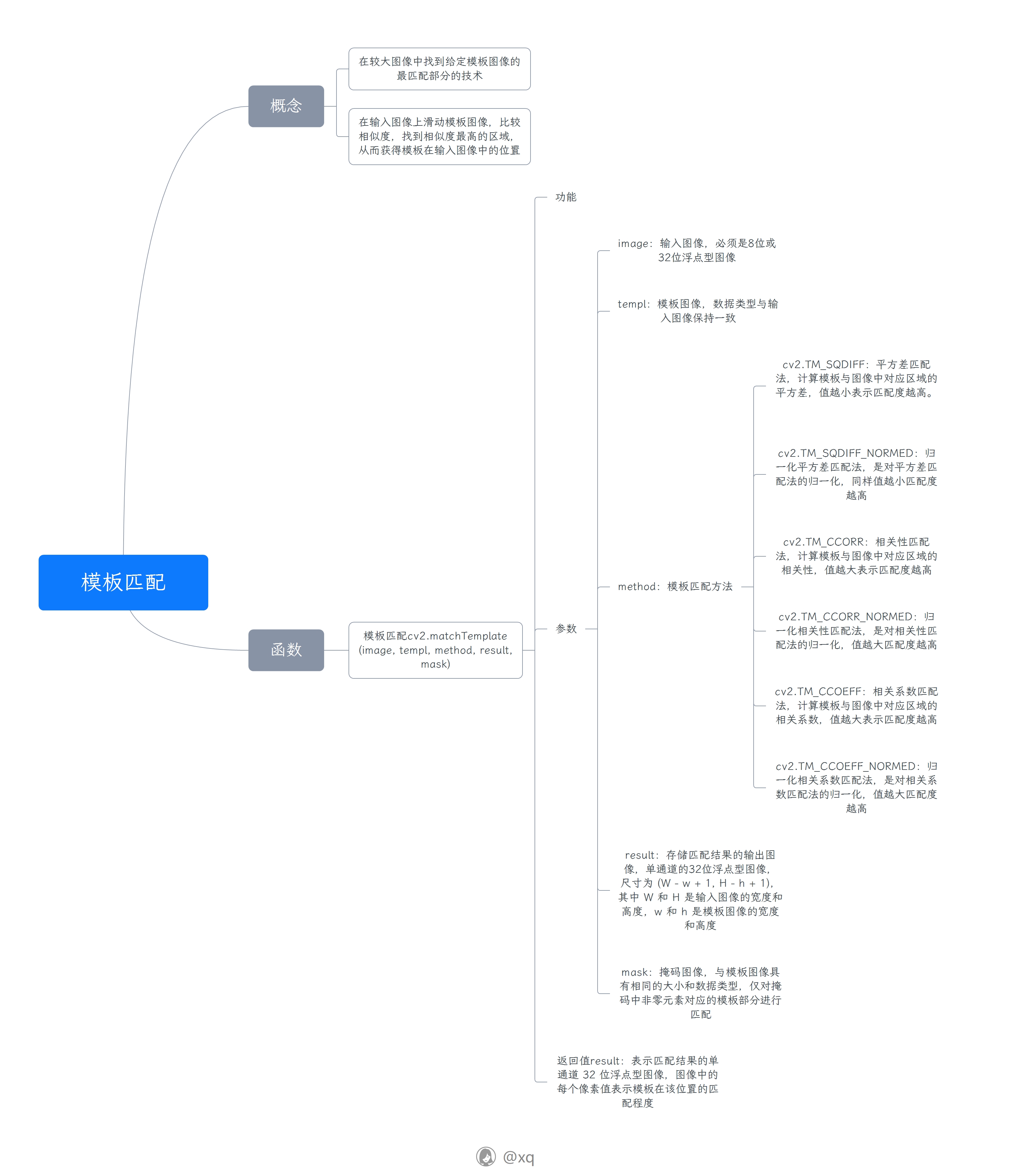
RAG
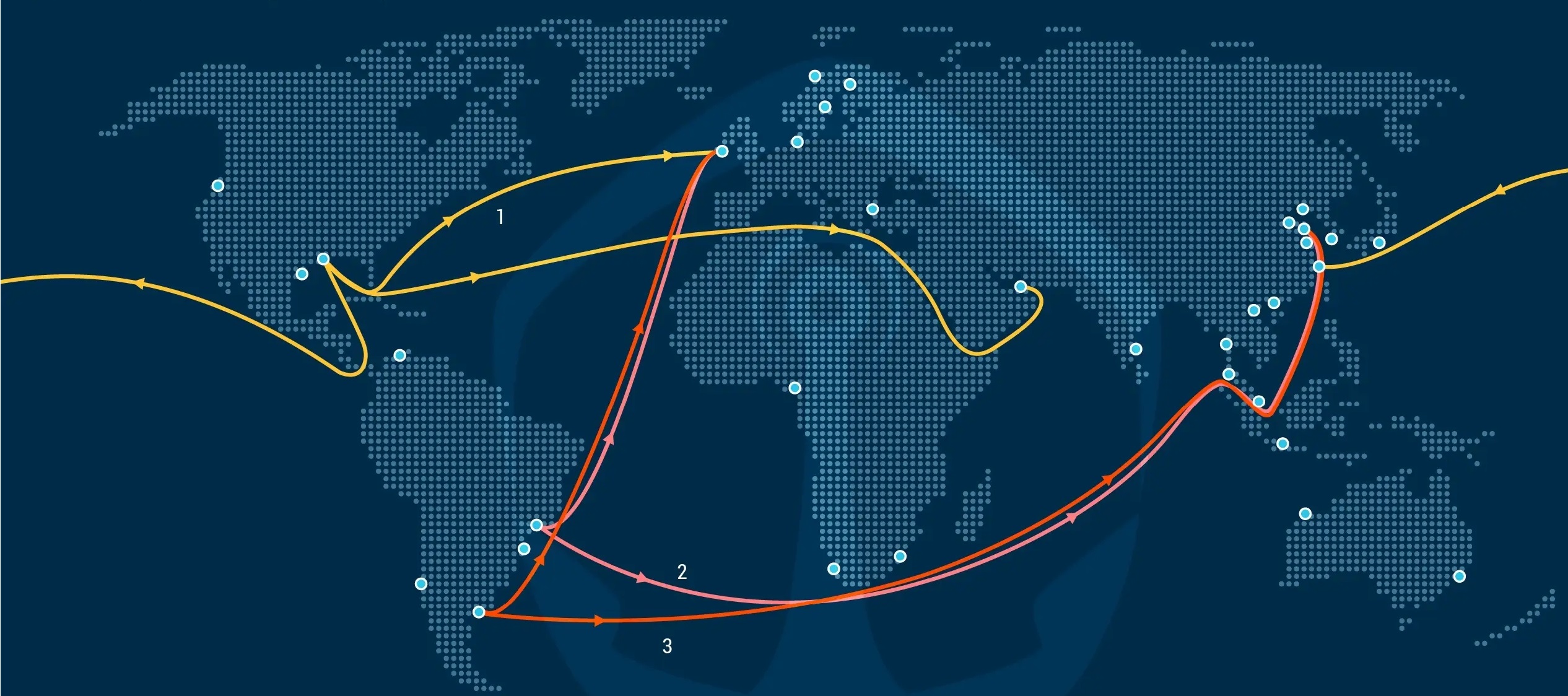
RAG过程
离线过程:
- 加载文档
- 将文档按一定条件切割成片段
- 将切割的文本片段转为向量,存入检索引擎(向量库)
在线过程:
- 用户输入Query,将Query转为向量
- 从向量库检索,获得相似度TopN信息
- 将检索结果和用户输入,共同组成Prompt
- 将Prompt 输入大模型,获取LLM的回复
用langchian构建RAG
1. 加载文档
LangChain中的文档对象Document有两个属性:
page_content: str类型,记录此文档的内容。metadata: dict类型,保存与此文档相关的元数据,包括文档ID、文件名等。
在langchain中,加载文档使用 文档加载器DocumentLoader 来实现,它从源文档加载数据并返回文档列表。每个DocumentLoader都有其特定的参数,但它们都可以通过.load()方法以相同的方式调用。
加载pdf
需要先安装pypdf库
pip install pypdf
用PyPDFLoader加载pdf,输入是文件路径,输出提取出的内容列表:
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_path)
pages = []
for page in loader.load():
pages.append(page)
返回的文档列表如下所示:
[
Document(
metadata={'source': 'D:\\桌面\\RAG分析.pdf', 'page': 0},
page_content='11111111111111111111111111111111111111111111111111111111'),
Document(
metadata={'source': 'D:\\桌面\\RAG分析.pdf', 'page': 1},
page_content='2222222222222222222222222222222222222222222222222222222')
]
加载网页
简单快速的文本提取
对于“简单快速”解析,需要 langchain-community 和 beautifulsoup4 库:
pip install langchain-community beautifulsoup4
使用WebBaseLoader,输入是url的列表,返回一个 Document 对象的列表,列表里的内容是一系列包含页面文本的字符串。在底层,它使用的是 beautifulsoup4 库。
import bs4
from langchain_community.document_loaders import WebBaseLoader
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = WebBaseLoader(web_paths=[page_url])
docs = loader.load()
assert len(docs) == 1
print(docs)
这样提取出的基本上是页面 HTML 中文本的转储,可能包含多余的信息,提取的信息如下所示(截取了首部)
[
Document(
metadata={
