文章目录
- 一、适用题目
- 二、豆瓣图书数据采集
- 1. 图书分类采集
- 2. 爬取不同分类的图书数据
- 3. 各个分类数据整合
- 三、豆瓣图书数据清洗
- 四、数据分析
- 五、数据可视化
- 1. 数据可视化大屏展示
- 源码获取看下方名片
一、适用题目
- 基于Python的豆瓣图书数据采集与分析
- 基于Python的豆瓣图书数据采集与可视化分析
- 基于Python的豆瓣图书数据分析与展示
- 基于Python的豆瓣图书数据分析与可视化实现
- 基于Python的豆瓣图书数据可视化分析
- 基于Selenium和Pandas的豆瓣图书数据采集与分析
- 基于Selenium和Pandas的豆瓣图书数据采集与可视化分析
- 基于Selenium和Pandas的豆瓣图书数据分析与展示
- 基于Selenium和Pandas的豆瓣图书数据分析与可视化实现
- 基于Selenium和Pandas的豆瓣图书数据可视化分析
- 基于Pandas和FineBI的豆瓣图书数据采集与分析
- 基于Pandas和FineBI的豆瓣图书数据采集与可视化分析
- 基于Pandas和FineBI的豆瓣图书数据分析与展示
- 基于Pandas和FineBI的豆瓣图书数据分析与可视化实现
- 基于Pandas和FineBI的豆瓣图书数据可视化分析
二、豆瓣图书数据采集
1. 图书分类采集
首先,设定要访问的网址,即豆瓣读书的标签页面地址,这个页面包含了各类图书的分类标签信息。
然后,设置请求头,其中包含用户代理信息,模拟使用特定版本的浏览器(这里是 Windows 系统下的 Chrome 117.0.0.0)发送请求,以避免被网站识别为异常请求而拒绝访问。
