一、分布式缓存简介
1. 什么是分布式缓存
分布式缓存:指将应用系统和缓存组件进行分离的缓存机制,这样多个应用系统就可以共享一套缓存数据了,它的特点是共享缓存服务和可集群部署,为缓存系统提供了高可用的运行环境,以及缓存共享的程序运行机制。
2、本地缓存VS分布式缓存
本地缓存:是应用系统中的缓存组件,其最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持的场景下使用本地缓存较合适;但是,它的缺点也是应为缓存跟应用程序耦合,多个应用程序无法共享缓存数据,各应用或集群的各节点都需要维护自己的单独缓存。很显然,这是对内存是一种浪费。
分布式缓存:与应用分离的缓存组件或服务,分布式缓存系统是一个独立的缓存服务,与本地应用隔离,这使得多个应用系统之间可直接的共享缓存数据。目前分布式缓存系统已经成为微服务架构的重要组成部分,活跃在成千上万的应用服务中。但是,目前还没有一种缓存方案可以解决一切的业务场景或数据类型,我们需要根据自身的特殊场景和背景,选择最适合的缓存方案。
3、分布式缓存的特性
相对于本地应用缓存,分布式缓存具有如下特性:
(1) 高性能:当传统数据库面临大规模数据访问时,磁盘I/O 往往成为性能瓶颈,从而导致过高的响应延迟。分布式缓存将高速内存作为数据对象的存储介质,数据以key/value 形式存储。
(2) 动态扩展性:支持弹性扩展,通过动态增加或减少节点应对变化的数据访问负载,提供可预测的性能与扩展性;同时,最大限度地提高资源利用率;
(3) 高可用性:高可用性包含数据可用性与服务可用性两方面,故障的自动发现,自动转义。确保不会因服务器故障而导致缓存服务中断或数据丢失。
( 4) 易用性:提供单一的数据与管理视图;API 接口简单,且与拓扑结构无关;动态扩展或失效恢复时无需人工配置;自动选取备份节点;多数缓存系统提供了图形化的管理控制台,便于统一维护;
4、分布式缓存的应用场景
分布式缓存的典型应用场景可分为以下几类:
(1) 页面缓存:用来缓存Web 页面的内容片段,包括HTML、CSS 和图片等,多应用于社交网站等;
(2) 应用对象缓存:缓存系统作为ORM 框架的二级缓存对外提供服务,目的是减轻数据库的负载压力,加速应用访问;
(3) 状态缓存:缓存包括Session 会话状态及应用横向扩展时的状态数据等,这类数据一般是难以恢复的,对可用性要求较高,多应用于高可用集群;
( 4) 并行处理:通常涉及大量中间计算结果需要共享;
(5) 事件处理:分布式缓存提供了针对事件流的连续查询(continuous query)处理技术,满足实时性需求;
( 6) 极限事务处理:分布式缓存为事务型应用提供高吞吐率、低延时的解决方案,支持高并发事务请求处理,多应用于铁路、金融服务和电信等领域;
二、 为什么要用分布式缓存?
在传统的后端架构中,由于请求量以及响应时间要求不高,我们经常采用单一的数据库结构。这种架构虽然简单,但随着请求量的增加,这种架构存在性能瓶颈导致无法继续稳定提供服务。
通过在应用服务与DB中间引入缓存层,我们可以得到如下三个好处:
(1)读取速度得到提升。
(2)系统扩展能力得到大幅增强。我们可以通过加缓存,来让系统的承载能力提升。
(3)总成本下降,单台缓存即可承担原来的多台DB的请求量,大大节省了机器成本。

通过在应用服务与DB中间引入缓存层,我们可以得到如下三个好处:
(1)读取速度得到提升。
(2)系统扩展能力得到大幅增强。我们可以通过加缓存,来让系统的承载能力提升。
(3)总成本下降,单台缓存即可承担原来的多台DB的请求量,大大节省了机器成本。
三、常用的缓存技术
目前最流行的分布式缓存技术有redis和memcached两种,
1. Memcache
Memcached 是一个高性能,分布式内存对象缓存系统,通过在内存里维护一个统一的巨大的 Hash 表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。简单的说就是:将数据缓存到内存中,然后从内存中读取,从而大大提高读取速度。老旧不推荐
2. Redis
Redis 是一个开源(BSD 许可),基于内存的,支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API。可以用作数据库、缓存和消息中间件。
Redis 支持多种数据类型 - string、Hash、list、set、sorted set。提供两种持久化方式 - RDB 和 AOF。通过 Redis cluster 提供集群模式。
Redis的优势:
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。(事务)
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
3. 分布式缓存技术对比
不同的分布式缓存功能特性和实现原理方面有很大的差异,因此他们所适应的场景也有所不同。

四、分布式缓存实现方案
缓存的目的是为了在高并发系统中有效降低DB的压力,高效的数据缓存可以极大地提高系统的访问速度和并发性能。分布式缓存有很多实现方案,下面将讲一讲分布式缓存实现方案。
1、缓存实现方案
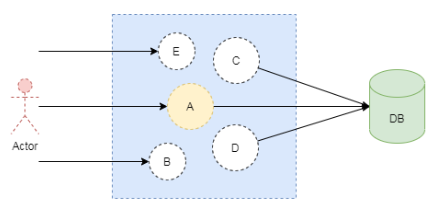
如上图所示,系统会自动根据调用的方法缓存请求的数据。当再次调用该方法时,系统会首先从缓存中查找是否有相应的数据,如果命中缓存,则从缓存中读取数据并返回;如果没有命中,则请求数据库查询相应的数据并再次缓存。
