25年3月来自澳门大学和 MIT 的论文“CoT-Drive: Efficient Motion Forecasting for Autonomous Driving with LLMs and Chain-of-Thought Prompting”。
准确的运动预测对于安全的自动驾驶 (AD) 至关重要。本研究提出 CoT-Drive,这是一种利用大语言模型 (LLM) 和思维链 (CoT) 提示方法来增强运动预测的创新方法。本文引入一种师生知识蒸馏策略,将 LLM 的高级场景理解能力有效地迁移到轻量级语言模型 (LM),确保 CoT-Drive 能够在边缘设备上实时运行,同时保持全面的场景理解和泛化能力。通过利用 CoT 提示技术,无需额外训练 LLM,CoT-Drive 生成的语义标注能够显著提升对复杂交通环境的理解,从而提高预测的准确性和鲁棒性。此外,还提供两个新的场景描述数据集:Highway-Text 和 Urban-Text,用于微调轻量级语言模型 (LM),使其能够生成特定于上下文的语义标注。对五个真实数据集的全面评估表明,CoT-Drive 的性能优于现有模型,凸显其在处理复杂交通场景方面的有效性和效率。总体而言,这项研究首次探讨 LLM 在该领域的实际应用。
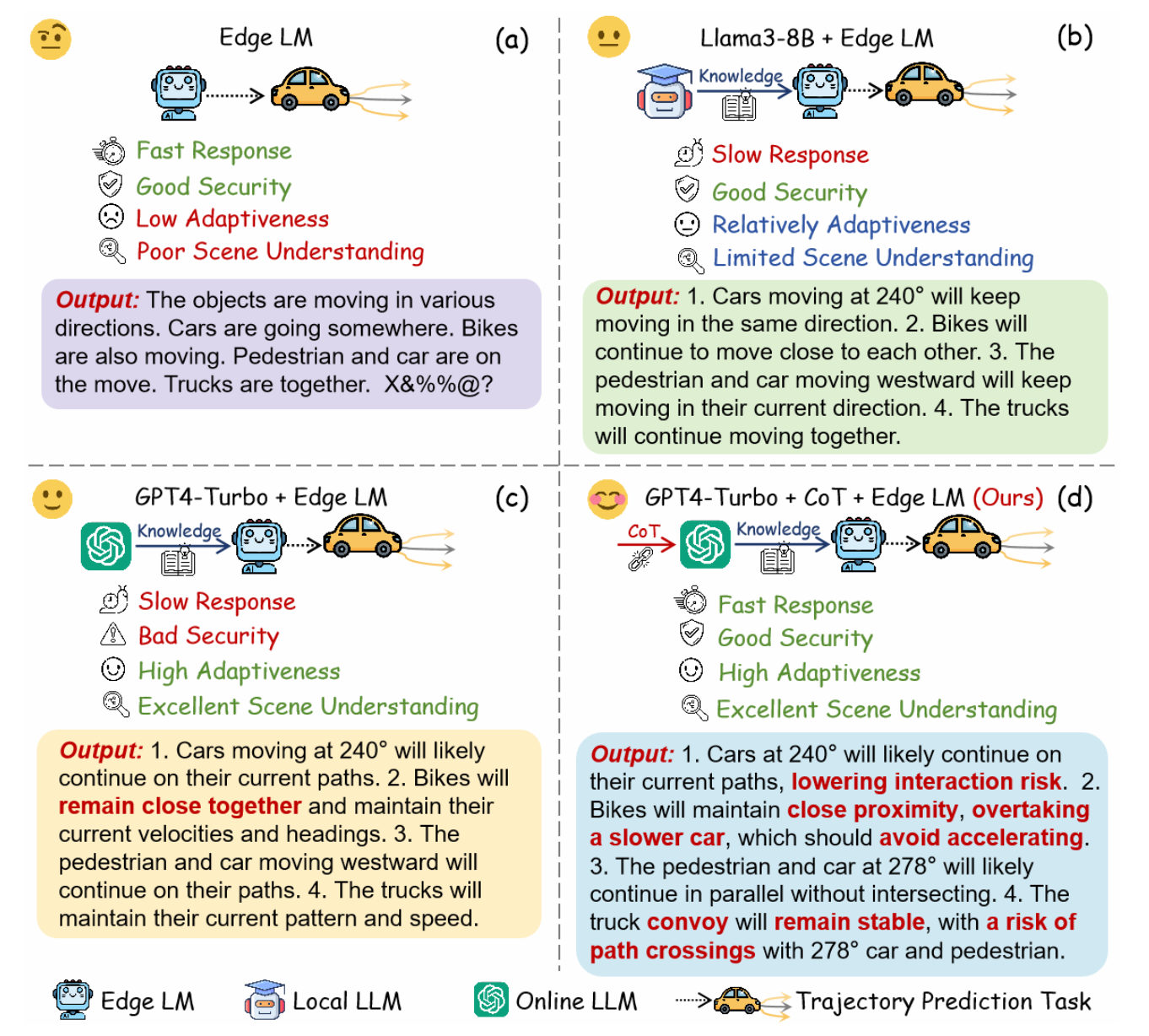
如图所示说明 COT-Drive 的优势 (d),从响应时间、安全性、适应性和场景理解能力等关键角度比较边缘语言模型 (a)、本地 LLM 与边缘 LM (b) 以及在线 LLM 与边缘 LM ©。
本研究在运动预测领域引入两个场景描述数据集:Highway-Text 和 Urban-Text。这两个数据集包含超过 1000 万个单词,描述各种交通场景。Highway-Text 数据集包含来自下一代仿真 (NGSIM) 数据集 [13] 的 4,327 个交通场景和来自高速公路无人机数据集 (HighD) [31] 的 2,279 个场景描述。