一、引言
制药行业客户迫切需要一种翻译解决方案,以解决公司内部多样化的翻译难题。他们需要的不仅是提升翻译效率和准确性的工具,更希望能够保持文档的原始格式。我们观察到客户的需求广泛,包括多语言办公文件、研究文档和药品报批文件等,这些需求多变、紧急,且不规律。传统机器翻译的局限在于准确度不足、成本高昂、难以掌握专业术语等。
为响应这些需求,我们开发了一套基于大语言模型(LLM)的智能翻译工作流,它能够灵活适应各种翻译场景,自动化提升翻译效率与质量,同时也能保持文档原有格式。包括三种翻译模式:简单翻译、增强型翻译和专家型翻译,以满足不同场景的需求。简单翻译模式专注于迅速提炼关键信息,适合快速把握文档核心;增强型翻译模式在保持原文忠实度的同时,增加必要描述,助力读者深入理解内容;专家型翻译模式则确保翻译的精准与专业,适合对准确性要求较高的文档。本文将深入探讨这一工作流的设计和执行,讨论如何通过精准的提示词提升翻译品质,并结合实际案例,展示该工作流在提高翻译效率和准确性方面的显著成效。
二、自动翻译工作流技术实现
(一)工作流程
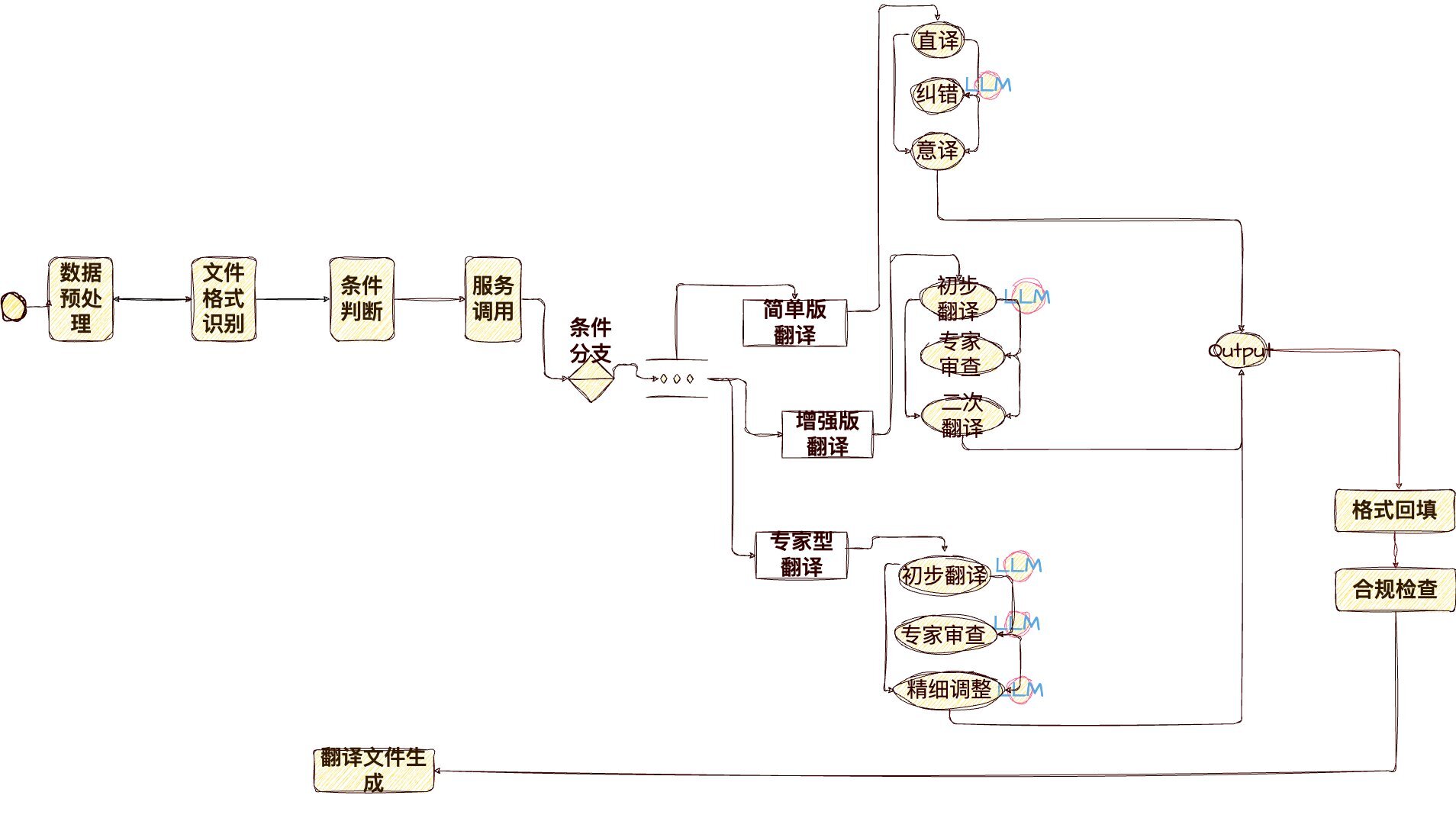
自动翻译工作流首先标准化和分割用户提交的内容,之后识别并提取文档中的文本、表格和图形。接着,根据文本类型和需求,自动或手动选择翻译策略。服务调用模块启动翻译流程,并将内容发送至翻译执行模块,该模块使用 LLM 技术进行翻译,提供三种翻译模式以适应不同需求。翻译后的内容按原格式回填,并可选合规检查以确保无敏感内容。最终翻译文件以用户指定的格式保存,便于使用和分享。
(二)工程设计细节
1、模块化设计:
-
数据预处理模块:负责接收和预处理原始翻译请求,包括文本清洗和格式标准化。
-
条件判断模块:根据预定义的业务规则对输入数据进行评估,人工或者自动决定翻译流程的路径。
