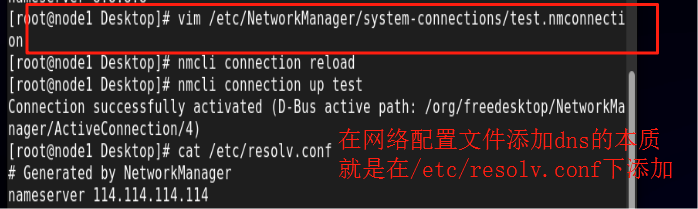
一、引言
高考志愿填报是考生人生的关键节点,合理的志愿填报能为其未来发展奠定良好基础。计算机类专业作为当下热门领域,相关信息对考生填报志愿至关重要。教育在线网站虽提供丰富的计算机类专业数据,但存在反爬机制,增加了数据获取难度。本研究借助 Scrapy 爬虫技术及多种数据处理分析方法,为考生提供全面准确的专业信息,辅助其科学填报志愿。
二、相关定义及工具
2.1 Scrapy 框架
Scrapy 是为爬取网站数据、提取结构性数据而设计的应用框架。它具备高效的异步网络请求、数据解析和存储能力,通过定义 Spider、Item、Pipeline 等组件,可方便地实现网页数据的爬取与处理。Spider 负责定义爬取逻辑和解析网页;Item 用于定义要爬取的数据结构;Pipeline 则处理爬取到的数据,如清洗、存储等。