同时,Urban-Text 数据集包含来自澳门网联自动驾驶 (MoCAD) 数据集 [3] 的 3,255 个样本和来自 ApolloScape [32] 的 2,176 个样本多智能场景描述,涵盖校园道路、城市道路、交叉路口和环岛等多种环境。这两个数据集都分为训练集 (70%)、验证集 (10%) 和测试集 (20%)。
为了增强 LLM 对复杂交通场景的理解并最大限度地减少幻觉,开发一种 CoT 提示技术,该技术使用顺序语言指令逐步引导 LLM 生成上下文感知的语义注释。如图所示,CoT 提示以渐进式对话的形式展开,每一步都引导 GPT-4 Turbo 关注场景的不同方面。该 CoT 提示技术的流程概述如下:
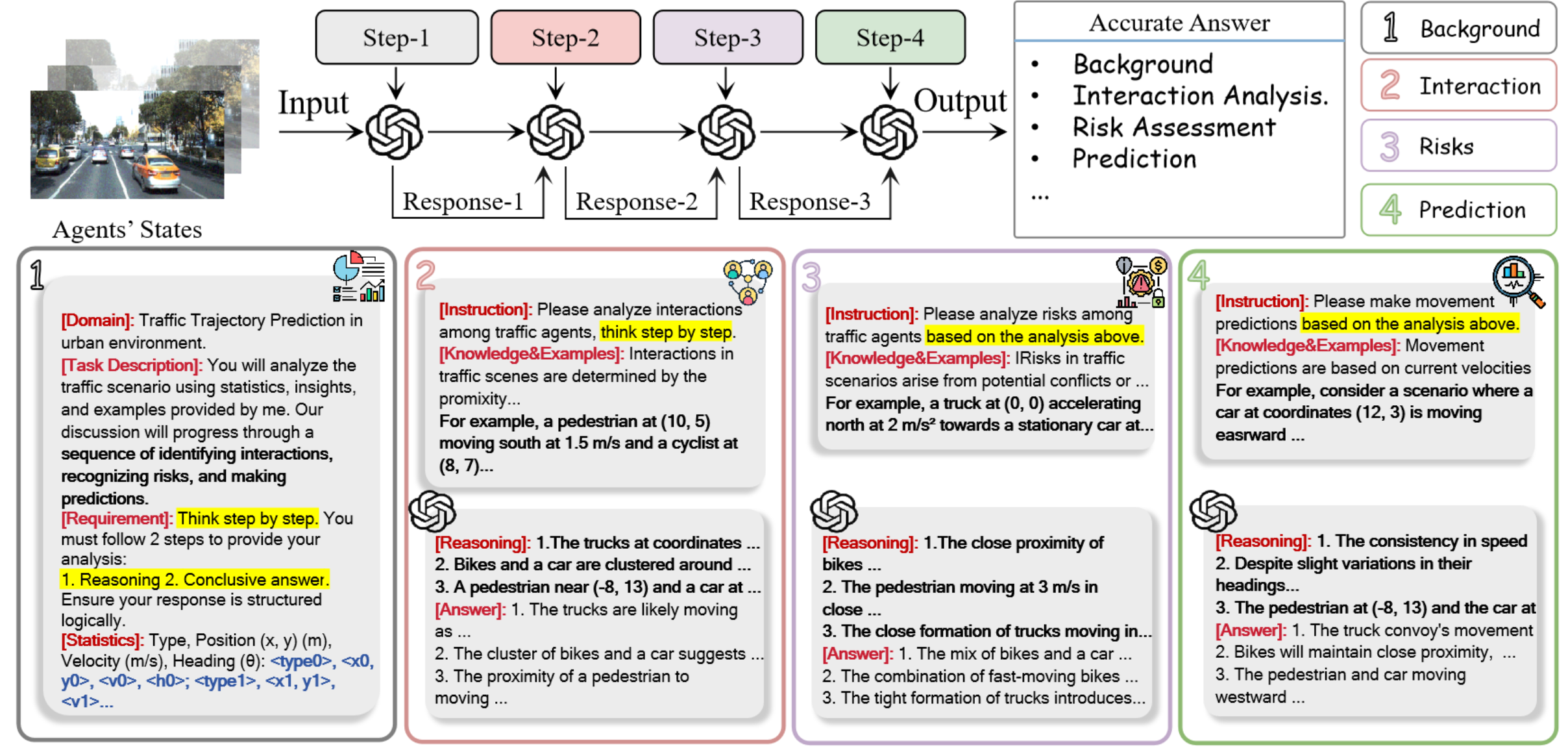
步骤 1:背景和统计数据。为高速公路和城市场景设计统一的结构化提示。每个数据对都提供丰富的交通智体信息,包括智体类型、位置、速度、航向和环境要素。该提示引导 LLM 识别关键智体并生成当前交通状况的全面概览,例如道路状况、交通密度、值得注意的事件以及每个智体的潜行为。
步骤 2:交互分析。此阶段利用步骤 1 中的上下文信息,分析交通主体之间的交互。该模型评估车辆、行人和骑行者等主体之间的相互影响,从而识别可能影响未来行为的关键交互。
步骤 3:风险评估。基于背景信息和交互信息,此阶段引导 LLM 评估潜在的事故风险。LLM 会回顾先前的发现,并结合车辆分布、速度、路况和行人行为等因素来评估碰撞可能性。该评估整合风险模型,根据主体类型、数量和接近程度计算紧急程度分数,量化即时风险,从而确定决策的优先级。
步骤 4:预测。在最后阶段,LLM 被指示预测目标车辆的未来行为,例如加速、减速或变道,并为这些预测提供依据。此外,LLM 还会为预测的行为生成未来轨迹坐标,并总结整个推理过程。