-
翻译执行模块:调用大型语言模型进行翻译任务执行,根据上一步条件判断的决策结果调用不同的工作流完成翻译
-
合规处理模块:对翻译结果进行进一步的规范,让生成内容满足合规要求
-
翻译文件生成模块:格式化最终的翻译结果,并将其输出到指定的存储或传输介质。
2、参数和结果存储:
设计数据库或文件系统来存储工作流的输入参数和输出结果,以便于跟踪、审核和后续处理。为每个翻译任务生成唯一的标识符,关联其输入和输出数据,确保数据的完整性和可追溯性。
3、条件判断逻辑:
-
支持用户选择由 LLM 自动选择翻译方式
-
支持用户人工选择翻译方式
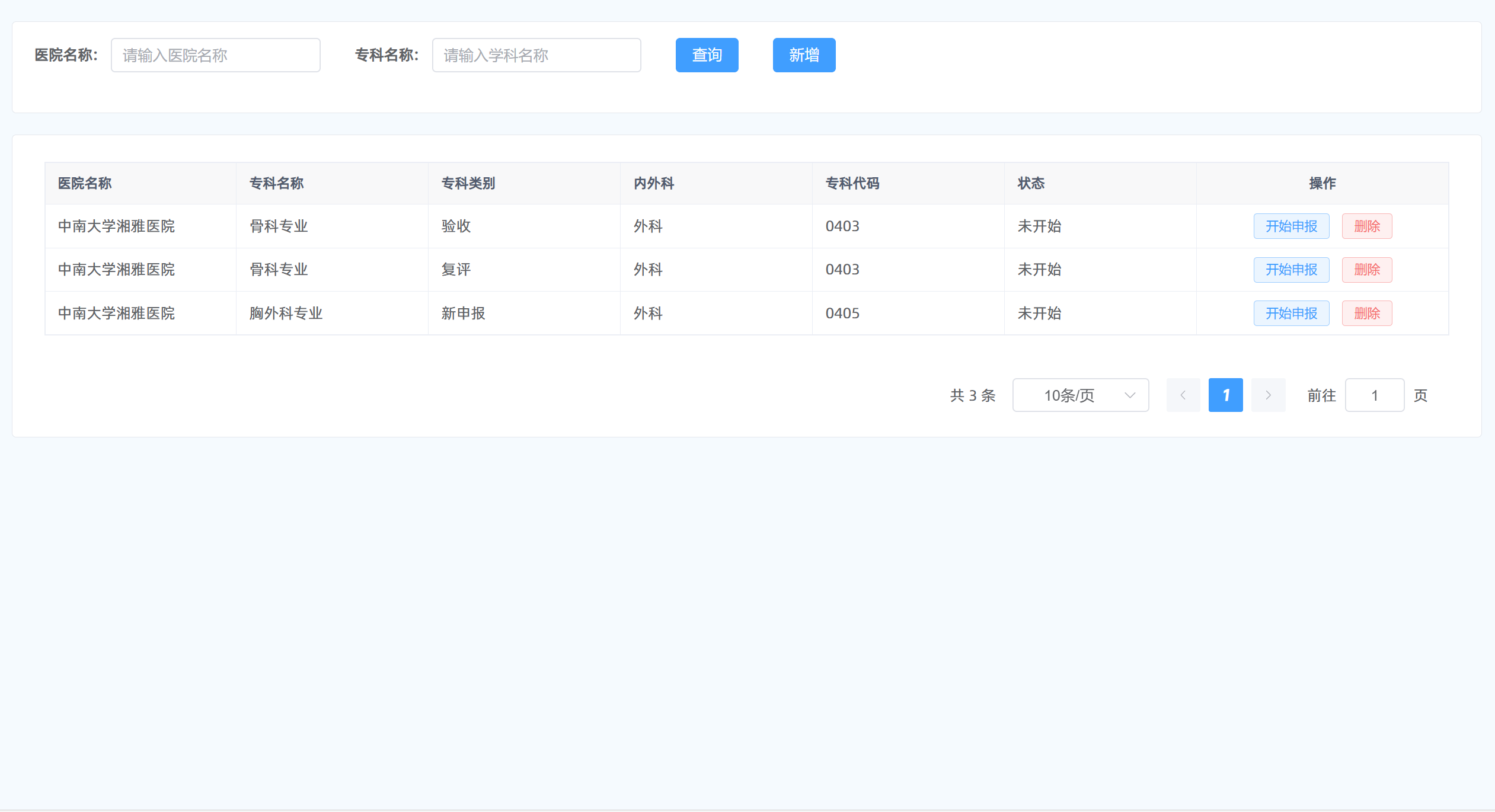
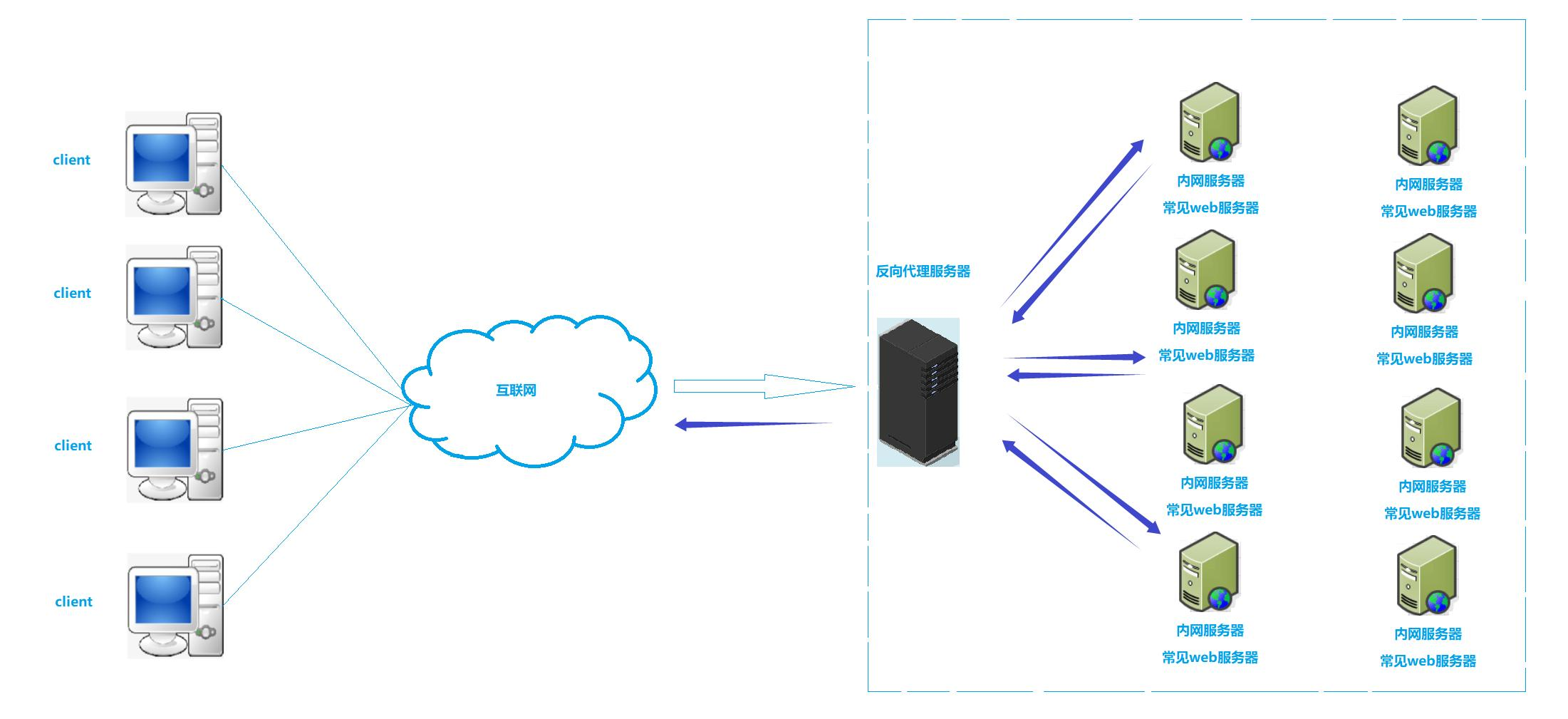
4、亚马逊云科技服务方案架构图
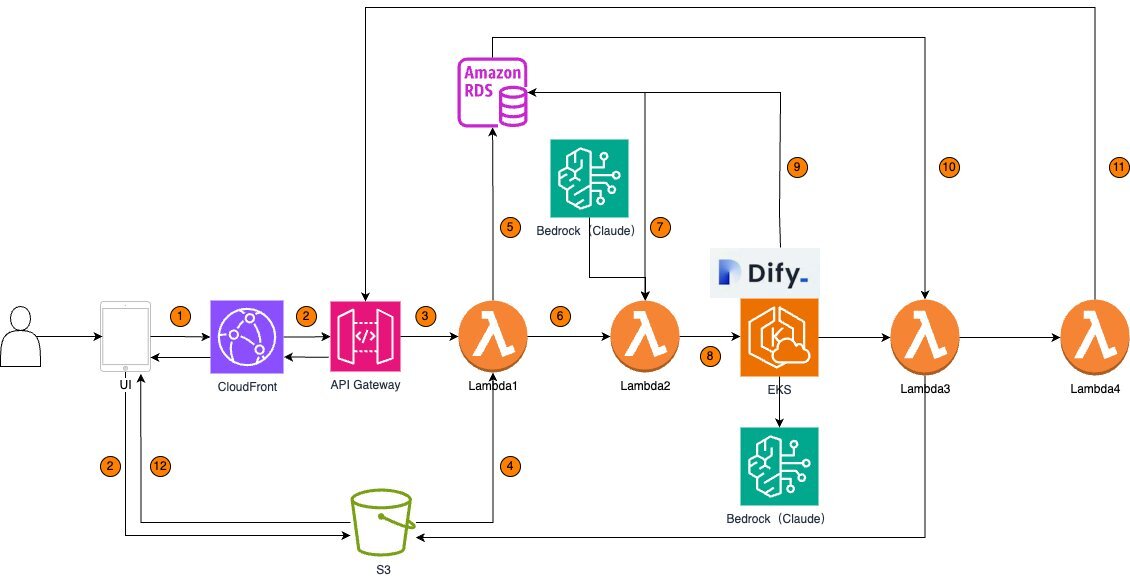
执行步骤:
-
用户通过用户界面上传文件到 S3、并发送翻译请求。
-
Amazon API Gateway 接收请求,并将其传递给 Lambda 1 进行文件预处理。
-
Lambda 1 处理文件后,将结果存储在 Amazon RDS 中。
-
Lambda 2 根据大模型选择翻译方式或者人工指定翻译方式,调用部署在 AWS EKS 上的 Dify 服务进行翻译任务。
-
Dify 服务调用 Bedrock 上 Claude 模型进行翻译处理。 翻译结果从 Bedrock 返回到 Dify,Dify 翻译结果存储到 Amazon RDS 中。
-
Lambda 3 从 Amazon RDS 读取翻译结果,进行格式回归,并将文件保存到 Amazon S3。
-
Lambda 3 保存文件后,触发 Lambda 4 生成下载链接。
-
