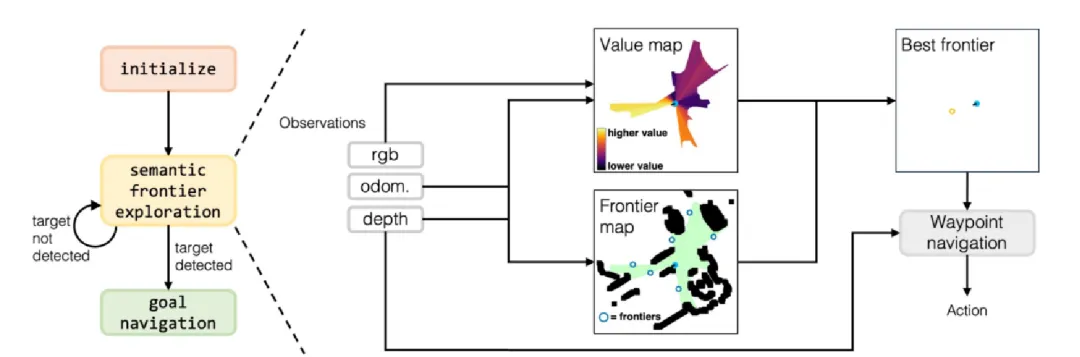
目标
- 了解规范化层的作用
- 掌握规范化层的实现过程
作用
所有的深层网络模型都需要标准网络层, 因为随着网络层数量的增加, 通过多层的计算后参数可能出现过大或者过小的情况, 这样可能导致在学习过程出现异常, 模型可能收敛比较慢,因此都会在一定的层数后接规范化层进行数值的规范化,使其特征数值在合理的范围内
代码实现
import torch.nn as nn
import torch
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
"""初始化函数有两个参数
:param features: 代表词嵌入的维度
:param eps: 他是一个足够小的数, 在规范化公式的分母中出现, 防止分母为0, 默认为1e-6
"""
super(LayerNorm, self).__init__()
# 根据 features的形状初始化两个参数张量a2. b2, 第一个初始化唯1张量, 也就是里面的元素都是1
# 第二个初始化为0张量, 也就是里面的元素都是0, 这两个张量就是规范化的参数
# 因为直接对上一层得到的结果做规范化, 又不能改变对目标的表征, 最后使用 nn.Parameter 封装, 代表他们是参数, 不需要训练
self.a2 = nn.Parameter(torch.ones(features))
self.b2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
"""减均值除方差
:param x: 输入参数x代表来自上一层的输出
"""
# 在函数中, 首先对输入变量x求其最后一个维度的均值(x.mean), 并保持输出维度与输入维度一致(keepdim=True)
# 接着再求最后一个维度的标准差(x.std), 然后就是根据规范化公式, 用x减去均值, 再除以规范化的标准差, 最后再乘以缩放参数a2, 再加上b2
# *代表同刑点乘, 即对应位置进行乘法操作, 加上位移参数
"""
请问规范化层中这段代码"self.a2 * (x - mean) / (std + self.eps) + self.b2", self.a2 为全1的对象乘后面的值不会发生任何值的改变,, 以及最后加上self.b2, 那么在transformer规范化层中这样做的意义是什么?
在Transformer的规范化层中,`self.a2` 和 `self.b2` 的引入确实看似多余,但实际上它们具有重要的意义。以下是具体解释:
1. **`self.a2` 的作用**
- 虽然初始化时 `self.a2` 是全1的对象,但在训练过程中,它是一个可学习的参数。这意味着模型可以通过反向传播调整它的值,从而对规范化后的数据进行缩放(scaling)。
- 这种缩放操作允许模型灵活地控制每个特征的权重,使得规范化后的数据能够更好地适应下游任务的需求。
2. **`self.b2` 的作用**
- 类似地,`self.b2` 初始化为全0的对象,但它也是一个可学习的参数。通过训练,它可以对规范化后的数据进行位移(shifting),从而调整每个特征的偏置。
- 这种位移操作使得模型能够在规范化的基础上进一步微调数据分布,以适应特定任务的需求。
3. **为什么要引入这两个参数?**
- 规范化操作(如 `(x - mean) / (std + self.eps)`)会改变输入数据的分布,使其均值为0,标准差为1。然而,这种分布可能并不总是适合后续的计算或任务需求。
- 通过引入 `self.a2` 和 `self.b2`,模型可以在规范化后重新调整数据的分布,使其更符合任务的需求。这相当于给模型提供了一种灵活性,使其能够更好地学习和表达复杂的模式。
4. **总结**
- 在Transformer中,`LayerNorm` 的设计目的是为了稳定训练过程,减少梯度消失或爆炸的问题。
- `self.a2` 和 `self.b2` 的引入则进一步增强了模型的表达能力,使规范化后的数据分布更加灵活可控。即使在初始化阶段它们看似不起作用,但随着训练的进行,它们会逐渐调整到最优值,从而提升模型性能。
因此,尽管在初始化阶段 `self.a2` 和 `self.b2` 的作用不明显,但它们的存在对于模型的最终表现至关重要。
"""
print("x: ", x)
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# std + self.eps 防止 std标准差为0
print("self.a2: ", self.a2)
print("mean: ", mean)
print("x - mean: ", x - mean)
print("self.a2 * (x - mean): ", self.a2 * (x - mean))
print("std + self.eps: ", std + self.eps)
print("self.a2 * (x - mean) / (std + self.eps): ", self.a2 * (x - mean) / (std + self.eps))
return self.a2 * (x - mean) / (std + self.eps) + self.b2
features = d_model = 3
eps = 1e-6
x = torch.randn(1, 3, 3)
layer = LayerNorm(features, eps)
y = layer(x)
print(y)
print(y.size())
"""output:
tensor([[[-0.0949, -1.4544, 1.4923, ..., -0.8013, 0.8509, -2.2505],
