遇到一个真实场景里使用二分算法的问题,本以为可以放心交给小师弟去做,结果出现了各种问题,在此梳理下二分算法的核心思想和使用细节。
文章目录
- 1.场景描述
- 2.场景分析
- 3.二分算法的精髓
- 总结
1.场景描述
系统A中所有业务日志保存在持久化的日志文件中,日志文件每4小时保存为一个文件,日志大小不一。有可能某个时段下完全无日志(如凌晨时段)。
现在发现,在过去的某次变更中,有一个业务问题当成通用异常处理掉了,异常中包含了一些业务参数,依据这些参数可以进行一个简单的校验 f f f,来校验是否出现了这个问题。
现在我们需要找出最早出现这个异常的时间点,进行后续的数据分析和策略制定。
2.场景分析
由于变更时间已久,排查历史变更及代码成本过高,最好的办法是读日志,确定具体的时间区间,从而做后续措施。
日志的时间区间跨度过大,粗略估计可能的时间区间为450天。一一读日志文件,可能最多需要2700次左右的IO,按最后的准确结果来看,从区间起点开始查找,也需要1400次左右的IO。
仔细分析,该时间区间,针对是否存在该问题的情况,可以变为一个 { 0 , 1 } \{0,1\} {0,1}的数组,而且本身是有序的,区间为 { 0 , 0 , 0 ⏟ n 个 0 . . . 1 , 1 , 1 , 1 ⏟ m 个 1 } \{\underbrace{0,0,0}_{n个0}...\underbrace{1,1,1,1}_{m个1}\} {n个0 0,0,0...m个1 1,1,1,1}。对这个区间进行二分的话,只需要 log 2 ( 2700 ) = 12 \log_{2}(2700)=12 log2(2700)=12次IO即可。
3.二分算法的精髓
二分理解起来简单,就是每次找另一半,能把复杂度降到log级别,但在实际运用过程中,经常会有类似数组下标越界、死循环、答案错误等问题,根本原因在于没有完全理解实际场景在二分搜索中的过程。
3.1 核心模板
二分算法的核心模板如下:
int l = [左边界], r = [右边界];
while([在区间内]) {
int m = [取左右边界的中点];
if([m是否符合要求]) {
[移动左或右区间](相当于排除一半区间)
} else {
[移动左或右区间](相当于排除一半区间)
}
}
