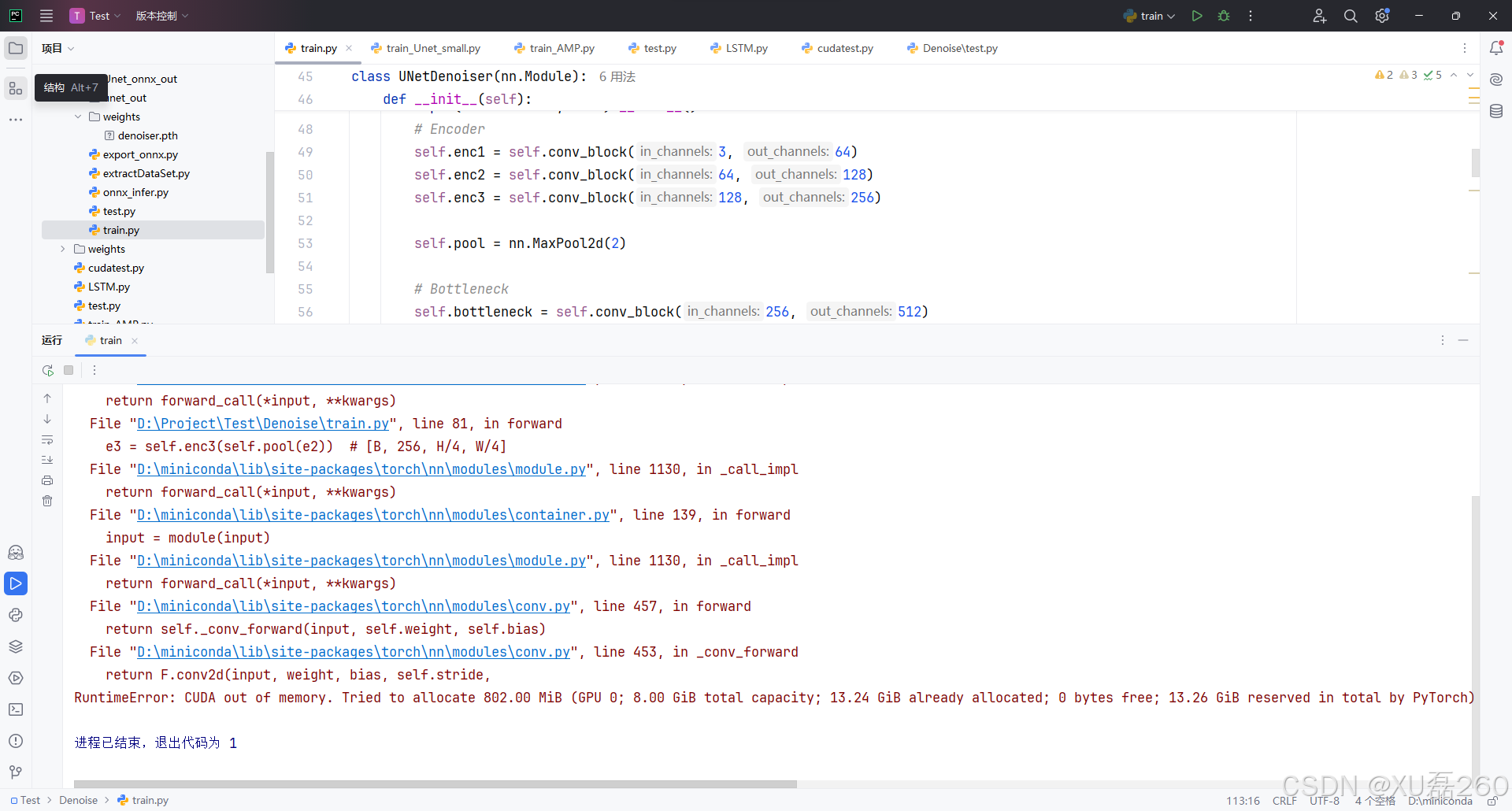
最近在训练一个基于 Tiny-UNet 的图像去噪模型时,我遇到了经典但棘手的错误:
RuntimeError: CUDA out of memory。本文记录了我如何从复现、分析,到逐步优化并成功解决该问题的全过程,希望对深度学习开发者有所借鉴。
-
训练数据:SIDD 小型图像去噪数据集
-
-
模型结构:简化版 U-Net(Tiny-UNet)
-
class UNetDenoiser(nn.Module): def __init__(self): super(UNetDenoiser, self).__init__() # Encoder self.enc1 = self.conv_block(3, 64) self.enc2 = self.conv_block(64, 128) self.enc3 = self.conv_block(128, 256) self.pool = nn.MaxPool2d(2) # Bottleneck self.bottleneck = self.conv_block(256, 512) # Decoder self.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2) self.dec3 = self.conv_block(512, 256) self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2) self.dec2 = self.conv_block(256, 128) self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2) self.dec1 = self.conv_block(128, 64) # Output self.final = nn.Conv2d(64, 3, kernel_size=1) def conv_block(self, in_channels, out_channels): return nn.Sequential( nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True) ) def forward(self, x): # Encoder e1 = self.enc1(x) # [B, 64, H, W] e2 = self.enc2(self.pool(e1)) # [B, 128, H/2, W/2] e3 = self.enc3(self.pool(e2)) # [B, 256, H/4, W/4] # Bottleneck b = self.bottleneck(self.pool(e3)) # [B, 512, H/8, W/8] # Decoder d3 = self.up3(b) # [B, 256, H/4, W/4] d3 = self.dec3(torch.cat([d3, e3], dim=1)) d2 = self.up2(d3) # [B, 128, H/2, W/2] d2 = self.dec2(torch.cat([d2, e2], dim=1)) d1 = self.up1(d2) # [B, 64, H, W] d1 = self.dec1(torch.cat([d1, e1], dim=1)) return self.final(d1)源代码:
# train_denoiser.py import os import math import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torchvision import transforms from torchvision.utils import save_image from PIL import Image # --- 数据集定义 --- class DenoisingDataset(Dataset): def __init__(self, noisy_dir, clean_dir, transform=None): self.noisy_paths = sorted([os.path.join(noisy_dir, f) for f in os.listdir(noisy_dir)]) self.clean_paths = sorted([os.path.join(clean_dir, f) for f in os.listdir(clean_dir)]) self.transform = transform if transform else transforms.ToTensor() def __len__(self): return len(self.noisy_paths) def __getitem__(self, idx): noisy_img = Image.open(self.noisy_paths[idx]).convert("RGB") clean_img = Image.open(self.clean_paths[idx]).convert("RGB") return self.transform(noisy_img), self.transform(clean_img) # --- 简单 CNN 去噪模型 --- # class SimpleDenoiser(nn.Module): # def __init__(self): # super(SimpleDenoiser, self).