削峰填谷:应对流量高峰,避免服务过载。
-
可靠性:通过持久化和重试机制确保消息不丢失。
-
扩展性:通过集群横向扩展处理能力。
选择 Broker 的考量因素
-
性能:吞吐量、延迟(如 Kafka 适合高吞吐,RabbitMQ 适合低延迟)。
-
持久化机制:是否需要保证消息不丢失。
-
协议支持:是否兼容现有系统。
-
运维复杂度:集群管理、监控工具是否完善。
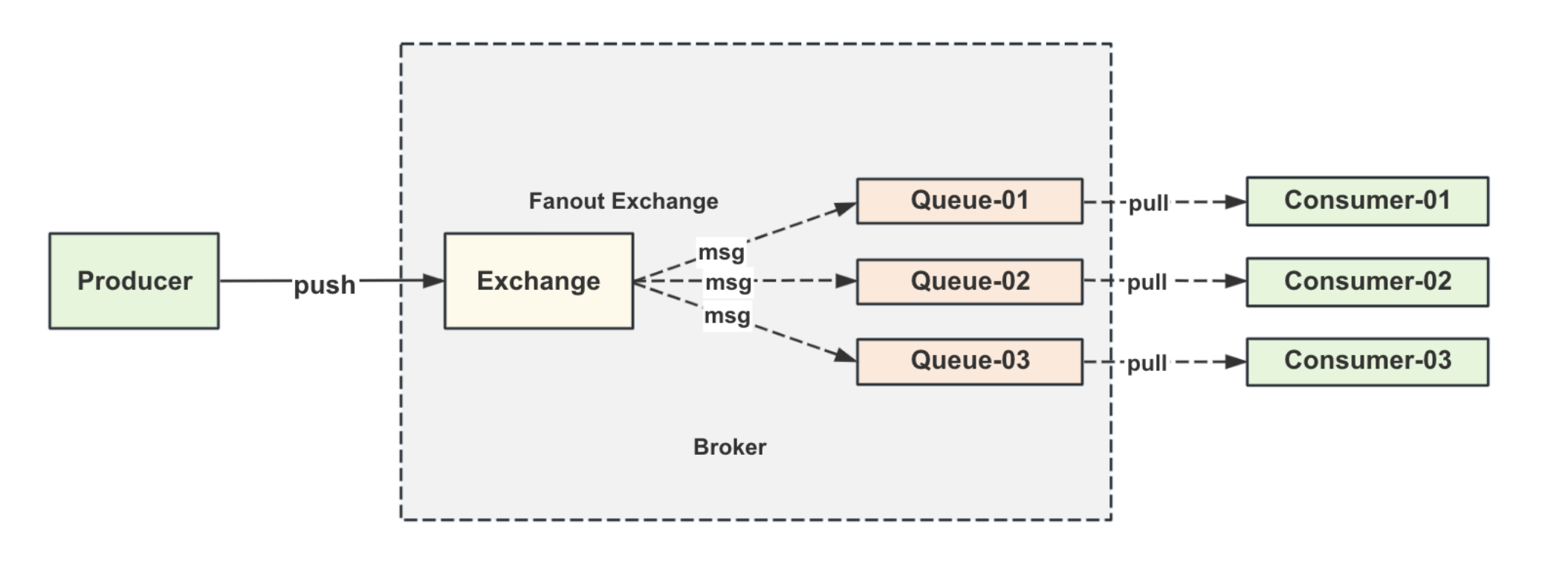
Exchange机制
Fanout类型
Fanout即⼴播模式
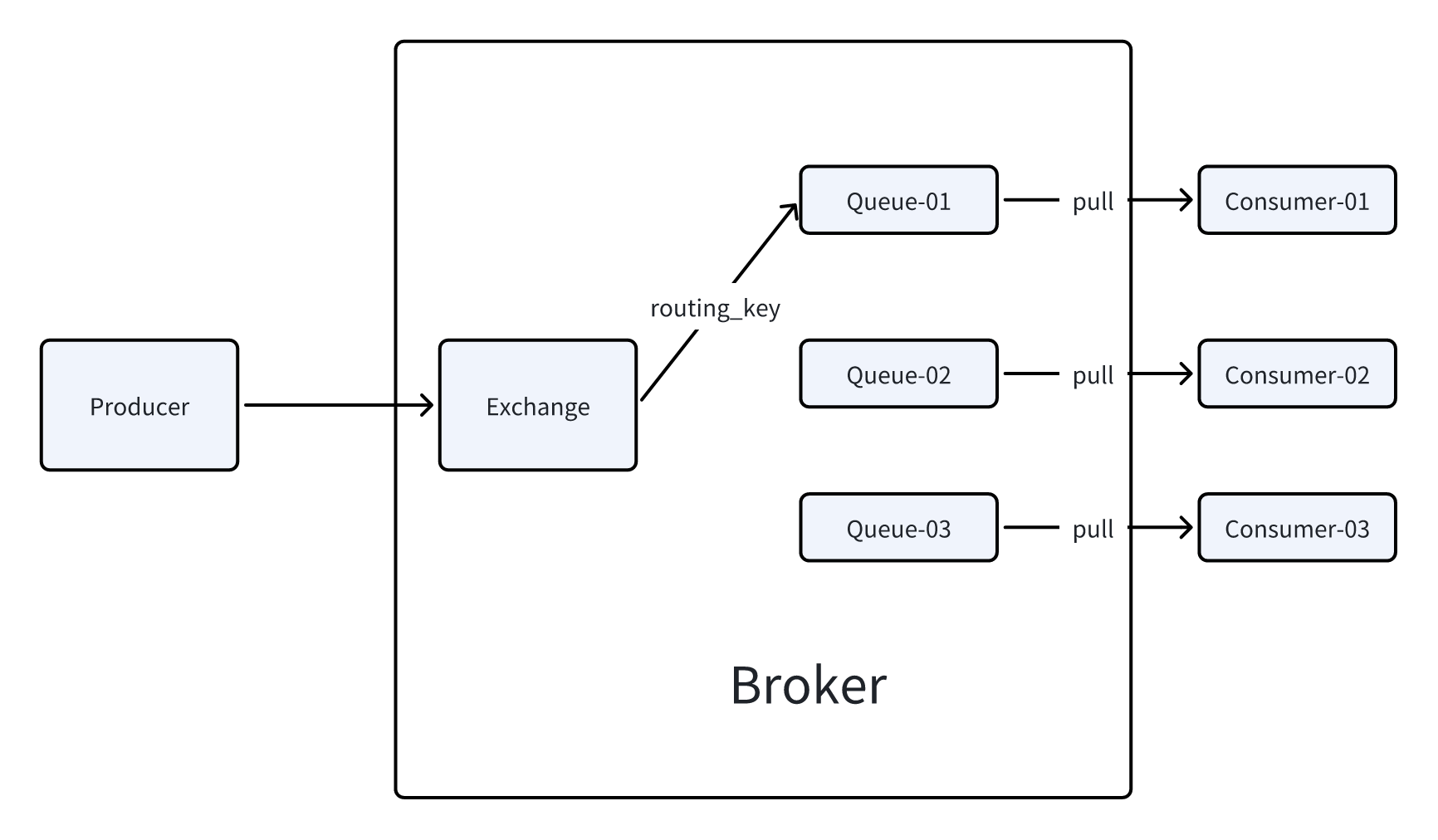
Direct类型
根据routing_key将消息投递到指定的队列上。
Topic类型
更加灵活的routing_key, ⽀持⽤通配符的⽅式处理消息的投递。
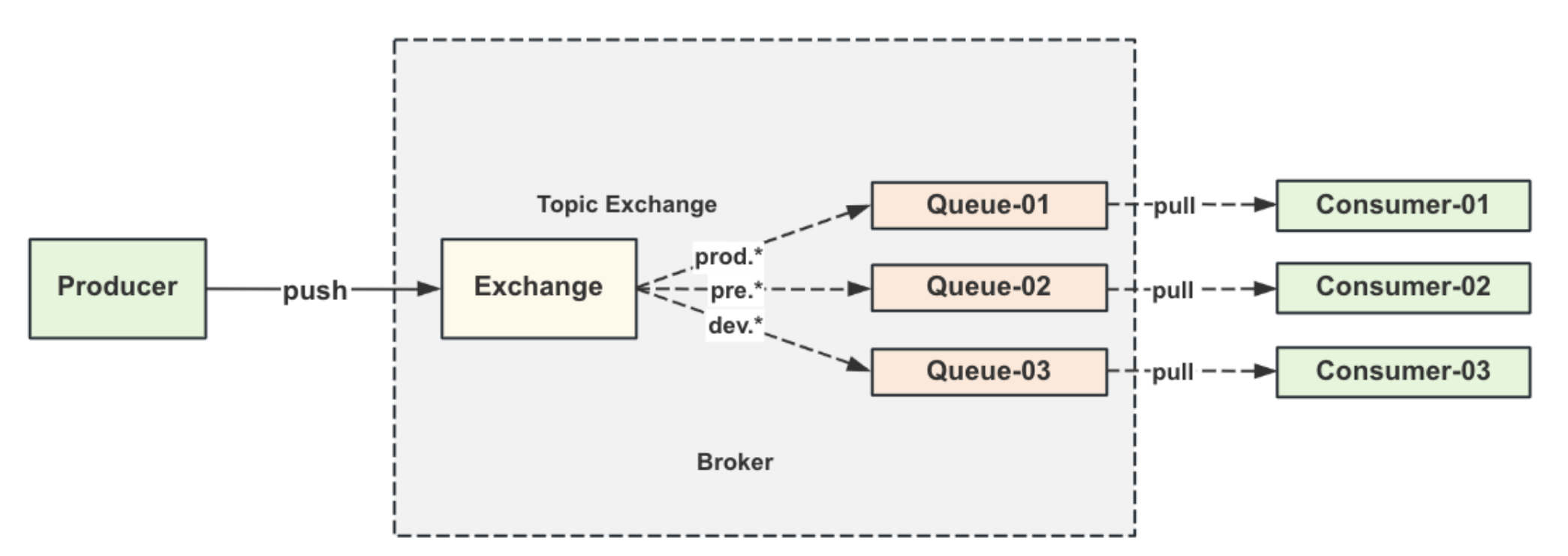
Header类型
更为细粒度的匹配逻辑,在投递消息的请求头上,注⼊多个header参数,路由规则是根据header的参 数去决定要投递哪个队列。
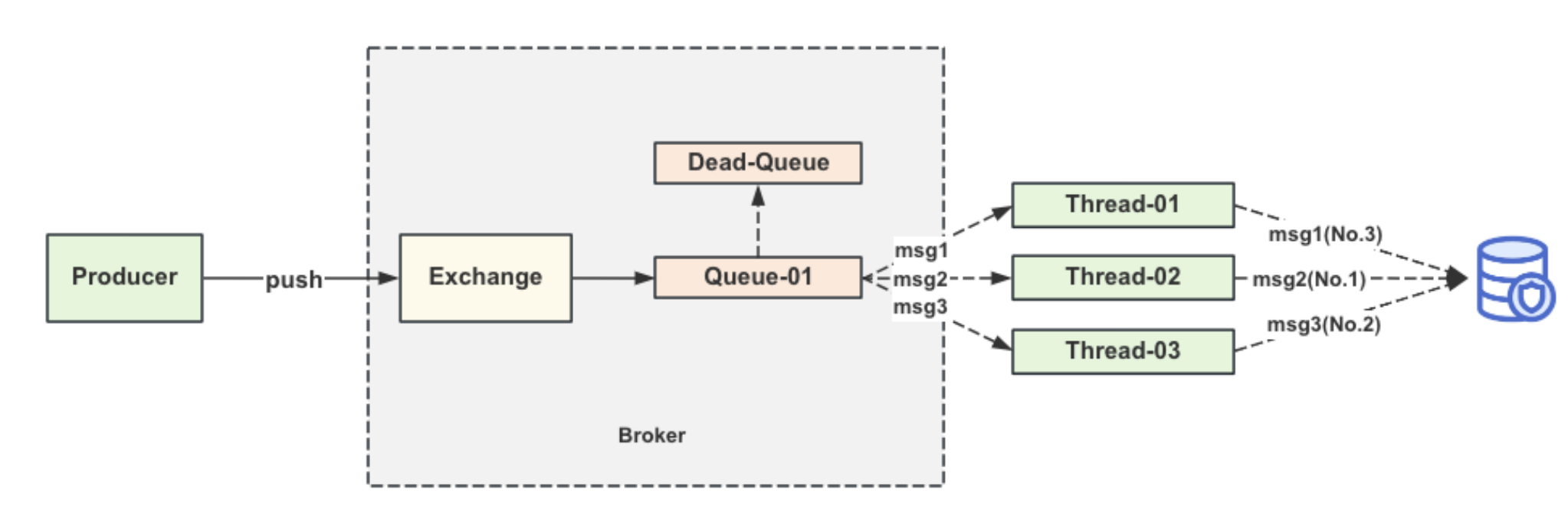
消息错误处理
- 消费异常的数据,会被投递到⼀条死信队列⾥⾯,后边重新再拉取消费。
