从零开始构建微博爬虫:实现自动获取并保存微博内容
前言
在信息爆炸的时代,社交媒体平台已经成为信息传播的重要渠道,其中微博作为中国最大的社交媒体平台之一,包含了大量有价值的信息和数据。对于研究人员、数据分析师或者只是想备份自己微博内容的用户来说,一个高效可靠的微博爬虫工具显得尤为重要。本文将详细介绍如何从零开始构建一个功能完善的微博爬虫,支持获取用户信息、爬取微博内容并下载图片。
项目概述
我们开发的微博爬虫具有以下特点:
- 功能全面:支持爬取用户基本信息、微博内容和图片
- 性能优化:实现了请求延迟、自动重试机制,避免被封IP
- 易于使用:提供简洁的命令行接口,支持多种参数配置
- 数据存储:支持CSV和JSON两种格式保存数据
- 容错机制:完善的错误处理,增强爬虫稳定性
- 自定义配置:通过配置文件灵活调整爬虫行为
技术选型
在构建微博爬虫时,我们使用了以下核心技术:
- Python:选择Python作为开发语言,其丰富的库和简洁的语法使爬虫开发变得简单高效
- Requests:处理HTTP请求,获取网页内容
- Pandas:数据处理和导出CSV格式
- tqdm:提供进度条功能,改善用户体验
- lxml:虽然本项目主要使用API接口,但保留XML解析能力以备扩展
- 正则表达式:用于清理HTML标签,提取纯文本内容
系统设计
架构设计
微博爬虫采用模块化设计,主要包含以下组件:
- 配置模块:负责管理爬虫的各种参数设置
- 爬虫核心:实现爬取逻辑,包括用户信息获取、微博内容爬取等
- 数据处理:清洗和结构化爬取到的数据
- 存储模块:将数据导出为不同格式
- 命令行接口:提供友好的用户交互界面
数据流程
整个爬虫的数据流程如下:
- 用户通过命令行指定爬取参数
- 爬虫初始化并请求用户信息
- 根据用户ID获取微博内容列表
- 解析响应数据,提取微博文本、图片URL等信息
- 根据需要下载微博图片
- 将处理后的数据保存到本地文件
实现细节
微博API分析
微博移动版API是我们爬虫的数据来源。与其使用复杂的HTML解析,直接调用API获取JSON格式的数据更为高效。我们主要使用了以下API:
- 用户信息API:
https://m.weibo.cn/api/container/getIndex?type=uid&value={user_id} - 用户微博列表API:
https://m.weibo.cn/api/container/getIndex?type=uid&value={user_id}&containerid={container_id}&page={page}
这些API返回的JSON数据包含了我们需要的所有信息,大大简化了爬取过程。
关键代码实现
1. 初始化爬虫
def __init__(self, cookie=None):
"""
初始化微博爬虫
:param cookie: 用户cookie字符串
"""
self.headers = DEFAULT_HEADERS.copy()
if cookie:
self.headers['Cookie'] = cookie
self.session = requests.Session()
self.session.headers.update(self.headers)
使用requests.Session维持会话状态,提高爬取效率,同时支持传入cookie增强爬取能力。
2. 获取用户信息
def get_user_info(self, user_id):
"""
获取用户基本信息
:param user_id: 用户ID
:return: 用户信息字典
"""
url = API_URLS['user_info'].format(user_id)
try:
response = self.session.get(url)
if response.status_code == 200:
data = response.json()
if data['ok'] == 1:
user_info = data['data']['userInfo']
info = {
'id': user_info['id'],
'screen_name': user_info['screen_name'],
'followers_count': user_info['followers_count'],
'follow_count': user_info['follow_count'],
'statuses_count': user_info['statuses_count'],
'description': user_info['description'],
'profile_url': user_info['profile_url']
}
return info
return None
except Exception as e:
print(f"获取用户信息出错: {e}")
return None
通过API获取用户的基本信息,包括昵称、粉丝数、关注数等。
3. 获取微博内容
def get_user_weibos(self, user_id, pages=10):
"""
获取用户的微博列表
:param user_id: 用户ID
:param pages: 要爬取的页数
:return: 微博列表
"""
weibos = []
container_id = f"{CONTAINER_ID_PREFIX}{user_id}"
for page in tqdm(range(1, pages + 1), desc="爬取微博页数"):
url = API_URLS['user_weibo'].format(user_id, container_id, page)
