本文只是做一个简单融合的实验,没有任何新颖,大家看看就行了。
1.数据集
本文所采用的数据集为Fruit-360 果蔬图像数据集,该数据集由 Horea Mureșan 等人整理并发布于 GitHub(项目地址:Horea94/Fruit-Images-Dataset),广泛应用于图像分类和目标识别等计算机视觉任务。该数据集共包含141 类水果和蔬菜图像,总计 94,110 张图像,每张图像的尺寸统一为 100×100 像素,且背景已统一处理为白色背景,以减少背景噪声对模型训练的影响。
数据集中涵盖了大量常见和不常见的果蔬品类,主要包括:
- 苹果(多个品种:如深雪、金苹果、金红、青奶奶、粉红女士、红苹果、红美味等)
- 香蕉(黄色、红色、淑女手指等)
- 葡萄(蓝色、粉红色、白色多个品种)
- 柑橘类(橙子、柠檬、酸橙、葡萄柚、柑橘等)
- 热带水果(芒果、木瓜、红毛丹、百香果、番石榴、荔枝、菠萝、火龙果等)
- 浆果类(蓝莓、覆盆子、草莓、黑加仑、红醋栗、桑葚等)
- 核果类与坚果类(桃子、李子、杏、椰子、榛子、核桃、栗子、山核桃等)
- 蔬菜类(黄瓜、茄子、胡椒、番茄、洋葱、花椰菜、甜菜根、玉米、土豆等)
- 其他类如:仙人掌果实、杨布拉、姜根、格兰纳迪拉、Physalis(灯笼果)、油桃、佩皮诺、罗望子、大头菜等。
在数据划分方面,本研究按照如下比例进行数据集划分:
(1)训练集:70,491 张图像
其中按照 8:2 的比例划分出验证集,得到最终:
训练子集:56,432 张
验证集:14,059 张
(2)测试集:23,619 张图像

2.模型简述
在图像分类任务中,深度学习方法已经取得了显著的进展,如残差神经网络(ResNet),Vision Transformer展现了较强的性能。ResNet作为CNN下的网络架构,在局部特征提取方面具有优势,能够有效地捕捉图像中的空间结构信息。而Vision Transformer作为Transformer的变种,在捕捉全局依赖关系和建模长程依赖性方面的具有更好的优势。
由于CNN的卷积操作本质上能够生成具有空间局部关联性的特征图,实际上可以视为一种变相的patch操作。因此,在将CNN与Transformer相结合时,可以避免传统ViT中对输入图像进行切分patch的操作,只需对图像进行位置编码,从而使得Transformer能够有效处理这些具有空间结构的特征图。这种设计不仅减少了计算开销,还使得整个模型在处理图像时更具效率与准确性。
同时,与原始ViT框架中描述的技术不同,原始框架通常会将一个可学习的位置嵌入向量预先添加到编码后的patch序列中,作为图像的位置信息进行表示。然而,为了简化模型的实现并提高计算效率,本文在架构设计上有所调整,省略了额外的位置编码步骤。具体来说,本文的模型通过直接输入编码后的patch序列到Transformer块中,跳过了对每个patch进行独立位置编码的操作。
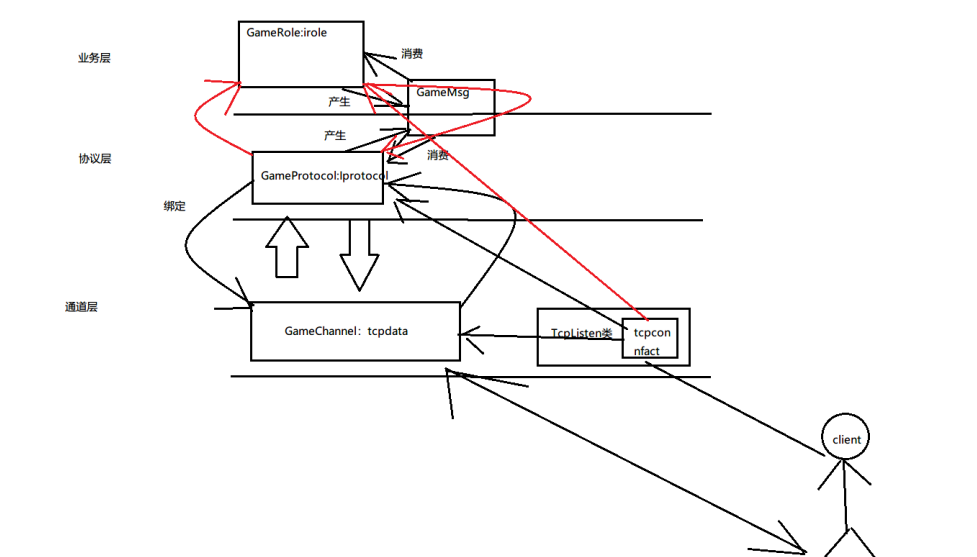
基于这一思路,结合了残差神经网络(ResNet)和Vision Transformer(ViT)两种网络架构,将它们以串行连接的方式进行融合。具体模型架构图如下图所示
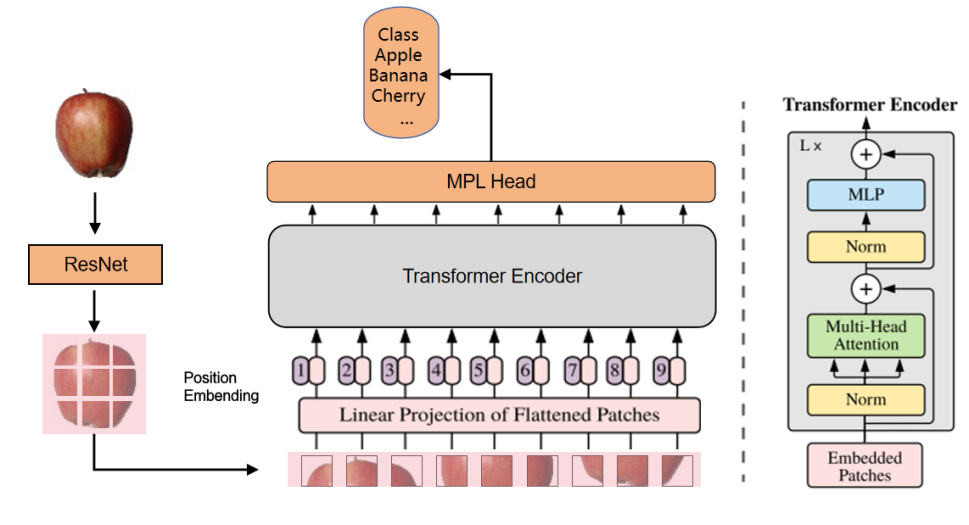
3.实验
模型代码(基于tensorflow2.X)
import glob
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers,models
import warnings
warnings.filterwarnings('ignore')
import os
Train = r"D:\archive (1)\fruits-360_dataset_100x100\fruits-360\Training"
Test = r"D:\archive (1)\fruits-360_dataset_100x100\fruits-360\Test"
IMAGE_SIZE = 100
NUM_CLASSES = 141
BATCH_SIZE = 32
imagegenerator = ImageDataGenerator(rescale=1.0 / 255.0, validation_split=0.2, rotation_range=10, horizontal_flip=True)
# Training and validation data generators
Train_Data = imagegenerator.flow_from_directory(
Train,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
subset='training'
)
Validation_Data = imagegenerator.flow_from_directory(
Train,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
subset='validation'
)
# Test data generator (no augmentation)
test_imagegenerator = ImageDataGenerator(rescale=1.0 / 255.0)
Test_Data = test_imagegenerator.flow_from_directory(
Test,
target_size=(IMAGE_SIZE,IMAGE_SIZE),