- 消费端消费消息,写⼊db。(db的连接池满了,数据写⼊失败。消息重试:晚点再消费⼀次消息,过 ⼀段时间再去消费。)
消息顺序消费设计
RabbitMQ的顺序消费能⼒不⾏,消费者如果使⽤多线程消费,⽆法保证多线程的处理顺序。
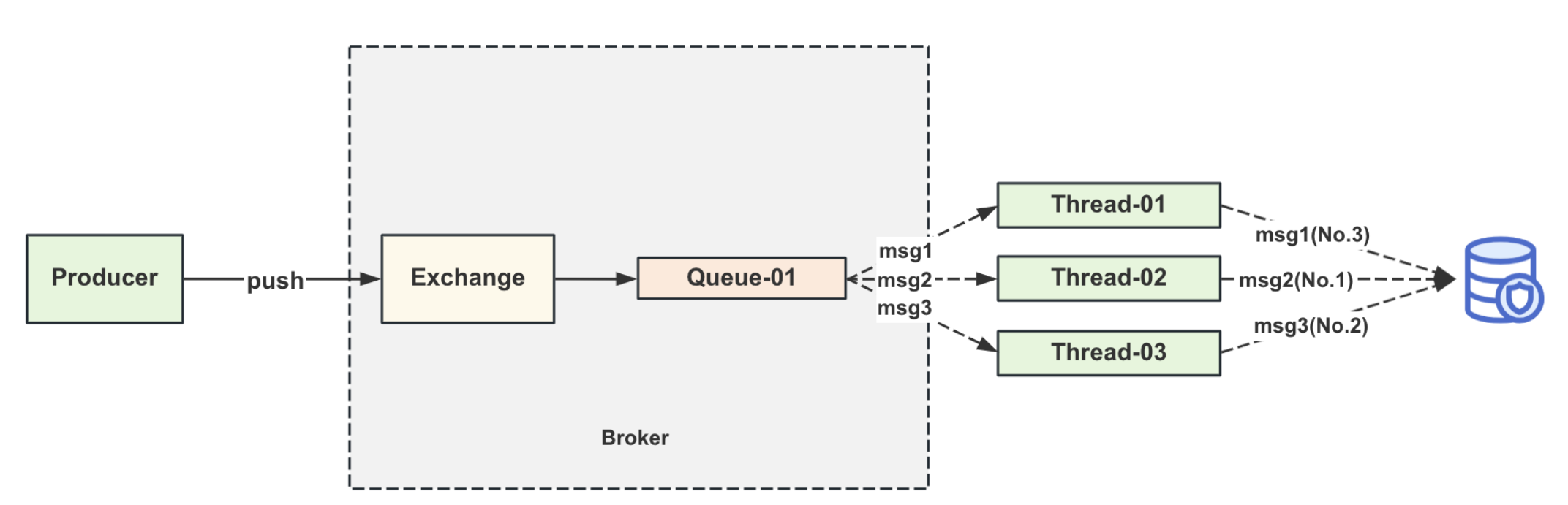
多个消费者对应⼀条队列,也是会有顺序错乱的问题。
RocketMQ
组成部分
- Broker
- NameServer(注册中⼼)
客⼾端和NameServer建⽴⻓链接,然后获取得到Broker的地址,再去访问Broker进⾏消息的投递和消费。
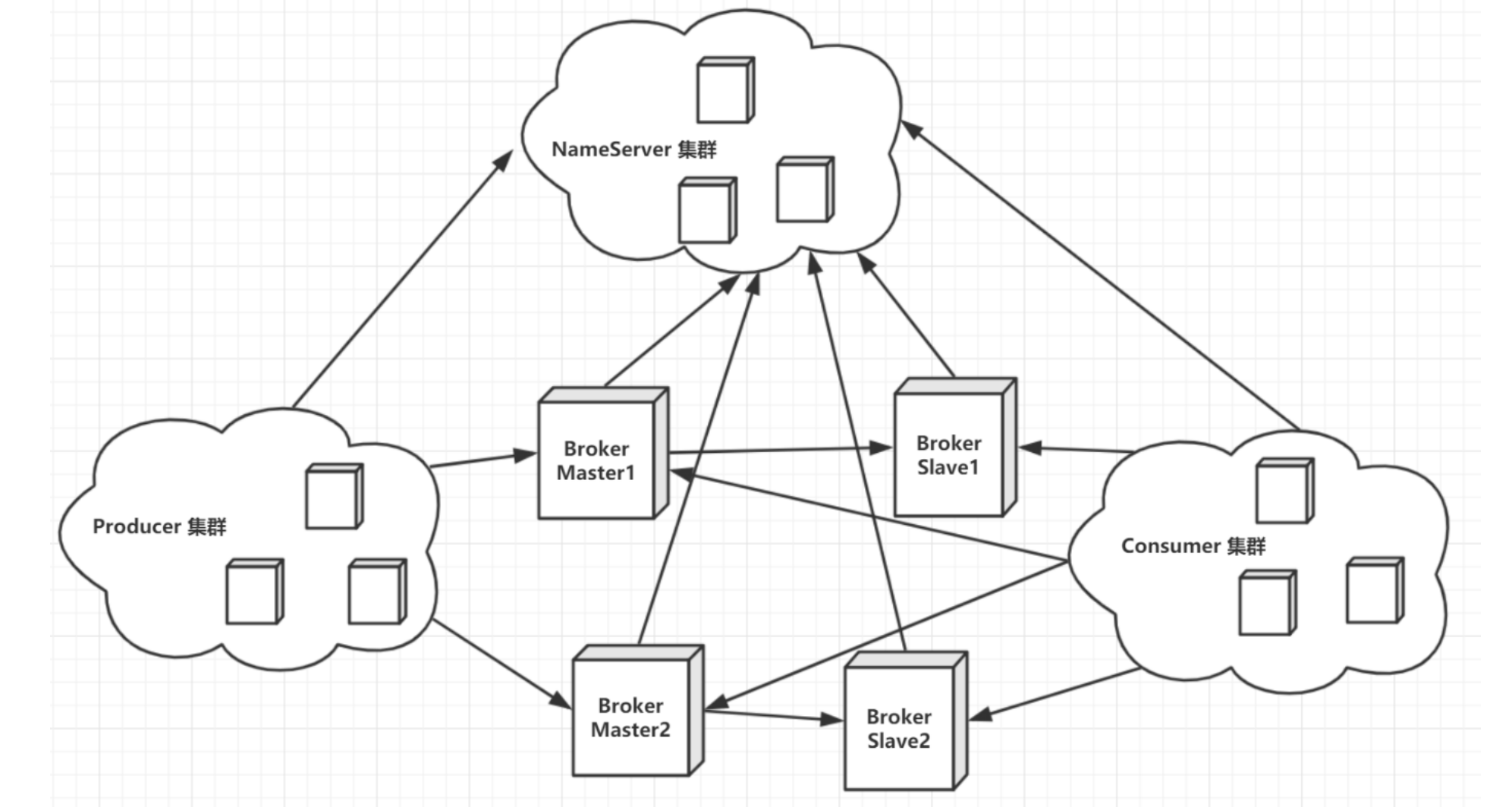
长连接(Long Connection):客户端与服务器建立TCP连接后,在完成一次请求后不会立即关闭连接,而是保持连接状态,以便后续多次通信复用该连接。
RocketMQ的发送链路
消息会先被发送到broker端存储,然后触发⼀个 dispatch 的动作,将消息的“索引信息”投递到不同的消费队列上边。最后每个消费者和具体的⼀条队列绑定关系后,便可以从队列中拉取最新 dispatch 过来的消息。
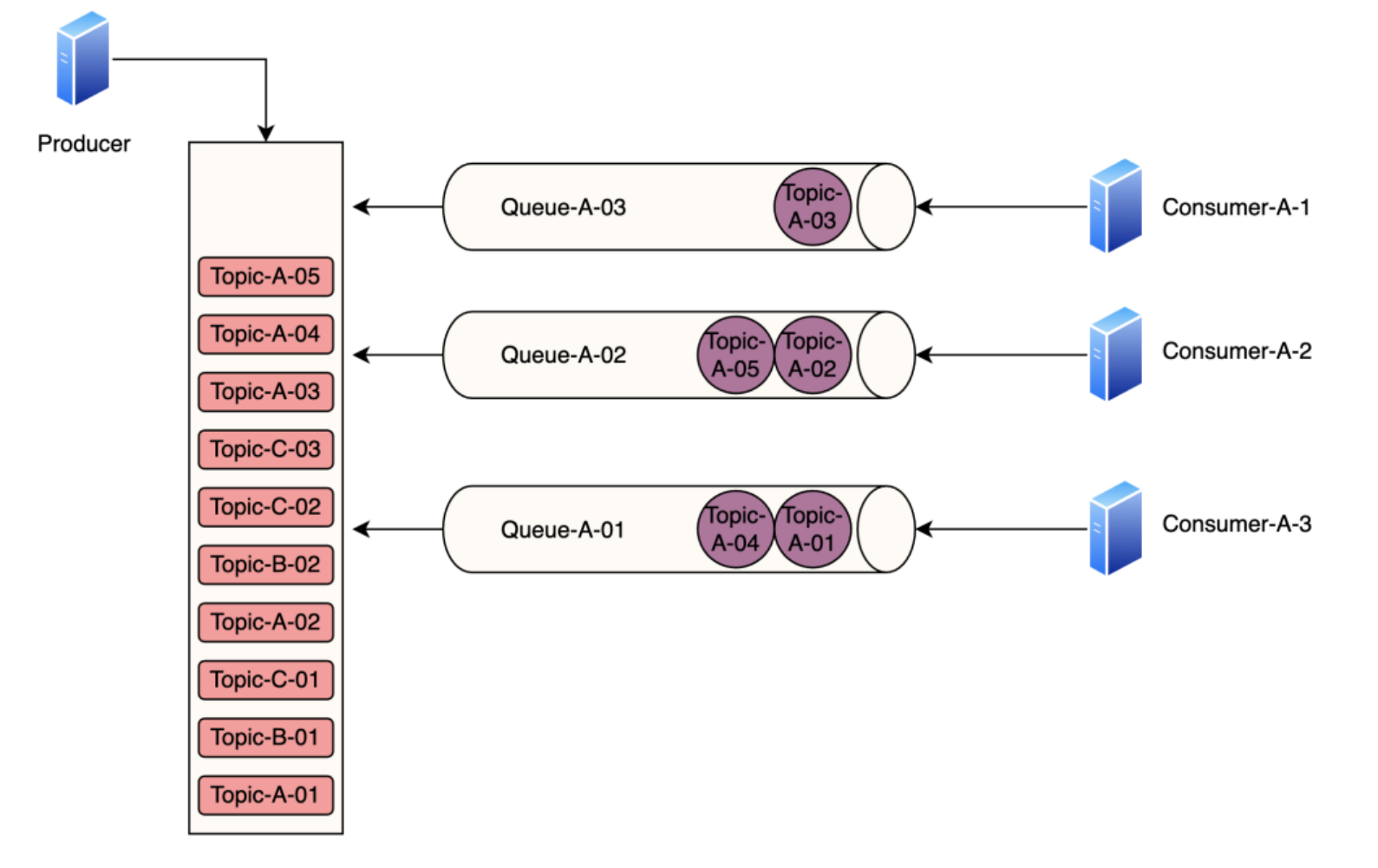