Lambda 4 将下载链接提供给 Amazon API Gateway,后者再提供给用户界面。
-
用户通过用户界面下载翻译后的文件。
5、翻译模块设计(Dify 实现):
自动翻译工作流中的翻译模块由 Dify 工作流实现。具体 Dify 工作流设计如下图所示:
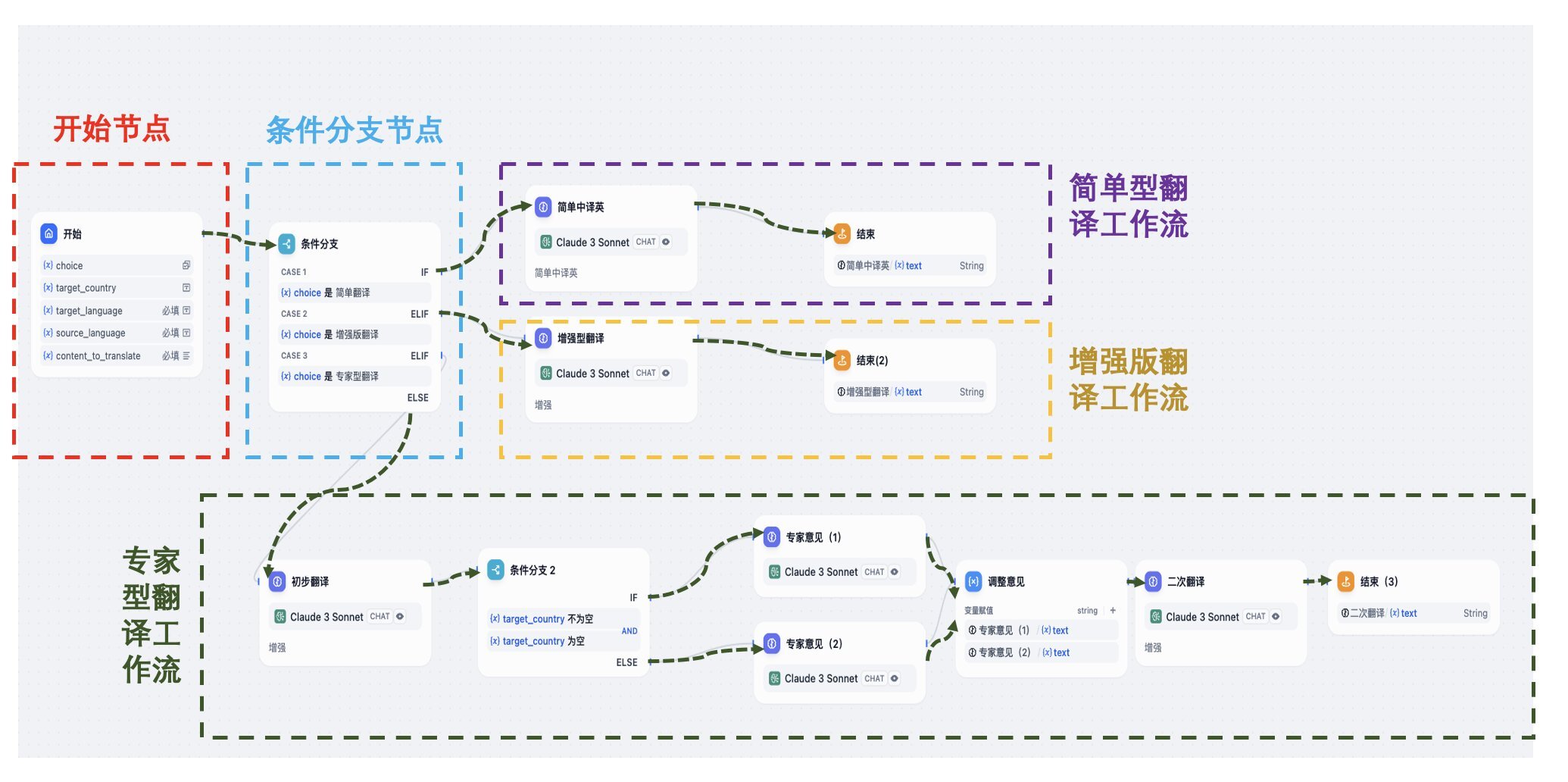
从开始节点接收用户输入的翻译需求,通过条件分支节点根据用户选择的翻译类型(简单、增强或专家型)引导至相应的翻译执行模块。简单型工作流直接使用 Claude 3 Sonnet 模型进行翻译;增强版在简单翻译后进一步优化;专家型则在初步翻译后,根据目标国家的条件可能加入专家意见,最后进行二次翻译以确保专业性。所有工作流最终都会输出翻译结果。
(1)简单翻译
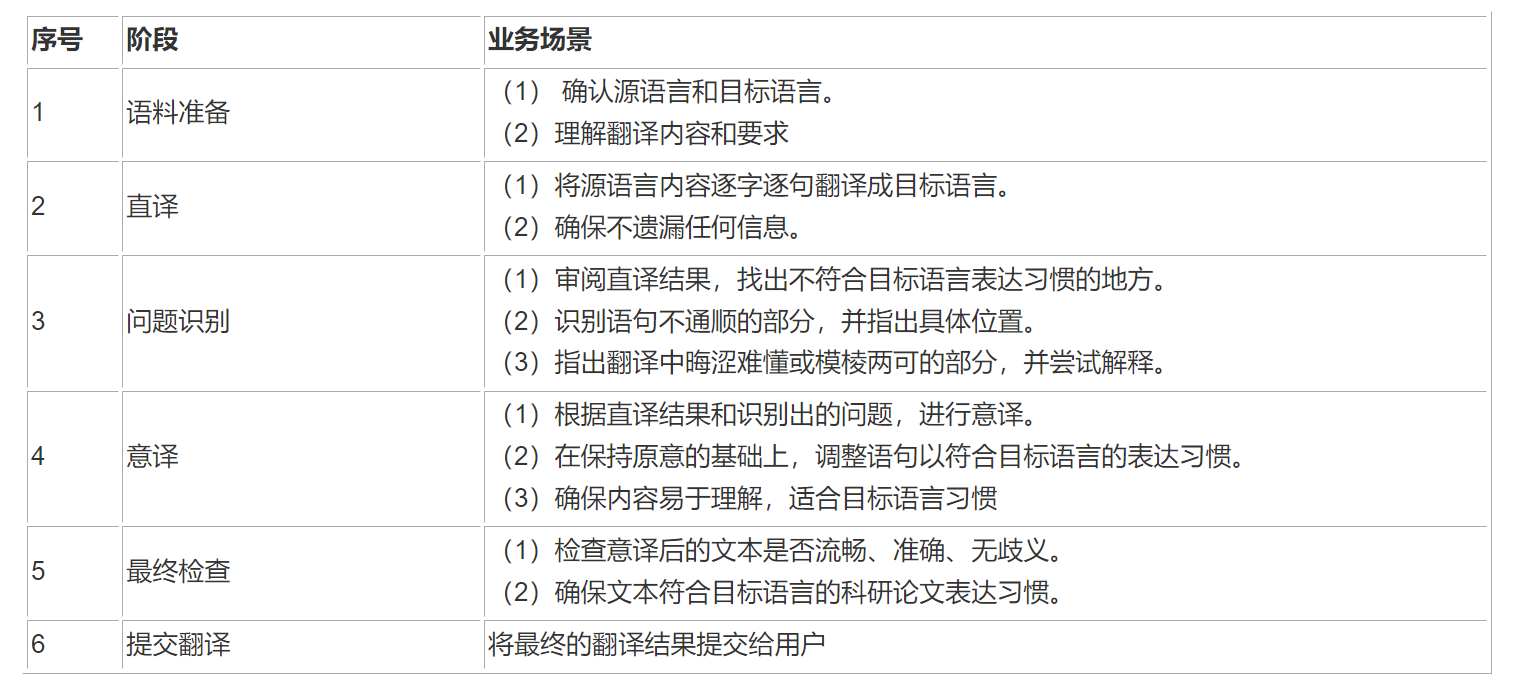
在“简单翻译”流程中,首先通过直译将内容从源语言翻译到目标语言,保持原有格式和信息的完整性。然后,翻译者会审查直译内容,指出不符合目标语言习惯、语句不通顺或晦涩难懂的问题。最后,基于直译和问题反馈,翻译者进行意译,以确保翻译内容不仅准确无误,而且流畅自然,同时平衡直译的忠实原文和意译的适应目标语言文化,以达到高质量的翻译效果。

-
部分提示词
## Role ##
You are a seasoned translator, skilled at writing high-quality articles. Please help me accurately translate the following content from {source_language} to {target_language}.
## Rules###
- The input format is in Markdown format, and the output format must also retain the original Markdown format. - Here is a common terminology correspondence table: {vocabulary}.
## Strategy##
The translation work is carried out in three steps, and the results of each step are printed:
1. Directly translate the content from {source_language} to {target_language}, maintaining the original format and not omitting any information.
2. Based on the result of the first step, identify specific issues that exist, describe accurately without being vague, and do not add content or formats that do not exist in the original text, including but not limited to:
2.1 Not conforming to the expression habits of {target_language}, clearly point out the non-conforming parts.
2.2 Sentences that are not smooth, indicate the location, no need to give modification suggestions, fix during free translation.
2.3 Vague, ambiguous, difficult to understand, you can try to give an explanation.
3. Based on the result of the first step and the issues pointed out in the second step, re-translate with the intention of ensuring the original meaning of the content, making it easier to understand and more in line with the expression habits of English scientific papers, while keeping the original format unchanged.
## Format##
The return format is as follows, where "{xxx}" represents a placeholder
### Direct Translation {Direct translation result}##
***
### Problems##
{List of specific problems in the direct translation}
***
### Paraphrase {Paraphrased result}##
### Important ###
Output only the new translation and nothing else.