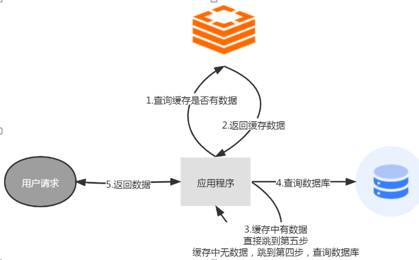
如上图所示,每一个用户请求都会先查询缓存中的数据,如果缓存命中,则会返回缓存中的数据。这样能减少数据库查询,提高系统的响应速度。
2、使用Spring Boot+Redis实现分布式缓存解决方案
接下来,以用户信息管理模块为例演示使用Redis实现数据缓存框架。
1.添加Redis Cache的配置类
RedisConfig类为Redis设置了一些全局配置,比如配置主键的生产策略KeyGenerator()方法,此类继承CachingConfigurerSupport类,并重写方法keyGenerator(),如果不配置,就默认使用参数名作为主键。
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport {
/ **
* 采用RedisCacheManager作为缓存管理器
* 为了处理高可用Redis,可以使用RedisSentinelConfiguration来支持Redis Sentinel
*/
@Bean
public CacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheManager redisCacheManager = RedisCacheManager.builder(connectionFactory).build();
return redisCacheManager;
}
/ **
* 自定义生成key的规则
*/
@Override
public KeyGenerator keyGenerator() {
return new KeyGenerator() {
@Override
public Object generate(Object o, Method method, Object...objects) {
// 格式化缓存key字符串
StringBuilder stringBuilder = new StringBuilder();
// 追加类名
stringBuilder.append(o.getClass().getName());
// 追加方法名
stringBuilder.append(method.getName());
// 遍历参数并且追加
for (Object obj :objects) {
stringBuilder.append(obj.toString());
}
System.out.println("调用Redis缓存Key: " + stringBuilder.toString());
return stringBuilder.toString();
}
};
}
}在上面的示例中,主要是自定义配置RedisKey的生成规则,使用@EnableCaching注解和@Configuration注解。
- @EnableCaching:开启基于注解的缓存,也可以写在启动类上。
- @Configuration:标识它是配置类的注解。
2.添加@Cacheable注解
在读取数据的方法上添加@Cacheable注解,这样就会自动将该方法获取的数据结果放入缓存。
@Repository
public class UserRepository {
/ **
* @Cacheable应用到读取数据的方法上,先从缓存中读取,如果没有,再从DB获取数据,然后把数据添加到缓存中
* unless表示条件表达式成立的话不放入缓存
* @param username
* @return
*/
@Cacheable(value = "user")
public User getUserByName(String username) {
User user = new User();
user.setName(username);
user.setAge(30);
user.setPassword("123456");
System.out.println("user info from database");
return user;
}
}在上面的实例中,使用@Cacheable注解标注该方法要使用缓存。@Cacheable注解主要针对方法进行配置,能够根据方法的请求对参数及其结果进行缓存。
1)这里缓存key的规则为简单的字符串组合,如果不指定key参数,则自动通过keyGenerator生成对应的key。
2)Spring Cache提供了一些可以使用的SpEL上下文数据,通过#进行引用。
3.测试数据缓存
创建单元测试方法调用getUserByName()方法,测试代码如下:
@Test
public void testGetUserByName() {
User user = userRepository.getUserByName("weiz");
System.out.println("name: "+ user.getName()+",age:"+user.getAge());
user = userRepository.getUserByName("weiz");
System.out.println("name: "+ user.getName()+",age:"+user.getAge());
}上面的实例分别调用了两次getUserByName()方法,输出获取到的User信息。
