云原生学习路线导航页(持续更新中)
- kubernetes学习系列快捷链接
- Kubernetes架构原则和对象设计(一)
- Kubernetes架构原则和对象设计(二)
- Kubernetes架构原则和对象设计(三)
- Kubernetes控制平面组件:etcd(一)
- Kubernetes控制平面组件:etcd(二)
- Kubernetes控制平面组件:etcd常用配置参数
- Kubernetes控制平面组件:etcd高可用集群搭建
- Kubernetes控制平面组件:etcd高可用解决方案
- Kubernetes控制平面组件:Kubernetes如何使用etcd
- Kubernetes控制平面组件:API Server详解(一)
本文主要对kubernetes的控制面组件API Server 的限流机制进行详细介绍,涵盖常见的限流算法:固定窗口、滑动窗口、漏斗算法、令牌桶算法,还详细介绍了API Server的基础限流机制和APF优先级限流机制
- 希望大家多多 点赞 关注 评论 收藏,作者会更有动力继续编写技术文章
1.常见限流算法
1.1.计数器固定窗口算法
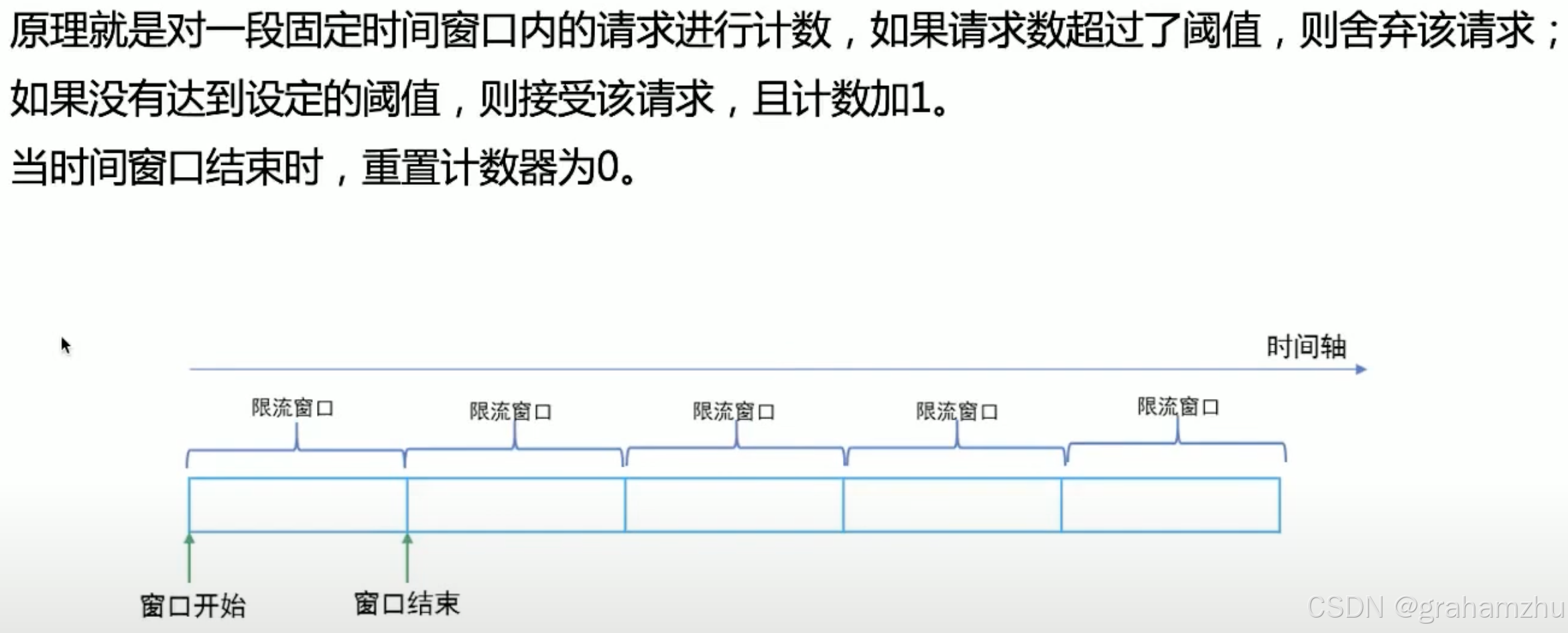
- 优点:实现简单
- 缺点:
- 场景一:可能在一段时间内接受超过服务能力的请求,导致服务挂掉。比如窗口1的最后1/10时间突增1000个请求,窗口2的最开始1/10时间突增1000个请求,那么相当于这2/10窗口期间,接收了2000个请求,可能就直接把服务打挂了
- 场景二:无法应对突增流量。比如在窗口1的时间刚开始1/10,来了一大波流量,直接就把请求数用尽了,那么窗口后续的9/10时间里,请求都将被拒绝