To avoid mixing the {source_language} with the {target_language}, only the {target_language} should be output after translation.(2)增强版翻译
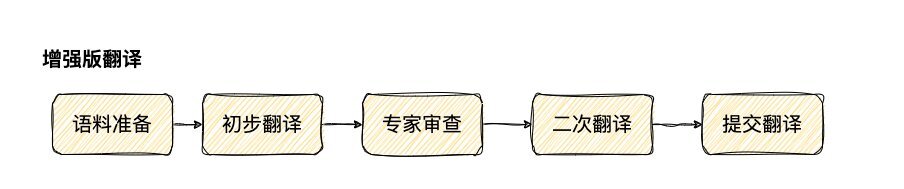
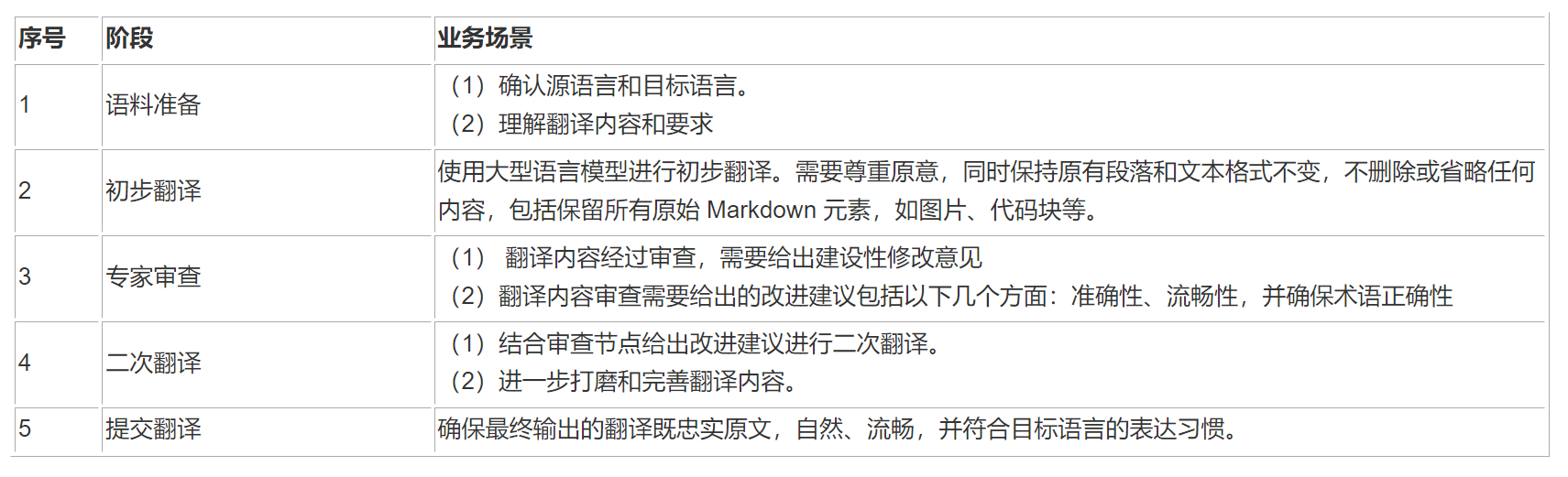
在“增强版翻译”流程中,工作逻辑开始于接收原始文本和必要的翻译参数,如源语言、目标语言和内容。然后,翻译内容会经过专家型语言模型的审查,该模型会给出具体的改进建议,以增强准确性、流畅性,并确保术语的一致性和文化适应性。最后,根据这些建议,进行二次翻译,以进一步打磨和完善翻译内容,确保最终输出的翻译既忠实原文,又自然、流畅,并符合目标语言的表达习惯。
-
部分提示词
You are a highly skilled translator tasked with translating various types of content from
into . Follow these instructions carefully to complete the translation task:
## Input ##
Depending on the type of input, follow these specific instructions:
1. If the input is a URL or a request to translate a URL:
First, request the built-in Action to retrieve the URL content. Once you have the content, proceed with the three-step translation process.
2. If the input is an image or PDF:
Get the content from image (by OCR) or PDF, and proceed with the three-step translation process.
3. Otherwise, proceed directly to the three-step translation process.
## Strategy ##
You will follow a three-step translation process:
1. Translate the input content from
into , respecting the original intent, keeping the original paragraph and text format unchanged, not deleting or omitting any content, including preserving all original Markdown elements like images, code blocks, etc.
2. Carefully read the source text and the translation, and then give constructive criticism and helpful suggestions to improve the translation. The final style and tone of the translation should match the style of
colloquially spoken in . When writing suggestions, pay attention to whether there are ways to improve the translation. The final style and tone of the translation should match the style of
colloquially spoken in . When writing suggestions, pay attention to whether there are ways to improve the translation.
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),
(ii) fluency (by applying
grammar, spelling and punctuation rules, and ensuring there are no unnecessary repetitions),
(iii) style (by ensuring the translations reflect the style of the source text and take into account any cultural context),
(iv) terminology (by ensuring terminology use is consistent and reflects the source text domain; and by only ensuring you use equivalent idioms ).
3. Based on the results of steps 1 and 2, refine and polish the translation
3. Based on the results of steps 1 and 2, refine and polish the translation
## Glossary
Here is a glossary of technical terms to use consistently in your translations:
## Output
For each step of the translation process, output your results within the appropriate XML tags:
<step1_initial_translation>
[Insert your initial translation here]
</step1_initial_translation>
<step2_reflection>
[Insert your reflection on the translation, write a list of specific, helpful and constructive suggestions for improving the translation. Each suggestion should address one specific part of the translation.]
</step2_reflection>
<step3_refined_translation>
[Insert your refined and polished translation here]
</step3_refined_translation>
Remember to consistently use the provided glossary for technical terms throughout your translation. Ensure that your final translation in step 3 accurately reflects the original meaning while sounding natural in
.
### Important ###
Output only the new translation and nothing else.