从RocketMQ和RabbitMQ的消息发送链路来看,会有⼀些出⼊:
• RocketMQ的消息主要都存放在了CommitLog⾥⾯,在消费队列存储的是消息的“索引”信息。
• RocketMQ的⼀条队列,⼀次只能允许被⼀个消费者占⽤,不能让多个消费者访问。
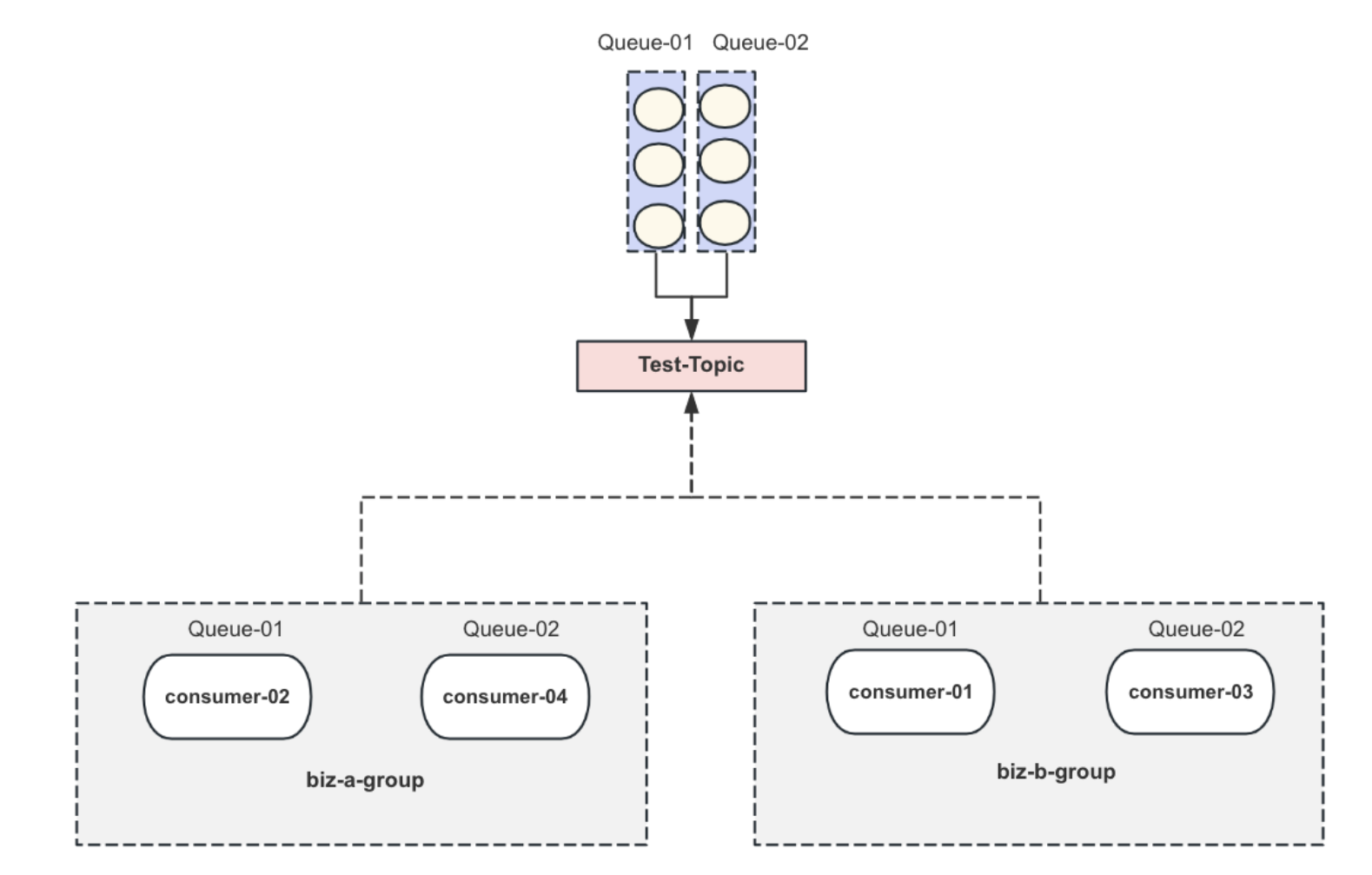
消费组
RocketMQ⾥⾯会有消费组的概念,即同⼀个topic下会有多个消费者,多个消费者可以组成不同的组别。⽽同⼀个组别的多个消费者们所持有的队列是互斥的。
消息回溯
在RocketMQ官⽅提供的控制台上,是具备这⽅⾯能⼒的。
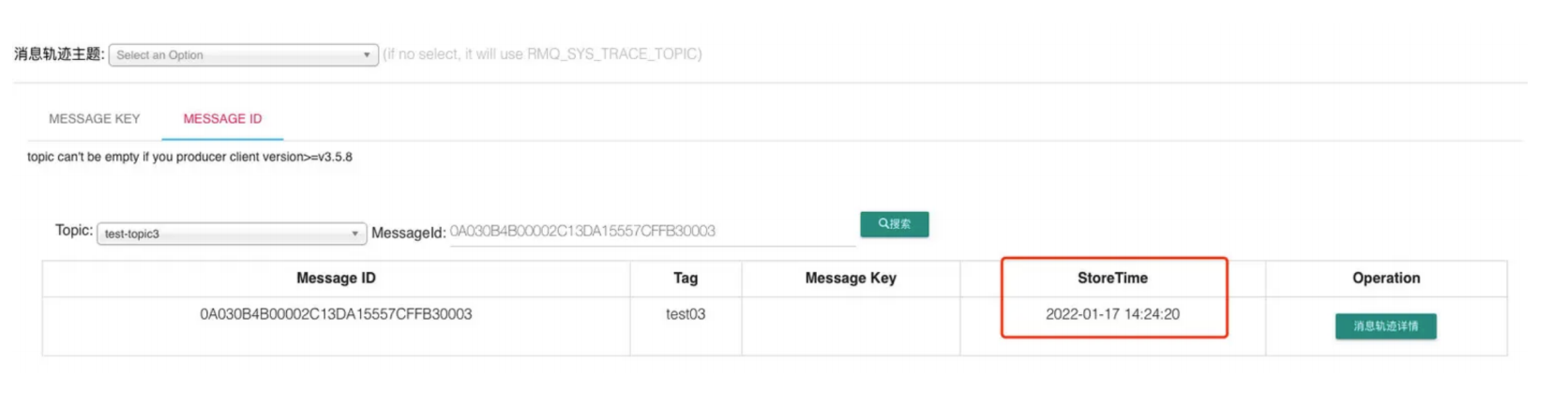
RocketMQ 的消息回溯功能允许消费者将消费进度(Offset)重置到过去的某个时间点或指定的消息位置,从而重新消费历史消息。
事务消息
RocketMQ在4.3.0版中开始⽀持分布式事务消息,RocketMQ采⽤了2PC的思想来实现了提交事务消息,同时增加⼀个补偿逻辑来处理⼆阶段超时或者失败的消息。
延迟消息
RocketMQ会在broker端,将需要延迟的消息都放在⼀个备份区域中(按照延迟的level放到不同的 queue⾥⾯去),然后有⼀个定时任务,扫描到期的数据,到期之后就将消息重新放⼊到对应队列⾥⾯。