batch_size=BATCH_SIZE,
class_mode='categorical',
# subset='test'
)
class ResidualBlock(layers.Layer):
def __init__(self, filters, kernel_size=(3, 3), strides=1):
super(ResidualBlock, self).__init__()
self.conv1 = layers.Conv2D(filters, kernel_size, strides=strides, padding="same", activation='relu')
self.conv2 = layers.Conv2D(filters, kernel_size, strides=1, padding='same', activation='relu')
self.shortcut = layers.Conv2D(filters, (1, 1), strides=strides, padding='same', activation='relu')
self.bn1 = layers.BatchNormalization()
self.bn2 = layers.BatchNormalization()
self.relu = layers.ReLU()
def call(self, inputs):
x = self.conv1(inputs)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
shortcut = self.shortcut(inputs)
x = layers.add([x, shortcut])
x = self.relu(x)
return x
# ResNet Model definition
class ResNetModel(layers.Layer):
def __init__(self):
super(ResNetModel, self).__init__()
self.conv1 = layers.Conv2D(32, (5, 5), activation='relu', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3),padding='same')
self.maxpool1 = layers.MaxPooling2D((2, 2))
# Residual Blocks
self.resblock1 = ResidualBlock(32,strides=1)
self.resblock2 = ResidualBlock(64,strides=2)
self.resblock3 = ResidualBlock(128,strides=2)
self.resblock4 = ResidualBlock(256, strides=2)
# self.global_avg_pool = layers.GlobalAveragePooling2D()
def call(self, inputs):
print(inputs.shape)
x = self.conv1(inputs)
print(x.shape)
x = self.maxpool1(x)
print(x.shape)
# Apply Residual Blocks
x = self.resblock1(x)
print(x.shape)
x = self.resblock2(x)
print(x.shape)
# x = self.resblock3(x)
# print(x.shape)
# x = self.resblock4(x)
# x = self.global_avg_pool(x)
# print(x.shape)
return x
class TransformerEncoder(layers.Layer):
def __init__(self, num_heads=8, key_dim=64, ff_dim=256, dropout_rate=0.1):
super(TransformerEncoder, self).__init__()
self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=key_dim)
self.dropout1 = layers.Dropout(dropout_rate)
self.norm1 = layers.LayerNormalization()
self.ff = layers.Dense(ff_dim, activation='relu')
self.ff_output = layers.Dense(key_dim*num_heads)
self.dropout2 = layers.Dropout(dropout_rate)
self.norm2 = layers.LayerNormalization()
def call(self, x):
# Multi-head self-attention
attention_output = self.attention(x, x)
attention_output = self.dropout1(attention_output)
x = self.norm1(attention_output + x) # Residual connection
# Feed Forward Network
ff_output = self.ff(x)