接下来,使用网络请求工具向目标网址发送一个 GET 请求,并设置请求超时时间为 10 秒。请求成功后,获取服务器返回的响应内容,该内容为包含网页信息的文本数据。
获取到网页文本后,利用网页解析工具,以 lxml 解析器对文本进行解析,将其转换为便于处理的结构化数据。
在解析后的网页结构中,通过选择器选中所有包含图书分类标签的链接元素,这些元素位于特定的 CSS 类名(‘.tagCola’)下。
对于每个选中的链接元素,提取其文本内容作为图书分类标签的名称,同时提取其链接地址,并将相对链接地址拼接上豆瓣读书的基础网址,得到完整的绝对链接地址。
将提取到的每个图书分类标签的名称和对应的链接地址,以字典的形式存储,字典的键分别为 ‘name’ 和 ‘href’,值分别为标签名称和链接地址。然后将每个字典添加到一个列表中,形成包含所有图书分类标签信息的列表。
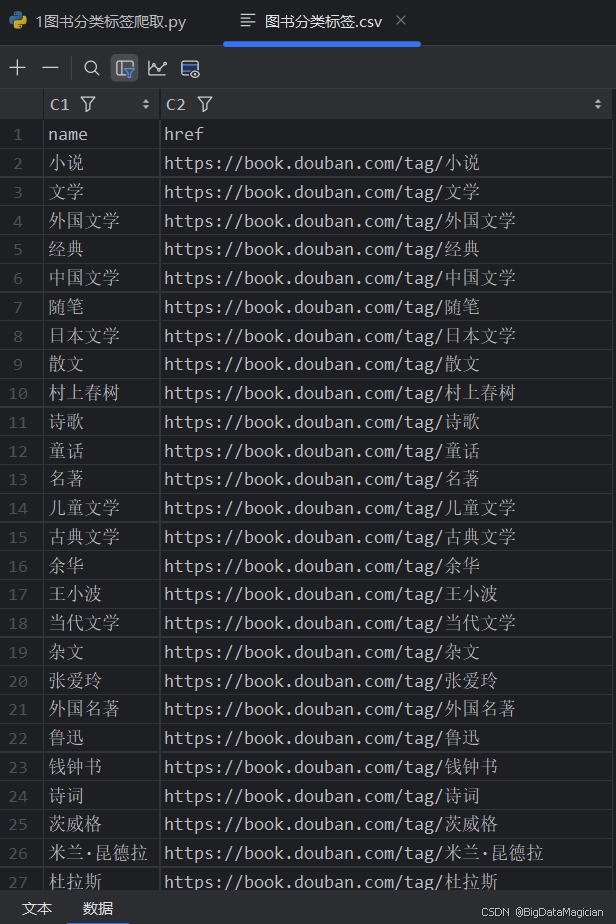
最后,使用数据处理工具,将这个包含图书分类标签信息的列表转换为一个数据表格形式的数据结构。并将这个数据表格保存为一个 CSV 文件,文件名为 “图书分类标签.csv”,存储在 “原始数据层” 文件夹下,保存时不包含索引列,并使用特定的编码格式(utf-8-sig)以确保中文字符的正确保存和读取。
采集后的部分数据如下图所示:
2. 爬取不同分类的图书数据
整个数据采集过程如下:
准备工作
- 读取分类标签:从之前保存的 CSV 文件中读取豆瓣读书的图书分类标签及对应的链接。
- 初始化浏览器:启动 Edge 浏览器,并打开一个示例图书分类页面,等待 60 秒,可能用于手动处理登录或其他验证。