RocketMQ的⾼性能原理
- 读写磁盘⾼性能的本质原因MMap技术
将磁盘空间映射到了内存区域,接着所有的写操作都是直接写⼊到了该块内存区域,然后根据策略同步/异步持久化到了磁盘中,这相对于传统的io磁盘性能要更⾼效。
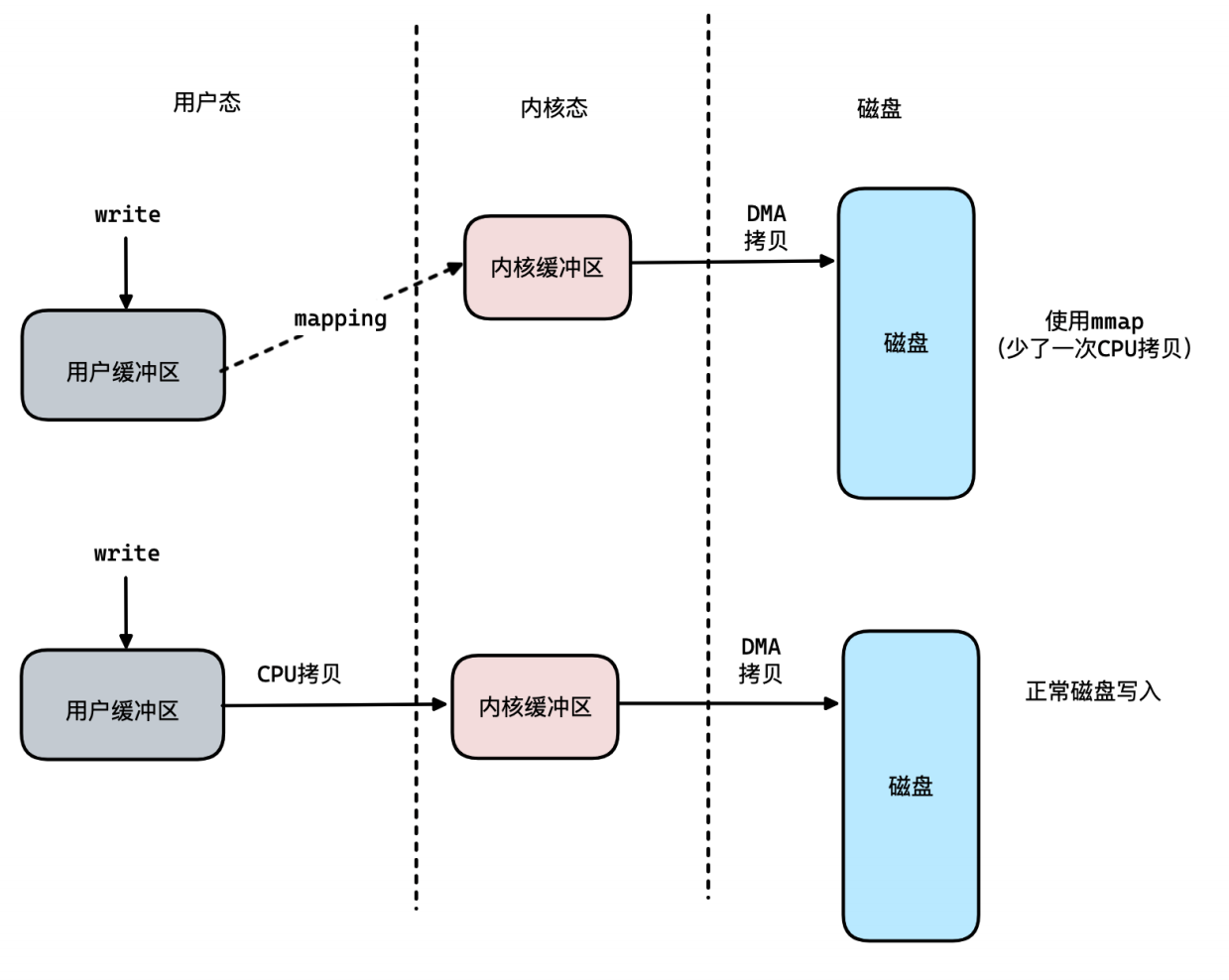
RocketMQ对mmap技术的⼀些优化
• 预映射 + 内存锁定 (系统内核的api调⽤)
在RocketMQ启动阶段,会先提前预先锁定内存映射模块,避免映射的内存被操作系统给置换了出去。
Kafka
Kafka与Zookeeper
Kafka早期版本和zookeeper其实是需要组合使⽤的,不过后边的架构设计中,在逐渐的解除和zk的耦合。早期的Kafka架构设计⾥⾯,Zookeeper主要是负责管理起具体的broker机器信息。
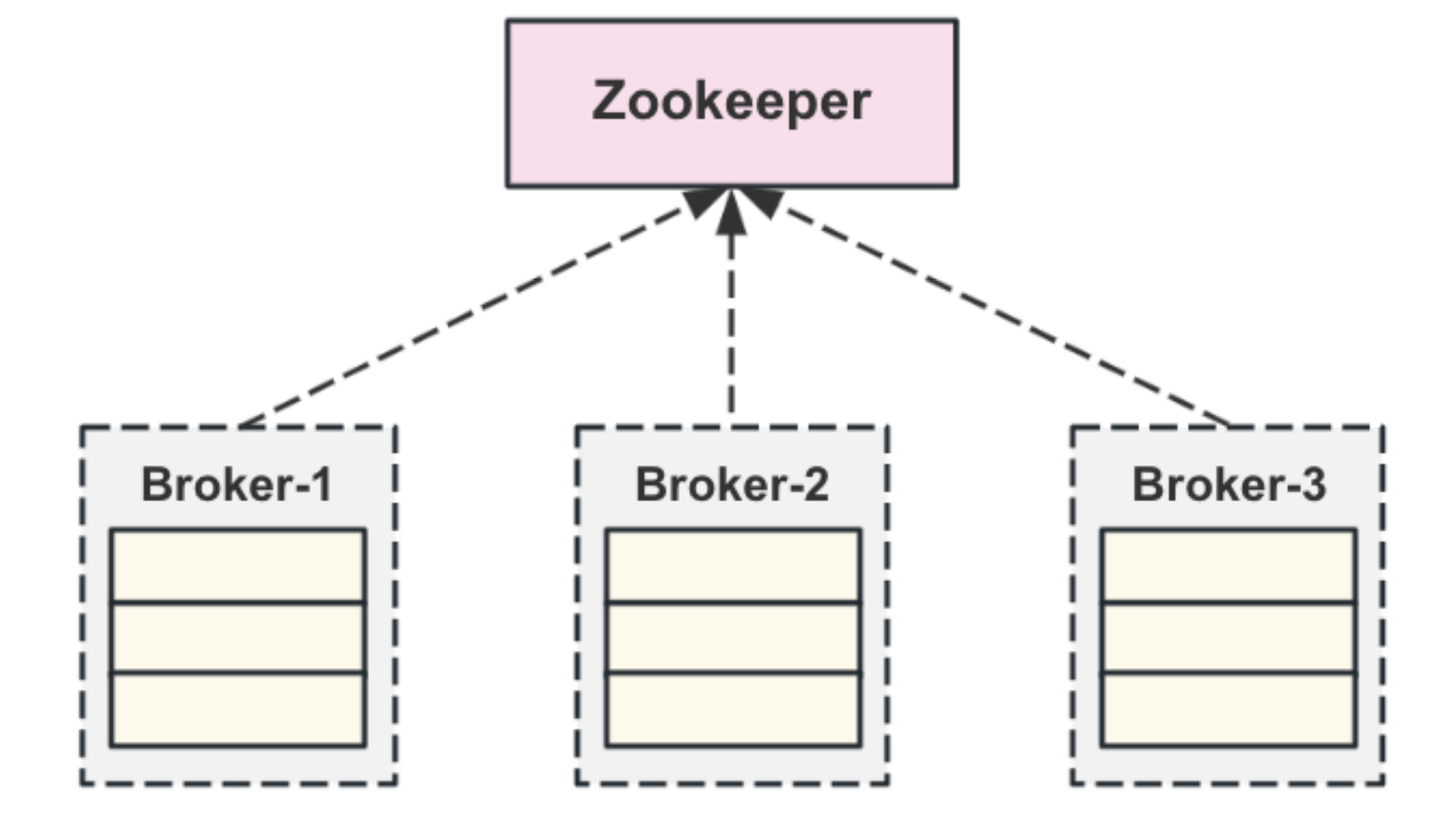
- Broker启动的时候,把地址注册到broker上,也就是/kafka/broker/ids⽬录下写⼊broker的id。
- 然后多个broker争先抢占zk的⼀个节点,在/kafka/controller⽬录下,抢占到该节点的broker是