通过迭代改进,所有四个步骤的洞察都被整合成标准格式的连贯语义注释。所有 LLM 生成的注释均经过人工验证,并与交通规则和法律标准进行交叉核对,以确保符合欧盟《通用数据保护条例》(GDPR)[33]。总而言之,这些数据集首次利用 GPT-4 Turbo 的语言能力和 CoT 提示功能,对交通场景进行详细的语义描述。通过引入这些数据集,旨在改进运动预测模型,提升泛化能力,并将 Highway-Text 和 Urban-Text 确立为自动驾驶研究中复杂性和真实性的基准。
架构概述
本研究的主要目标,是预测目标智体在自动驾驶汽车感知范围内的未来轨迹。在当前时间 t,给定目标智体(下标为 0)及其周围交通智体(下标从 1 到 n)在 t − t_h 到 t 时间间隔内的历史智体状态 X_0:nt−t_h:t,任务是预测目标智体在指定预测范围 t_f 内的未来轨迹 Y_0t+1:t+t_f。历史智体状态 X_0:n^t−t_h:t 包含目标智体及其周围智体的二维位置坐标、航向、速度、车道标识符和加速度。 CoT-Drive 的整体流程如图 (a) 所示,它基于编码器-解码器范式构建,包含四个关键组件:语言指令编码器、交互-觉察编码器、跨模态编码器和解码器。简而言之,语言指令编码器生成交通场景的语义描述,包括交互分析、风险评估和运动预测,以提供全面的理解。这些描述随后被提取为多模态特征 F_m,而交互-觉察编码器同时提取局部空间特征 F_p。随后,跨模态编码器集成并更新这些特征 F_m 和 F_p 的表示,以生成跨模态特征 F_c。最后,解码器利用 F_c 预测多模态轨迹。
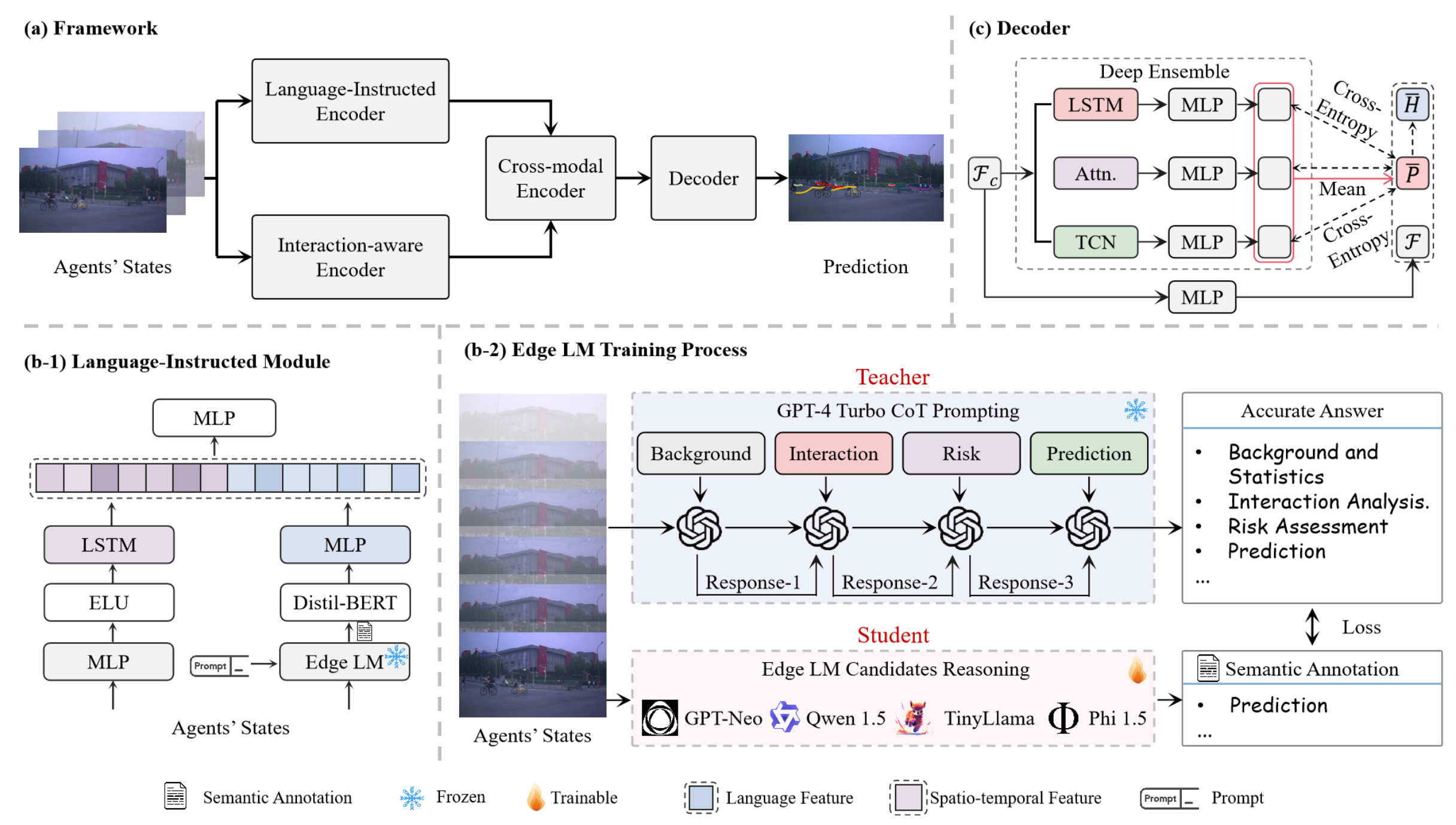
语言指令编码器