处理每个图书分类
- 检查文件是否存在:对于每个图书分类,检查对应的 CSV 文件是否已经存在。如果存在,则跳过该分类,避免重复采集。
- 遍历分类页面:
- 构建页面 URL:根据分类链接和当前页码,构建要访问的页面 URL。
- 访问页面:使用浏览器访问该 URL,并随机等待 1 - 3 秒,模拟人类浏览行为。
- 检查页面是否有图书条目:如果页面上没有图书条目,则认为该分类的所有页面都已处理完毕,结束该分类的采集。
- 等待图书条目加载:等待页面上的所有图书条目元素加载完成,最多等待 10 - 20 秒。
- 提取图书信息:
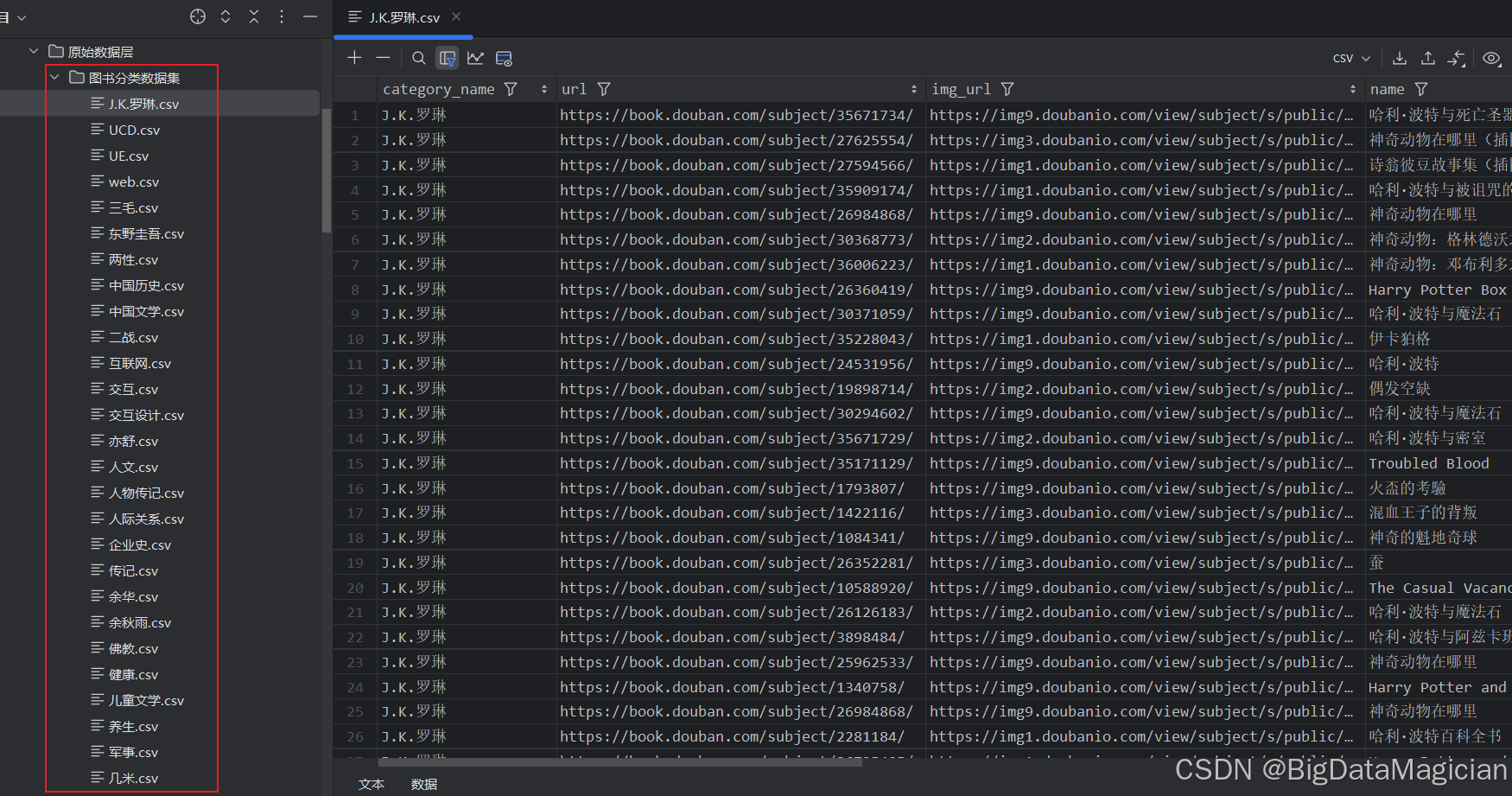
- 遍历图书条目:对于页面上的每个图书条目,提取其相关信息,包括图书链接、封面图片链接、书名、出版信息、评分、评价数量、简介和购买信息。
- 存储图书信息:将提取的图书信息存储在一个字典中,并添加到数据列表中。
- 保存数据:
- 创建 CSV 文件:如果对应的 CSV 文件不存在,则创建该文件并写入表头。
- 追加数据:将当前页面提取的图书信息以 DataFrame 的形式追加到 CSV 文件中。
- 等待一段时间:随机等待 1 - 3 秒,避免对网站造成过大压力。
结束采集
处理完所有图书分类后,关闭浏览器,结束数据采集过程。
爬取后的数据如下图所示:
3. 各个分类数据整合
此过程旨在将指定目录下的多个 CSV 文件合并为一个 CSV 文件。具体步骤如下:
准备工作
- 明确源目录和目标文件路径。源目录是存放待合并 CSV 文件的位置,目标文件是合并后数据要保存的地方。
- 若目标文件所在的输出目录不存在,将其创建出来。