最后,单击Run Test或在方法上右击,选择Run 'testGetUserByName',运行单元测试方法,结果如下图所示。
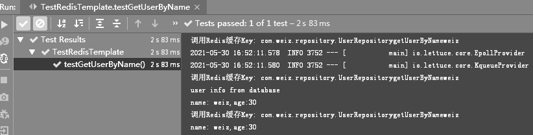
通过上面的日志输出可以看到,首次调用getPersonByName()方法请求User数据时,由于缓存中未保存该数据,因此从数据库中获取User信息并存入Redis缓存,再次调用会命中此缓存并直接返回。
五、常见问题及解决方案
1.缓存预热
缓存预热指在用户请求数据前先将数据加载到缓存系统中,用户查询 事先被预热的缓存数据,以提高系统查询效率。缓存预热一般有系统启动 加载、定时加载等方式。
5.热key问题
所谓热key问题就是,突然有大量的请求去访问redis上的某个特定key,导致请求过于集中,达到网络IO的上限,从而导致这台redis的服务器宕机引发雪崩。
针对热key的解决方案:
1. 提前把热key打散到不同的服务器,降低压力
2. 加二级缓存,提前加载热key数据到内存中,如果redis宕机,则内存查询
2.缓存击穿
缓存击穿是指大量请求缓存中过期的key,由于并发用户特别多,同时新的缓存还没读到数据,导致大量的请求数据库,引起数据库压力瞬间增大,造成过大压力。缓存击穿和热key的问题比较类似,只是说的点在于过期导致请求全部打到DB上而已。
解决方案:
1. 加锁更新,假设请求查询数据A,若发现缓存中没有,对A这个key加锁,同时去数据库查询数据,然后写入缓存,再返回给用户,这样后面的请求就可以从缓存中拿到数据了。
2. 将过期时间组合写在value中,通过异步的方式不断的刷新过期时间,防止此类现象发生。

3.缓存穿透
缓存穿透是指查询不存在缓存中的数据,每次请求都会打到DB,就像缓存不存在一样。
解决方案:
- 接口层增加参数校验,如用户鉴权校验,请求参数校验等,对 id<=0的请求直接拦截,一定不存在请求数据的不去查询数据库。
- 布隆过滤器:指将所有可能存在的Key通过Hash散列函数将它映射为一个位数组,在用户发起请求时首先经过布隆过滤器的拦截,一个一定不存在的数据会被这个布隆过滤器拦截,从而避免对底层存储系统带来查询上 的压力。
- cache null策略:指如果一个查询返回的结果为null(可能是数据不存在,也可能是系统故障),我们仍然缓存这个null结果,但它的过期 时间会很短,通常不超过 5 分钟;在用户再次请求该数据时直接返回 null,而不会继续访问数据库,从而有效保障数据库的安全。其实cache null策略的核心原理是:在缓存中记录一个短暂的(数据过期时间内)数据在系统中是否存在的状态,如果不存在,则直接返回null,不再查询数据库,从而避免缓存穿透到数据库上。
布隆过滤器
布隆过滤器的原理是在保存数据的时候,会通过Hash散列函数将它映射为一个位数组中的K个点,同时把他的值置为1。这样当用户再次来查询A时,而A在布隆过滤器值为0,直接返回,就不会产生击穿请求打到DB了。
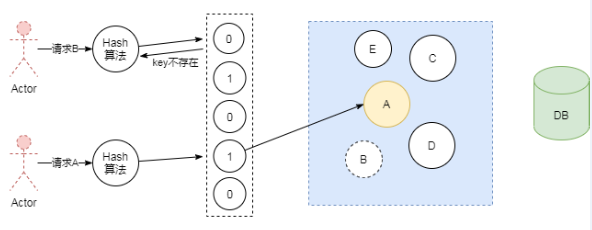
4.缓存雪崩
缓存雪崩指在同一时刻由于大量缓存失效,导致大量原本应该访问缓存的请求都去查询数据库,而对数据库的CPU和内存造成巨大压力,严重的话会导致数据库宕机,从而形成一系列连锁反应,使得整个系统崩溃。雪崩和击穿、热key的问题不太一样的是,缓存雪崩是指大规模的缓存都过期失效了。
针对雪崩的解决方案:
1. 针对不同key设置不同的过期时间,避免同时过期
2. 限流,如果redis宕机,可以限流,避免同时刻大量请求打崩DB
3. 二级缓存,同热key的方案。
六、缓存与数据库数据一致性
缓存与数据库的一致性问题分为两种情况,一是缓存中有数据,则必须与数据库中的数据一致;二是缓存中没数据,则数据库中的数据必须是最新的。
3.1删除和修改数据
第一种情况:我们先删除缓存,在更新数据库,潜在的问题:数据库更新失败了,get请求进来发现没缓存则请求数据库,导致缓存又刷入了旧的值。
第二种情况:我们先更新数据库,再删除缓存,潜在的问题:缓存删除失败,get请求进来缓存命中,导致读到的是旧值。
3.2先删除缓存再更新数据库
假设有2个线程A和B,A删除缓存之后,由于网络延迟,在更新数据库之前,B来访问了,发现缓存未命中,则去请求数据库然后把旧值刷入了缓存,这时候姗姗来迟的A,才把最新数据刷入数据库,导致了数据的不一致性。
解决方案
针对多线程的场景,可以采用延迟双删的解决方案,我们可以在A更新完数据库之后,线程A先休眠一段时间,再删除缓存。
需要注意的是:具体休眠的时间,需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。当然这种策略还要考虑redis和数据库主从同步的耗时。
3.3先更新数据库再删除缓存
这种场景潜在的风险就是更新完数据库,删缓存之前,会有部分并发请求读到旧值,这种情况对业务影响较小,可以通过重试机制,保证缓存能得到删除。
七、 分布式系统中使用 Redis 实现缓存更新通知
在分布式系统中使用 Redis 实现缓存更新通知的 Java 具体方案可以通过 发布订阅(Pub/Sub) 或 Redis Streams 实现。以下是详细的分步实现说明(基于 Jedis 或 Lettuce 客户端)。
环境准备
1. 添加 Maven 依赖
xml
复制
