一、引言
1.1 研究背景
伴随互联网技术的迅猛发展,在线教育平台积累了海量备考数据。以粉某网为例,其备考数据涵盖考试资讯、备考资料、用户评价等,对备考者意义重大。然而,获取并分析这些数据颇具挑战,需借助先进的爬虫技术和数据分析方法。
1.2 研究目的
本研究旨在运用 Python 的 Scrapy 框架从粉某网爬取备考数据,通过一系列处理与分析,为备考者提供针对性备考建议和决策支持。具体目标为:实现稳定高效的数据爬取,应对网站反爬机制;对数据进行清洗整理,存储为 CSV 文件;运用数据分析和机器学习技术挖掘潜在信息与规律。
1.3 研究意义
本研究可为备考者提供全面准确的备考信息,提升备考效率与成功率;为在线教育平台的运营优化提供数据支撑,促进教育资源合理分配;丰富和发展网络数据爬取与分析技术,为相关研究提供参考。
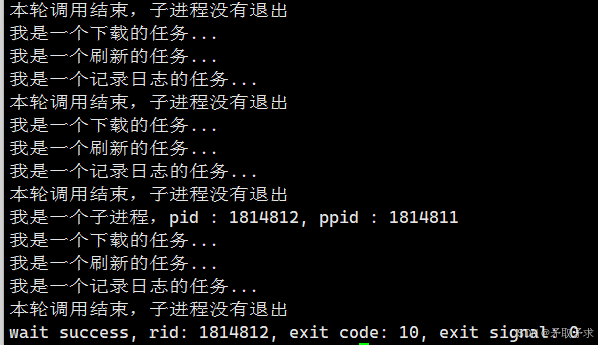
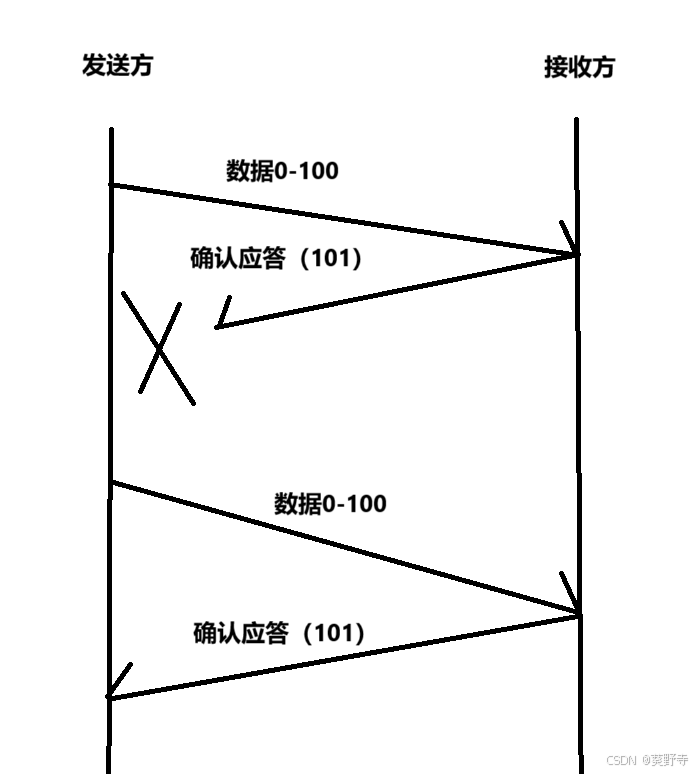
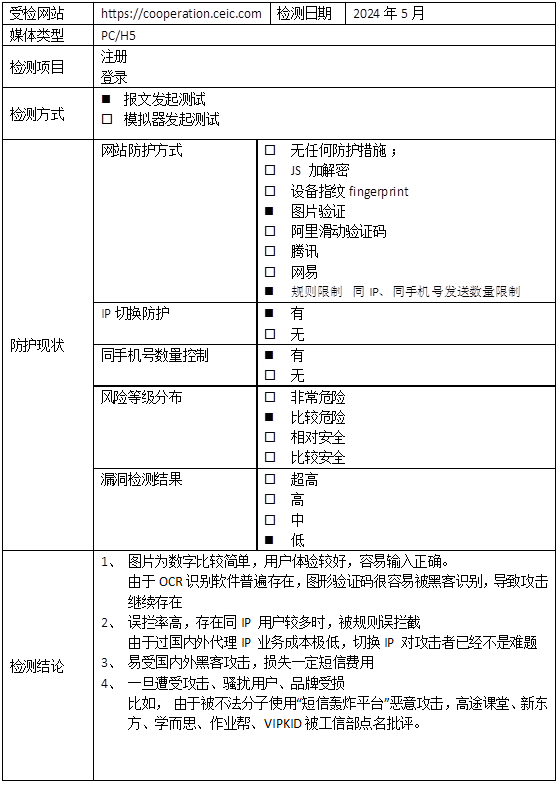



![[matlab]南海地形眩晕图代码](https://i-blog.csdnimg.cn/direct/31657d2f3ba74d27bc69e704b923cbce.png)
![[SpringBoot]快速入门搭建springboot](https://i-blog.csdnimg.cn/direct/303463e3e8754062ac30c5dac5f2b61e.png)