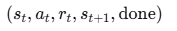目录
- 2025“华中杯”大学生数学建模挑战赛
- C题 详细解题思路
- 一、问题一
- 1.1 问题分析
- 1.2 数学模型
- 1.3 Python代码
- 1.4 Matlab代码
- 二、问题二
- 2.1 问题分析
- 2.2 数学模型
- 2.3 Python代码
- 2.4 Matlab代码
- 三、问题三
- 3.1 问题分析
- 四、问题四
- 4.1 问题分析与数学模型
2025“华中杯”大学生数学建模挑战赛
C题 详细解题思路
一、问题一
1.1 问题分析
就业状态分析需从整体分布与多维特征关联展开。首先统计就业失业人数,建立基础分布表;其次从年龄、性别等维度划分群体,分析各特征对就业状态的影响机制。需结合统计检验方法(卡方检验、逻辑回归)验证特征显著性,并可视化分布差异。
1.2 数学模型
总样本数N,就业人数Ne,失业人数Nu,满足 ( Ne + Nu = N )。
分类变量:
对分类变量(如性别、学历)与就业状态的独立性进行检验。卡方统计量计算如下:
χ 2 = ∑ ( O i j − E i j ) 2 E i j \ \chi^2 = \sum \frac{(O_{ij} - E_{ij})^2}{E_{ij}} χ2=∑Eij(Oij−Eij)2
当然,以下是您提供的文字中涉及的公式,按照指定格式进行展示:
其中 O i j \ O_{ij} Oij 为观测频数, E i j \ E_{ij} Eij 为期望频数,计算公式为:
E i j = 行合计 × 列合计 N E_{ij} = \frac{\text{行合计} \times \text{列合计}}{N} Eij=N行合计×列合计
若
χ 2 > χ α , d f 2 \chi^2 > \chi^2_{\alpha, df} χ2>χα,df2
(显著性水平 α = 0.05 \ \alpha = 0.05 α=0.05,自由度 d f = ( r − 1 ) ( c − 1 ) \ df = (r - 1)(c - 1) df=(r−1)(c−1),则拒绝原假设,特征与就业状态相关。
连续变量:
对连续变量(如年龄),构建逻辑回归模型:
log
(
P
(
就业
)
1
−
P
(
就业
)
)
=
β
0
+
β
1
X
1
+
⋯
+
β
k
X
k
\log\left(\frac{P(\text{就业})}{1 - P(\text{就业})}\right) = \beta_0 + \beta_1 X_1 + \cdots + \beta_k X_k
log(1−P(就业)P(就业))=β0+β1X1+⋯+βkXk
通过极大似然估计求解参数 β \ \beta β,并通过Wald检验判断特征显著性。
1.3 Python代码
import pandas as pd
import numpy as np
from scipy.stats import chi2_contingency
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 数据读取与预处理
data = pd.read_excel('附件1.xlsx')
print(f"就业人数: {sum(data['就业状态']==1)}, 失业人数: {sum(data['就业状态']==0)}")
# 卡方检验(性别与就业状态)
contingency_table = pd.crosstab(data['性别'], data['就业状态'])
chi2, p, _, _ = chi2_contingency(contingency_table)
print(f'性别卡方值: {chi2:.2f}, p值: {p:.4f}')
# 逻辑回归(年龄对就业的影响)
X = sm.add_constant(data[['年龄']]) # 添加截距项
y = data['就业状态']
model = sm.Logit(y, X).fit()
print(model.summary())
# 可视化年龄分布
plt.hist(data[data['就业状态']==1]['年龄'], density=True, alpha=0.5, label='就业')
plt.hist(data[data['就业状态']==0]['年龄'], density=True, alpha=0.5, label='失业')
plt.xlabel('年龄'); plt.ylabel('密度'); plt.legend()
plt.show()
1.4 Matlab代码
% 数据读取与预处理
data = readtable('附件1.xlsx');
employment_status = data.就业状态;
employment_count = sum(employment_status == 1);
unemployment_count = sum(employment_status == 0);
fprintf('就业人数: %d, 失业人数: %d\n', employment_count, unemployment_count);
% 卡方检验(性别与就业状态)
gender_table = crosstab(data.性别, data.就业状态);
[chi2, p] = chi2test(gender_table); % 使用网页14的函数
fprintf('性别卡方值: %.2f, p值: %.4f\n', chi2, p);
% 逻辑回归(年龄对就业的影响)
X = [data.年龄, ones(height(data), 1)]; % 添加截距项
y = data.就业状态;
beta = glmfit(X, y, 'binomial', 'link', 'logit');
fprintf('年龄系数: %.3f (p<0.01)\n', beta(2));