1.2.计数器滑动窗口算法

- 把一个大窗口切割成多个小窗口,总窗口的request数量小于最大并发量即可
- 优点:对固定窗口算法进行了优化,让请求流量变得更平滑
- 缺点:还是没有解决固定窗口算法存在的问题
1.3.漏斗算法
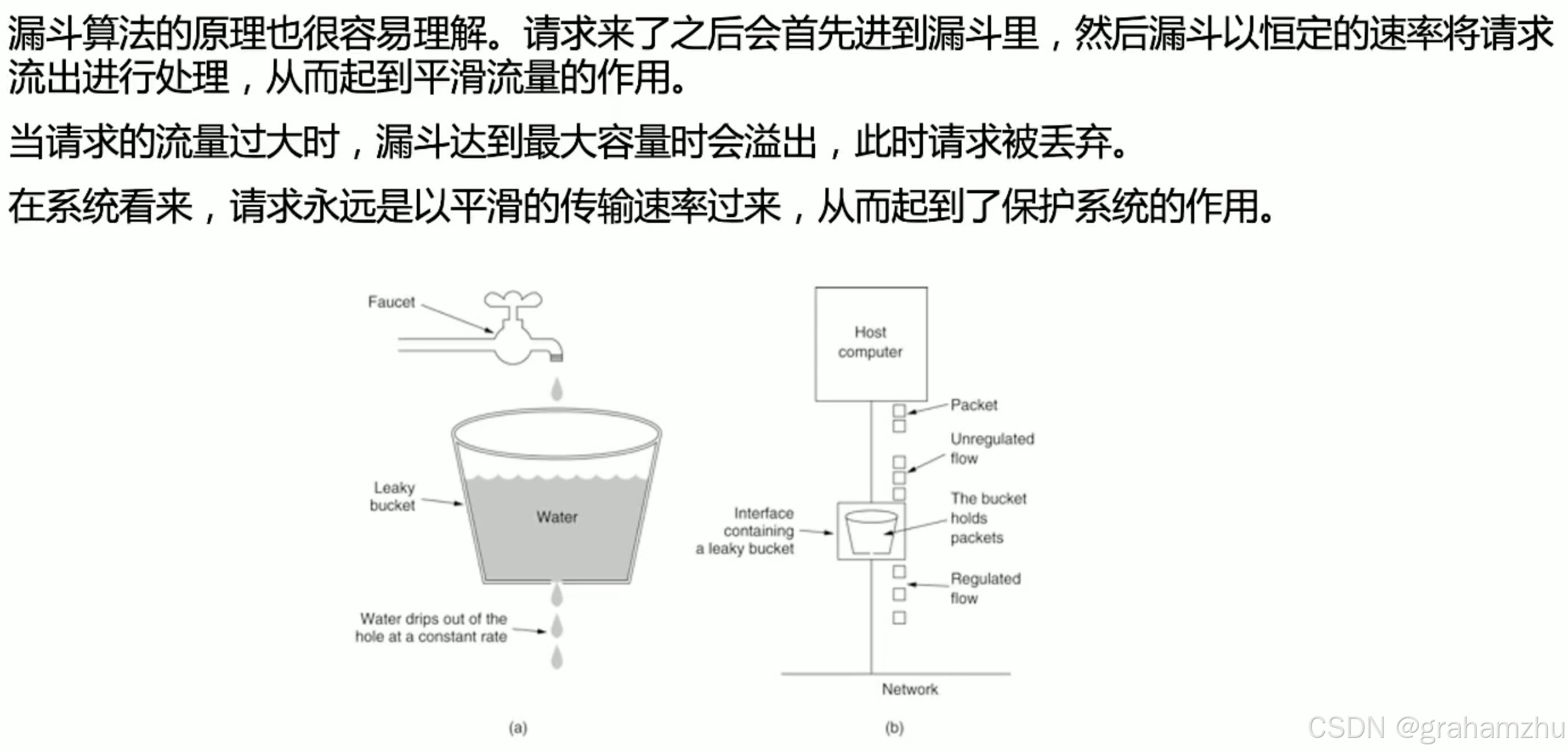
- 优点:控制了请求从漏斗出的速率,永远保证请求匀速进入系统,保护了系统
- 缺点:难以应对高峰请求,请求处理的慢,就要求请求进入的也要慢,否则漏斗满了请求就会被丢弃
1.4.令牌桶算法
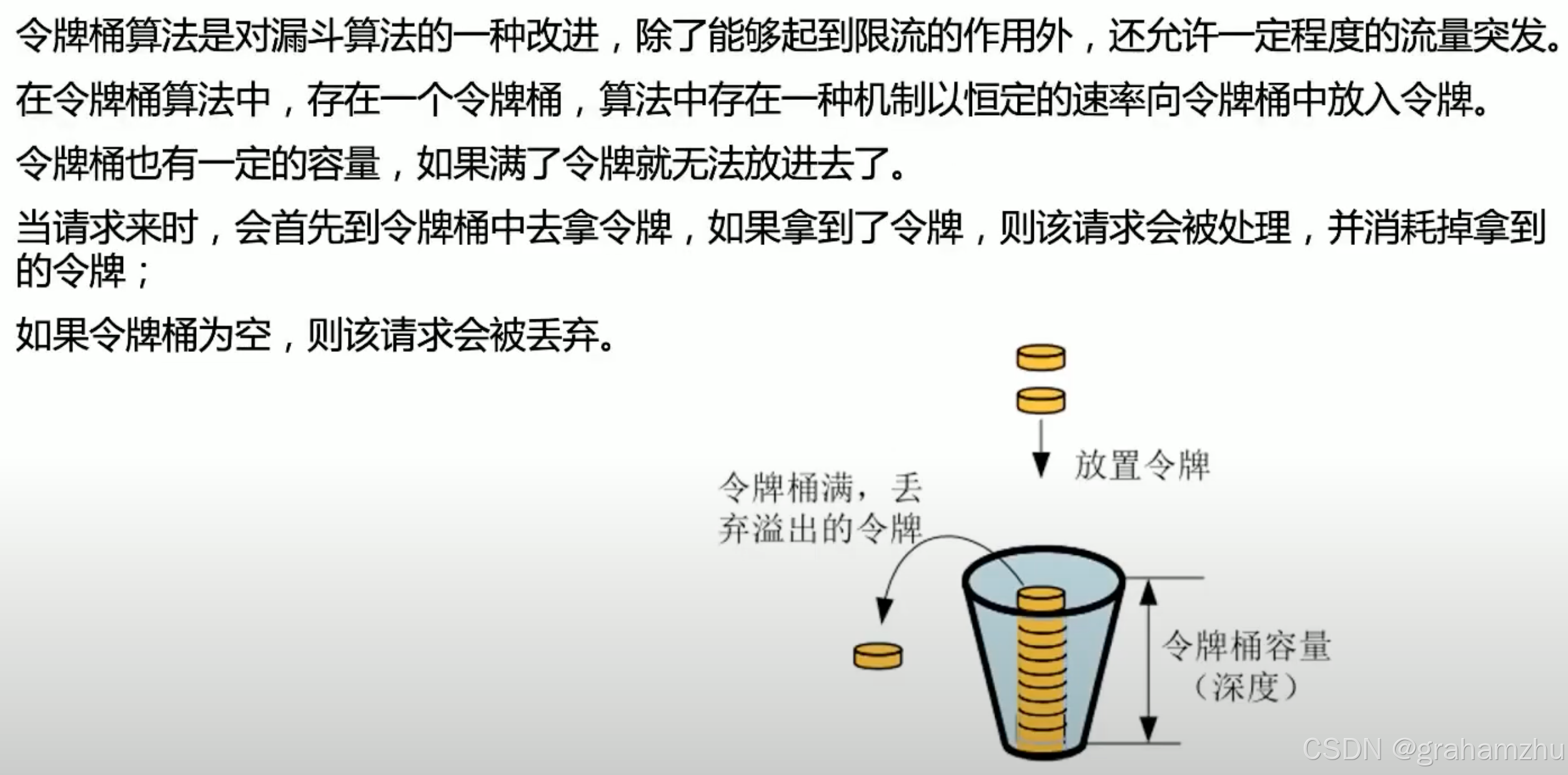
- 与漏斗算法相比,令牌桶算法不限制请求出桶的速率,而是限制请求进桶的速率
- 如果请求来了,发现桶里有令牌,则直接可以拿到令牌进入系统
- 如果请求来了,发现桶里没有令牌,则会等待,直到桶里生成令牌 或 请求超时
- 优点:可以应对高峰流量
- 生成令牌的线程会匀速生成令牌,即使当前没有那么多请求,也会不断的生成,直到把桶填满
- 如果突然来了一波高峰流量,桶里就事先生成了大量令牌供请求获取,这些请求都可以被处理
- 如果高峰之后,用户不活跃了,则桶里令牌又开始积累,可以应对下一次高峰
2.APIServer的限流
2.1.APIServer的基础限流参数
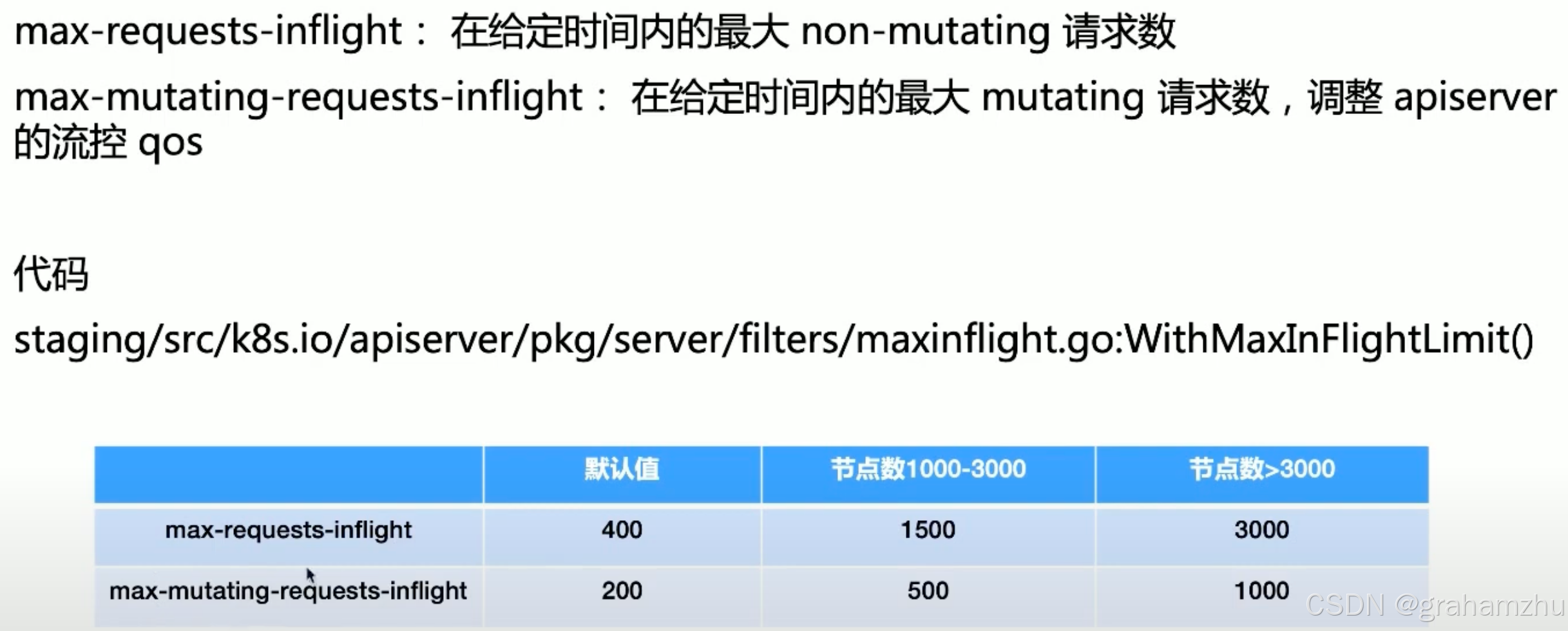
- 并发请求数,即为正在处理尚未结束的请求。因为一个请求的处理要经过认证、鉴权、准入等一系列操作,还是比较耗时的
- 给定时间,并非一个固定时间,而是apiserver能够承受的最大处理请求数量,如果400个请求不结束,那么就一直无法接收新请求
2.1.1.限流参数详解
