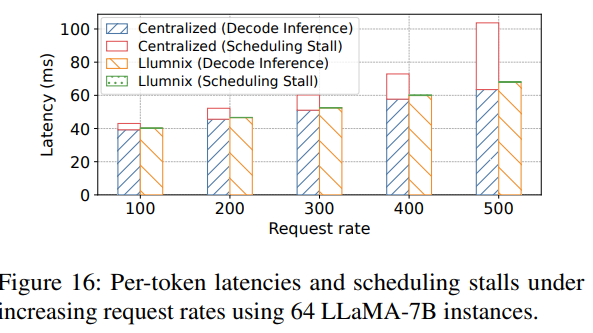
核心目标: 理解 mysql 索引的工作原理、类型、优缺点,并掌握创建、管理和优化索引的方法,以显著提升数据库查询性能。
什么是索引?
索引是一种特殊的数据库结构,它包含表中一列或多列的值以及指向这些值所在物理行的指针(或对于聚集索引,直接包含数据)。其主要目的是加快数据检索(select 查询)的速度。你可以把它想象成一本书的目录或索引,让你能够快速定位到需要查找的内容,而不是逐页翻阅。
索引如何工作(简化理解)?
mysql 最常用的索引类型是 b-tree 索引(或其变种如 b+tree)。b-tree 是一种自平衡的树状数据结构,它保持数据有序,并允许高效地进行查找、插入、删除和顺序访问。当你在索引列上执行查询时(例如 where indexed_col = value 或 order by indexed_col),数据库可以利用 b-tree 结构快速定位到匹配的行,避免了全表扫描(逐行检查)。
使用索引的优点
- 大幅提高查询速度: 这是索引最主要的好处,尤其是在
where子句、join操作的on子句中使用的列。 - 加速排序: 如果
order by子句中的列有索引,mysql 可以直接利用索引的有序性返回结果,避免额外的排序操作。 - 加速分组:
group by操作通常也需要排序,索引可以帮助加速。 - 保证数据唯一性:
unique索引和primary key约束可以确保列值的唯一性。
使用索引的缺点 (cons)
- 占用存储空间: 索引本身也需要存储在磁盘上(或内存中),会增加数据库的总体积。
- 降低写入性能: 当对表进行
insert,update,delete操作时,不仅要修改数据行,还需要同步更新相关的索引结构,这会增加写操作的开销。索引越多,写操作越慢。 - 索引维护成本: 索引需要维护,例如在数据大量变动后可能需要重建或优化(虽然 innodb 在这方面自动化程度较高)。
索引的类型
- 按功能/逻辑分类:
1. 主键索引
- 一种特殊的唯一索引,用于唯一标识表中的每一行。
- 列值必须唯一 (
unique) 且不能为空 (not null)。 - 一个表只能有一个主键。
- 通常在创建表时定义。innodb 表是围绕主键组织的(聚集索引)。
-- 建表时定义
create table users (
user_id int primary key,
username varchar(50) not null
);
-- 或表级定义 (用于单列或复合主键)
create table user_roles (
user_id int,
role_id int,
primary key (user_id, role_id)
);
2. 唯一索引
- 确保索引列(或列组合)中的所有值都是唯一的。
- 与主键不同,它允许一个
null值。 - 主要目的是保证数据完整性,同时也能加速查询。
-- 建表时定义 (列级)
create table employees (
emp_id int primary key,
email varchar(100) unique
);
-- 建表时定义 (表级)
create table products (
product_id int primary key,
sku varchar(50),
constraint uq_sku unique (sku)
);
-- 后续添加
alter table employees add constraint uq_emp_ssn unique (social_security_number);
-- 或使用 create unique index
create unique index idx_uq_phone on customers (phone_number);
3. 普通索引 / 常规索引
- 最基本的索引类型,没有唯一性限制。
- 其唯一目的就是加速数据检索。
key是index的同义词。
-- 建表时定义
create table logs (
log_id int primary key,
log_time datetime,
user_id int,
index idx_log_time (log_time), -- 创建普通索引
key idx_user_id (user_id) -- key 与 index 等效
);
-- 后续添加
alter table logs add index idx_message_prefix (log_message(50)); -- 前缀索引
-- 或使用 create index
create index idx_order_date on orders (order_date);
4. 复合索引 / 组合索引 / 多列索引
- 在表的多个列上创建的索引。
- 顺序非常重要! 遵循最左前缀原则 (leftmost prefix principle)。
-- 建表时定义
create table orders (
order_id int primary key,
customer_id int,
order_date date,
index idx_cust_date (customer_id, order_date) -- 复合索引
);
-- 后续添加
alter table products add index idx_category_price (category_id, price);
5. 全文索引
- 专门用于在文本列 (
char,varchar,text) 中进行关键字搜索。 - 使用
match(column) against('keywords')语法进行查询。 - innodb (mysql 5.6+) 和 myisam 引擎支持。
-- 建表时定义
create table articles (
article_id int primary key,
title varchar(200),
body text,
fulltext index idx_ft_title_body (title, body)
) engine=innodb; -- 确保引擎支持
-- 后续添加
alter table articles add fulltext index idx_ft_body (body);
-- 查询
select * from articles where match(title, body) against('database performance');
6. (了解) 空间索引
- 用于地理空间数据类型。优化地理位置查询。
-- create table spatial_table (
-- g geometry not null,
-- spatial index(g)
-- );
- 按物理存储方式/结构分类 (主要是 innodb vs myisam):
-
聚集索引 (clustered index)
- innodb 表强制要求有且只有一个。
- 表的物理存储顺序与索引顺序一致,通常是按主键组织。
- 优点:主键查找和范围查询快。缺点:插入慢,二级索引查找需两次。
-
非聚集索引 (non-clustered index) / 二级索引 (secondary index)
- myisam 表的所有索引都是非聚集的。innodb 表的非主键索引是二级索引。
- 索引逻辑顺序与数据物理存储顺序无关。
- 索引项包含索引值和指向数据行的指针(myisam)或主键值(innodb)。
- 优点:插入快。缺点:查找可能需要额外步骤获取数据。
-
关键索引概念
- 覆盖索引 (covering index)
当查询所需的所有列都包含在使用的索引中时,mysql 直接从索引获取数据,无需访问数据行(回表),性能极高。
-- 对于 index idx_name_age (name, age)
-- 这个查询可以使用覆盖索引
select name, age from users where name = 'alice';
-
索引选择性 (index selectivity)
索引列中不同值的比例 (cardinality / total rows)。选择性越高(越接近 1),索引效果越好。性别列选择性低,身份证号列选择性高。 -