<!-- Jedis 客户端 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.4.3</version>
</dependency>
<!-- 或者 Lettuce 客户端 -->
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>6.2.6.RELEASE</version>
</dependency>2. Redis 连接配置
java
复制
// 使用 Jedis
JedisPool jedisPool = new JedisPool("redis-host", 6379);
// 使用 Lettuce
RedisClient redisClient = RedisClient.create("redis://redis-host:6379");
StatefulRedisConnection<String, String> connection = redisClient.connect();方案 1:Redis 发布订阅(Pub/Sub)
核心流程
- 发布者(数据变更时发送通知)
- 订阅者(所有节点监听频道并更新缓存)
代码实现
发布者(数据变更时触发)
jav
public class CacheUpdatePublisher {
private final Jedis jedis;
public CacheUpdatePublisher(JedisPool jedisPool) {
this.jedis = jedisPool.getResource();
}
// 数据更新后发送通知
public void updateDataAndNotify(String dataKey, String newValue) {
// 1. 更新数据库(伪代码)
// db.update(dataKey, newValue);
// 2. 发布缓存更新通知到频道
jedis.publish("cache-update-channel", dataKey);
System.out.println("已发布缓存更新通知: " + dataKey);
}
}订阅者(每个节点运行)
java
public class CacheUpdateSubscriber {
private final JedisPool jedisPool;
public CacheUpdateSubscriber(JedisPool jedisPool) {
this.jedisPool = jedisPool;
}
public void startListening() {
new Thread(() -> {
try (Jedis jedis = jedisPool.getResource()) {
// 订阅频道
jedis.subscribe(new JedisPubSub() {
@Override
public void onMessage(String channel, String message) {
// 收到通知后更新缓存
String dataKey = message;
System.out.println("收到缓存更新通知: " + dataKey);
// 删除旧缓存(或重新加载)
// cache.delete(dataKey);
// 从数据库加载最新数据(伪代码)
// String newValue = db.get(dataKey);
// cache.set(dataKey, newValue);
}
}, "cache-update-channel");
}
}).start();
}
}运行示例
java
public class Main {
public static void main(String[] args) {
JedisPool jedisPool = new JedisPool("localhost", 6379);
// 启动订阅者
CacheUpdateSubscriber subscriber = new CacheUpdateSubscriber(jedisPool);
subscriber.startListening();
// 模拟发布者更新数据
CacheUpdatePublisher publisher = new CacheUpdatePublisher(jedisPool);
publisher.updateDataAndNotify("user:1001", "new data");
}
}方案 2:Redis Streams(可靠消息队列)
核心流程
- 生产者(数据变更时写入 Stream)
- 消费者(节点消费消息并确认)
代码实现
生产者(写入 Stream)
java
public class CacheStreamProducer {
private final Jedis jedis;
public CacheStreamProducer(JedisPool jedisPool) {
this.jedis = jedisPool.getResource();
}
public void sendCacheUpdateEvent(String dataKey) {
// 写入 Stream,指定字段
Map<String, String> fields = new HashMap<>();
fields.put("key", dataKey);