Controller⻆⾊(分布式锁思路),主要负责后续的topic编辑,分区管理等作⽤。这台Broker上会保存集群中最全的Broker数据信息,其他的Broker节点需要定期往这台机器上报⾃⼰的信息。 - zk的临时节点消失,其他Broker重新抢锁,选出新的 Controller⻆⾊
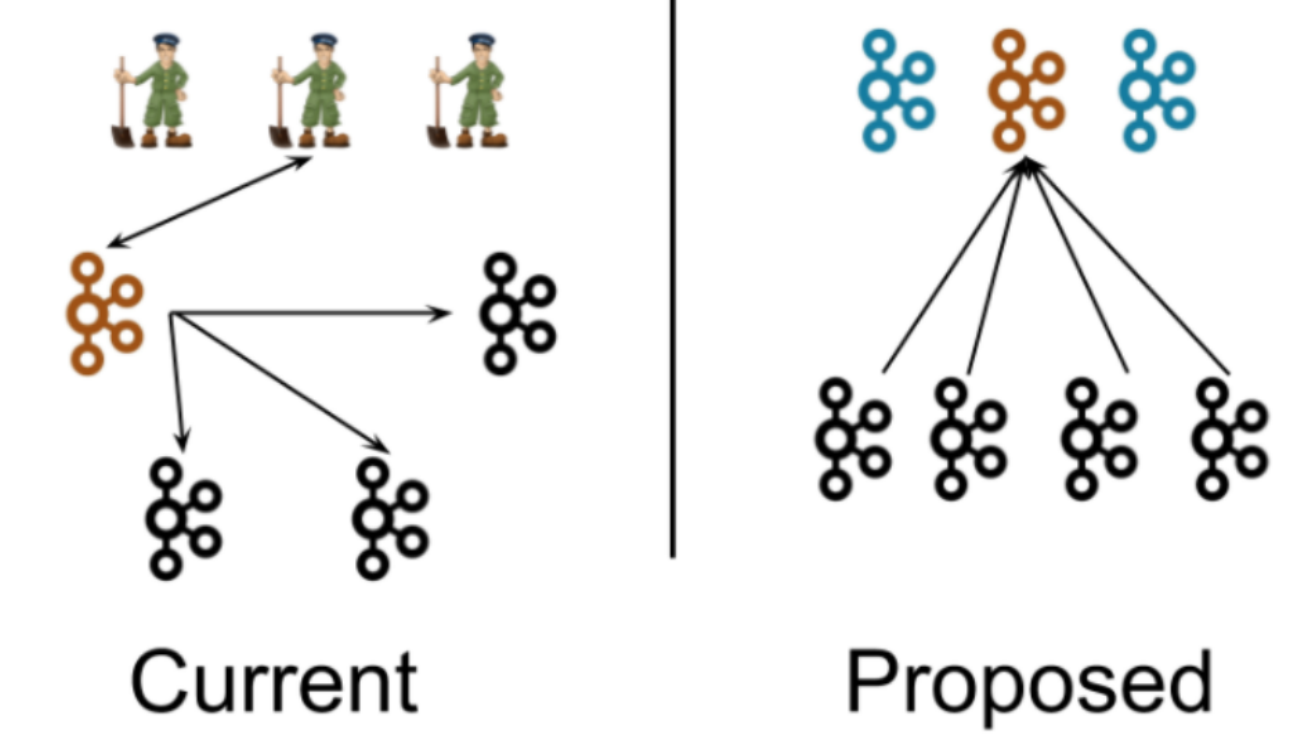
摒弃了zk依赖之后,其实后边Kafka使⽤了⾃研的 Controller Quorum 替换了之前zk的⻆⾊。
Kafka的消息发送和消费链路
Kafka的消息发送和消费架构其实和前边两款MQ的架构有点类似:
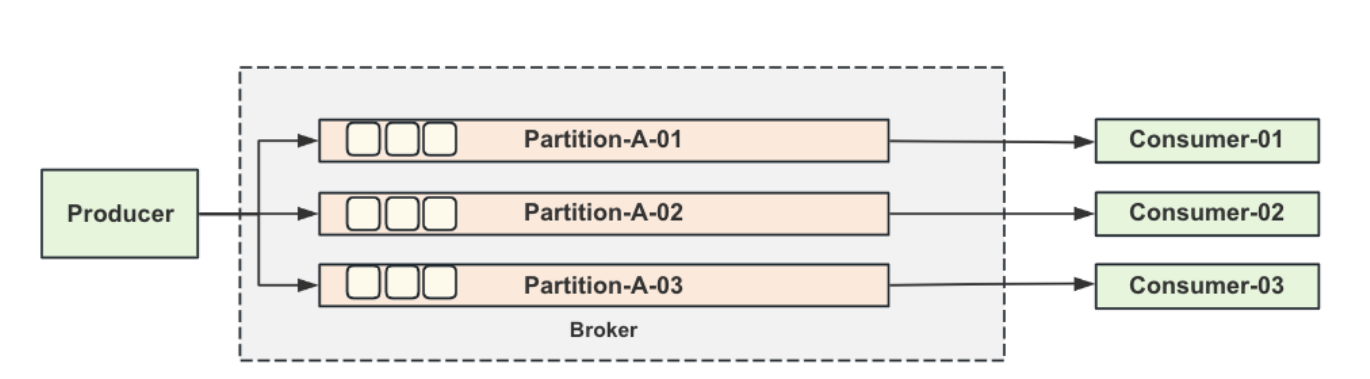
当producer发送消息抵达Broker之后,Broker会将发送过来的消息存放在不同的partition模块中,这⾥要注意,Kafka的partition你可以理解为类似于RocketMQ⾥⾯的CommitLog,存储实际消息的⼀个结构,但是它和RocketMQ的commitlog不同,Kafka不会把所有的topic信息都往⼀个commitlog⾥ ⾯去顺序写⼊,⽽是按照topic为粒度去写⼊。