'source': 'https://python.langchain.com/',
'title': 'How to add memory to chatbots | 🦜️🔗 LangChain',},
page_content='\n\n\n\n\nHow to add memory to chatbots | 🦜️🔗 LangChain\n\n\n\n\n\n\nSkip to main contentJoin us at '
)
]
如果了解底层 HTML 中主体文本的表示,可以通过 BeautifulSoup 指定所需的 <div> 类和其他参数。
下面仅解析文章的主体文本:
loader = WebBaseLoader(
web_paths=[page_url],
bs_kwargs={
"parse_only": bs4.SoupStrainer(class_="theme-doc-markdown markdown"),
},
bs_get_text_kwargs={"separator": " | ", "strip": True},
)
docs = []
async for doc in loader.alazy_load():
docs.append(doc)
assert len(docs) == 1
doc = docs[0]
提取出的内容如下所示:
[
Document(
metadata={
'source': 'https://python.langchain.com/docs/how_to/chatbots_memory/'
},
page_content='How to add memory to chatbots | A key feature of chatbots is their ability to use the content of previous conversational turns as context. '
)
]
可以使用各种设置对 WebBaseLoader 进行参数化,允许指定请求头、速率限制、解析器和其他 BeautifulSoup 的关键字参数。详细信息参见 API 参考。
高级解析
如果想对页面内容进行更细粒度的控制或处理,可以用langchain-unstructured进行高级解析。
pip install langchain-unstructured
pip install unstructured
注意: 如果不安装unstructured会报错!
下面的代码不是为每个页面生成一个 Document 并通过 BeautifulSoup 控制其内容,而是生成多个 Document 对象,表示页面上的不同结构。这些结构包括章节标题及其对应的主体文本、列表或枚举、表格等。
from langchain_unstructured import UnstructuredLoader
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = UnstructuredLoader(web_url=page_url)
docs = []
for doc in loader.load():
docs.append(doc)
print(docs[:5])
输出如下所示(太长了,截取了部分):
[
Document(
metadata={