ff_output = self.ff_output(ff_output)
ff_output = self.dropout2(ff_output)
x = self.norm2(ff_output + x) # Residual connection
return x
# Vision Transformer (ViT) 模型
class VisionTransformer(models.Model):
def __init__(self, input_shape=(100, 100, 3), num_classes=141, num_encoders=3, patch_size=8, num_heads=16,
key_dim=4, ff_dim=256, dropout_rate=0.2):
super(VisionTransformer, self).__init__()
self.patch_size = patch_size
#Resnet
self.resnet=ResNetModel()
# Patch Embedding
self.conv = layers.Conv2D(64, (patch_size, patch_size), strides=(patch_size, patch_size), padding='valid')
self.reshape = layers.Reshape((-1, 64))
self.norm = layers.LayerNormalization()
# 位置编码层
self.position_encoding = self.add_weight("position_encoding", shape=(1, 625, 64))
# Stack multiple Transformer Encoder layers
self.encoders = [
TransformerEncoder(num_heads=num_heads, key_dim=key_dim, ff_dim=ff_dim, dropout_rate=dropout_rate) for _ in
range(num_encoders)]
# Global Average Pooling
self.global_avg_pooling = layers.GlobalAveragePooling1D()
# Fully connected layer
self.fc1 = layers.Dense(256, activation='relu')
self.dropout = layers.Dropout(0.2)
self.fc2 = layers.Dense(num_classes, activation='softmax')
def call(self, inputs):
#resnet
x = self.resnet(inputs)
# print("===========================")
# print(x.shape)
# Patch Embedding
x = self.reshape(x)
# 添加位置编码
x = x + self.position_encoding # 将位置编码加到Patch嵌入向量中
# print(x.shape)
# x = self.norm(x)
# Apply multiple Transformer encoders
for encoder in self.encoders:
x = encoder(x)
# Global Average Pooling
x = self.global_avg_pooling(x)
# Fully connected layers
x = self.fc1(x)
x = self.dropout(x)
x = self.fc2(x)
return x
# 构建 Vision Transformer 模型
vit_model = VisionTransformer(input_shape=(100, 100, 3), num_classes=141, num_encoders=3)
vit_model.build(input_shape=(None, IMAGE_SIZE, IMAGE_SIZE, 3)) # 手动构建模型
# 打印模型摘要
vit_model.summary()
# 编译模型
vit_model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy']
)
checkpoint_path = "training_checkpoints_1/vit_model_checkpoint_epoch_{epoch:02d}.h5"
# 创建ModelCheckpoint回调
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
checkpoint_path,
monitor='val_accuracy', # 你可以选择监控验证集的损失或准确度
save_best_only=True, # 只保存验证集损失最小的模型
save_weights_only=True, # 只保存权重(而不是整个模型)
verbose=1 # 打印日志
)
# 检查是否有保存的模型权重文件
checkpoint_dir = "training_checkpoints_1/"
# 查找所有的 .h5 文件
checkpoint_files = glob.glob(os.path.join(checkpoint_dir, "vit_model_checkpoint_epoch_*.h5"))