获取 CSV 文件
- 对源目录进行查找,找出其中所有的 CSV 文件。
- 统计找到的 CSV 文件数量并记录。
读取 CSV 文件
- 逐个读取这些 CSV 文件。
- 若文件读取成功,记录读取成功信息;若读取过程中出现错误,记录错误信息。
合并数据
- 将所有成功读取的 CSV 文件对应的数据进行合并。
- 记录合并完成信息。
保存合并后的数据
- 把合并好的数据保存到之前指定的目标文件中。
- 若保存成功,记录保存成功信息;若保存过程中出现错误,记录错误信息。
整合后的部分数据如下图所示:
三、豆瓣图书数据清洗
- 数据读取与查看:从本地CSV文件读取豆瓣图书数据,查看数据的前几行、列名及基本信息,对数据有初步了解。
- 拆分“pub”列:对数据中的“pub”列进行拆分,根据不同的分隔符和格式,将其拆分为“author”(作者)、“translator”(译者)、“publisher”(出版社)、“publish_date”(出版日期)和“price”(价格)这几列。拆分完成后,删除原“pub”列,再将处理后的数据保存到新的CSV文件中。
- 日期列处理:对“publish_date”列进行处理,只保留年份信息。若日期不为空,截取前4位作为年份并转换为整数类型;若年份不是4位数字、无法转换为整数、大于2025或小于1900,则设为“None”。处理完成后,将该列重命名为“publish_year”。
- 价格列处理:从“buy_info”列中提取价格信息,若提取的价格大于2000,则设为2000;若提取失败则设为“None”。处理完成后,删除“buy_info”列。
- 出版社列处理:对“publisher”列进行处理,若列值中包含“年”或“-”,则设为“None”,否则保留原内容。