该编码器从复杂的交通场景中提取丰富的语义特征,在准确性和效率之间取得平衡,以适应实际应用。如上图(b-1)所示,引入一个“师生”知识蒸馏框架,使用预训练的语言学习模型(LLM)GPT-4 Turbo作为“老师”,基于学习者提示生成针对交通场景的语义响应 A。这些语义答案 A 随后被用作知识标签,指导“学生”模型,这是一个轻量级的边缘优化语言模型(边缘语言模型),如上图(b-2)所示是边缘 LM 的训练进程。在“老师”模型的指导下,“学生”模型经过微调,以复制老师在场景理解和生成语义注释 S 方面的能力和行为。该编码器中多模态融合技术的加入,捕捉语义注释 S 与历史智体状态 X_0^t−t_h:t之间的交互,从而生成多模态特征 F_m。
- 教师模型:为了充分利用大模型的场景理解能力,本文提出一种零样本 CoT(教师模型)提示方法,引导GPT-4 Turbo 逐步解读交通场景,最终为“学生”模型生成准确的答案 (A)。其设计一系列问题(Q)和提示(T),它们以对话的方式与 GPT-4 Turbo p_GPT 交互,旨在最大限度地提高生成准确答案 (A) 的可能性。
然后,CoT推理的集成通过嵌入推理步骤©进一步增强提示(T)。提示(T)旨在模拟人类的认知功能,例如交互-风险评估-预测,引导 GPT-4 Turbo 完成一系列问题(Q),这些问题有助于初步推理并最终得出最终答案。此外,每个问题都融合常识性知识和具体示例,使模型能够自主地逐步完善其响应。这些循序渐进的 CoT 提示增强 GPT 在交通场景中学习上下文和推断含义的能力,无需额外的微调,从而为“学生”模型提供精确且信息丰富的语义答案 A。
- 学生模型:为了减轻推理过程中的计算负担,采用轻量级边缘语言模型 (LM) 作为“学生”模型,从“教师”模型 p_GPT(该模型通过 CoT 提示增强)学习场景理解能力。“学生”模型以历史智体状态 X_0:nt−t_h:t 作为输入,生成语义标注 S。具体而言,知识蒸馏过程涉及使用信息丰富的场景答案 A 来监督学生模型的训练,以准确理解 X_0:n^t−t_h:t 所描述的交通场景。