# ... 请求和处理逻辑 ...
使用分页请求获取多页微博内容,并添加进度条提升用户体验。
4. 图片下载优化
def _get_large_image_url(self, url):
"""
将微博图片URL转换为大图URL
"""
# 常见的微博图片尺寸标识
size_patterns = [
'/orj360/', '/orj480/', '/orj960/', '/orj1080/', # 自适应尺寸
'/thumb150/', '/thumb180/', '/thumb300/', '/thumb600/', '/thumb720/', # 缩略图
'/mw690/', '/mw1024/', '/mw2048/' # 中等尺寸
]
# 替换为large大图
result_url = url
for pattern in size_patterns:
if pattern in url:
result_url = url.replace(pattern, '/large/')
break
return result_url
微博图片URL通常包含尺寸信息,我们通过替换这些标识,获取原始大图。
容错和优化
在实际爬取过程中,我们实现了多种优化机制:
- 请求延迟:在每次请求之间添加延迟,避免请求过快被限制
- 自动重试:下载失败时自动重试,提高成功率
- 异常处理:捕获并处理各种异常情况,确保爬虫稳定运行
- 图片格式识别:自动识别图片格式,正确保存文件
- 进度显示:使用tqdm提供进度条,直观显示爬取进度
使用指南
安装与配置
- 克隆项目并安装依赖:
git clone https://github.com/yourusername/weibo-spider.git
cd weibo-spider
pip install -r requirements.txt
- 基本使用方法:
python main.py -u 用户ID
- 高级选项:
# 使用cookie增强爬取能力
python main.py -u 用户ID -c "你的cookie字符串"
# 自定义爬取页数
python main.py -u 用户ID -p 20