return [结果];
接下来就是依据具体的问题将这个模板实例化,在实例化的过程中,就需要解决以下几个问题:
- 左右边界怎么取?
- 如何判断在区间内?
- 如何取中点?
- 如何移动区间?
- 如何取到想要的结果?
如果只是对二分有过简单的理解,那么抠这些细节将会非常的难受。接下来我们可以显看一个实际的例子,放慢二分的每一步,从中去发现细节之处。
3.2 二分过程图解
先上一个经典的解决这个问题的代码:(至于为什么这么写分析完过程再讲)
public static int binarySearchClosed(int[] arr) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (check(arr, mid)) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return left;
}
为了简化过程,省去文件读取、文件指针移动的过程,只保留核心逻辑: a r r arr arr为 { 0 , 1 } \{0,1\} {0,1}数组且有序, a r r [ i ] = 1 arr[i]=1 arr[i]=1表示该天的日志出现了问题。我们的目标是找到最小的 i i i,使得 a r r [ i ] = 1 arr[i]=1 arr[i]=1。
我们以以下数组为例:

接下来模拟程序的执行流程:
1.初始时候, L = 0 , R = 8 L=0,R=8 L=0,R=8。
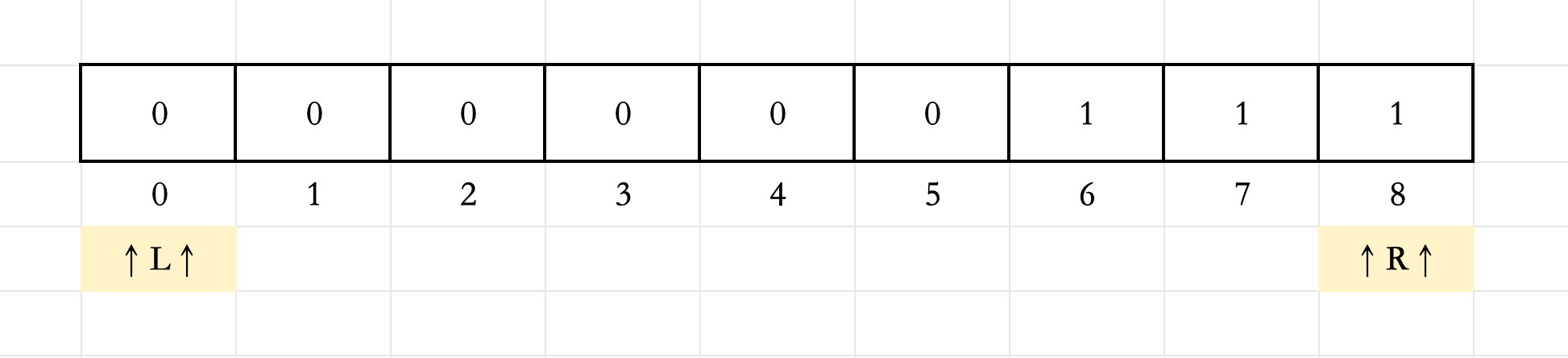
2.此时的 L L L和 R R R满足 L ≤ R L\leq R L≤R,计算 M = ( 0 + 8 ) / 2 = 4 M=(0+8)/2=4 M=(0+8)/2=4。
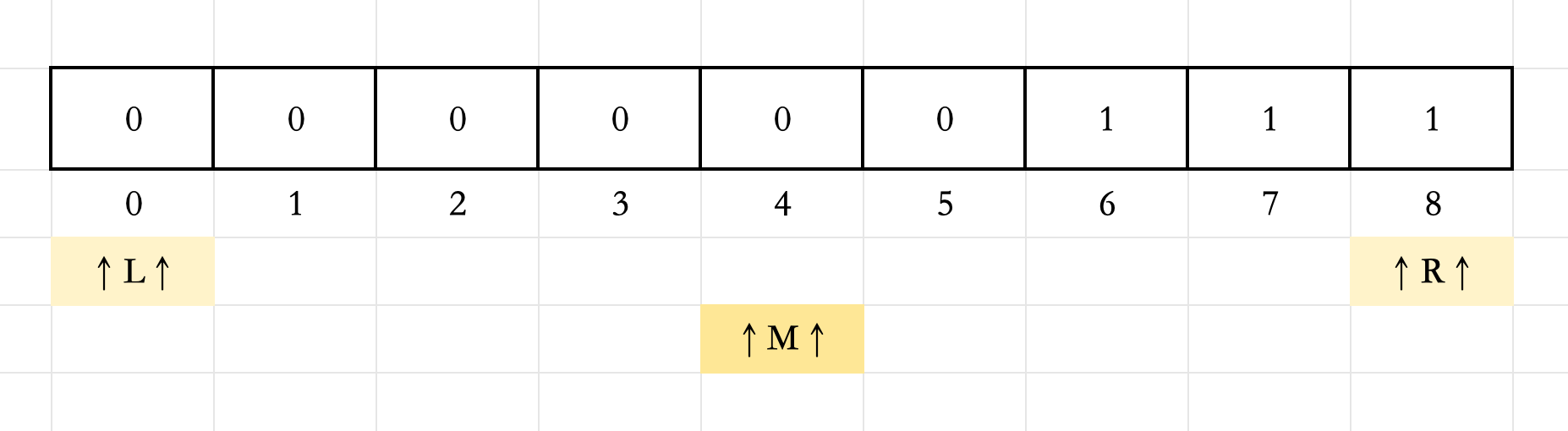
3.此时
c
h
e
c
k
(
M
)
=
0
check(M)=0
check(M)=0,说明区间
[
L
,
M
]
[L,M]
[L,M]可以直接排除,用红色标记,并更新
L
=
M
+
1
=
5
L=M+1=5
L=M+1=5。
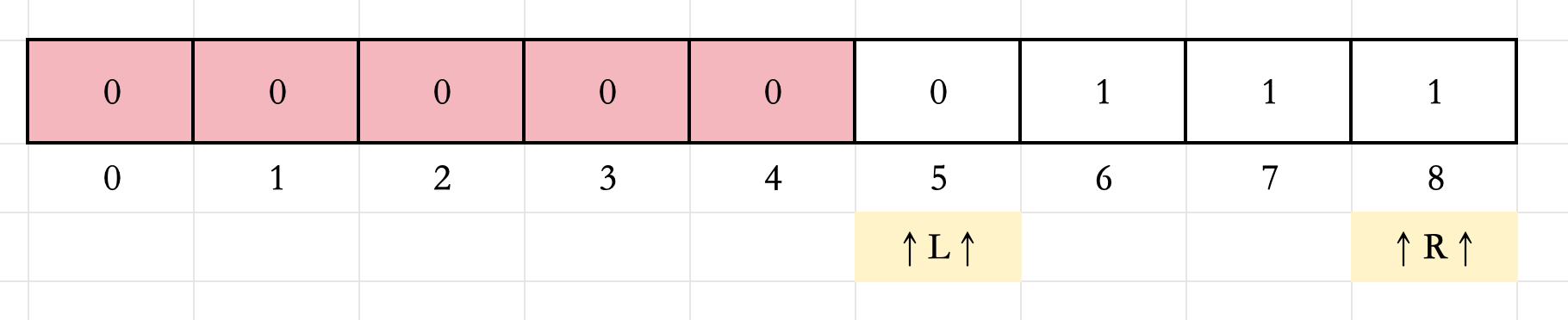