这个学习过程从根本上讲涉及学生模型逐步逼近教师模型,这表现为 S 和 A 之间的逐步对齐。具体来说,实验各种学生模型,包括 GPT-Neo、Qwen 1.5 [34]、TinyLlama [35] 和 Phi 1.5 [36],研究参数大小对知识蒸馏有效性的影响。
- 多模态融合:多模态融合负责接受语义注释 S 和嵌入的目标智体历史状态 X_0^t−t_h:t 并将它们融合。首先,语义注释 S 通过 DistilBERT 框架 [37] 进行处理,并结合最大池化,以提取语义特征 F_s。并行地,历史智体状态 X_0 被输入到 Linear-ELU-LSTM 网络结构中以生成时间特征 F_t。最后,利用多层感知器(MLP)融合两种模态的特征,从而生成多模态特征 F_m。
交互-觉察编码器
在编码器中采用基于 Transformer 的结构来捕捉目标智体与周围智体之间的空间交互。在任何给定的时间步 t_k ∈ [t − t_h, t],历史状态 X_0:n^t_k 会被输入到该模块中,首先通过多层感知器 (MLP) 进行维度变换。然后,利用多头注意机制和归一化函数对这些表征的空间动态进行建模,并在所有时间帧上共享权重。最后,这些处理后的表征通过另一个多层感知器 (MLP) 生成空间特征 F_p。
跨模态编码器
在引入一组编码器之后,在解码器之前引入一种注意机制。该机制旨在捕捉编码特征的跨模态交互,从而能够动态调整这些不同信息源的权重。这使得模型能够根据当前情境的特定需求进行定制。
此外,对这些向量进行矩阵乘积,以加权跨模态特征。
解码器
解码器采用双重策略来处理交通场景中的偶然不确定性 (AU) 和认知不确定性 (EU)。它使用高斯混合模型 (GMM) 进行基于机动的多模态预测,并辅以深度集成技术,以提高对罕见场景的适应性。为了对 AU 进行建模,操作被分为横向(左转、右转、直行)和纵向(加速、减速、保持速度)运动。基于观察的智体状态 X_0:nt−t_h:t,估计机动概率 P(M | X_0:n^t-t_h:t),并利用 GMM 预测未来轨迹。