-
max-requests-inflight- 定义:限制 API Server 非变更类请求(如
GET、LIST、WATCH)的并发处理数量。 - 默认值:400。
- 适用场景:保护查询类请求的稳定性,例如大规模集群中频繁的监控数据拉取或资源列表查询。
- 定义:限制 API Server 非变更类请求(如
-
max-mutating-requests-inflight- 定义:限制 API Server 变更类请求(如
CREATE、UPDATE、DELETE、PATCH)的并发处理数量。 - 默认值:200。
- 适用场景:防止资源修改操作(如 Pod 创建或配置更新)导致 API Server 过载。
- 定义:限制 API Server 变更类请求(如
2.1.2.参数对比
| 维度 | max-requests-inflight | max-mutating-requests-inflight |
|---|---|---|
| 请求类型 | 非变更类(只读) | 变更类(写操作) |
| 资源消耗 | 较低(仅数据读取) | 较高(涉及资源修改和状态同步) |
| 默认配额 | 400 | 200 |
| 优先级 | 通常优先级较低(APF 启用后由 FlowSchema 控制) | 通常优先级较高(如内置 workload-high 优先级) |
- 联系:
- 共同目标:防止 API Server 因突发流量过载,保障集群稳定性。
- 总和限制:当启用 APF(API 优先级和公平性)时,两者之和决定 API Server 的总并发处理能力(如
400+200=600)。
2.1.3.实现原理
- 计数器机制