4.此时的 L L L和 R R R满足 L ≤ R L\leq R L≤R,计算 M = ( 5 + 8 ) / 2 = 6 M=(5+8)/2=6 M=(5+8)/2=6。
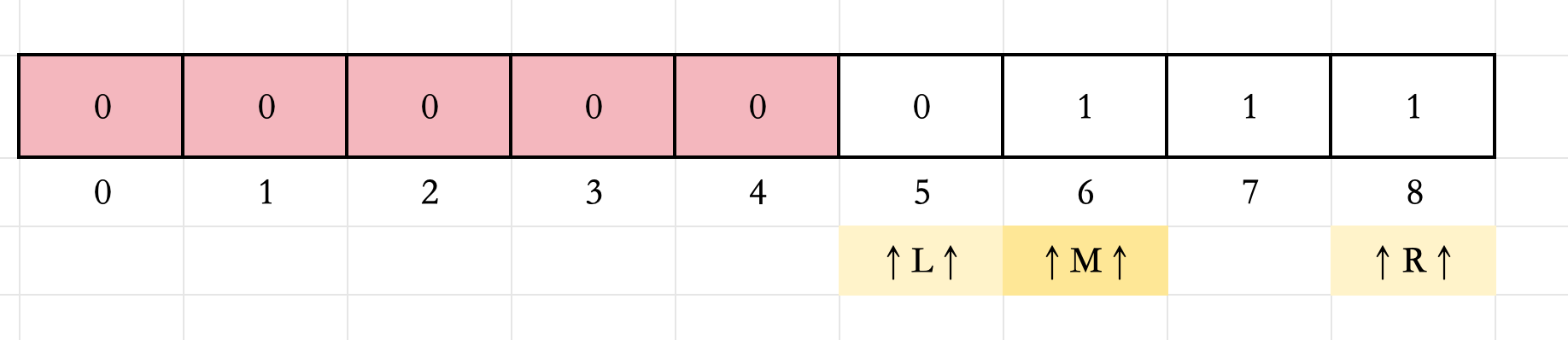
5.此时
c
h
e
c
k
(
M
)
=
1
check(M)=1
check(M)=1,说明区间
[
M
,
R
]
[M,R]
[M,R]都是符合条件的,用蓝色标记,但是我们需要找最小的符合条件的,所以需要在这个区间的左边去找,更新
R
=
M
−
1
=
5
R=M-1=5
R=M−1=5。
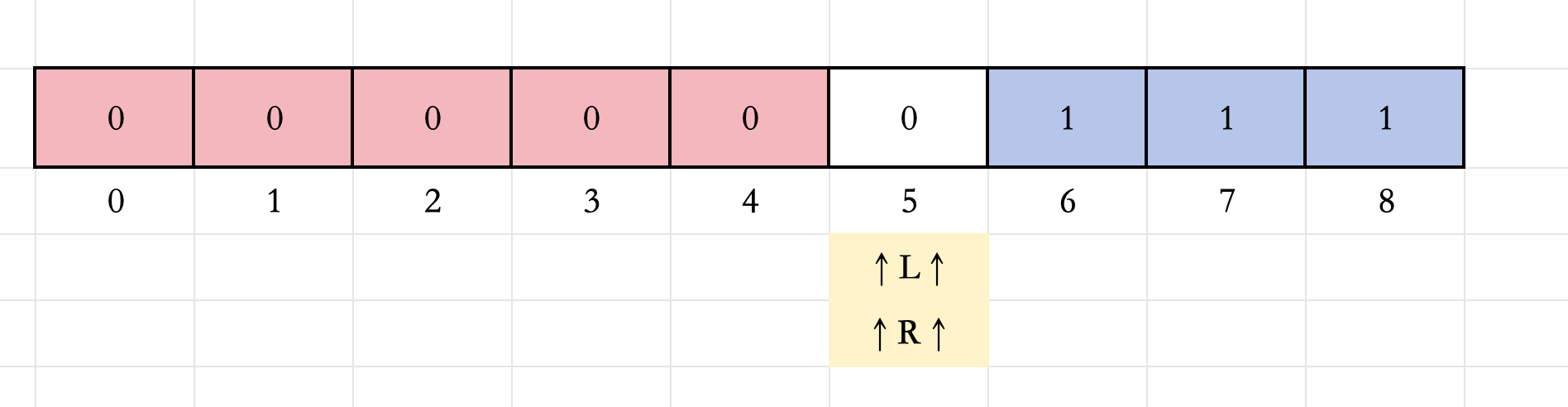
6.此时的 L L L和 R R R满足 L ≤ R L\leq R L≤R,计算 M = ( 5 + 5 ) / 2 = 5 M=(5+5)/2=5 M=(5+5)/2=5。
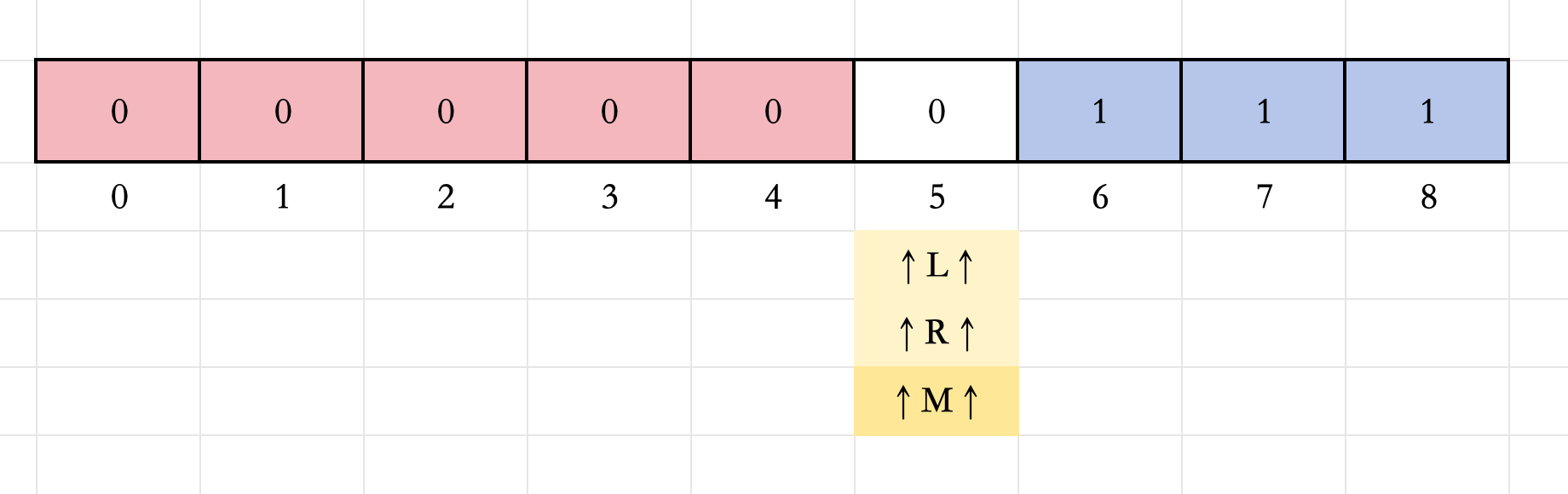
7.此时
c
h
e
c
k
(
M
)
=
0
check(M)=0
check(M)=0,说明区间
[
L
,
M
]
[L,M]
[L,M](
[
5
,
5
]
[5,5]
[5,5])可以直接排除,用红色标记,所以更新
L
=
M
+
1
=
6
L=M+1=6
L=M+1=6。
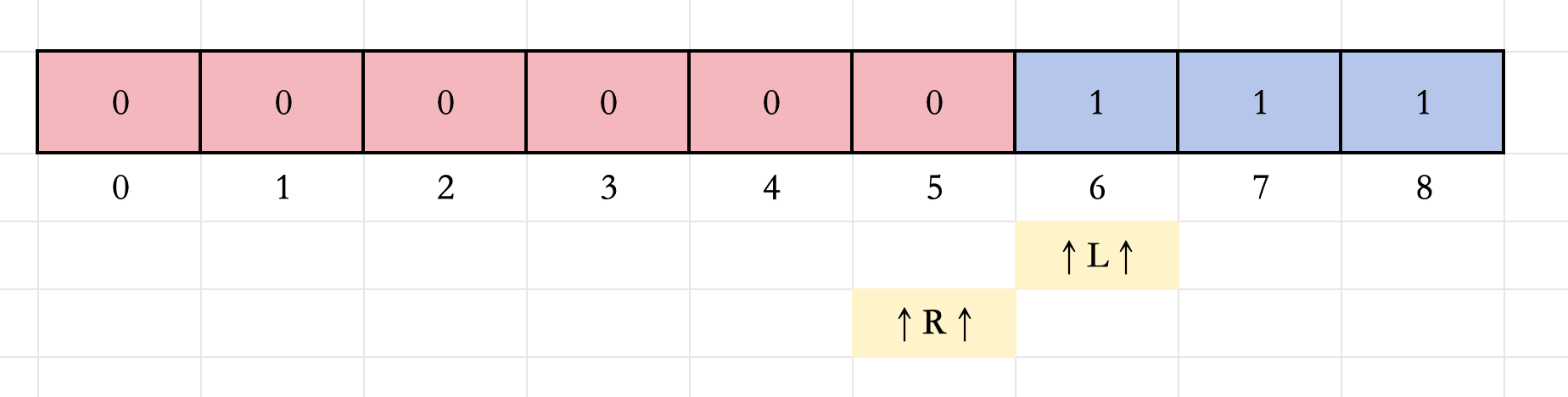
8.此时 L > R L>R L>R,不满足循环条件,退出循环,并返回 L L L。
通过上述的图解过程,我们可以得出以下细节:
- 初始选取的 L L L和 R R R是数组中的有效下标,也就是说能在二分的过程中取到的,相当于循环一直在闭区间 [ L , R ] [L,R] [L,R]中操作。
- 只要我们操作的区间不为空,就可以一直循环下去,区间不为空的条件就是 L ≤ R L\leq R L≤R。
- 每次判断 M M M是否符合条件后,我们都可以排除一半不符合条件的数。
- 循环结束时, L = R + 1 L=R+1 L=R+1, L L L指向第一个符合条件的数, R R R指向不符合条件的最后一个数。