此外,利用深度集成方法对 EU 进行建模。采用 Q 个异构模型进行机动预测,每个模型生成不同的机动 M 概率分布,表示为 P_q(M),其中 q ∈ [1, Q]。通过聚合这些模型输出,增强数据鲁棒性并量化 EU,如上图 © 所示。计算集成的平均预测 P ̄(M),并测量平均交叉熵 H ̄(M),以提取这些异构模型的逐帧金字塔特征图。
该集成模型包含多种模型,例如多层长短期记忆 (LSTM)、时间卷积网络 (TCN) 和多头自注意模型,它们共同增强目标智体 Y_0^t:t+t_f 的多模态未来轨迹预测能力。同时,F_c 经过多层感知器 (MLP) 处理,修改时间维度大小,从过去时间 t_h 变为未来时间 t_f,最终得到 F。最后,推导出双变量高斯分布参数。其解码器包括一个LSTM和MLP。
训练与推理
- 训练:模型训练过程分为两个连续的阶段:语言模型 (LM) 微调和动作预测训练。第一阶段,使用所提出的 Highway-Text 和 Urban-Text 数据集对边缘语言模型 (LM) 进行微调。这些数据集有效地封装从教师模型 (GPT-4 Turbo) 中蒸馏的知识,从而促进通用语义场景信息的学习。此微调过程遵循自回归语言模型的标准训练范式。考虑到在实际训练过程中,场景特定提示和教师模型的参考答案 A 会合并为一个完整的序列 B。
此过程有助于词汇和语义层面的语义对齐,使边缘语言模型能够内化教师的推理模式和对特定场景信息的语境理解。在此阶段之后,边缘语言模型在场景理解方面将取得卓越的性能。
此外,利用多任务学习策略来实现第二阶段损失函数 L_stage-2,该损失函数包含轨迹预测损失函数 L_traj 和用于机动预测的机动损失函数 L_mane,其定义为 L_stage-2 = α L_traj + (1 − α) L_mane。
机动损失函数 L_mane 评估预测轨迹相对于预期机动的准确性。此外,轨迹损失函数 L_traj 遵循双变量高斯分布进行定义。总而言之,组合损失函数可确保预测轨迹的准确性并与实际驾驶操作保持一致,从而提高实际条件下的可靠性。