__init__() # self.encoder = nn.Sequential( # nn.Conv2d(3, 64, 3, padding=1), nn.ReLU(), # nn.Conv2d(64, 64, 3, padding=1), nn.ReLU() # ) # self.decoder = nn.Sequential( # nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), # nn.Conv2d(64, 3, 3, padding=1) # ) # # def forward(self, x): # x = self.encoder(x) # x = self.decoder(x) # return x class UNetDenoiser(nn.Module): def __init__(self): super(UNetDenoiser, self).__init__() # Encoder self.enc1 = self.conv_block(3, 64) self.enc2 = self.conv_block(64, 128) self.enc3 = self.conv_block(128, 256) self.pool = nn.MaxPool2d(2) # Bottleneck self.bottleneck = self.conv_block(256, 512) # Decoder self.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2) self.dec3 = self.conv_block(512, 256) self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2) self.dec2 = self.conv_block(256, 128) self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2) self.dec1 = self.conv_block(128, 64) # Output self.final = nn.Conv2d(64, 3, kernel_size=1) def conv_block(self, in_channels, out_channels): return nn.Sequential( nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True) ) def forward(self, x): # Encoder e1 = self.enc1(x) # [B, 64, H, W] e2 = self.enc2(self.pool(e1)) # [B, 128, H/2, W/2] e3 = self.enc3(self.pool(e2)) # [B, 256, H/4, W/4] # Bottleneck b = self.bottleneck(self.pool(e3)) # [B, 512, H/8, W/8] # Decoder d3 = self.up3(b) # [B, 256, H/4, W/4] d3 = self.dec3(torch.cat([d3, e3], dim=1)) d2 = self.up2(d3) # [B, 128, H/2, W/2] d2 = self.dec2(torch.cat([d2, e2], dim=1)) d1 = self.up1(d2) # [B, 64, H, W] d1 = self.dec1(torch.cat([d1, e1], dim=1)) return self.final(d1) # --- PSNR 计算函数 --- def calculate_psnr(img1, img2): mse = torch.mean((img1 - img2) ** 2) if mse == 0: return float("inf") return 20 * torch.log10(1.0 / torch.sqrt(mse)) # --- 主训练过程 --- def