这样设计的好处在于:多个主题,多个partition模块管理,可以让多核cpu的计算机充分发挥其性能。
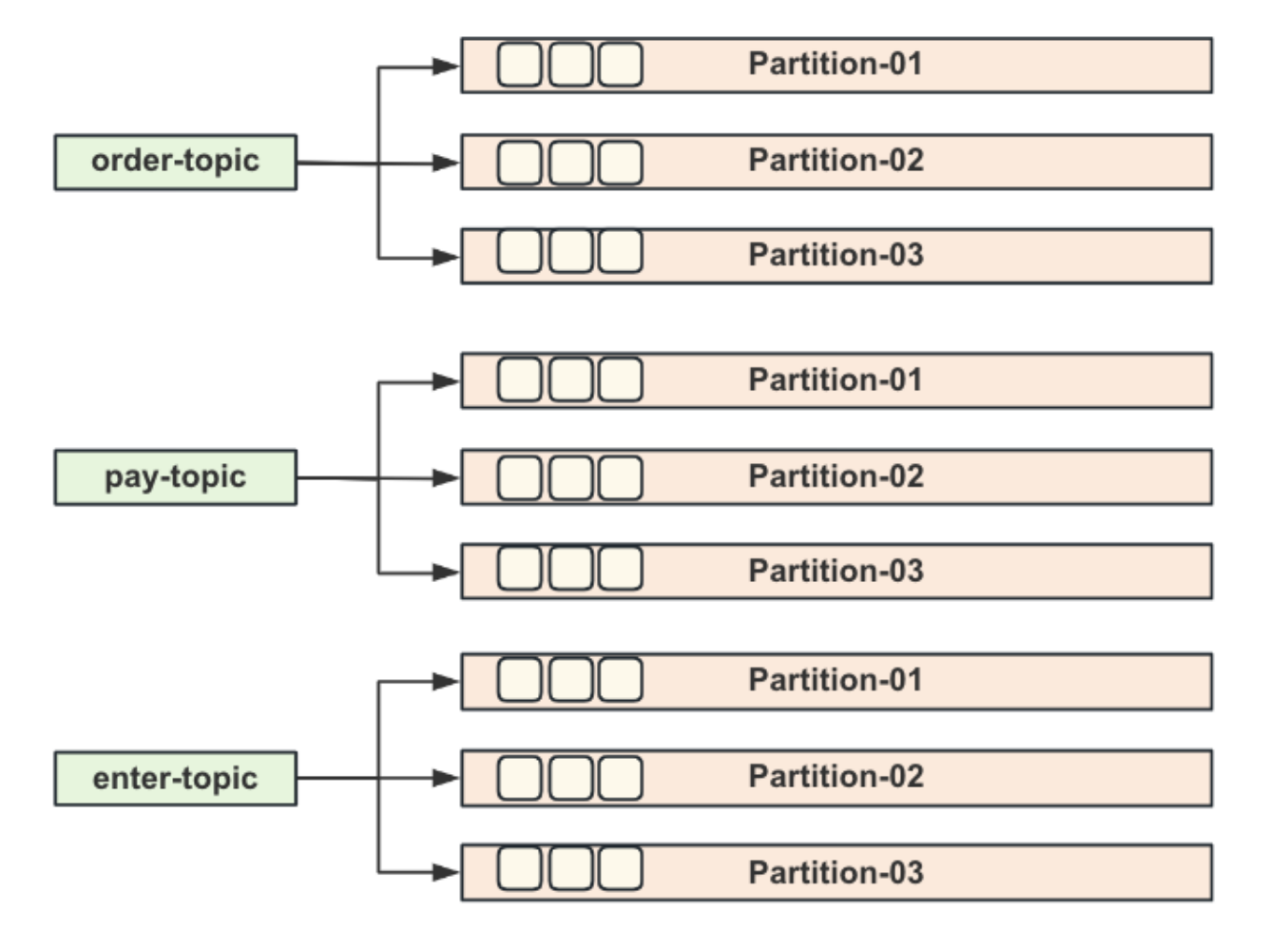
在Kafka的集群架构⾥⾯,不同的Partition⽂件会被分散到不同的Broker上存放,这样可以让不同的机器负责不同的Partition⽂件写⼊,可以保证同⼀个Topic下的消息写⼊不会只单单受限于单台机器的硬件性能。
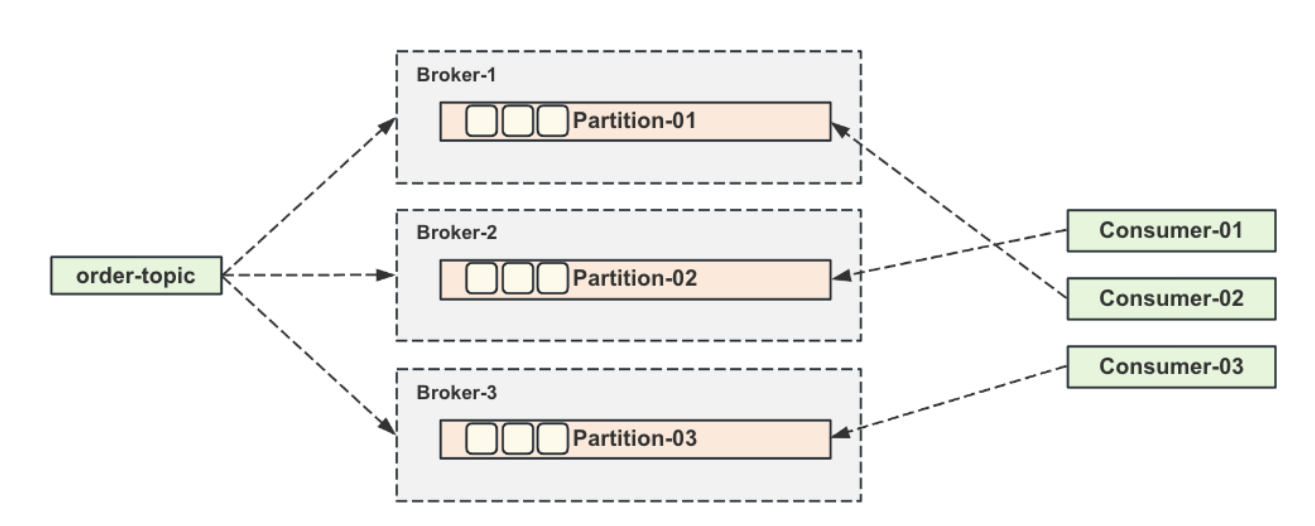
Kafka的消息存储原理
topic下的消息存储结构如下图所⽰,在⼀个segment下边会有.log,.index,.timestamp⽂件存在, Kafka⾥⾯的消息存储实际上是存在⼀个个不同的segment⾥⾯的。
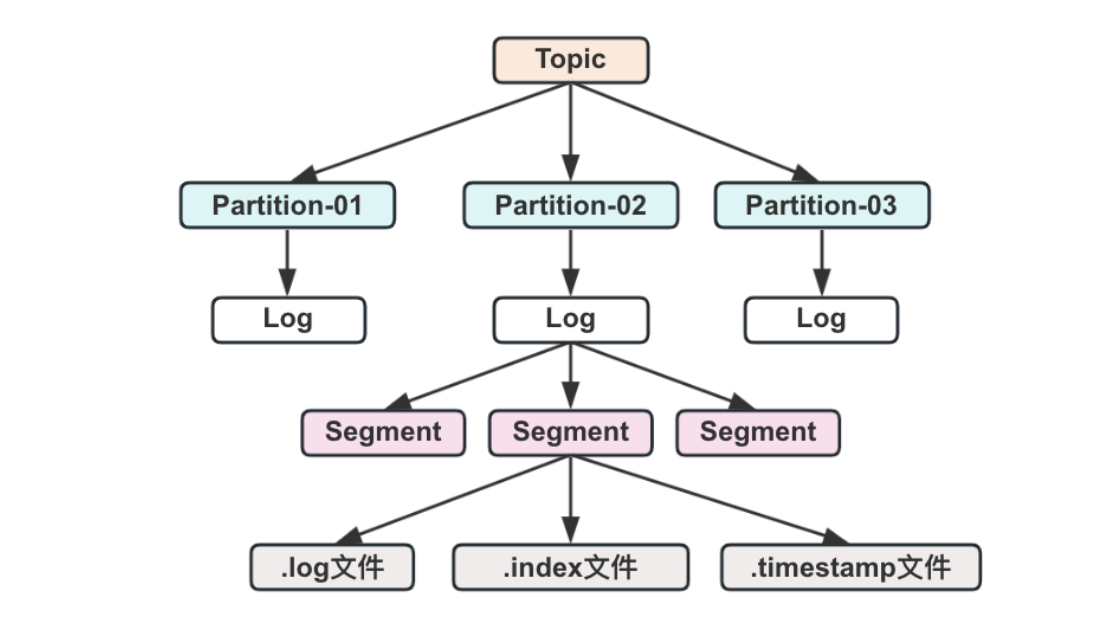
所谓的segment其实也是⼀个虚拟的概念,实际映射到物理磁盘上,分成了.log,.index,.timestamp⽂件的组合。
• .log⽂件实际的数据存储⽂件,顺序写⼊存储。
• .index⽂件索引⽂件,⾥⾯保存了具体消息存在于.log的地址信息。
• .timestamp⽂件⽤于记录哪些消息是7天以内的,如果超过了7天,⼀般消息默认会被删除。