# 下载微博图片
python main.py -u 用户ID --download_images
# 指定输出格式
python main.py -u 用户ID --format json
目标网页:
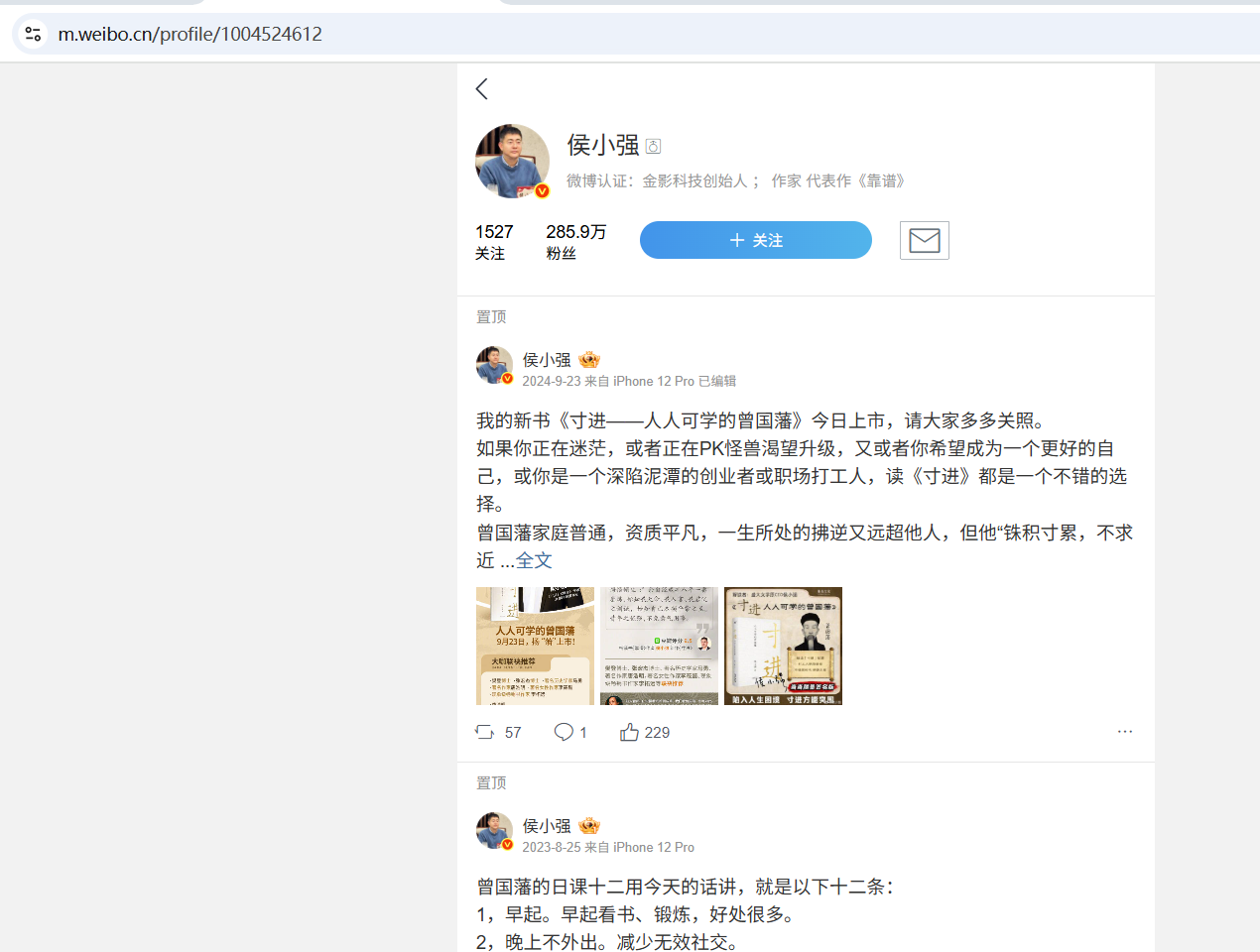
爬取结果数据:

技术挑战与解决方案
1. 反爬虫机制应对
微博有一定的反爬虫机制,主要体现在请求频率限制和内容访问权限上。我们通过以下方式解决:
- 添加合理的请求延迟,避免频繁请求
- 支持传入cookie增强权限
- 实现错误重试机制,提高稳定性
2. 图片防盗链问题
微博图片设有防盗链机制,直接访问可能返回403错误。解决方案:
- 解析并转换图片URL,获取原始链接
- 在请求头中添加正确的Referer和User-Agent
- 实现多次重试,应对临时失败
3. 数据清洗
微博内容包含大量HTML标签和特殊格式,需要进行清洗:
- 使用正则表达式去除HTML标签
- 规范化时间格式
- 结构化处理图片链接
未来改进方向
- 增加代理支持:支持代理池轮换,进一步避免IP限制
- 扩展爬取内容:支持爬取评论、转发等更多内容
- 增加GUI界面:开发图形界面,提升用户体验
- 数据分析功能:集成基础的统计分析功能
- 多线程优化:实现多线程下载,提高爬取效率
结语
本文详细介绍了一个功能完善的微博爬虫的设计与实现过程。通过这个项目,我们不仅实现了微博内容的自动获取和保存,也学习了爬虫开发中的各种技术要点和最佳实践。希望这个项目能对有类似需求的读者提供帮助和启发。
微博爬虫是一个既简单又有挑战性的项目,它涉及到网络请求、数据解析、异常处理等多个方面。通过不断的优化和改进,我们可以构建出越来越强大的爬虫工具,为数据分析和研究提供可靠的数据来源。
源码获取链接:源码
声明:本项目仅供学习和研究使用,请勿用于商业目的或违反微博用户隐私和服务条款的行为。使用本工具时请遵守相关法律法规,尊重他人隐私权。




![[密码学基础]GB与GM国密标准深度解析:定位、差异与协同发展](https://i-blog.csdnimg.cn/direct/c0887140f6664f3bb49b9915ad087560.png#pic_center)