# print(latest_checkpoint)
if checkpoint_files:
# 使用 os.path.getctime() 获取文件创建时间(或者使用 getmtime() 获取修改时间)
latest_checkpoint = max(checkpoint_files, key=os.path.getctime)
print(f"Loading model from checkpoint: {latest_checkpoint}")
# 加载模型权重
vit_model.load_weights(latest_checkpoint)
else:
print("No checkpoint found, starting from scratch.")
# 训练模型
history = vit_model.fit(
Train_Data,
epochs=20,
validation_data=Validation_Data,
shuffle=True,
callbacks=[checkpoint_callback]
)
# 评估模型
test_loss, test_acc = vit_model.evaluate(Test_Data)
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_acc}")
# 训练和验证的准确率和损失历史记录
def plot_training_history(history):
# 创建子图
plt.figure(figsize=(14, 6))
# 准备训练准确率和验证准确率的图
plt.subplot(1, 2, 1)
plt.title('Accuracy History')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.plot(history.history['accuracy'], label='Training Accuracy', marker='o')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy', color='green', marker='o')
plt.legend()
# 准备训练损失和验证损失的图
plt.subplot(1, 2, 2)
plt.title('Loss History')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.plot(history.history['loss'], label='Training Loss', marker='o')
plt.plot(history.history['val_loss'], label='Validation Loss', color='green', marker='o')
plt.legend()
# 显示图形
plt.tight_layout()
plt.show()
# 绘制训练过程
plot_training_history(history)
for i in range(16):
# 获取测试数据的下一个批次
img_batch, labels_batch = Test_Data.next()
img = img_batch[0] # 获取当前批次的第一张图像
true_label_idx = np.argmax(labels_batch[0]) # 获取真实标签的索引
# 获取真实标签的名称
true_label = [key for key, value in Train_Data.class_indices.items() if value == true_label_idx]
# 扩展维度以匹配模型输入
EachImage = np.expand_dims(img, axis=0)
# 进行预测
prediction = vit_model.predict(EachImage)
# 获取预测标签
predicted_label = [key for key, value in Train_Data.class_indices.items() if
value == np.argmax(prediction, axis=1)[0]]
# 获取预测的概率
predicted_prob = np.max(prediction, axis=1)[0]
# 绘制图像
plt.subplot(4, 4, i + 1)
plt.imshow(img)
plt.title(f"True: {true_label[0]} \nPred: {predicted_label[0]} \nProb: {predicted_prob:.2f}")
plt.axis('off')
plt.tight_layout()
plt.show()做了如下参数实验
| ResNet层数 | Encoder层数 | num_heads | test_accuracy |
| 2(32,64) | 3 | 4 | 92.14% |
| 3(32,64,128) | 3 | 4 | 94.53% |
| 2(32,64) | 3 | 8 | 96.19% |
| 3(32,64,128) | 3 | 8 | 97.46% |
| 2(32,64) | 3 | 16 | 93.32% |
| 3(32,64,128) | 3 | 16 | 93.17% |
分类效果图