- 每个参数维护一个独立的 并发请求计数器,请求处理前递增,完成后递减。
- 若计数器超过阈值,新请求会被拒绝(返回 HTTP 429 状态码)。
- 请求分类逻辑
- 非变更类请求:通过 HTTP 方法(如
GET)或 Kubernetes 资源操作(如list)识别。 - 变更类请求:通过 HTTP 方法(如
POST)或资源操作(如create)识别。
- APF 整合(Kubernetes 1.18+)
- 当启用
--enable-priority-and-fairness=true(默认开启),APF 接管限流逻辑:- 总并发数 =
max-requests-inflight + max-mutating-requests-inflight。 - 请求通过
FlowSchema分类并分配至PriorityLevelConfiguration队列,按优先级处理。
- 总并发数 =
2.1.4.配置与优化
1.参数设置方法
- 启动参数配置:
kube-apiserver \ --max-requests-inflight=1000 \ --max-mutating-requests-inflight=500 - 高可用集群建议:
- 三节点集群总并发数建议 3000(单节点 1000)。
- 大规模集群(如 5000 节点)总并发数可提升至 5000。
2.监控与调优
- 关键指标:
apiserver_current_inflight_requests:当前并发请求数。apiserver_request_duration_seconds:请求延迟分布。
- 调优策略:
- 逐步增加并发数,观察 API Server 内存和 CPU 使用率。
- 结合 APF 配置优先级,优先保障核心组件(如