train_denoiser(): noisy_dir = r"F:\SIDD数据集\archive\SIDD_Small_sRGB_Only\noisy" clean_dir = r"F:\SIDD数据集\archive\SIDD_Small_sRGB_Only\clean" batch_size = 1 num_epochs = 50 lr = 0.0005 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") dataset = DenoisingDataset(noisy_dir, clean_dir, transform=transforms.ToTensor()) dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True) # model = SimpleDenoiser().to(device) # 替换为 UNet model = UNetDenoiser().to(device) criterion = nn.MSELoss() optimizer = optim.Adam(model.parameters(), lr=lr) for epoch in range(num_epochs): model.train() total_loss = 0.0 total_psnr = 0.0 for noisy, clean in dataloader: noisy, clean = noisy.to(device), clean.to(device) denoised = model(noisy) loss = criterion(denoised, clean) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() total_psnr += calculate_psnr(denoised, clean).item() avg_loss = total_loss / len(dataloader) avg_psnr = total_psnr / len(dataloader) print(f"Epoch [{epoch+1}/{num_epochs}] - Loss: {avg_loss:.4f}, PSNR: {avg_psnr:.2f} dB") # 保存模型 os.makedirs("weights", exist_ok=True) torch.save(model.state_dict(), "weights/denoiser.pth") print("模型已保存为 weights/denoiser.pth") if __name__ == "__main__": train_denoiser() -
显卡:8GB 显存的 RTX GPU
-
问题定位
我们从报错堆栈中看到:
e3 = self.enc3(self.pool(e2))
RuntimeError: CUDA out of memory. Tried to allocate 746.00 MiB
说明问题发生在模型第三层 encoder(enc3)前的 pooling 后,这说明:
-
当前的输入尺寸、batch size 占用了太多显存;
-
或者模型本身结构太重;
-
又或者显存未被合理管理(例如碎片化)。
分析与优化过程
第一步:降低 batch size
原始 batch size 设置为 16,直接触发爆显存。
我们尝试逐步调小 batch size:
batch_size = 6 # 从16降低到6
观察显存变化,发现仍有波动。为更稳定,设置为 4 或动态适配:
batch_size = min(8, torch.cuda.get_device_properties(0).total_memory // estimated_sample_size)
发现同样的错误,显存不知。分析可能是网络参数太大了,或者训练过程没有启动内存优化。导致的内存不足,这些可以通过策略进行改进,达到训练的目的。
第二步:开启 cuDNN 自动优化
torch.backends.cudnn.benchmark = True
cuDNN 会根据不同卷积输入尺寸自动寻找最优算法,可能减少显存使用。
第三步:开启混合精度训练 AMP(Automatic Mixed Precision)
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
output = model(input)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
-
autocast()自动在部分层使用 float16,提高速度并减小显存压力; -
GradScaler确保在 float16 条件下梯度依然稳定。
实测显存使用降低近 30%,OOM 问题明显缓解!