'image_url': 'https://colab.research.google.com/assets/colab-badge.svg',
'link_texts': ['Open In Colab'],
'link_urls': ['https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/how_to/chatbots_memory.ipynb'],
'languages': ['eng'],
'filetype': 'text/html',
'url': 'https://python.langchain.com/docs/how_to/chatbots_memory/',
'category': 'Image',
'element_id': '76f10732f139a03f24ecf55613a5116a'
},
page_content='Open In Colab'
),
Document(
metadata={
'category_depth': 0,
'languages': ['eng'],
'filetype': 'text/html',
'url': 'https://python.langchain.com/docs/how_to/chatbots_memory/',
'category': 'Title',
'element_id': 'b6bfe64119578f39e0dd7d0287b2964a'
},
page_content='How to add memory to chatbots'
),
Document(
metadata={
'languages': ['eng'],
'filetype': 'text/html',
'parent_id': 'b6bfe64119578f39e0dd7d0287b2964a',
'url': 'https://python.langchain.com/docs/how_to/chatbots_memory/',
'category': 'NarrativeText',
'element_id': 'ac3524f3e30afbdf096b186a665188ef'
},
page_content='A key feature of chatbots is their ability to use the content of previous conversational turns as context. This state management can take several forms, including:'
),
Document(
metadata={
'category_depth': 1,
'languages': ['eng'],
'filetype': 'text/html',
'parent_id': 'b6bfe64119578f39e0dd7d0287b2964a',
'url': 'https://python.langchain.com/docs/how_to/chatbots_memory/',
'category': 'ListItem',
'element_id': '0c9193e450bacf9a4d716208b2e7b1ee'
},
page_content='Simply stuffing previous messages into a chat model prompt.'