从整个二分的过程来看,其实就是不断缩小操作区间的过程,当区间为空,原始的大区间已经分为了红蓝两部分,红色部分不符合条件,蓝色部分符合条件,而左指针指向蓝色区间的起点,右指针指向红色区间的终点。
基于此代码和思想,其实我们已经可以拓展出解决任何二分问题的思路了,只需要确定:
- 需要操作的二分区间边界为多少。
- 如何判断二分中点是否满足答案。
- 二分结束后我需要的是什么结果。
例如(基础数量关系):
1.在一个有序数组中(区间为整个数组),找大于等于x的最小下标。(check函数写成
a
r
r
[
m
]
>
=
t
a
r
g
e
t
arr[m]>=target
arr[m]>=target)
2.在一个有序数组中,找大于x的最小下标。(check函数写成
a
r
r
[
m
]
>
t
a
r
g
e
t
arr[m]>target
arr[m]>target)
3.在一个有序数组中,找小于等于x的最大下标。(等价于【找大于x的最小下标】 - 1)
4.在一个有序数组中,找小于x的最大下标。(等价于【找大于等于x的最小下标】 - 1)
核心就是变动check函数以及循环结束后左右指针的指向。
3.3 各种区间写法
经常会看到有些会把初始条件写为: L = − 1 L=-1 L=−1或 R = N R=N R=N(数组长度),其实本质上是操作的区间不一样,不一样的初始区间,会导致循环条件、区间移动方法、最终结果有所不同,但核心思想都是一样的。
一般来说,二分的写法分为三种:闭区间、半闭半开区间、开区间。
当整个区间的分布为:前一段不满足条件,后一段满足条件,有以下的细节。
3.3.1 闭区间二分查找 [ l e f t , r i g h t ] [left, right] [left,right]
- 搜索范围始终保持在闭区间 [ l e f t , r i g h t ] [left, right] [left,right] 内
- 循环条件为 l e f t < = r i g h t left <= right left<=right
- 当 c h e c k ( a r r [ m i d ] ) = = t r u e check(arr[mid])==true check(arr[mid])==true 时,搜索区间变为 [ l e f t , m i d − 1 ] [left, mid-1] [left,mid−1]