但以上训练的预加载时间太慢,显卡占有率过低,有点显卡当前没有任务----“偷懒”的意思。可能是数据的加载或者显存抖动造成的。
第四步:优化 DataLoader 性能(间接缓解显存抖动)
dataloader = DataLoader(
dataset, batch_size=batch_size, shuffle=True,
num_workers=num_workers, pin_memory=True
)-
num_workers启用多进程加载数据; -
pin_memory=True启用固定内存,更快传输到 GPU。
虽然不直接节省显存,但显著减少显存峰值抖动(尤其在小 batch 训练时)。
第五步:检查图像输入尺寸是否太大
原始图像尺寸为 512×512:
transform = transforms.Compose([
transforms.Resize((256, 256)), # 降低分辨率
transforms.ToTensor()
])
最终训练代码结构
我们将上述策略集成到了 train.py 脚本中(如下),包括:
-
Dataset & Dataloader 加速
-
混合精度训练
-
cuDNN 优化
-
实时 PSNR 显示
-
自动保存模型权重
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
from torch.cuda.amp import autocast, GradScaler
from tqdm import tqdm
# --- 启用 cuDNN 自动优化 ---
torch.backends.cudnn.benchmark = True
# --- 数据集定义 ---
class DenoisingDataset(Dataset):
def __init__(self, noisy_dir, clean_dir, transform=None):
self.noisy_paths = sorted([os.path.join(noisy_dir, f) for f in os.listdir(noisy_dir)])
self.clean_paths = sorted([os.path.join(clean_dir, f) for f in os.listdir(clean_dir)])
self.transform = transform if transform else transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()
])
def __len__(self):
return len(self.noisy_paths)
def __getitem__(self, idx):
noisy_img = Image.open(self.noisy_paths[idx]).convert("RGB")
clean_img = Image.open(self.clean_paths[idx]).convert("RGB")
return self.transform(noisy_img), self.transform(clean_img)
# --- Tiny UNet 模型 ---
class TinyUNet(nn.Module):
def __init__(self):
super(TinyUNet, self).__init__()
self.enc1 = self.conv_block(3, 16)