- 评价人数列处理:对“rating_count”列进行处理,将“少于10人评价”转换为10,“目前无人评价”转换为0,其他情况提取数字作为评价人数;若提取失败则设为“None”。
- 空值处理:检查数据各列的缺失值情况,对“name”(图书名称)、“author”(作者)、“publisher”(出版社)列的缺失值直接删除;对“rating”(评分)列的缺失值,按图书分类用均值填充;对“plot”(情节简介)列的缺失值用“未知”填充;对“translator”(译者)列的缺失值用“无译者”填充并去除前后空格;对“publish_year”(出版年份)列的缺失值,按图书分类用中位数填充;对“price”(价格)列的缺失值,按图书分类用均值填充。
- 重复值处理:检查数据中的重复值,若存在则删除重复数据。
- 异常值处理:检查数据的异常值,对“rating”(评分)列的异常值进行处理,将评分限制在0 - 10的范围内。
- 数据保存:将清洗后的数据保存到本地新的CSV文件中,同时将其保存到MySQL数据库的指定表中。
清洗后的部分数据如下图所示:
四、数据分析
分析后的结果数据文件如下图所示:
五、数据可视化
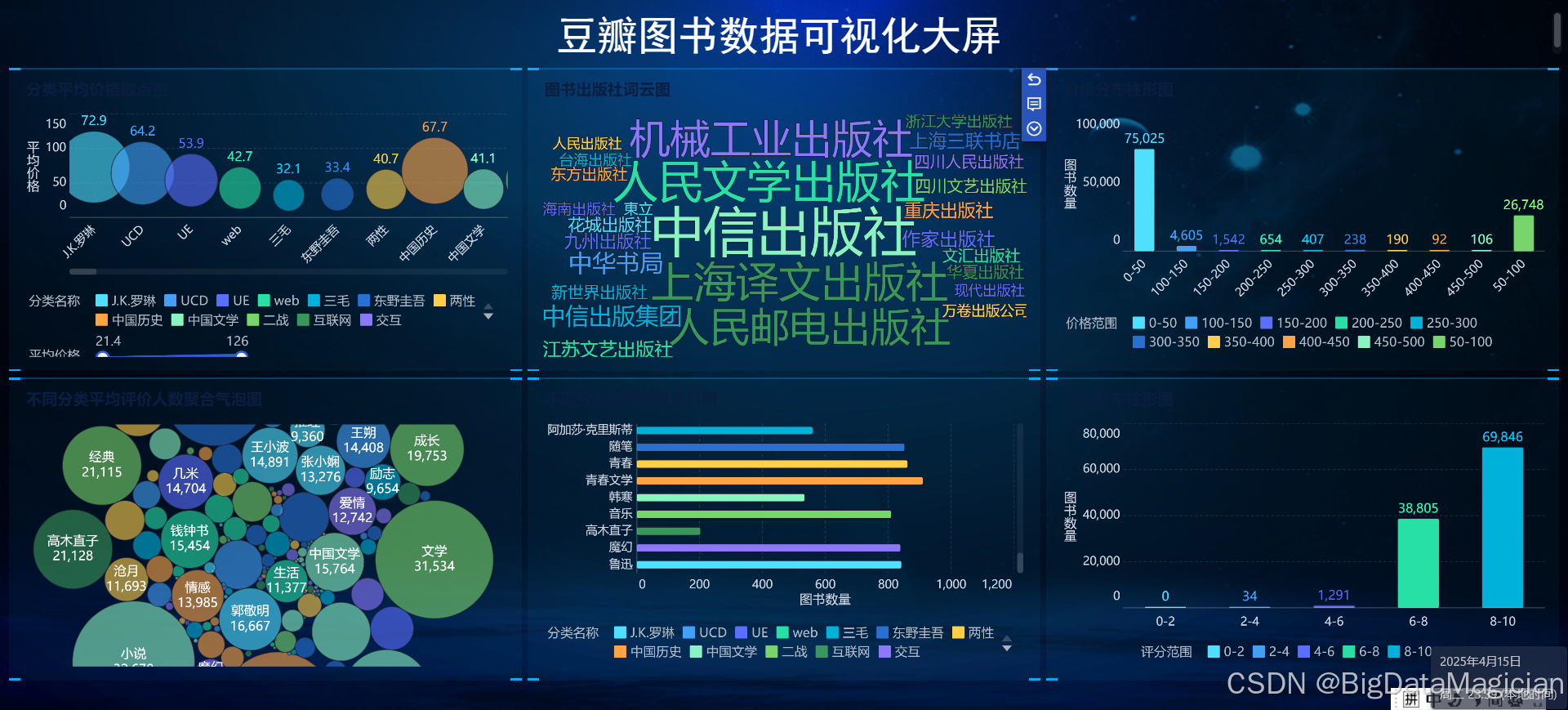
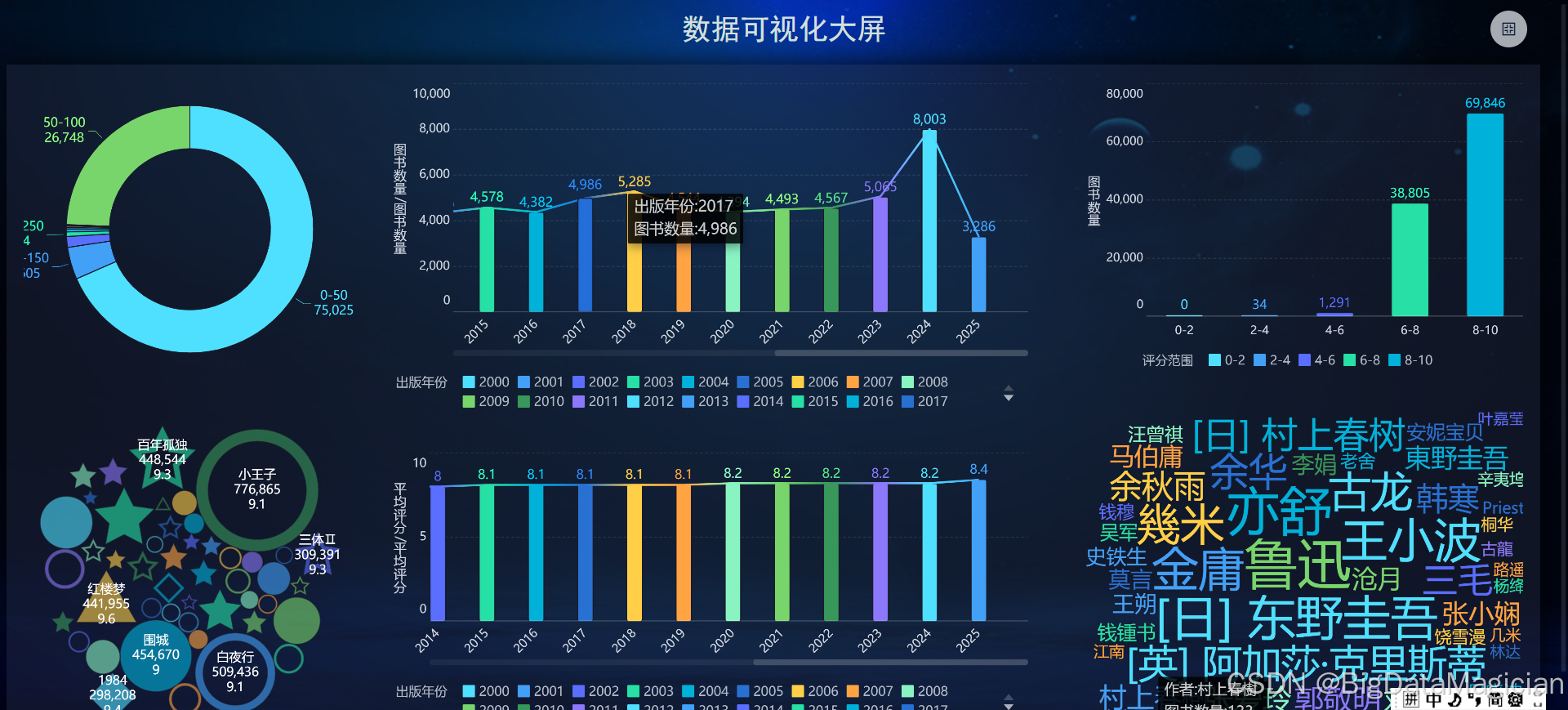
1. 数据可视化大屏展示


![[MySQL] 事务管理(二) 事务的隔离性底层](https://i-blog.csdnimg.cn/direct/9a78a348f89d49c0b289a2caa2e10146.png)