),
]
可以用doc.page_content来输出正文文本:
for doc in docs[:5]:
print(doc.page_content)
输出如下所示:
Open In Colab
Open on GitHub
How to add memory to chatbots
A key feature of chatbots is their ability to use the content of previous conversational turns as context. This state management can take several forms, including:
Simply stuffing previous messages into a chat model prompt.
2. 切割文档
当文档过长时,模型存在两方面问题:一是可能无法完整加载至上下文窗口,二是即便能加载,从中提取有用信息也较为困难。
为破解此困境,可将文档拆分成多个块来进行嵌入与存储,如此一来,分块后还能快速精准地定位到与查询最相关的部分。
在具体操作中,可以把文档按照每块 1000 个字符的规格进行拆分,同时在块之间设置 200 个字符的重叠。之所以设置重叠,是为了降低将某块有效信息与其关联的重要上下文被人为割裂开的风险,保证内容的连贯性与完整性。
以下代码采用的文本分割器是 RecursiveCharacterTextSplitter,它会利用常见分隔符对文档进行递归拆分,直至各块大小满足既定要求。此外,代码还启用了 add_start_index=True 的设置,使每个分割后的文档块在初始文档中的字符起始位置得以保留,这一位置信息将以元数据属性 “start_index” 的形式呈现。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
3. 将块转为向量存储到数据库
为了在运行时能够对文本块进行高效搜索,我们通常需要对文本块进行索引,而嵌入内容是实现这一目标的常见方法。
我们将每个文档分割后的文本块进行嵌入处理,并将这些嵌入插入到向量数据库中。当要搜索这些分割后的文本块时,可以将文本搜索查询进行嵌入,然后执行“相似性”度量,以识别出与查询嵌入最相似的存储文本块。其中,余弦相似性是一种简单且常用的相似性度量方法,它通过测量每对嵌入(高维向量)之间的角度的余弦值,来评估它们的相似程度。
我们可以通过Chroma 向量存储和 Ollama嵌入模型,完成对所有文档分割后的文本块的嵌入和存储工作。
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
embedding = OllamaEmbeddings(model_url="http://localhost:11434")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=embedding)
4. 检索
创建一个简单的应用程序,接受用户问题,搜索相关文档,并将检索到的文档和初始问题传递给模型以返回答案,具体步骤如下:
-
定义搜索文档的逻辑:LangChain 定义了一个检索器接口,它封装了一个可以根据字符串返回相关文档的索引查询。检索器的唯一要求是能够接受查询并返回文档,具体的底层逻辑由检索器指定。
-
使用向量存储检索器:最常见的检索器类型是向量存储检索器,它利用向量存储的相似性搜索能力来促进检索。任何
VectorStore都可以轻松转换为一个Retriever,使用VectorStore.as_retriever()方法。
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")
print(retrieved_docs[0].page_content)
输出如下所示:
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
5. 生成
生成时,将所有内容整合到一个链中,该链接受一个问题,检索相关文档,构建提示,将其传递给模型,并解析输出。
from langchain_community.document_loaders import UnstructuredURLLoader
from langchain_community.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.retrievers import VectorStoreRetriever
from langchain_community.prompts import PromptTemplate
from langchain_community.chains import RetrievalQA
# 加载文档
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = UnstructuredURLLoader(urls=[page_url])
# 拆分文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(loader.load())
# 创建向量存储和嵌入
embedding = OllamaEmbeddings(model_url="http://localhost:11434")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=embedding)
retriever = VectorStoreRetriever(vectorstore=vectorstore)
# 构建提示和生成链
prompt_template = """Use the following context to answer the question at the end. If the answer isn't found in the context, just say that you don't know.
{context}
Question: {question}"""
PROMPT = PromptTemplate.from_template(prompt_template)
# 创建 RAG 链
rag_chain = RetrievalQA.from_chain_type(
retriever=retriever,
chain_type="stuff",
prompt=PROMPT
)
# 执行查询
result = rag_chain.invoke("What are the approaches to Task Decomposition?")
print(result['result'])