Kafka读写数据的⾼性能原理
- 写⼊数据⽤了MMap技术
MMap虚拟内存映射,能够实现⾮常⾼效的⽂件读写能⼒。
- 消费者拉取数据使⽤了SendFile技术
⽽ Linux 2.4+ 内核通过 sendfile 系统调⽤,提供了零拷⻉。磁盘数据通过 DMA 拷⻉到内核态 Buffer 后,直接通过 DMA 拷⻉到 NIC Buffer(socket buffer),⽆需 CPU 拷⻉。这也是零拷⻉这⼀说法的来源。除了减少数据拷⻉外,因为整个读⽂件 - ⽹络发送由⼀个 sendfile 调⽤完成,整个过程只有两次上下⽂切换,因此⼤⼤提⾼了性能。
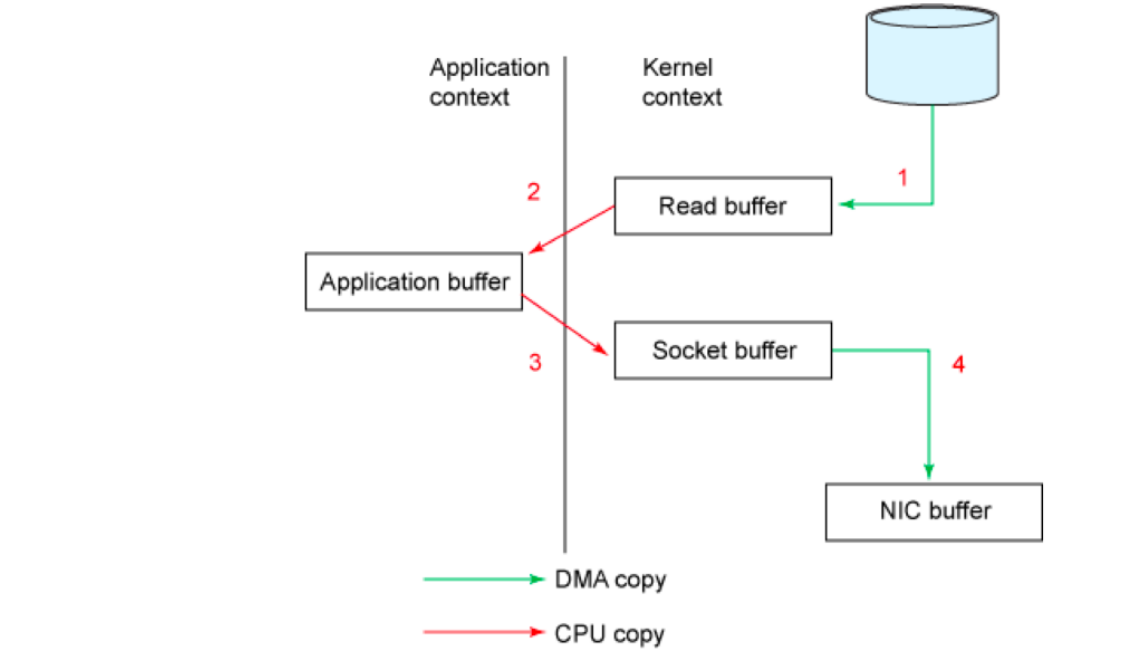
Consumer -> broker 读数据(⽹络)(⽹卡接收consumer数据->broker读取数据(mmap定位数据)-> 通过⽹络发送给到consumer)
• 传统数据在⽹卡上的发送链路
• 使⽤SendFile技术后,数据在⽹卡端的发送链路
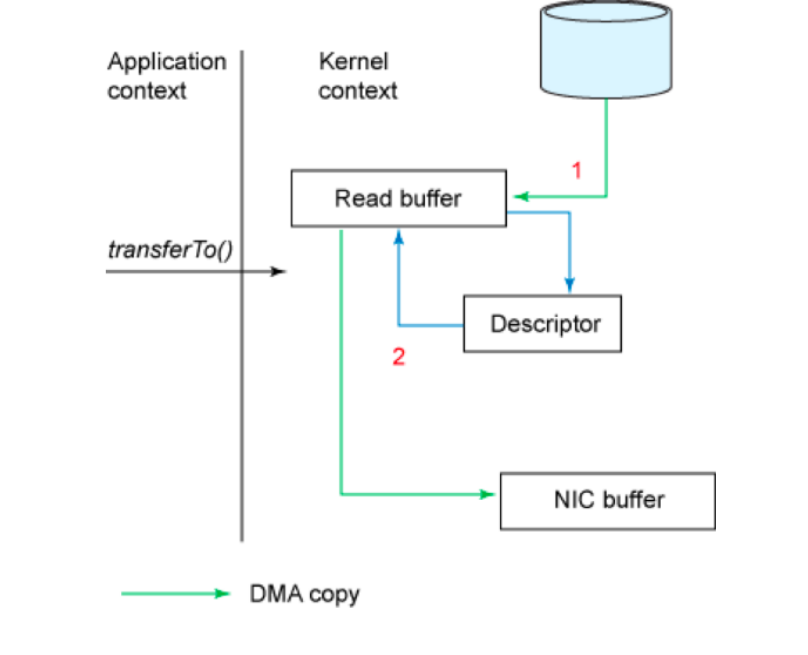