- 当 c h e c k ( a r r [ m i d ] ) = = f a l s e check(arr[mid])==false check(arr[mid])==false时,搜索区间变为 [ m i d + 1 , r i g h t ] [mid+1, right] [mid+1,right]
- 循环退出时:
l
e
f
t
>
r
i
g
h
t
left > right
left>right
- l e f t left left 指向第一个符合要求的位置
- r i g h t right right 指向最后一个不符合要求的位置
3.3.2 半闭半开区间二分查找 [ l e f t , r i g h t ) [left, right) [left,right)
- 搜索范围为 [ l e f t , r i g h t ) [left, right) [left,right),包含 l e f t left left但不包含 r i g h t right right
- 循环条件为 l e f t < r i g h t left < right left<right
- 当 c h e c k ( a r r [ m i d ] ) = = t r u e check(arr[mid])==true check(arr[mid])==true 时,搜索区间变为 [ l e f t , m i d ) [left, mid) [left,mid)
- 当 c h e c k ( a r r [ m i d ] ) = = f a l s e check(arr[mid])==false check(arr[mid])==false 时,搜索区间变为 [ m i d + 1 , r i g h t ) [mid+1, right) [mid+1,right)
- 循环退出时:
l
e
f
t
=
=
r
i
g
h
t
left == right
left==right
- l e f t / r i g h t left/right left/right 都指向第一个符合要求的位置