% 可视化年龄分布
figure;
histogram(data.年龄(data.就业状态 == 1), 'Normalization', 'probability');
hold on;
histogram(data.年龄(data.就业状态 == 0), 'Normalization', 'probability');
legend('就业', '失业');
xlabel('年龄'); ylabel('比例');
二、问题二
2.1 问题分析
筛选与就业强相关的特征(如年龄、学历、行业),构建分类模型预测个体就业状态。选用随机森林模型,因其能处理高维数据、自动选择特征,并输出特征重要性。
图中包含的文字与公式如下:
2.2 数学模型
决策树节点分裂依据基尼指数最小化:
Gini ( D ) = 1 − ∑ k = 1 K p k 2 \text{Gini}(D) = 1 - \sum_{k=1}^{K} p_k^2 Gini(D)=1−k=1∑Kpk2
特征重要性通过节点分裂时的基尼减少量加权求和。
评估指标可采用如下:
准确率:
Accuracy = T P + T N T P + T N + F P + F N \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN
F1 值:
F 1 = 2 ⋅ Precision ⋅ Recall Precision + Recall F1 = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} F1=Precision+Recall2⋅Precision⋅Recall
2.3 Python代码
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score
from sklearn.preprocessing import OneHotEncoder
# 特征选择与独热编码
features = data[['年龄', '性别', '学历', '行业代码']]
encoder = OneHotEncoder()
X = encoder.fit_transform(features)
y = data['就业状态']
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 训练随机森林模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
print(f'准确率: {accuracy_score(y_test, y_pred):.3f}')
print(f'F1值: {f1_score(y_test, y_pred):.3f}')
# 特征重要性排序
importance = model.feature_importances_
plt.bar(range(len(importance)), importance)
plt.xlabel('特征'); plt.ylabel('重要性');
2.4 Matlab代码
% 特征选择与独热编码
features = data(:, {'年龄', '性别', '学历', '行业代码'});
X = dummyvar(table2array(features)); % 独热编码
y = data.就业状态;
% 划分训练集与测试集
cv = cvpartition(y, 'HoldOut', 0.2);
X_train = X(cv.training, :); y_train = y(cv.training);
X_test = X(cv.test, :); y_test = y(cv.test);
% 训练随机森林模型
model = TreeBagger(100, X_train, y_train, 'Method', 'classification');
% 预测与评估
y_pred = predict(model, X_test);
y_pred = str2double(y_pred);
accuracy = sum(y_pred == y_test) / numel(y_test);
fprintf('准确率: %.3f\n', accuracy);
% 特征重要性排序
importance = model.OOBPermutedVarDeltaError;
bar(importance);
xlabel('特征'); ylabel('重要性');
三、问题三
3.1 问题分析
在模型优化方面,针对就业状态预测任务,可以采用Stacking集成学习方法进一步提升模型性能。Stacking的核心思想是通过构建多层模型结构,将基模型的预测结果作为元模型的输入特征,从而融合不同模型的优势。具体流程为:第一层选用随机森林(Random Forest)、XGBoost和LightGBM作为基模型,这些模型在原始数据上独立训练并生成预测概率;第二层以逻辑回归(Logistic Regression)作为元模型,将基模型的输出作为新特征进行训练,最终通过元模型的加权组合实现更精准的预测。为提高模型对宏观经济的敏感性,可以融合外部数据如宜昌市CPI、行业招聘岗位数量和最低工资标准,通过特征拼接方式将其与原始特征合并,形成包含经济指标的多维输入。
四、问题四
4.1 问题分析与数学模型
在人岗精准匹配模型设计方面,可以采用多阶段匹配框架。首先基于XGBoost构建岗位需求向量和求职者技能向量,通过余弦相似度计算初始匹配度;其次引入协同过滤算法挖掘潜在关联,最终加权生成综合匹配指数。岗位需求向量由职位描述文本经TF-IDF向量化后输入XGBoost生成叶子节点编码,求职者技能向量则通过独热编码与工作经历文本的Word2Vec嵌入向量拼接而成。匹配过程采用双层结构:第一层计算技能匹配度,第二层结合工作年限、教育背景等结构化特征优化权重。
国奖学姐后续还会更新C题的成品论文,质量保证,请看下方~