SendFile 是一种高效的文件传输技术,通过操作系统提供的系统调用(如 Linux 的 sendfile())实现数据直接从文件系统传输到网络套接字,避免数据在用户空间和内核空间之间的多次拷贝,从而显著提升传输性能。这种技术属于“零拷贝(Zero-Copy)”优化的一种实现。
三种消息队列对⽐
| RabbitMQ | RocketMQ | Kafka | |
|---|---|---|---|
| 语言 | erlang | java | Scala/Java |
| 性能 | 一般 | 强 | 非常强 |
| 消息存储 | 按照topic区别存储,消息复制到多个queue中。 | 所有topic的消息统一存储在一份commitlog里面。 | 按topic粒度分散在不同的partition中,底层以segment的.log文件为粒度进行存储。 |
| 运维难度 | 简单 | 简单 | 高 |
| 适用场景 | - 可靠性要求高的消息传递场景 - 广告推送,用户状态变更等 | - 可以覆盖RabbitMQ的场景 - 支持事务消息,结合最终一致性思想来用于解决分布式事务 - 支持延迟消息能力 - 实时计算,电商秒杀 - 高性能,高可用计算 | - 实时计算,大数据分析 - 日志采集 - 事件总线 |
| 失败重试 | 支持 | 支持 | 需要手动实现 |
| 性能 | 30mb/s | 650mb/s | 650mb/s |