[-2.5870, 0.2960, -2.1403, ..., 0.1612, -1.3862, -1.5998],
[-0.1957, -0.1322, -2.3934, ..., 0.4920, -0.2850, -0.6868],
...,
[-0.6752, 0.5418, -1.5606, ..., -2.1540, -0.4754, 0.1213],
[ 0.3079, 1.2774, -0.9723, ..., -0.3016, -1.5236, -1.1208],
[-0.0062, -0.3422, -0.8661, ..., 0.0146, -0.5056, 0.7262]]],
grad_fn=<AddBackward0>)
torch.Size([1, 512, 512])
"""
nn.Parameter 说明
输入输出类型
- 输入:任意
torch.Tensor(通常是需要训练的权重或偏置)。 - 输出:包装后的
Parameter类型张量(继承自Tensor,但会被自动注册到模型的参数列表中)。
基本作用
- 功能:将张量标记为模型的 可训练参数,优化器(如
Adam)会更新这些参数。 - 用途:定义自定义层的权重(如
nn.Linear中的weight和bias)。
底层原理
nn.Parameter是Tensor的子类,通过requires_grad=True自动启用梯度计算。- 当添加到
nn.Module时,会被自动加入model.parameters()列表。
代码示例
import torch
import torch.nn as nn
class CustomLayer(nn.Module):
def __init__(self):
super().__init__()
# 定义一个可训练参数(标量)
self.weight = nn.Parameter(torch.randn(1))
def forward(self, x):
return x * self.weight # 前向传播时使用参数
model = CustomLayer()
print(list(model.parameters())) # 查看模型参数(包含weight)
torch.Tensor.mean 说明
输入输出类型
- 输入:任意形状的
Tensor,可指定维度dim。 - 输出:沿指定维度求均值后的
Tensor(若dim=None则返回标量)。
基本作用
- 功能:计算张量的 算术平均值,支持沿特定维度操作。
- 用途:数据归一化、损失函数计算(如 MSE 的均值)。
底层原理
- 数学公式:( \text{mean}(x) = \frac{1}{n} \sum_{i=1}^n x_i )
- 底层调用 CUDA 或 CPU 的并行化归约操作(如
thrust::reduce)。
代码示例
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
# 全局均值
print(x.mean()) # tensor(2.5)
# 沿维度0(列方向)求均值
print(x.mean(dim=0)) # tensor([2., 3.])
# 保持维度(输出形状为[1, 2])
print(x.mean(dim=0, keepdim=True)) # tensor([[2., 3.]])
torch.Tensor.std
输入输出类型
- 输入:任意形状的
Tensor,可指定维度dim和是否无偏估计(unbiased)。 - 输出:沿指定维度求标准差后的
Tensor(若dim=None则返回标量)。
基本作用
- 功能:计算张量的 标准差,衡量数据离散程度。
- 用途:数据标准化(如 BatchNorm)、统计分析。
底层原理
-
数学公式(无偏估计):
std ( x ) = 1 n − 1 ∑ i = 1 n ( x i − mean ( x ) ) 2 \text{std}(x) = \sqrt{\frac{1}{n-1} \sum_{i=1}^n (x_i - \text{mean}(x))^2} std(x)=n−11i=1∑n(xi−mean(x))2 -
底层通过两步实现:先计算均值,再计算平方差的均值。
代码示例
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
# 全局标准差(无偏估计)
print(x.std()) # tensor(1.2909944)
# 沿维度1(行方向)求标准差
print(x.std(dim=1)) # tensor([0.7071, 0.7071])
# 有偏估计(分母为n)
print(x.std(dim=1, unbiased=False)) # tensor([0.5, 0.5])
三者的对比总结
| 函数/方法 | 作用 | 常用场景 | 关键参数 |
|---|---|---|---|
nn.Parameter | 定义可训练参数 | 自定义模型层 | 无 |
tensor.mean() | 计算均值 | 损失函数、数据归一化 | dim, keepdim |
tensor.std() | 计算标准差 | BatchNorm、数据标准化 | dim, unbiased |
常见问题
Q:nn.Parameter 和普通 Tensor 的区别?
A:Parameter 会被自动注册到模型参数列表(model.parameters()),普通 Tensor 不会。
Q:unbiased=False 在 std() 中何时使用?
A:当数据是全体样本(非抽样)时用有偏估计(分母为 n),默认无偏估计(分母 n-1)更通用。





![[MySQL] 事务管理(二) 事务的隔离性底层](https://i-blog.csdnimg.cn/direct/9a78a348f89d49c0b289a2caa2e10146.png)