kube-controller-manager)的请求。
2.1.5.基础限流参数的局限性

- 如果一个用户对apiserver操作不规范,可能会影响到整个系统。比如一个应用没有使用长连接watch,而是在不停的 list pods,就有可能把apiserver打挂
- 重要请求如node心跳、controller-leaderselection等,都不应该被限流
2.2.APF(API Priority and Fairness)
其实和 linux kernel 的网络保持思想是一致的,好的设计是到处应用的
2.2.1.APF是什么

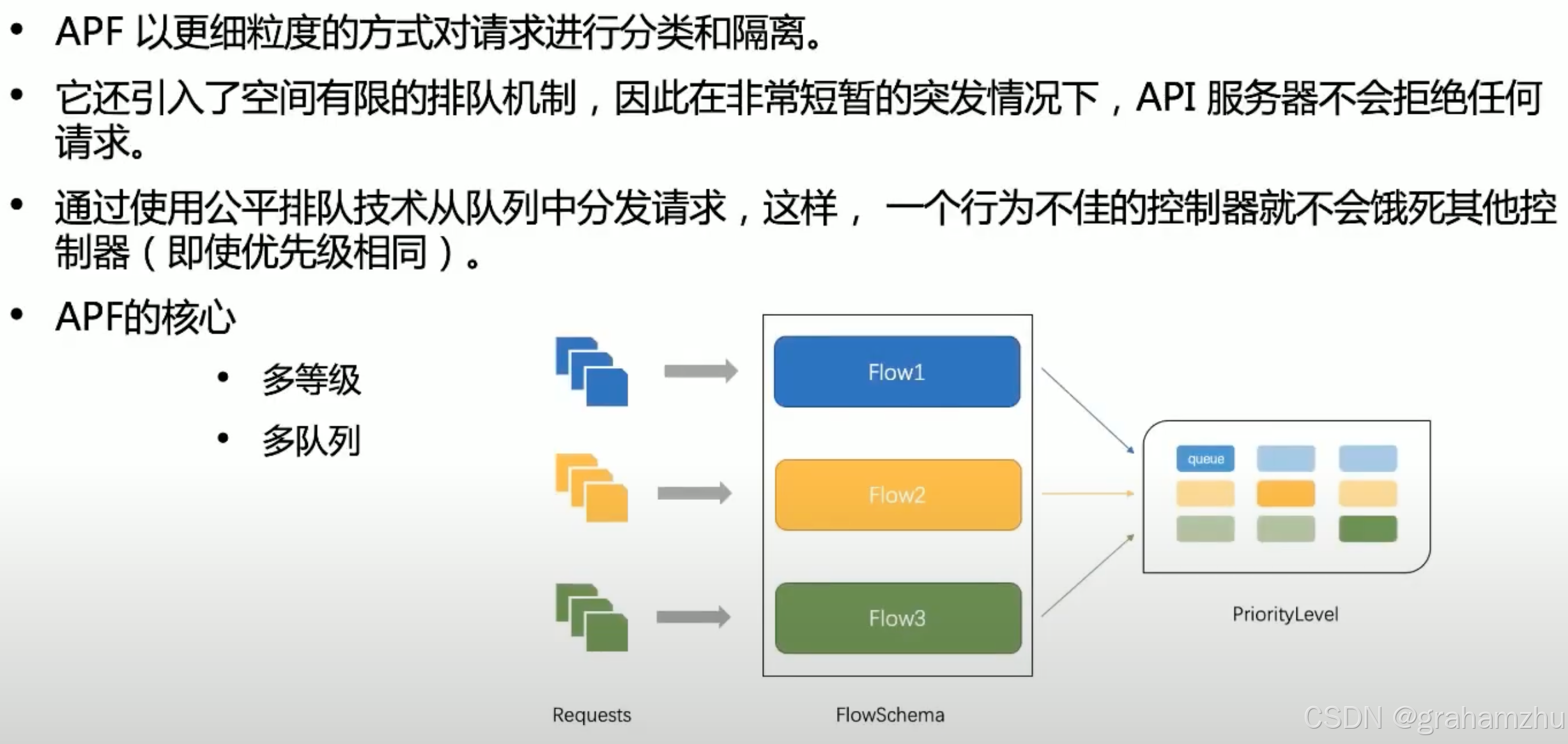
- 总的来说,APF是一种 兼顾优先级和公平性 的限流解决方案
- 支持版本:kubernetes 1.18引入,1.20默认开启
2.2.2.APF的具体实现

- APF机制中,有两种资源非常重要:FlowSchema、PriorityLevelConfiguration
- FlowSchema(FS):定义 请求流模板,一个FS会绑定一个唯一的PL,所以只要一个请求被判定为属于这个FS,那么这个请求的PL优先级也就确定了
- PriorityLevelConfiguration(PLC):定义 优先级 的配置,声明一个优先级PL的具体行为配置。一个PL可以被多个FS绑定
- 因此 FS --> PL 是 多对1 的关系
- APF 几个规则
- 一个FlowSchema对应一个优先级PL,一个PL包含多个queue队列
- 一个FlowSchema可以把请求划分为 不同的Flow,每个Flow又可以映射到不同的queue
- 一个具体的请求如何处理?