- 推理:对于场景标注任务,历史智体状态被转换为经过微调的边缘语言模型 (LM) 的文本输入,LM 使用提示工程 (prompt engineering) 生成场景标注。在运动预测任务中,该模型将语义标注与历史智体状态相结合,生成多模态未来轨迹。在推理过程中,只有经过知识蒸馏的轻量级语言模型负责生成场景描述,从而确保自动驾驶汽车 (AV) 的高效预测。
CoT-Drive 在四块 NVIDIA A100 40GB GPU 上进行训练。关键实现和参数设置如下:
- 语言模型训练细节:使用 bf16 精度和监督微调 (SFT) 对四个语言模型进行微调。在初步实验后,为了确保稳定性和泛化能力,选择了 2e^−5 的学习率。批量大小为 8,以平衡效率和有效的梯度更新。训练运行 10 个 epoch,权重衰减为 0.01,以防止过拟合。如图所示,验证损失曲线显示第 10 个 epoch 时模型快速收敛,表明其能够有效适应数据分布,降低训练成本,并有助于加快实际应用的开发速度。
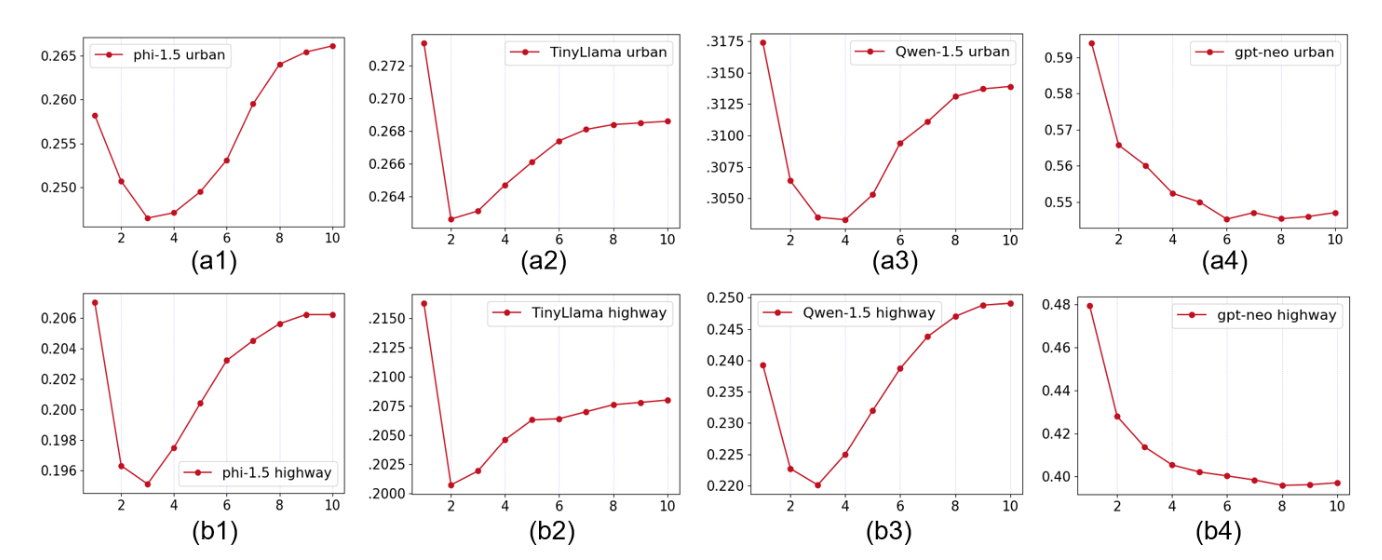
- 预测框架细节:运动预测框架训练 16 个 epoch,批量大小为 64,旨在提高 GPU 内存效率并提升泛化能力。用带有余弦退火热重启的 Adam 优化器,将学习率从 10^−3 调整到 10^−5,以实现快速收敛和微调。交互-觉察编码器的隐藏层大小为 64,具有 8 个注意头和 3 个层,旨在平衡计算效率和最佳验证结果。解码器采用多尺度 LSTM、TCN 和多头自注意(4 个头)的集成,以增强鲁棒性和准确性。



![[大模型]什么是function calling?](https://i-blog.csdnimg.cn/direct/b49475b7556145699a37128b08d173eb.png)