self.enc2 = self.conv_block(16, 32)
self.enc3 = self.conv_block(32, 64)
self.pool = nn.MaxPool2d(2)
self.bottleneck = self.conv_block(64, 128)
self.up3 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec3 = self.conv_block(128, 64)
self.up2 = nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2)
self.dec2 = self.conv_block(64, 32)
self.up1 = nn.ConvTranspose2d(32, 16, kernel_size=2, stride=2)
self.dec1 = self.conv_block(32, 16)
self.final = nn.Conv2d(16, 3, kernel_size=1)
def conv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True)
)
def forward(self, x):
e1 = self.enc1(x)
e2 = self.enc2(self.pool(e1))
e3 = self.enc3(self.pool(e2))
b = self.bottleneck(self.pool(e3))
d3 = self.up3(b)
d3 = self.dec3(torch.cat([d3, e3], dim=1))
d2 = self.up2(d3)
d2 = self.dec2(torch.cat([d2, e2], dim=1))
d1 = self.up1(d2)
d1 = self.dec1(torch.cat([d1, e1], dim=1))
return self.final(d1)
# --- PSNR 计算 ---
def calculate_psnr(img1, img2):
mse = torch.mean((img1 - img2) ** 2)
if mse == 0:
return float("inf")
return 20 * torch.log10(1.0 / torch.sqrt(mse))
# --- 训练函数 ---
def train_denoiser():
noisy_dir = r"F:\SIDD数据集\archive\SIDD_Small_sRGB_Only\noisy"
clean_dir = r"F:\SIDD数据集\archive\SIDD_Small_sRGB_Only\clean"
batch_size = 6
num_epochs = 50
lr = 0.0005
num_workers = 4
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()
])
dataset = DenoisingDataset(noisy_dir, clean_dir, transform=transform)
dataloader = DataLoader(
dataset, batch_size=batch_size, shuffle=True,
num_workers=num_workers, pin_memory=True