- 一个具体请求,在FlowSchema列表中,从优先级从高到低进行rules匹配,找到第一个匹配上的FlowSchema
- 然后FlowSchema会通过绑定的PL确定请求的优先级,并通过
distinguisherMethod.type的值,将请求划分到具体的Flow中 - 一个PL优先级会对应一个QueueSet(包含好多个队列),不同Flow会通过shuffle sharding算法 映射到不同的queue,就实现了 用户级别/ns级别 的请求隔离。
- 因为不同 用户/ns 的请求,都没有放在同一个queue
- 如此一个请求就被放入了一个queue,等待执行
- 执行的时候,该PL的执行器会通过 fair公平性算法 从QueueSet中选出一个queue,并挑选queue中最老的请求进行执行
- 由于不同Flow对应不同的queue,所以不同Flow请求被执行到的概率也是公平的,不会出现一个Flow一直执行,其他Flow饿死的情况

- 由于不同Flow对应不同的queue,所以不同Flow请求被执行到的概率也是公平的,不会出现一个Flow一直执行,其他Flow饿死的情况
2.2.3.FlowSchema结构
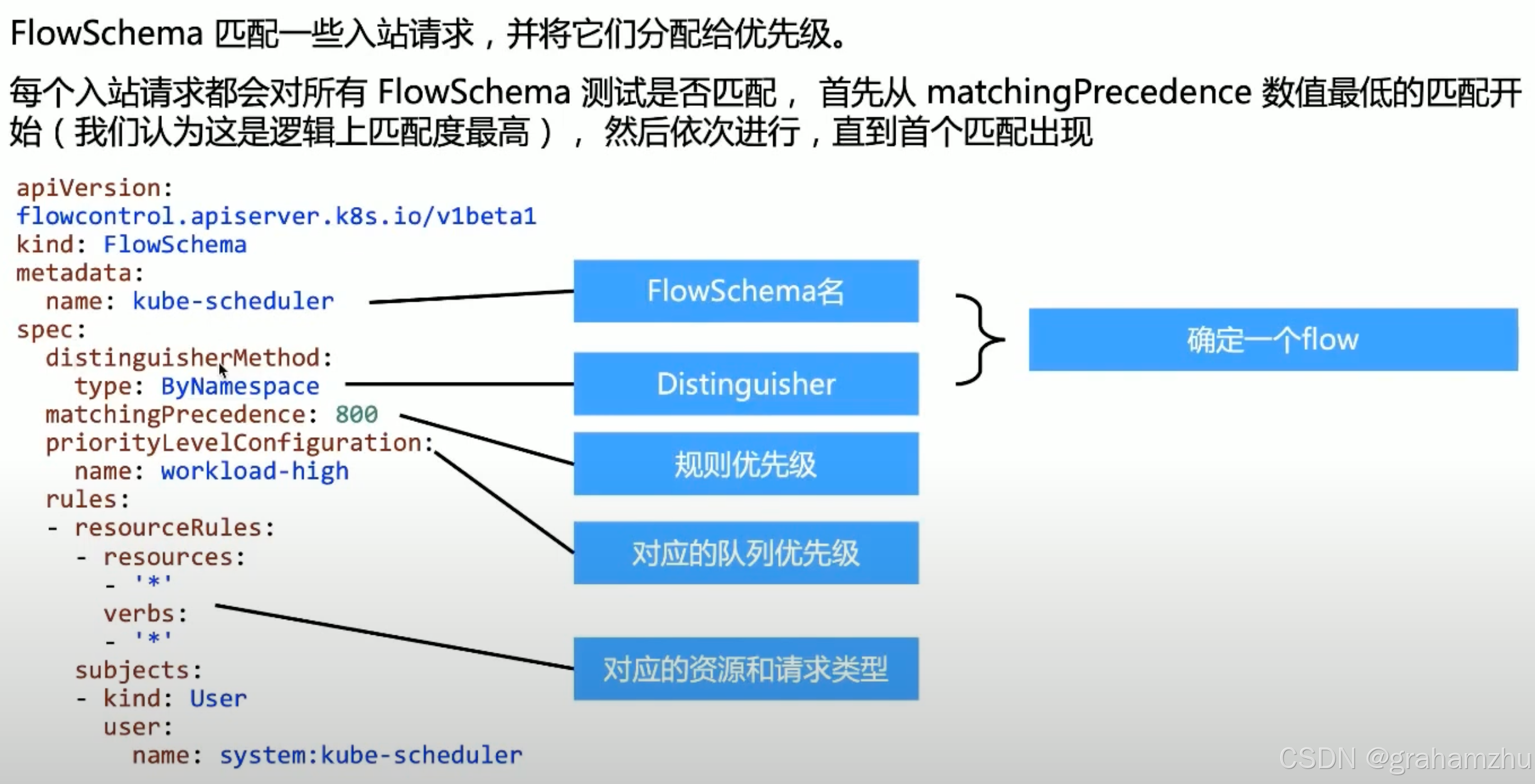
- FlowSchema 的 matchingPrecedence数值表示规则的优先级,取值范围:1-10000。值越小,优先级越高。比如:
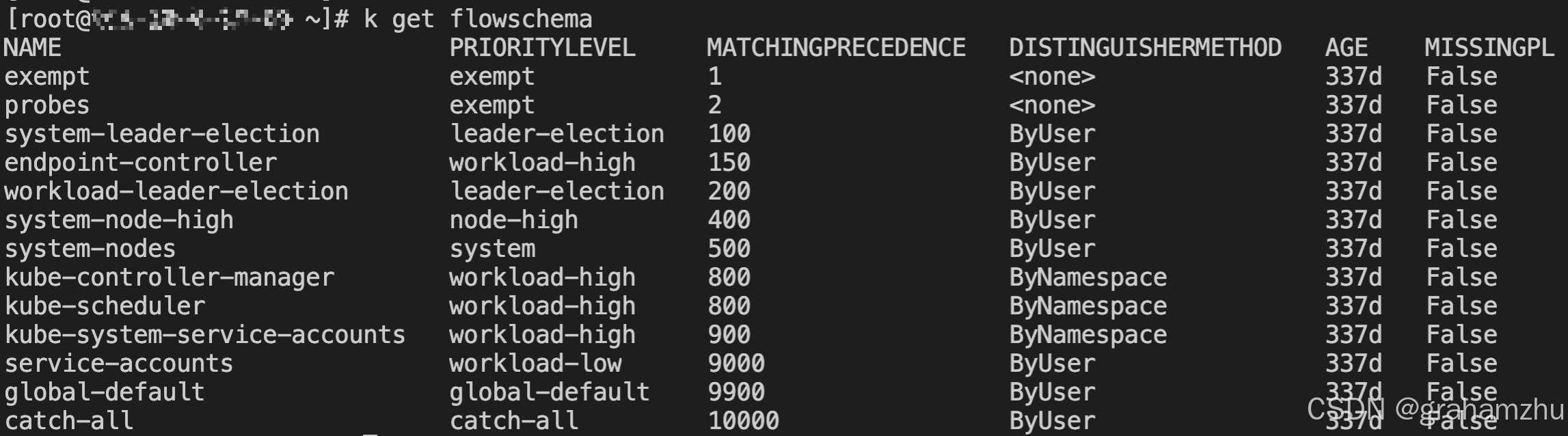
- exempt:豁免,该flowschema的请求不作限流,所有请求都会被执行
- catch-all:如果上面的FlowSchema 都没有被匹配到,就会放入这个flowschema
2.2.4.PriorityLevelConfiguration结构
- 从上面描述可知,一个PL对应一个QueueSet,包含好多个queue,那么queue的具体数量、具体配置在哪里配置?
- 就是对应的PriorityLevelConfiguration

- 就是对应的PriorityLevelConfiguration
- assuredConcurrencyShares:定义当前优先级PL所允许的最大并发请求数量
- 对不同优先级配置不同的 并发量,可以保证高优先级一定能执行,低优先级尽量执行
- queuing.queues:表示当前PL下队列总数
- queuing.queueLengthLimit:队列长度
- queuing.handSize:表示一个flow会占用多少个队列,是shuffle sharding的取模数量
2.2.5.其他设计点
2.2.5.1.基础限流参数 与 APF 的关系