- 如果数组中没有符合要求的位置,则 l e f t / r i g h t left/right left/right 等于 a r r . l e n g t h arr.length arr.length
3.3.3 开区间二分查找 ( l e f t , r i g h t ) (left, right) (left,right)
- 搜索范围为 ( l e f t , r i g h t ) (left, right) (left,right),不包含 l e f t left left和 r i g h t right right
- 初始化时 l e f t = − 1 left = -1 left=−1, r i g h t = a r r . l e n g t h right = arr.length right=arr.length
- 循环条件为 l e f t + 1 < r i g h t left + 1 < right left+1<right
- 当 c h e c k ( a r r [ m i d ] ) = = t r u e check(arr[mid])==true check(arr[mid])==true 时,搜索区间变为 ( l e f t , m i d ) (left, mid) (left,mid)
- 当 c h e c k ( a r r [ m i d ] ) = = f a l s e check(arr[mid])==false check(arr[mid])==false时,搜索区间变为 ( m i d , r i g h t ) (mid, right) (mid,right)
- 循环退出时:
r
i
g
h
t
=
l
e
f
t
+
1
right = left + 1
right=left+1
- r i g h t right right 指向第一个符合要求的位置
- l e f t left left 指向最后一个不符合要求的位置
总结
二分算法是一种巧妙的思想,在面对一些逻辑上有序的问题时,可以迅速的排除掉一半的区间,从而能在log级别的时间内找出需要的答案。落实到代码上时,会有各种细节问题,但只要理解到二分的核心思想,将其视为一个不断缩小区间的过程,很快就能找到自己实现二分问题的节奏。希望本文的出发点能对你有所帮助。
ATFWUS 2025-04-22