)
model = TinyUNet().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
scaler = GradScaler() # AMP 梯度缩放器
os.makedirs("weights", exist_ok=True)
for epoch in range(num_epochs):
model.train()
total_loss = 0.0
total_psnr = 0.0
for noisy, clean in tqdm(dataloader, desc=f"Epoch {epoch+1}/{num_epochs}"):
noisy = noisy.to(device, non_blocking=True)
clean = clean.to(device, non_blocking=True)
optimizer.zero_grad()
with autocast(): # 混合精度推理
denoised = model(noisy)
loss = criterion(denoised, clean)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
total_loss += loss.item()
total_psnr += calculate_psnr(denoised.detach(), clean).item()
avg_loss = total_loss / len(dataloader)
avg_psnr = total_psnr / len(dataloader)
print(f"✅ Epoch [{epoch+1}/{num_epochs}] - Loss: {avg_loss:.4f}, PSNR: {avg_psnr:.2f} dB")
torch.save(model.state_dict(), f"weights/tiny_unet_epoch{epoch+1}.pth")
print("🎉 模型训练完成,所有权重已保存至 weights/ 目录")
if __name__ == "__main__":
train_denoiser()
最后得到的训练文件,这里我设置的50次训练迭代:
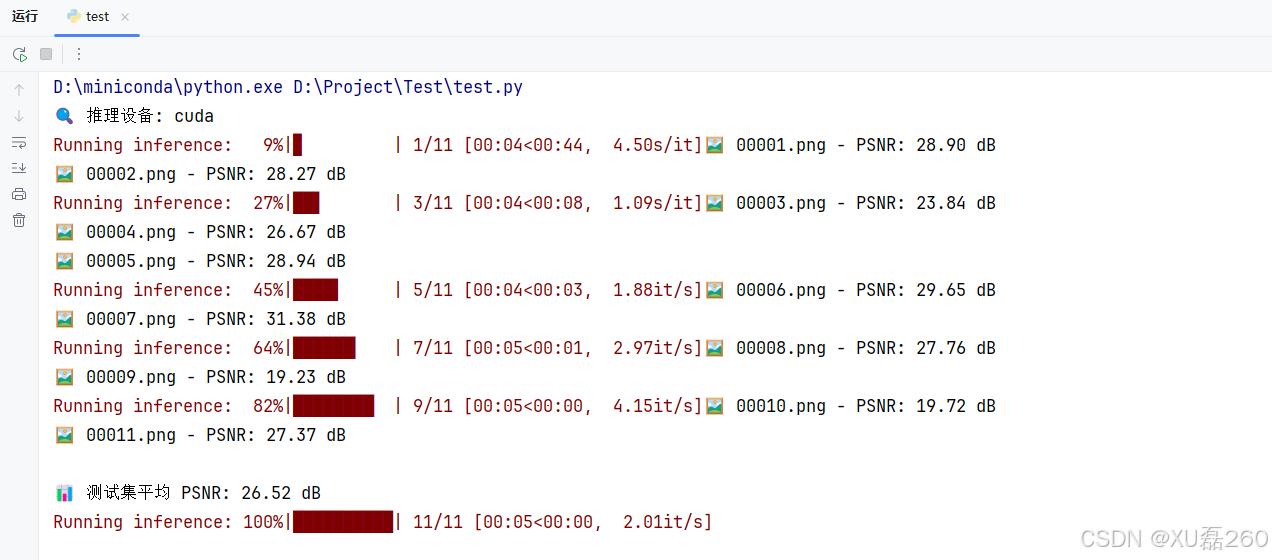
测试模型的推理效果
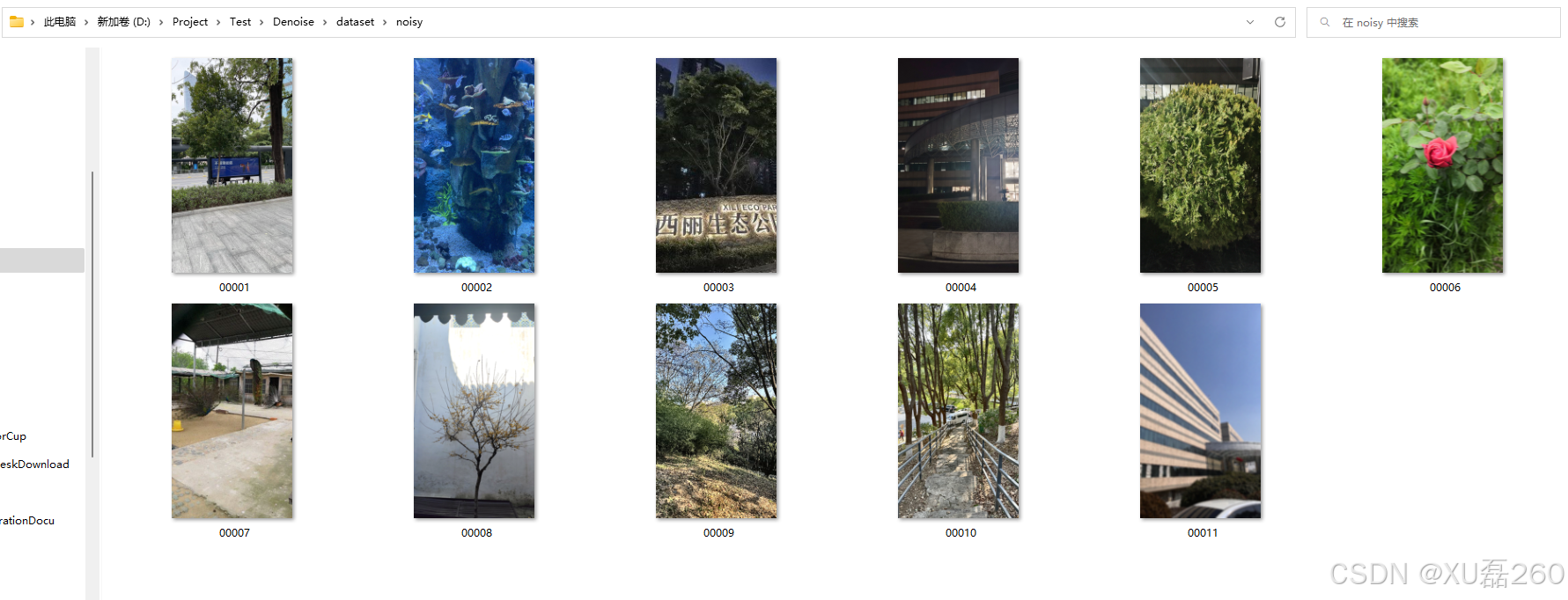
原去带噪声图片:
去噪后(可以看到这里仍然有bug,肉眼看效果并不是很好,需要进一步优化,考虑到模型的泛化性):

总结:处理 CUDA OOM 的思路模板
-
先查 batch size,这是最常见爆显存原因;
-
确认输入尺寸是否太大或未 resize;
-
启用 AMP,简单又高效;
-
合理设计模型结构(Tiny UNet > ResUNet);
-
使用 Dataloader 加速,避免数据传输抖动;
-
手动清理缓存防止 PyTorch 持有多余内存;
-
查看 PyTorch 显存使用报告,加上:
print(torch.cuda.memory_summary())











![[Android]豆包爱学v4.5.0小学到研究生 题目Ai解析](https://i-blog.csdnimg.cn/direct/9f7582b7d3e84cce8540eab6a44d0773.png)