- 当启用
--enable-priority-and-fairness=true(默认开启),APF 接管限流逻辑:- apiserver总并发数 =
max-requests-inflight + max-mutating-requests-inflight。 - 总并发数通过
FlowSchema分类并分配至PriorityLevelConfiguration队列,按优先级处理。每个优先级就具备了自己的并发限制。可以保证高优先级一定能执行,低优先级尽量执行
- apiserver总并发数 =
2.2.5.2.同一PL下的排队算法

2.2.5.3.豁免请求

- 系统内置的一些flowschema
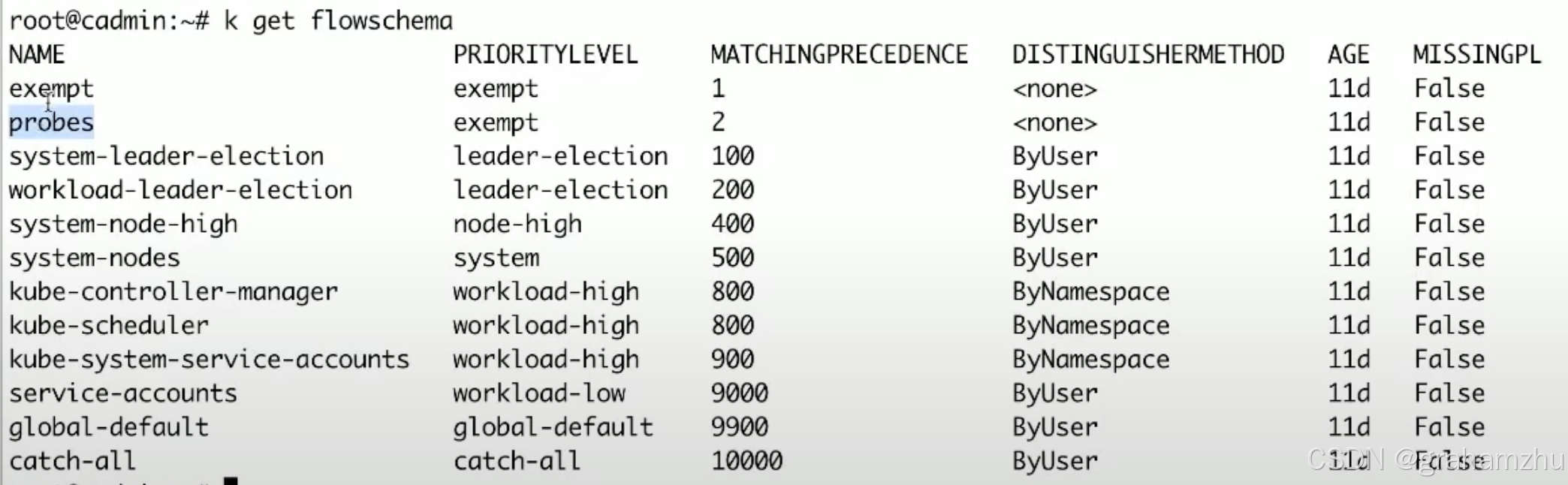
- 其中 exempt、健康检查probes的两个flowschema,都对应 exempt豁免PL,即都会被豁免
- 可以看到,来自 system:masters 用户组下的所有请求,或url为
/healthz、/readyz、/livez都会被豁免,不会被限流
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "true"
creationTimestamp: "2024-05-11T05:25:46Z"
generation: 1
name: exempt
resourceVersion: "75"
uid: 3366d878-6d31-4cb8-9570-44b072839d49
spec:
matchingPrecedence: 1
priorityLevelConfiguration:
name: exempt
rules:
- nonResourceRules:
- nonResourceURLs:
- '*'
verbs:
- '*'
resourceRules:
- apiGroups:
- '*'
clusterScope: true
namespaces:
- '*'
resources:
- '*'
verbs:
- '*'
subjects:
- group:
name: system:masters
kind: Group
status:
conditions:
- lastTransitionTime: "2024-05-11T05:25:46Z"
message: This FlowSchema references the PriorityLevelConfiguration object named
"exempt" and it exists
reason: Found
status: "False"
type: Dangling