jedis.xadd("cache-stream", StreamEntryID.NEW_ENTRY, fields);
System.out.println("已发送 Stream 消息: " + dataKey);
}
}消费者(节点消费消息)
java
public class CacheStreamConsumer {
private final JedisPool jedisPool;
private static final String GROUP_NAME = "cache-group";
private static final String CONSUMER_NAME = "node-1";
public CacheStreamConsumer(JedisPool jedisPool) {
this.jedisPool = jedisPool;
initializeStreamGroup();
}
// 初始化消费者组
private void initializeStreamGroup() {
try (Jedis jedis = jedisPool.getResource()) {
try {
jedis.xgroupCreate("cache-stream", GROUP_NAME, new StreamEntryID(), true);
} catch (Exception e) {
// 组已存在时忽略异常
}
}
}
public void startConsuming() {
new Thread(() -> {
try (Jedis jedis = jedisPool.getResource()) {
while (true) {
// 从 Stream 读取消息(阻塞式)
List<Entry<String, List<StreamEntry>>> messages = jedis.xreadGroup(
GROUP_NAME, CONSUMER_NAME, 1, 0, false,
Collections.singletonMap("cache-stream", ">")
);
if (messages != null && !messages.isEmpty()) {
for (StreamEntry entry : messages.get(0).getValue()) {
String dataKey = entry.getFields().get("key");
System.out.println("处理缓存更新: " + dataKey);
// 删除或更新缓存(伪代码)
// cache.delete(dataKey);
// 确认消息处理完成
jedis.xack("cache-stream", GROUP_NAME, entry.getID());
}
}
}
}
}).start();
}
}运行示例
java
public class Main {
public static void main(String[] args) {
JedisPool jedisPool = new JedisPool("localhost", 6379);
// 启动消费者
CacheStreamConsumer consumer = new CacheStreamConsumer(jedisPool);
consumer.startConsuming();
// 模拟生产者发送消息
CacheStreamProducer producer = new CacheStreamProducer(jedisPool);
producer.sendCacheUpdateEvent("user:1001");
}
}注意事项
- 幂等性设计
消费者可能重复收到同一条消息(如网络重试),需确保多次处理同一消息的结果一致。例如:
-
- j
if (!cache.isKeyLatest(dataKey, newValue)) {
cache.update(dataKey, newValue);
}- 消息丢失处理
-
- Pub/Sub:节点宕机期间的消息会丢失,需结合数据库版本号或定时全量同步。
- Streams:通过
XPENDING检查未确认消息,设计重试机制。
- 性能优化
-
- 批量处理:合并多个缓存更新事件(如攒批 100ms 内的消息)。
- 本地缓存:使用 Caffeine 或 Ehcache 作为一级缓存,减少 Redis 压力。
- 消费者负载均衡
-
- 在 Redis Streams 中,多个消费者可通过不同 Consumer 名称共享同一 Group,实现负载均衡。
方案对比
| 特性 | Pub/Sub | Redis Streams |
| 可靠性 | 低(消息无持久化) | 高(消息持久化,支持 ACK) |
| 实时性 | 高(即时推送) | 高(支持阻塞读取) |
| 复杂度 | 低(无需维护消费状态) | 中(需管理消费者组和消息 ID) |
| 适用场景 | 允许短暂消息丢失的实时通知 | 高可靠性要求的任务分发 |
总结
- 轻量级实时通知:选择 Pub/Sub,代码简单,适合对可靠性要求不高的场景(如社交动态更新)。
- 高可靠消息队列:选择 Redis Streams,适合订单状态同步、库存扣减等关键业务。
- 扩展方案:若需严格保证缓存与数据库一致性,可结合 MySQL Binlog 监听(如 Canal)同步到 Redis。