前缀索引 (prefix indexing)
对长字符串列只索引前缀部分,节省空间,提高速度。语法:index(column_name(prefix_length))。缺点:不能用于order by/group by。
alter table user_profiles add index idx_bio_prefix (biography(100));
-
索引基数 (index cardinality)
索引中唯一值的估计数量。show index可查看。基数越高通常选择性越好。 -
(了解) 降序索引 (descending indexes)
mysql 8.0+ 支持真正的desc索引,优化order by ... desc。
-- mysql 8.0+
create index idx_created_desc on articles (created_at desc);
- (了解) 不可见索引 (invisible indexes)
mysql 8.0+ 引入。优化器不使用,但索引仍维护。用于测试移除索引的影响。
alter table my_table alter index idx_name invisible; -- 设为不可见
alter table my_table alter index idx_name visible; -- 设为可见
索引管理语法
创建索引
- 建表时 (
create table): (见上文类型定义) - 使用
create index:
create index idx_name on table_name (column1, column2(10));
create unique index uq_email on users (email);
create fulltext index ft_content on documents (content);
使用 alter table:
alter table table_name add index idx_name (column_name);
alter table table_name add unique key uq_name (column_name);
alter table table_name add primary key (column_name); -- (如果尚无主键)
alter table table_name add fulltext index ft_name (column_name);
查看索引
show index from table_name;: 最常用,显示详细信息。
show index from employees;
show create table table_name;: 显示建表语句,包含索引定义。
show create table orders;
- 查询
information_schema:
select index_name, column_name, index_type
from information_schema.statistics
where table_schema = 'your_database_name' and table_name = 'your_table_name';
删除索引
drop index index_name on table_name;: 最常用。
drop index idx_order_date on orders;
drop index uq_sku on products;
alter table table_name drop index index_name;: 功能同上。
alter table logs drop index idx_user_id;
alter table table_name drop primary key;: 删除主键。
alter table some_table drop primary key;
alter table table_name drop foreign key fk_name;: 删除外键约束。
选择哪些列加索引?
where子句频繁使用的列。join on子句的连接列。order by子句的列。group by子句的列。- 选择性高的列。
- 考虑复合索引(注意最左前缀和列顺序)。
索引失效(不被使用)的常见情况
- 对索引列使用函数或表达式 (
where year(col)=...)。 like查询以%开头 (where name like '%son')。or条件两边未都建立合适索引。- 数据类型不匹配 / 隐式类型转换 (
where string_col = 123)。 - 索引选择性过低。
- 表数据量过小。
- mysql 优化器认为全表扫描更快。
索引优化与 explain
explain命令: 分析select执行计划的关键工具。查看type,key,rows等字段判断索引使用情况。
explain select * from users where username = 'test';
- 定期维护 (相对次要,尤其对 innodb):
analyze table table_name;: 更新统计信息。optimize table table_name;: myisam 整理碎片;innodb 通常重建表。
总结与最佳实践
- 索引提速查询,但降低写入性能、占空间。
- 理解 innodb (默认) 和 myisam 区别。
- 优先索引
where,join,order by,group by的列。 - 善用复合索引(最左前缀)和覆盖索引。
- 避免索引列上用函数、隐式转换、
like '%...'。 - 用
explain分析和验证索引效果。 - 不过度索引,定期审查。
练习题
假设有 orders 表: (order_id int pk, customer_id int, product_name varchar(100), quantity int, order_date date)
- 为
orders表的customer_id列添加一个普通索引,名为idx_cust_id。
答案:
alter table orders add index idx_cust_id (customer_id);
-- 或者
-- create index idx_cust_id on orders (customer_id);
- 为
orders表添加一个复合索引,包含order_date和product_name(前 50 个字符),索引名为idx_date_product。
答案:
alter table orders add index idx_date_product (order_date, product_name(50));
- 假设需要确保每个客户在同一天的同一个产品只能下一个订单。请为
orders表添加一个合适的唯一约束(假设可以基于customer_id,order_date,product_name)。约束名为uq_cust_date_prod。
答案:
alter table orders add constraint uq_cust_date_prod unique (customer_id, order_date, product_name);
- 查看
orders表上存在的所有索引。
答案:
show index from orders;
- 删除第 2 题创建的复合索引
idx_date_product。
答案:
drop index idx_date_product on orders;
-- 或者
-- alter table orders drop index idx_date_product;
- 分析以下查询的执行计划(假设
customer_id列已有索引idx_cust_id):explain select order_id, product_name from orders where customer_id = 123 order by order_date;思考order by是否能利用索引。
答案:
explain select order_id, product_name from orders where customer_id = 123 order by order_date;