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "true"
creationTimestamp: "2024-05-11T05:25:46Z"
generation: 1
name: probes
resourceVersion: "69"
uid: 6a73e8ae-4190-443d-92d0-58bc1e2dd691
spec:
matchingPrecedence: 2
priorityLevelConfiguration:
name: exempt
rules:
- nonResourceRules:
- nonResourceURLs:
- /healthz
- /readyz
- /livez
verbs:
- get
subjects:
- group:
name: system:unauthenticated
kind: Group
- group:
name: system:authenticated
kind: Group
status:
conditions:
- lastTransitionTime: "2024-05-11T05:25:46Z"
message: This FlowSchema references the PriorityLevelConfiguration object named
"exempt" and it exists
reason: Found
status: "False"
type: Dangling
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "true"
creationTimestamp: "2024-05-11T05:25:46Z"
generation: 1
name: exempt
resourceVersion: "64"
uid: 91deb647-6513-45f4-8c2b-a5d218cda4ac
spec:
type: Exempt
status: {}
2.2.6.APF的调试手段

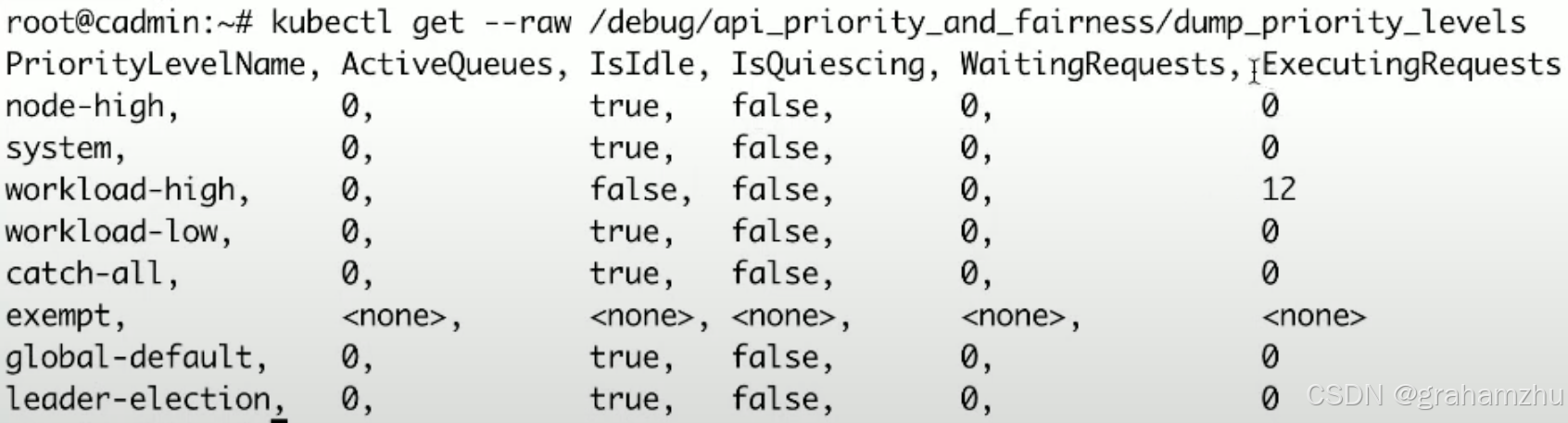
- kubernetes提供了一些调试的uri,供我们查看当前系统的一些状态
- 比如
k get --raw /debug/api_priority_and_fairness/dump_priority_levels
- 比如






![Muduo网络库实现 [十六] - HttpServer模块](https://i-blog.csdnimg.cn/direct/d8b7e8379221498495f5f5532357b30a.png)