To avoid mixing the {source_language} with the {target_language}, only the {target_language} should be output after translation.(3)专家型翻译
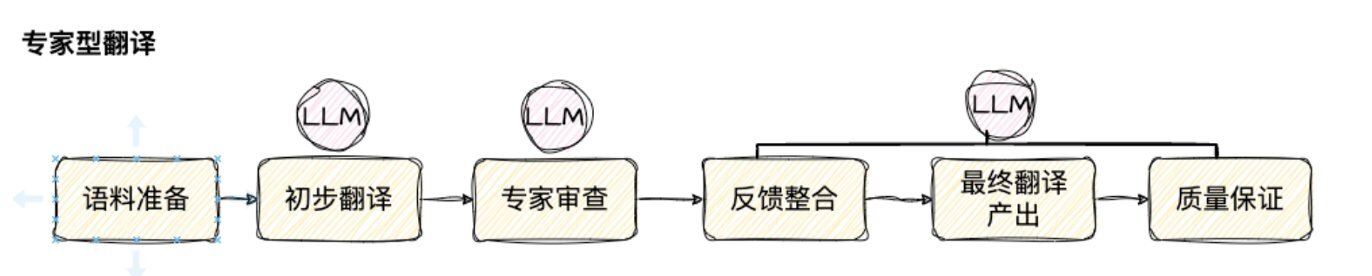
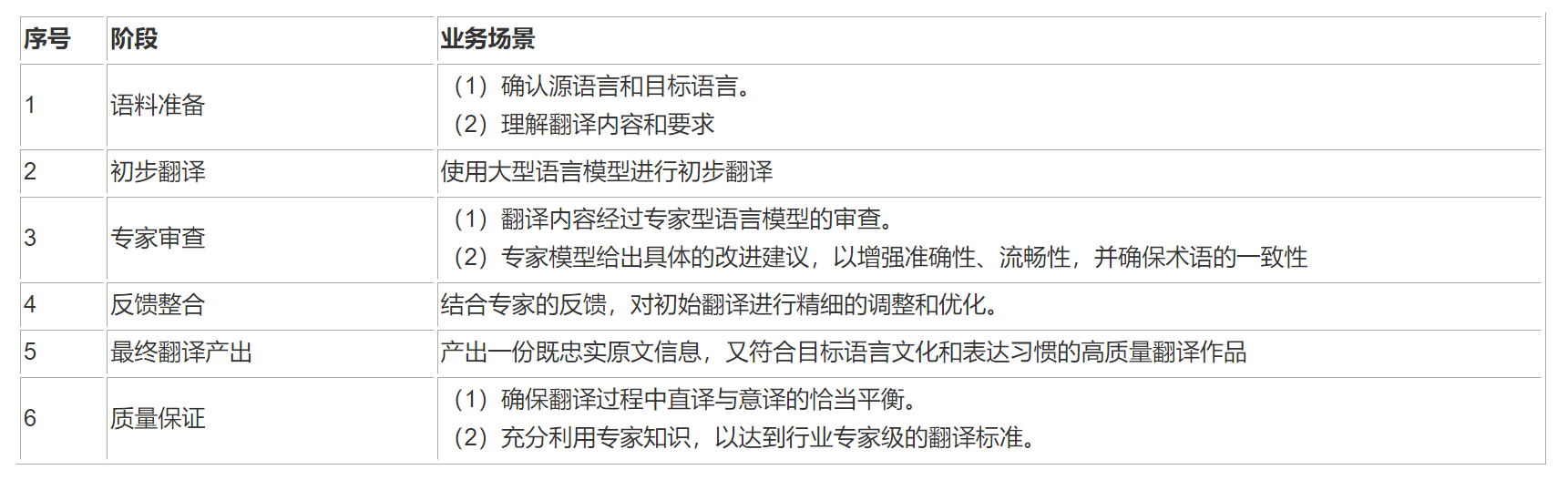
在“专家型翻译”流程中,工作逻辑首先涉及接收翻译任务的基本参数,包括原文内容、源语言和目标语言。接着,利用大型语言模型进行初步直译,生成初始翻译草稿。然后,通过专家型语言模型对直译结果进行细致的审查,提供专业的修改建议,这些建议关注于提升翻译的准确性、流畅性、风格一致性以及术语的恰当使用。最后,结合专家的反馈,对初始翻译进行精细的调整和优化,以产出一份既忠实原文信息,又符合目标语言文化和表达习惯的高质量翻译作品。这一流程确保了翻译过程中直译与意译的恰当平衡,以及专家知识的充分利用,以达到行业专家级的翻译标准。
-
部分提示词:
Your task is to carefully read a source text and a translation from {
{source_language}}to {
{target_language}}and then give constructive criticism and helpful suggestions to improve the translation.
The final style and tone of the translation should match the style of {
{target_language}}colloquially spoken in {
{target_country}}.
The source text and initial translation, delimited by XML tags <SOURCE_TEXT></SOURCE_TEXT> and <TRANSLATION></TRANSLATION>, are as follows:
<SOURCE_TEXT>
{
{content_to_translate}}
</SOURCE_TEXT>
<TRANSLATION>
{
{text}}
</TRANSLATION>
When writing suggestions, pay attention to whether there are ways to improve the translation's
(i) accuracy (by correcting errors of addition, mistranslation, omission, or untranslated text),
(ii) fluency (by applying {
{target_language}}grammar, spelling and punctuation rules, and ensuring there are no unnecessary repetitions),
(iii) style (by ensuring the translations reflect the style of the source text and take into account any cultural context),
(iv) terminology (by ensuring terminology use is consistent and reflects the source text domain; and by only ensuring you use equivalent idioms {
{target_language}}.
Write a list of specific, helpful and constructive suggestions for improving the translation.
Each suggestion should address one specific part of the translation.
Output only the suggestions and nothing else.6、文档格式保留和还原
采用结构化的方法来确保文档的原始格式的保留。例如,.docx 格式文档通过 python-docx 库加载 .docx 文件,该库提供了访问文档各个组成部分的能力。遍历文档中的所有段落、表格、内联形状以及页眉和页脚,提取其中的文本内容,并将这些文本收集到一个列表中,为翻译工作做准备。
在翻译阶段,利用多线程执行提高效率,通过 concurrent.futures.ThreadPoolExecutor 创建线程池,并将待翻译的文本列表分配给 translate 函数进行并行处理。这个函数调用 LLM 来执行实际的翻译任务。
翻译完成后,需要将翻译后的文本准确地还原到原始文档的相应位置。通过维护一个索引 i 来跟踪翻译文本 translated_texts 列表中的位置,再次遍历文档的各个部分,并将翻译后的文本放回原来的位置。这包括更新段落文本、表格单元格内容、内联形状中的文本以及页眉和页脚中的文本。
修改后的文档被保存为一个新的 .docx 文件,文件名中包含时间戳,以确保与原始文件区分开来。这样可以让翻译后的文档在内容和形式上都与原始文档保持一致。
文档格式还原部分代码:
def translate_docx_file(docx_file, from_language, to_language):
"""
翻译指定的 .docx 文件并保存为新的 .docx 文件。
"""
doc = docx.Document(docx_file)
texts = []
# 提取文本
for para in doc.paragraphs:
if para.text:
texts.append(para.text)
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
texts.append(cell.text)
for shape in doc.inline_shapes:
if hasattr(shape, 'text_frame'):
text_frame = shape.text_frame
for para in text_frame.paragraphs:
texts.append(para.text)
for section in doc.sections:
header = section.header
for para in header.paragraphs:
texts.append(para.text)
logger.info(f">>>> Number of tasks: {len(texts)}")
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
results = executor.map(lambda text: translate(text, from_language, to_language), texts)
translated_texts = list(results)
i = 0
for para in doc.paragraphs:
if para.text:
logger.info(f"assemble: {para.text}\n {translated_texts[i]}")
para.text = translated_texts[i]
i += 1
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
cell.text = translated_texts[i]
i += 1
for shape in doc.inline_shapes:
if hasattr(shape, 'text_frame'):
text_frame = shape.text_frame
for para in text_frame.paragraphs:
para.text = translated_texts[i]
i += 1
for section in doc.sections:
header = section.header
for para in header.paragraphs:
para.text = translated_texts[i]
i += 1
# 保存翻译后的文档
ts = time.strftime('%Y%m%d%H%M%S')
new_file_name = os.path.splitext(docx_file)[0] + f'_{ts}_translated.docx'
doc.save(new_file_name)
logger.info(f"<<< {ts} Completed.")
return new_file_name三、翻译效果测试
我们使用客户提供的一篇待翻译文档 (.docx 格式)作为测试样例,上传至自动翻译工作流,分别使用简单翻译、增强版翻译和专家翻译三种方式执行翻译任务。根据分析翻译结果进行对比、分析。
原文内容如下:

翻译后内容(以专家版翻译为例)如下:

通过对翻译结果对比,发现在原文件格式保留方面,几乎没有差别。同时发现主要区别集中在翻译内容的输出上。简单版翻译在内容完整性上会进行一些省略。
例如,原文中:
In order to standardize the supervision and inspection of drug clinical trial institutions, and strengthen the management of drug clinical trials, this Measure is formulated in accordance with the Drug Administration Law of the People’s Republic of China, the Vaccine Administration Law of the People’s Republic of China, the Drug Registration Administration Measures, the Administrative Regulations on Drug Clinical Trial Institutions, and the Good Clinical Practice (hereinafter referred to as GCP).
简单版翻译的翻译结果为:

可以看到这份翻译省略了对《中华人民共和国疫苗管理法》、《药品注册管理办法》、《药物临床试验机构管理规定》和《药物临床试验质量管理规范》(GCP)的引用。因为这种没有涵盖原文中提到的所有法律和规定,也因此显著降低了翻译内容的完整性,因为它没可能影响到对监管框架的全面理解。
增强版翻译结果为:

可以看到在内容完整性方面,增强版翻译保证了内容完整,同时为了方便读者理解,尝试提供更多的法律和规定细节,但可能引入了原文中未提及的内容,例如“保证临床试验数据的真实性、可靠性和追溯性”这样的描述性语言。
专家版翻译结果为:

在内容完整性方面,专家版翻译完整地保留了原文中提到的所有法律和规定,包括 GCP 的引用。同时为了保证与原文一致,没有加入任何描述性或者解释性语言。比较好地保持了与原文一致、完整、不偏不漏。
除此之外,在准确度方面简单版翻译使用了较为泛化、通俗的表达方式,如“主要缺陷”而不是“重大药品质量缺陷”,可能影响到读者对缺陷严重性的理解。增强版翻译和专家版翻译由于引入了术语表,因此在术语的使用上表现相对更好,与行业标准术语更为一致。在流畅度方面,简单版翻译的句子结构清晰,易于理解,但在某些术语的使用上可能略显生硬。增强版翻译在流畅度上也表现不错,但是由于加入了原文之外的解释,可能会略显冗长。专家版翻译在流畅度上与增强版翻译相似,在行文规范要求更加严格,翻译内容最接近原文。
从以上的分析可以看出,简单版翻译的适用场景主要是需要快速了解文档大意的非正式场合,例如初步审查或一般性了解,或者对专业术语要求不高、不需要精确法律或技术细节的场合,以及帮助新手快速了解某个领域的基本概念;增强版翻译的适用场景主要为适用于需要一定程度的专业性和准确性,同时也需要易于理解的文档;而专家型翻译的内容翻译完整性、准确度和行文风格最贴近原文,因此更适用于对准确性和完整性要求比较高的场合,以及要求反应原文的精确意图和细节的诉求。
四、回顾与总结
通过对比分析,我们可以看到,自动翻译工作流能够:
-
理解和保持原文档的格式与内容。
-
自动化判断或人工指定三种不同的翻译方式,方便适配不同的翻译需求。简单版翻译适用于快速浏览和非正式场合;增强版翻译适用于需要一定程度专业性的内部文档;专家型翻译在内容完整性、准确度和流畅度方面表现最佳,因此适用于更加正式技术文档。
-
保证翻译后的内容回填到原文档格式中,以保持文档格式不变。
这种方式满足企业级的多元化的内部翻译场景,有助于更好地提升用户的翻译体验。除了制药行业之外,该方案也可以拓展到其他的垂直行业使用,如制造、零售、游戏等行业使用。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者
本期最新实验《多模一站通 —— Amazon Bedrock 上的基础模型初体验》
✨ 精心设计,旨在引导您深入探索Amazon Bedrock的模型选择与调用、模型自动化评估以及安全围栏(Guardrail)等重要功能。无需管理基础设施,利用亚马逊技术与生态,快速集成与部署生成式AI模型能力。
⏩️[点击进入实验] 即刻开启 AI 开发之旅
构建无限, 探索启程!